说到 Redis,很多开发者的第一反应就是分布式缓存。在业务开发中,将热点数据存入 Redis 以减轻数据库压力,这确实是最常见的用法。但经过多年的发展,Redis 早已超越了单纯的缓存角色,衍生出多种强大的能力。善用这些能力,不仅能解决许多实际问题,还能帮你省去引入额外中间件的麻烦。
我见过不少项目,明明用 Redis 就能搞定的事情,却额外引入了好几个第三方组件,导致架构变得复杂,维护成本也随之攀升。今天,我们就来聊聊 Redis 除了缓存之外,那些真正实用且强大的核心能力。看完你会发现,Redis 的玩法远比你想象的要丰富。
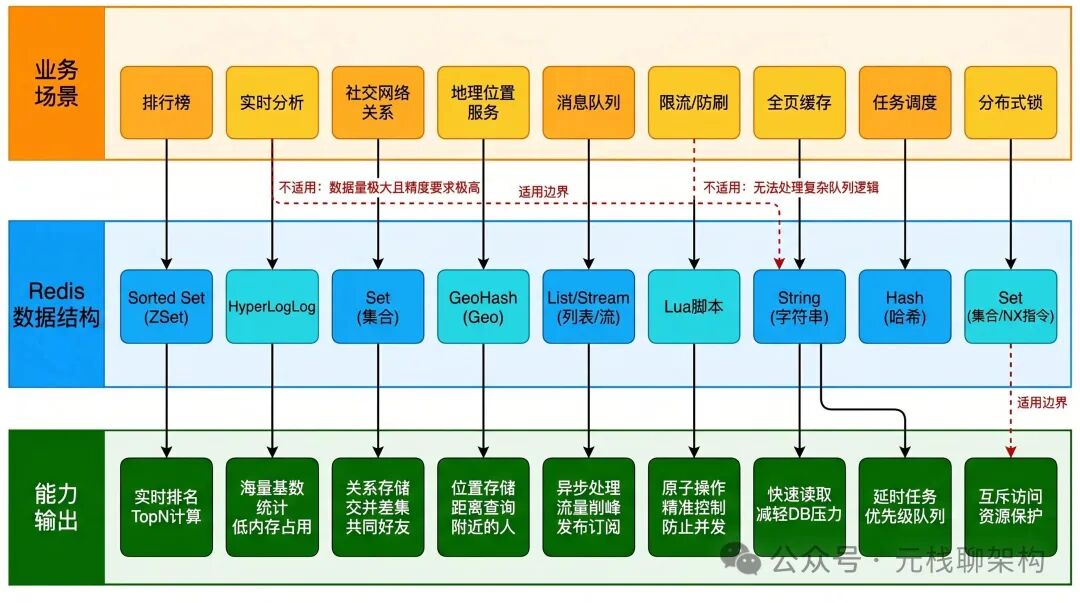
一、分布式锁,用Redis就能搞定
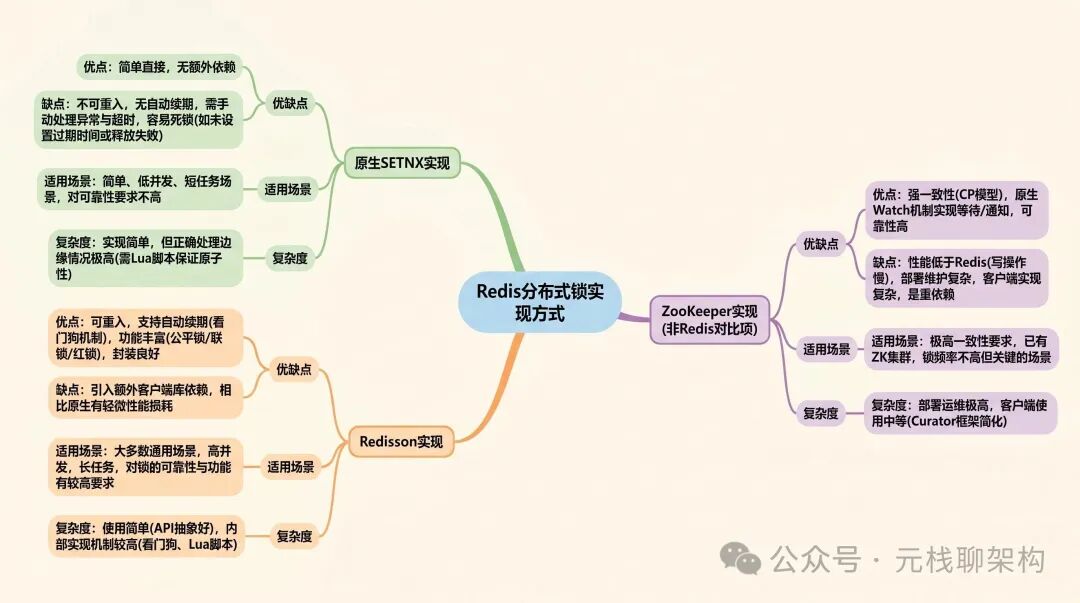
在分布式场景下,为了防止多个节点同时操作同一资源,我们需要用到分布式锁。很多人的第一反应是使用 ZooKeeper 或数据库的排他锁。实际上,Redis 原生就能很好地支持分布式锁,并且足够好用。
Redis 实现分布式锁的核心命令是 SETNX(SET if Not eXists),只有当键不存在时才会设置成功,这相当于“抢到”了锁。现在更推荐使用更完善的命令:SET key value NX EX expire,这个命令可以一步完成加锁和设置过期时间,有效防止死锁。
当然,这里也存在一些挑战,比如锁过期了但业务逻辑还未执行完毕怎么办?能否实现自动续期?像 Redisson 这样的客户端已经为我们解决了这些问题,其内置的“看门狗”机制可以自动为锁续期,无需开发者手动干预。
如果你的业务场景不是对强一致性要求达到百分之百的严苛程度,那么 Redis 实现的分布式锁完全够用。没有必要为了追求理论上的完美而额外引入 ZooKeeper,徒增架构的复杂度。对于绝大多数业务场景而言,最终一致性已经足够满足需求。
二、延时队列,不用MQ也能玩
业务开发中,我们经常遇到延时任务的需求,例如:订单下单后30分钟未支付自动取消,用户注册7天后发送欢迎短信等。面对这种场景,很多人会选择引入 RabbitMQ 或 RocketMQ。其实,利用 Redis 的有序集合(ZSet)就能轻松实现一个延时队列。
思路非常简单:将任务的执行时间作为分数(score),任务内容作为值(value),存入一个 ZSet 中。然后,启动一个后台线程定期轮询这个 ZSet,取出当前时间已经到点(score <= 当前时间戳)的任务并执行即可。
这种方式的优点是简单直接,无需额外部署消息队列,直接利用现有的 Redis 即可。缺点在于它没有完善的消息确认机制,如果任务执行失败,需要开发者自行处理重试逻辑。但对于一些对可靠性要求不是极端高的场景,比如超时取消订单,这种方案完全够用,能让架构保持简洁。
我在多个项目中都采用了这种方案,运行稳定,既节省了搭建和维护 MQ 的成本,也简化了系统架构。
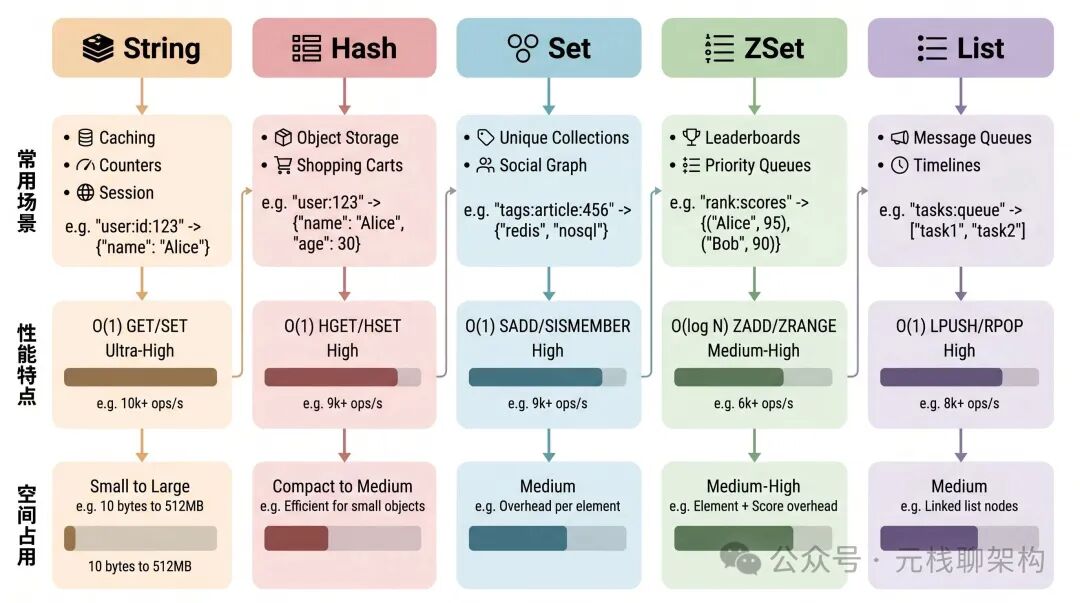
三、排行榜,天然就是SortedSet干的活
网站或 App 中经常需要展示排行榜,例如销量榜、热度榜、积分排名等。这种场景简直就是为 Redis 的 SortedSet(有序集合) 量身定做的。
SortedSet 天然保持元素有序。当你更新某个成员的分数时,它的排序位置会自动调整。获取 Top N 数据也非常高效,无论是正序还是倒序,直接使用范围查询命令即可。构建一个实时排行榜,其性能远超在数据库中使用 ORDER BY 进行排序。
例如,实现一个文章点赞排行榜:每次用户点赞时,使用 ZINCRBY 命令给对应文章的分数加1;需要获取点赞前十的文章时,直接使用 ZREVRANGE 0 9 命令即可。一句话搞定,无需自己编写复杂的排序逻辑。
对于排行榜这类需求,真的没有必要将其放在数据库中处理。Redis 的 SortedSet 无论在性能还是开发效率上,都是最优解。
四、位图,省空间的统计神器
如果你需要统计用户签到情况,或者记录用户一年中哪些天登录过,那么位图(Bitmap) 将是绝佳的选择。
一个用户一年的签到记录,使用 Bitmap 只需要 365 个比特位,不到 50 个字节。即使面对一千万用户,总占用空间也不到 50 MB,空间利用率极高。计算连续签到天数,或者判断某天是否签到,直接进行位操作即可,性能非常出色。
不仅仅是签到,实际上任何二值状态统计的场景都可以使用 Bitmap。例如,统计用户是否活跃、是否访问过某个页面、是否在黑名单中,都可以用它来实现。
以前可能觉得这个功能使用场景不多,但真正用起来才会发现“真香”。其极高的空间利用率,远比将数据存储在数据库中要节省得多。
五、HyperLogLog,做UV统计不用愁
网站统计 UV(独立访客)时,如果使用数据库或者 Redis 的 Set 进行去重,当用户量巨大时,空间占用会非常可观。而使用 Redis 的 HyperLogLog 数据结构,仅需固定的约 12KB 内存,就能统计接近亿级别的 UV,并且误差率可以接受(大约在 1% 以内)。
对于 UV 这类统计,业务上通常并不要求百分之百精确,一个接近准确的数字就足够了,HyperLogLog 完美契合这一需求。无论你有多少 UV,它都只占用约 12KB 空间,极其节省资源。
当然,如果你的业务要求必须精确无误,那么还是需要使用 Set 或数据库。但对于大多数场景,如首页 UV、文章阅读 UV 等,HyperLogLog 的性价比无疑是最高的。
六、总结:合理利用,简化架构
说了这么多,并不是鼓励你把所有消息队列、协调服务都扔掉,全部换成 Redis。专业的事情依然需要专业的组件来完成,例如,如果你的延时任务要求极高的可靠性,那么专业的消息队列仍然是更好的选择。Redis 的方案更适合轻量级、对可靠性要求相对宽松的场景。
这里的核心思路是:既然 Redis 已经存在于你的项目之中,那么能够利用它解决的问题,就尽量避免引入新的组件。这样做可以显著降低架构的复杂度,减少运维和维护成本,何乐而不为呢?
很多时候,并不是架构越复杂就越厉害。能够用简洁、高效的方案解决问题,才是真正的本事。Redis 能够如此流行,不仅仅是因为它缓存做得好,其内置的一系列精巧而强大的数据结构,确实能帮助我们完成许多意想不到的工作。
希望本文能帮助你重新认识 Redis,发掘其更多潜力。如果你想深入探讨后端架构或数据库相关的其他话题,欢迎到 云栈社区 交流分享。
 发表于 2026-4-23 03:53:51
|
查看: 126|
回复: 0
发表于 2026-4-23 03:53:51
|
查看: 126|
回复: 0
