导读:分库分表做完了,ID 怎么生成?自增 ID 会重复,UUID 对索引不友好,Snowflake 又怕时钟回拨。本文从一个线上重复订单的故障出发,梳理分布式 ID 的四大主流方案,以及不同系统规模下的最佳选择。
一条“重复”订单引发的故障
你可能遇到过类似的场景:某个周五下午,线上突然收到用户投诉,同一笔订单被扣了两次款。客服拉出订单详情,发现两条记录的订单号一模一样,但支付流水号不同,金额、商品、下单时间完全相同。
DBA 赶紧查库,发现这两条记录分别落在了 order_0032 和 order_0096 两张分表里,订单号都是 100458723。根因很快定位:分库分表之后,两个数据库实例各自用的是本地 AUTO_INCREMENT,恰好在同一秒生成了相同的自增 ID。下游支付系统拿这个 ID 做幂等键,两条请求都通过了校验,于是产生了重复扣款。
故障复盘会上,架构师在白板上写了一行字:分库分表之后,自增 ID 这条路就走不通了,全局唯一 ID 是分布式系统的“地基”。
这不是一个新话题,但很多团队在分库分表的方案里花了大量精力设计分片键、选择分片算法,却在 ID 生成上草草了事。今天我们就来聊聊,从单库到分库分表,再到千万 QPS 的大规模系统,ID 生成方案到底经历了怎样的演进。
自增 ID 为什么不行了
在单库单表的时代,MySQL 的 AUTO_INCREMENT 是最自然的选择。它简单、有序、性能好,几乎零成本。InnoDB 的主键索引是聚簇索引,自增 ID 意味着数据按插入顺序物理存储,写入时只需追加到 B+ 树的末端,不会产生页分裂,写入性能极好。
但分库分表之后,这套机制立刻面临三个致命问题:
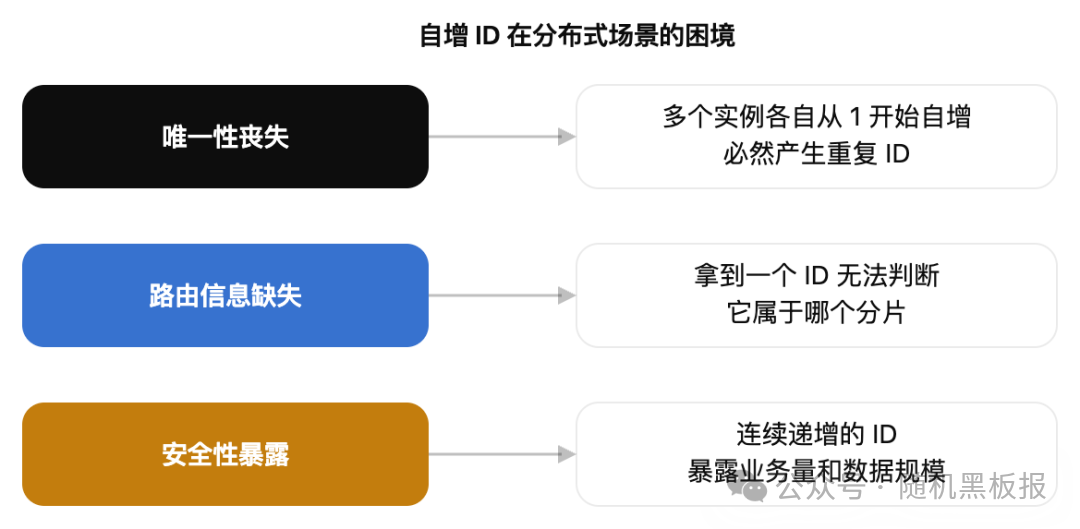
第一个问题最直观:两个数据库实例各自维护 AUTO_INCREMENT,生成的 ID 必然重复。有人说,可以设置不同的起始值和步长,比如实例 A 从 1 开始步长 2,实例 B 从 2 开始步长 2。这确实能避免冲突,但它把数据库实例的数量硬编码进了 ID 生成规则。将来要加实例怎么办?步长改不了,已有的 ID 空间也回收不了。步长方案本质上是一个“写死实例数”的静态方案,在需要弹性扩缩容的场景下毫无用处。
第二个问题在实际开发中也非常头疼。分表之后,业务经常需要根据订单号反查它落在哪张表。如果 ID 里没有携带分片信息,每次查询都要遍历所有分片,或者维护一套额外的路由映射表,这在高 QPS 场景下是不可接受的。
第三个问题在 C 端业务中尤其敏感。如果你的订单号是简单递增的,竞争对手只需要隔一段时间下两笔订单,用 ID 之差就能大致推算出你的日订单量。这在电商、社交、金融等领域是实实在在的商业风险。
全局 ID 的核心要求
在设计分布式 ID 方案之前,先厘清需求。不同业务对 ID 的诉求差异很大,但有一组底线要求是几乎所有分布式系统都需要的:
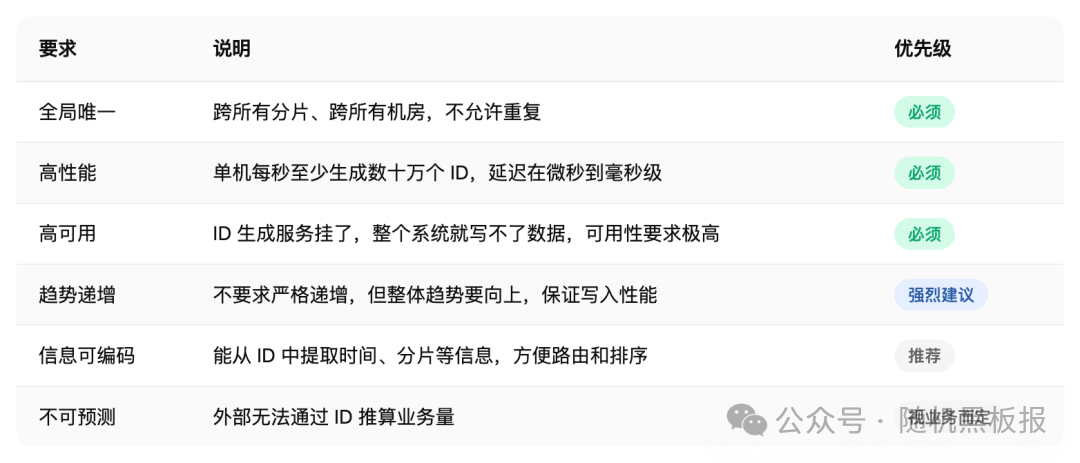
这里有一个容易被忽视的点:趋势递增和严格递增是两个完全不同的要求。严格递增意味着后生成的 ID 一定比先生成的大,这在分布式环境下几乎不可能做到(除非引入全局锁或单点序列化,但那就回到了性能瓶颈的老路)。趋势递增则宽松得多,只要求在一个时间窗口内,大部分 ID 是递增的,允许小范围的乱序。对 InnoDB 的聚簇索引来说,趋势递增就够了,偶尔的乱序只会导致少量页分裂,影响可以忽略。
方案一:数据库号段模式
既然自增 ID 的问题在于“各自为政”,一个直接的思路就是搞一个集中式的号段分配器。
基本原理
核心思想很简单:在一个独立的数据库中维护一张号段表,每个业务类型对应一行记录,记录当前已分配到的最大值。应用服务启动时,或者当前号段用完时,去号段表申请一批 ID(比如一次申请 1000 个),然后在本地内存中自增分配,用完了再去申请下一批。
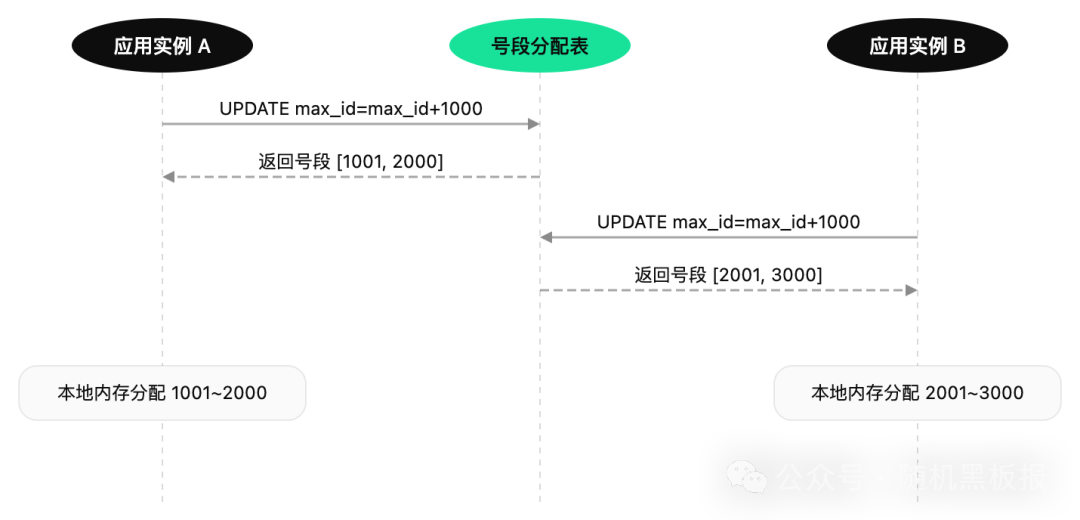
这种方案的优点非常明显:
- ID 全局唯一且严格递增(在同一实例内)
- 对号段数据库的访问频率极低(每 1000 次 ID 生成才访问一次),性能压力几乎可以忽略
- 实现简单,不依赖任何中间件
双 Buffer 优化
号段模式有一个隐患:当一个号段快要用完时,需要同步去数据库申请新号段,这个数据库请求虽然很快(通常在 1~3ms),但在极端高并发下,这几毫秒的阻塞可能导致 ID 生成出现抖动。
解决办法是双 Buffer 预加载。当当前号段消耗到一定比例(比如 20% 剩余)时,异步去申请下一个号段,缓存在备用 Buffer 中。当前号段用完后,直接切换到备用 Buffer,丝滑过渡,零等待。

美团的 Leaf-segment 就是这种方案的典型代表。它在号段模式的基础上加了双 Buffer,还支持动态调整步长(低流量时步长小一些,减少 ID 浪费;高流量时步长大一些,减少数据库访问频率),在实际生产中表现非常稳定。
号段模式的局限
号段模式虽然简单可靠,但它有几个先天不足:
- 强依赖数据库:号段表所在的数据库是单点。虽然访问频率不高,但一旦这个库挂了,所有实例的号段耗尽后就无法生成新 ID。需要搭配主从切换或多活部署来保障可用性
- ID 连续性暴露信息:生成的 ID 是连续递增的,竞争对手依然可以通过差值推算业务量
- 不携带时间信息:纯数字递增的 ID,看不出这条记录是什么时候产生的,在排查问题时不太方便
号段模式适合对 ID 有序性要求高、对信息安全性要求不高的内部系统,比如内部流水号、日志追踪 ID 等场景。
方案二:Snowflake 算法
2010 年,Twitter 开源了 Snowflake 算法,可以说是分布式 ID 领域的里程碑事件。它用一个 64 位的 long 型整数来编码一个全局唯一 ID,巧妙地把时间、机器、序列号三个维度压缩到了一个数字里。
位结构设计
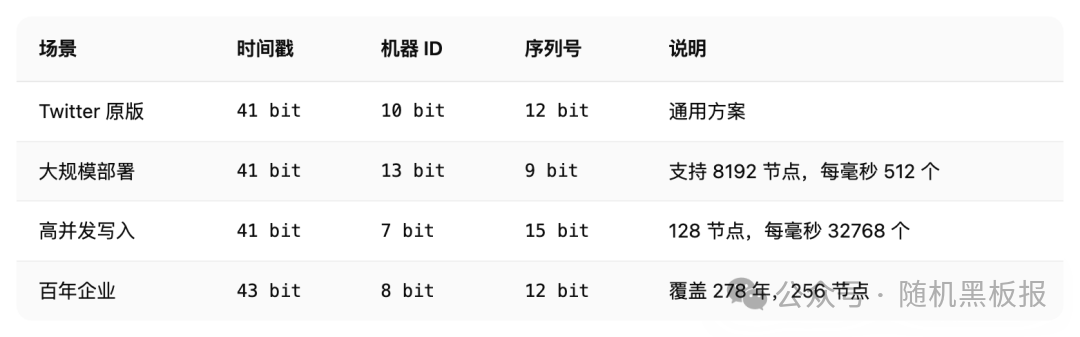
Snowflake 的 64 位分布如下:

1 bit 符号位:固定为 0,保证生成的 ID 是正数
41 bit 时间戳:存储毫秒级时间戳与自定义纪元的差值,41 bit 可以用约 69 年
10 bit 机器 ID:支持最多 1024 个节点(也可以拆成 5 bit 数据中心 + 5 bit 机器号)
12 bit 序列号:同一毫秒内的自增序列,支持每毫秒 4096 个 ID
这意味着,单个 Snowflake 节点每秒可以生成约 409 万个 ID,完全在本地内存完成,不依赖任何外部服务。
为什么是 41+10+12
这个位分配不是随意定的。Twitter 在设计时做了仔细的权衡:
- 41 bit 时间戳:覆盖约 69 年,对于一个系统的生命周期来说绰绰有余。如果从 2020 年开始算,可以用到 2089 年
- 10 bit 机器 ID:1024 台机器,对于大多数服务来说足够。如果你的服务部署超过 1024 个实例,通常可以通过逻辑分组(按业务线分)来解决
- 12 bit 序列号:每毫秒 4096 个,绝大多数场景下不会溢出。即使在秒杀场景下,通常也不会有单台机器在 1 毫秒内处理超过 4096 笔订单
当然,这个位分配不是写死的。实际生产中,不同公司会根据自己的场景做调整。比如:
时钟回拨:Snowflake 的阿喀琉斯之踵
Snowflake 算法本身非常优雅,但它有一个绕不开的软肋:对系统时钟的依赖。
ID 的前 41 位是时间戳,如果机器的时钟发生了回拨(NTP 校时、闰秒、手动调整等),就可能生成重复的 ID。举个例子:12:00:01 生成了 ID=X,然后时钟回拨到 12:00:00,这时候又可能生成一个同样的 ID=X。
业界对此有几种应对策略:
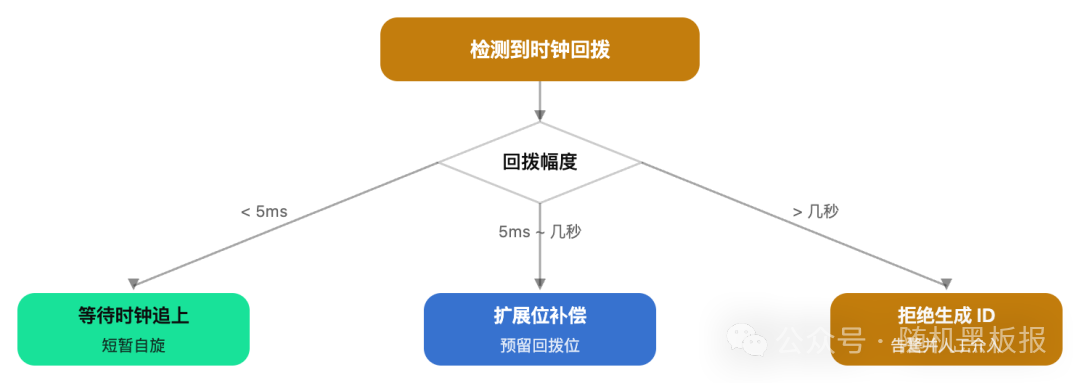
短暂等待:如果回拨只有几毫秒,直接 sleep 等时钟追上来。简单粗暴但有效
回拨位补偿:在机器 ID 中预留 2~3 bit 作为“时钟序列”,每次检测到回拨就加 1,相当于切换到一个新的“逻辑机器”
拒绝服务:如果回拨超过阈值(比如 5 秒),直接拒绝生成 ID 并触发告警。大幅度时钟回拨通常意味着系统出了严重问题,不应该“兜底”继续工作
百度的 UidGenerator 和美团的 Leaf-snowflake 都对时钟回拨做了不同程度的优化处理,在实际生产中可以参考。
方案三:UUID 及其变体
UUID(Universally Unique Identifier)是另一条完全不同的技术路线。它不依赖任何中心化的服务或时钟同步,每个节点独立生成,靠 128 bit 的超大空间和随机性来保证“概率上唯一”。
UUID 的版本演进
UUID 经历了多个版本的迭代,每个版本的设计思路和适用场景都不同:
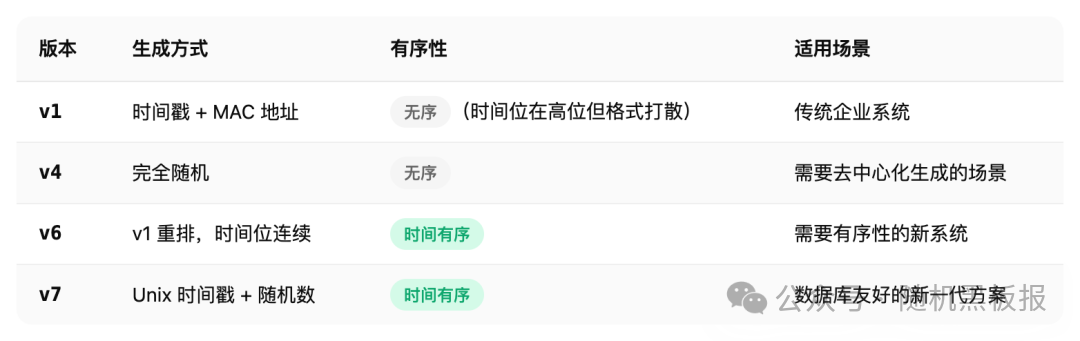
在分布式系统中,UUID v4 是用得最多的版本。它的优点很突出:完全去中心化,任何节点在任何时候都能独立生成,不需要协调,不需要网络调用,不需要担心时钟回拨。
但 UUID 作为数据库主键有一个严重的性能问题:128 bit 的随机 UUID 对 InnoDB 的聚簇索引极不友好,随机写入导致大量页分裂,写入性能可能下降 3~5 倍。
这不是小问题。在百万 QPS 的订单系统中,写入性能下降 3 倍意味着你需要多部署数倍的数据库资源才能扛住同样的写入量,成本和运维复杂度都会显著上升。
UUID v7 就是为了解决这个问题而生的。它把 Unix 毫秒时间戳放在最高位,低位用随机数填充,这样生成的 UUID 在时间维度上是单调递增的,对聚簇索引友好。但 128 bit 的长度(存储为 36 字符的字符串或 16 字节的二进制)仍然比 64 bit 的 Snowflake ID 大一倍,索引占用空间更多,比较操作也更慢。
方案四:Redis / ZooKeeper 中心化生成
既然需要全局唯一,最直觉的思路就是用一个中心化的服务来“发号”。Redis 的 INCR 命令是原子操作,天然适合做这件事。
Redis 发号器
一条 INCR order_id_seq 命令就能拿到一个全局唯一的递增 ID,Redis 单实例每秒可以处理几十万次 INCR 操作,性能完全够用。
但问题在于:这是一个单点。
Redis 挂了怎么办?主从切换期间可能丢失最后几次 INCR 的结果,导致 ID 重复。Redis Cluster 模式下,INCR 是单 key 操作,无法利用多分片的并发优势。
为了解决单点问题,通常的做法是部署多个 Redis 实例,每个实例负责不同的 ID 段。比如 3 个实例,分别只生成模 3 余 0、余 1、余 2 的 ID。这又回到了前面说的步长方案,扩展性受限。
ZooKeeper 分配机器 ID
ZooKeeper 在分布式 ID 场景中更多扮演“辅助”角色,而不是直接发号。它最常见的用法是为 Snowflake 节点分配 worker ID:每个实例启动时在 ZooKeeper 上创建一个临时顺序节点,拿到的序号就是自己的 worker ID。这样就不需要手动配置每台机器的 ID,实现了“自动注册”。
中心化发号器的核心矛盾在于,它把“生成全局唯一 ID”这个高频操作变成了一个网络调用,在千万 QPS 的场景下,这个网络调用本身就是瓶颈。号段模式通过“批量获取、本地消费”来规避这个矛盾,是一种更务实的折中。
不同规模下的方案选择
讲了这么多方案,到底该用哪个?答案是:看你的系统规模和业务约束。
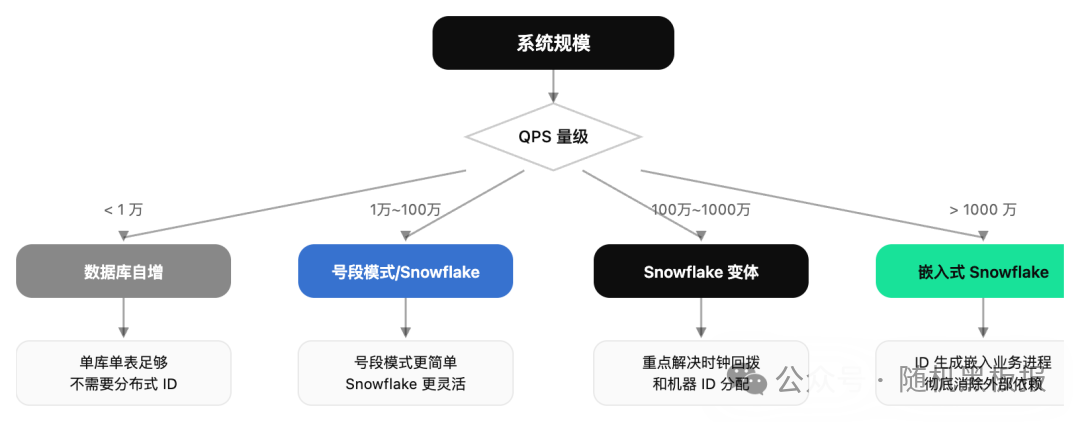
在不同的 QPS 量级下,ID 生成面临的核心挑战是不同的:
十万级 QPS:简单够用就好
这个量级下,号段模式是最佳选择。一个主从高可用的 MySQL 实例作为号段分配器,步长设为 1000,每秒只需要访问几十到几百次号段表,数据库毫无压力。实现简单、运维成本低、ID 严格递增,对聚簇索引最友好。
百万级 QPS:Snowflake 登场
当 QPS 上到百万,号段模式的号段表虽然访问频率不高,但每次申请新号段时的数据库延迟(1~3ms)在极端场景下可能成为抖动源。Snowflake 算法完全在本地内存生成,零外部依赖,延迟稳定在微秒级,非常适合这个量级。
关键是做好两件事:机器 ID 的自动分配(用 ZooKeeper 或配置中心)和时钟回拨的处理。
千万级 QPS:极致本地化
到了千万 QPS,ID 生成需要做到三个“零”:零网络调用、零锁竞争、零外部依赖。
Snowflake 的基本思路是对的,但需要进一步优化:
嵌入式部署:ID 生成逻辑直接嵌入业务进程,不走 RPC 不走 HTTP
预计算缓冲:后台线程预先生成一批 ID 放入无锁队列,业务线程直接取用
分段时间戳:把毫秒级时间戳改为秒级或 10 毫秒级,留更多 bit 给序列号,单个时间窗口能生成更多 ID
千万 QPS 场景下,ID 生成不是一个“服务”,而是一个“库”,它必须和业务代码运行在同一个进程中,任何跨进程的调用都是不可接受的开销。
ID 生成方案的工程细节
选定了方案之后,还有一些工程细节容易被忽视,但在生产环境中至关重要。
ID 的长度和存储
64 bit 的 Snowflake ID 存储为 BIGINT 类型,占 8 字节。这是一个非常“经济”的选择。作为主键和索引,8 字节的 BIGINT 比 16 字节的 UUID 或 36 字节的 UUID 字符串要节省大量存储空间和索引空间。
在一个拥有 10 亿行数据、5 个索引的表中,主键长度从 16 字节缩减到 8 字节,光索引就能节省约 40GB 的磁盘空间。这不仅是存储成本的差异,更直接影响 Buffer Pool 的利用率,间接影响查询性能。
ID 中编码业务信息
很多公司会在 Snowflake 的基础上,在 ID 中编码额外的业务信息。比如在机器 ID 的 10 bit 中,拿 3 bit 表示业务线,7 bit 表示机器号。这样拿到一个 ID,不仅知道它是什么时候生成的,还知道是哪个业务线的哪台机器生成的,排查问题时非常有用。
更进一步,有些方案会在 ID 中编码分片信息。比如把分片键的哈希值嵌入 ID 的某几位,这样拿到 ID 就能直接计算出数据在哪个分片,省去了一次路由查询。

ID 的可读性
纯数字的 ID 对机器友好,但对人不友好。一个 19 位的数字 1382971839483052032,你能一眼看出它是什么时候生成的吗?
有些公司会在对外暴露的场景中,对 ID 做一层编码转换。比如用 Base62(0-9a-zA-Z)编码,把 19 位数字压缩成 11 位的可打印字符串,既缩短了长度,又不容易被直接猜测。但要注意,这只是“展示层”的转换,存储层依然用 BIGINT,避免字符串比较带来的性能损耗。
从“能用”到“好用”的演进路线
回顾整篇文章,分布式 ID 的演进路线其实非常清晰:

每一步演进都不是因为前一个方案“不好”,而是因为系统规模变了,原来的方案在新的约束条件下不再是最优解。
数据库自增 ID 在单库时代是最优解,号段模式在分库分表初期是最优解,Snowflake 在大规模分布式系统中是最优解。没有银弹,只有最适合当前阶段的选择。
如果你的系统正在从单库向分库分表演进,号段模式几乎是“性价比”最高的起步方案:实现成本低、风险可控、性能够用。等系统规模进一步增长,再迁移到 Snowflake 方案也不迟,因为 ID 的消费方通常只关心“唯一性”和“可排序性”,底层的生成方式可以平滑切换。
真正需要你在一开始就想清楚的,不是用哪种算法,而是 ID 的长度(64 bit 还是 128 bit)、ID 中是否需要编码业务信息、以及 ID 是否需要对外暴露。这些决策一旦确定,后续改起来的代价远比更换生成算法要大得多。
如果你对构建高可用、高并发的分布式系统有更多兴趣,或者想了解如何为你的MySQL数据库选择合适的主键方案,欢迎在云栈社区与更多开发者交流探讨。
 发表于 2026-4-23 03:50:55
|
查看: 181|
回复: 0
发表于 2026-4-23 03:50:55
|
查看: 181|
回复: 0
