当系统从单机扩展到集群,Session 存储方案也必须跟着演进。本文从一个扩容导致用户掉线的真实案例出发,系统梳理了会话缓存从本地内存、集中式 Redis 到分布式集群的完整演进路线,并深入分析了 JWT 替代方案的利弊、千万 QPS 下的容量规划与跨机房同步策略。更多关于后端系统架构的深度探讨,欢迎在云栈社区交流。
一次扩容引发的登录风暴
凌晨两点,运维团队正在对一个电商系统做例行扩容。新增了 8 台应用服务器,Nginx 自动发现新节点并开始分流。一切看起来风平浪静,直到客服群里炸了锅:大量用户反馈“刚登录就被踢了”“购物车清空了”“支付页面跳回首页”。
排查了半个小时才找到原因:这套系统的会话(Session)存储在应用服务器本地内存里。扩容后,负载均衡器把同一个用户的请求路由到了不同的机器,新机器上没有这个用户的 Session,自然就认为用户没登录。
这种事在日活几万的小系统上可能不太容易遇到,因为单台机器就能撑住,根本不需要频繁扩缩容。但当你的系统成长到百万、千万 QPS 时,几十上百台应用节点动态伸缩是家常便饭,会话管理的架构选择,直接决定了系统能不能在弹性伸缩的同时保持用户体验的连续性。
今天聊的就是这件事:Session 从“存在本地”到“存在远端”再到“分布式架构”下的演进路线,以及每一步背后的 trade-off。
会话的本质:有状态的无状态协议
HTTP 是无状态的,每个请求之间互相独立,服务器不会记住“你是谁”。但实际业务场景中,用户登录之后浏览商品、加购物车、下单支付,这些操作需要一个连续的身份上下文。Session 就是为了解决这个矛盾而诞生的。
一个典型的 Session 生命周期大概是这样的:
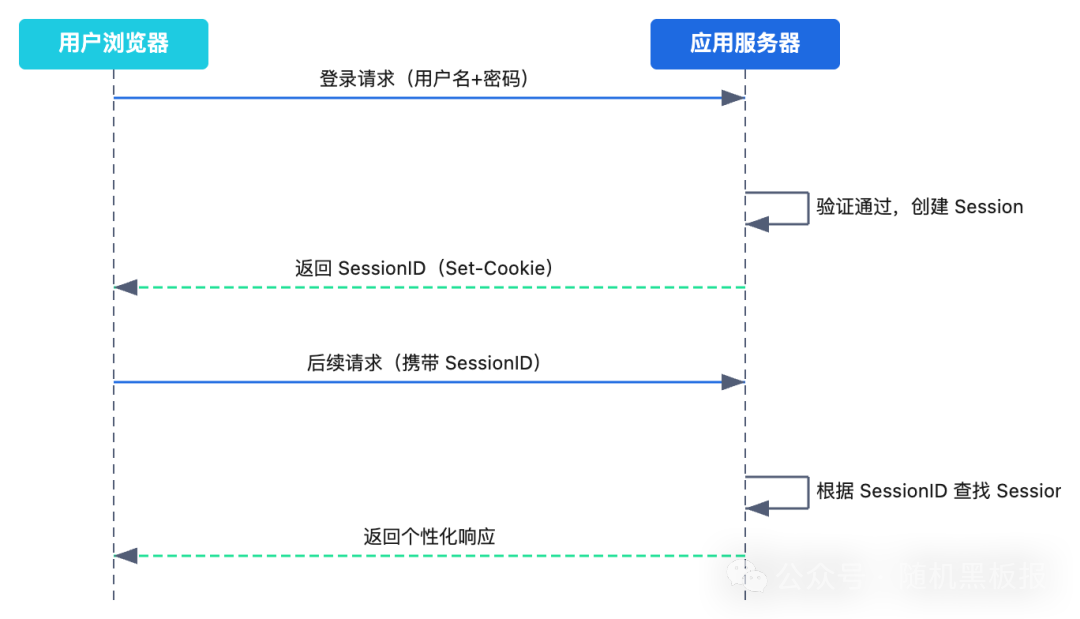
从架构视角来看,Session 本质上是一个 Key-Value 存储:Key 是 SessionID,Value 是用户的状态数据(身份信息、权限、偏好等)。问题的核心不在于怎么生成这个 Key-Value,而在于把它存在哪、怎么存、怎么让多个节点都能读到。
这就引出了会话存储的架构演进之路。
第一代:本地内存存储
最朴素的方案,Session 直接放在应用进程的内存里。Java 的 HttpSession、PHP 的 $_SESSION、Node.js 的 express-session 默认都是这么干的。
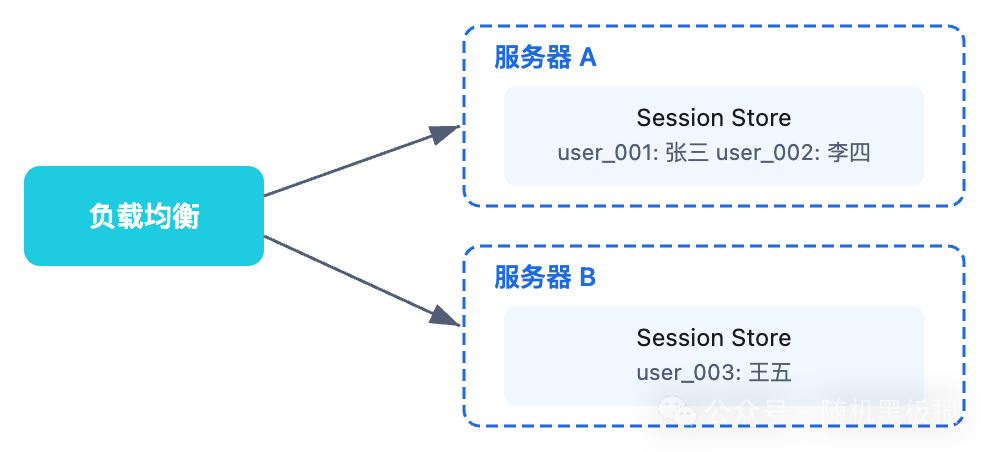
优点很明显:实现简单,读写速度极快(内存直接访问,纳秒级),不依赖任何外部组件。
但缺点同样致命:

为了缓解“节点绑定”的问题,很多团队会在负载均衡器上配置“粘性会话”(Sticky Session),让同一个用户的请求始终路由到同一台服务器。常见的实现方式是基于 Cookie 或者源 IP 做哈希。
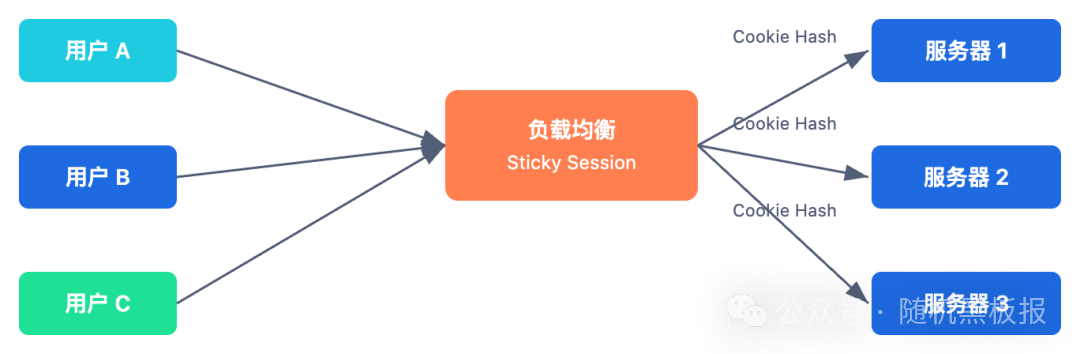
粘性会话勉强能用,但它本质上是在回避问题而不是解决问题。粘性会话把无状态的负载均衡退化成了有状态的路由,弹性伸缩和故障转移的优势荡然无存。
在十万 QPS 以下的规模,粘性会话还凑合。一旦到了百万 QPS,节点数量多、故障概率高、扩缩容频繁,这个方案就不可接受了。
第二代:集中式会话存储
既然问题的根源是“Session 分散在各个节点上”,那就把它集中起来。所有应用节点不再自己存 Session,统一去一个中心化的存储里读写。
最常见的选择是Redis。一来它是内存数据库,读写延迟低(通常在 1ms 以内);二来它天然支持 Key-Value 模型和 TTL 过期,跟 Session 的语义完美匹配。
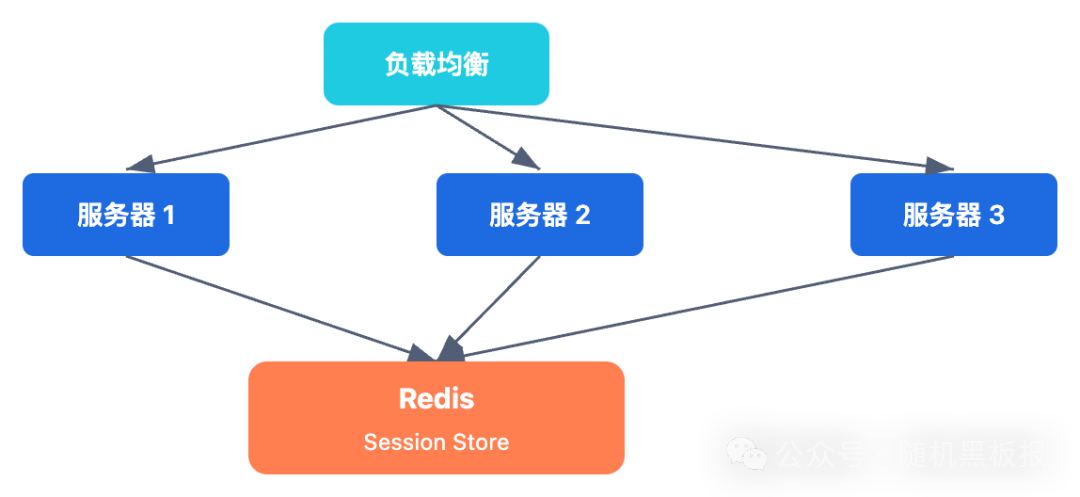
这个架构一下子解决了前面提到的几个核心问题:
- 无状态化:应用节点本身不再存储 Session,任何一台服务器都能处理任何用户的请求
- 弹性伸缩:随意增减应用节点,不会影响已有 Session
- 故障隔离:某台应用服务器挂了,用户被路由到其他节点,Session 依然有效
但同时引入了新的问题:
网络延迟:每个请求至少多一次网络往返(查 Session)。内网环境下 Redis 的 RTT 大约在 0.1ms 到 0.5ms,对于大多数业务来说可以接受。但如果你的接口本身只需要 2ms 处理,额外的 0.5ms 就意味着 25% 的延迟增加,这在高性能场景下不能忽视。
单点瓶颈:所有 Session 读写都压在一个 Redis 实例上。单个 Redis 实例的极限大约是 10 万到 15 万 QPS(纯读场景下可以更高)。如果你的系统有 1000 万 DAU,峰值时刻有 200 万在线用户同时操作,每个请求都要查 Session,这个量级单个 Redis 实例显然扛不住。
数据安全:Redis 默认是内存存储,虽然有 RDB 和 AOF 持久化,但在极端情况下(比如主从切换期间的短暂数据丢失),可能会导致部分用户的 Session 丢失。对于电商支付场景,这意味着用户可能需要重新登录,体验不好但不至于灾难性。
集中式 Session 存储是从“能用”到“好用”的关键一步,它让应用层真正做到了无状态化。在十万到百万 QPS 的规模区间,这套方案足够稳健。但当流量继续攀升到千万级别,集中式存储本身就成了需要被解决的瓶颈。
第三代:分布式会话存储
当集中式 Redis 成为瓶颈时,自然的演进方向是把 Session 存储也做分布式。这里有几条路可以走。
Redis Cluster 分片
最直接的思路:利用 Redis Cluster 的 16384 个哈希槽,把 Session 按照 SessionID 分散到不同的分片上。每个分片只负责一部分 Session 数据。
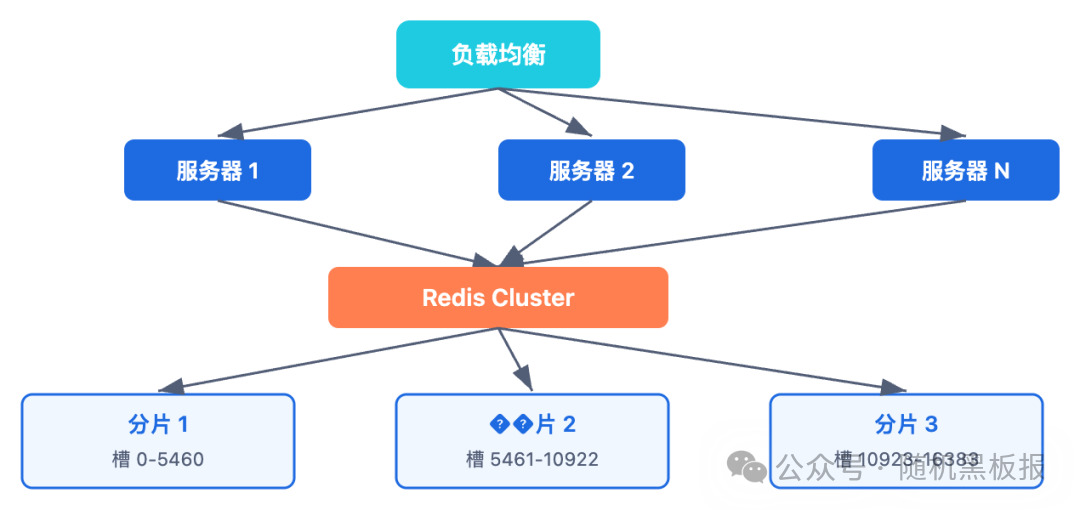
假设你有 6 个 Redis 分片(3 主 3 从),理论上吞吐量可以接近单机的 3 倍,也就是 30 万到 45 万 QPS。如果还不够,继续加分片就行。
但 Redis Cluster 在 Session 场景下有几个需要注意的点:
- 跨槽操作:如果业务逻辑需要在一次操作中访问多个用户的 Session(比如群聊场景下批量获取),跨分片查询会增加延迟
- 分片迁移:Cluster 做 resharding 时,正在迁移的槽上的 Session 访问会有短暂的 MOVED/ASK 重定向,增加一次网络往返
- 内存碎片:Session 大小通常不均匀(有的用户 Session 里存了一大堆购物车数据),可能导致分片间的内存不均衡
多级缓存:本地 + 远端
另一个思路是“近水救近火”:在应用节点本地维护一层 Session 缓存,远端 Redis 作为权威数据源。

本地缓存通常使用 Caffeine(Java)或者 LRU Cache,容量有限(比如缓存最近 5 分钟活跃的 1 万个 Session),设置较短的 TTL(30 秒到 2 分钟)。
这套方案的关键数据:

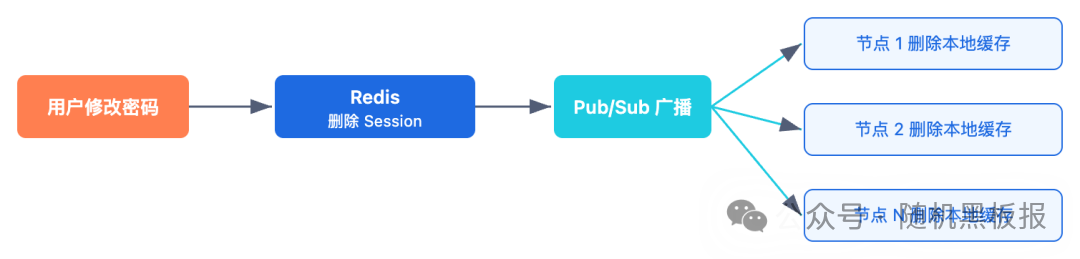
本地缓存是性能优化的利器,但代价是引入了一致性窗口:用户修改密码后,在 L1 TTL 到期之前,旧 Session 可能仍然有效。
对于“修改密码后立即踢掉所有在线设备”这类强一致性要求的场景,需要额外的机制来处理:比如通过 Redis Pub/Sub 广播一条失效通知,让所有节点的本地缓存主动删除该 Session。
一致性哈希路由
如果不想引入 Redis Cluster 的复杂性,还有一种轻量方案:在客户端(应用层)使用一致性哈希来路由 Session 请求。每个 SessionID 通过哈希函数映射到某个 Redis 实例上。
这种方案在中等规模(几十万到几百万 Session)下效果不错。但跟粘性会话类似,当某个 Redis 实例故障时,映射到该实例的所有 Session 都会丢失。配合主从复制可以缓解,但无法完全消除。
无 Session 方案:JWT 的诱惑与陷阱
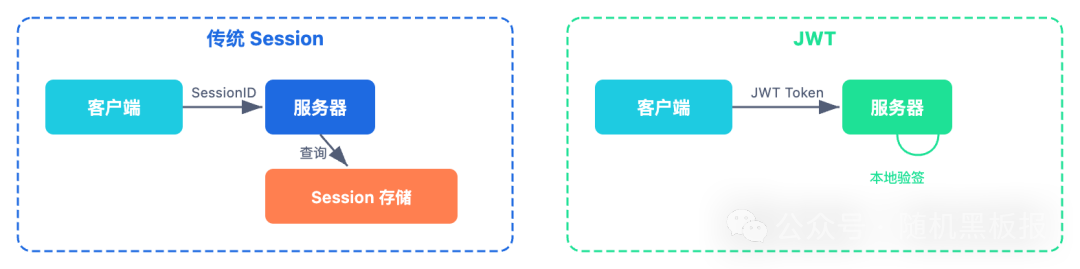
聊到 Session 分布式化,一定会有人问:“为什么不用 JWT?把状态存到客户端,服务器完全无状态,分布式问题不就不存在了吗?”
JWT(JSON Web Token)确实是一种“反其道而行之”的思路:不再把状态存在服务端,而是把用户信息编码成一个签名过的 Token,发给客户端。每次请求时客户端携带 Token,服务端只需要验签就能知道“你是谁”。
听起来很美好,但工程实践中 JWT 做 Session 管理有几个绕不过去的坑:
Token 吊销难题:JWT 一旦签发,在过期时间之前都是有效的。如果用户修改了密码、被封禁、或者 Token 泄露,你没法让一个已签发的 JWT 立即失效。常见的解法是维护一个“黑名单”,但这就又引入了服务端状态,JWT 的“无状态”优势就打了折扣。
Token 体积问题:一个包含用户基本信息的 JWT 通常有 500 字节到 2KB。如果你还塞了权限列表、角色信息,体积会更大。每个请求都携带这么大的 Token,在移动端弱网环境下,带宽开销不可忽视。而 SessionID 通常只有 32 到 64 字节。
刷新机制的复杂性:为了平衡安全性和体验,通常会用“短期 Access Token + 长期 Refresh Token”的双 Token 方案。Access Token 有效期很短(比如 15 分钟),过期后用 Refresh Token 换取新的。这套机制本身就增加了客户端和服务端的复杂度。

JWT 不是 Session 的替代品,而是不同场景的不同选择。在需要即时吊销、频繁更新状态的场景下,Server-Side Session 仍然是更可控的方案。
实际工程中,很多系统会混用两种方案:对外网关使用 JWT 做无状态鉴权,内部服务使用 Server-Side Session 管理精细的用户状态。
千万 QPS 下的 Session 架构实战
当系统规模到了千万 QPS,会话管理面临的挑战已经不仅仅是“存哪里”的问题,而是一整套工程体系。
容量规划
假设系统有 5000 万注册用户,日活 1500 万,峰值同时在线 500 万。每个 Session 平均占用 1KB,那么:
- Session 总存储量:500 万 x 1KB = 5GB
- Session QPS(假设每个在线用户每秒 2 次请求):500 万 x 2 = 1000 万 QPS
5GB 的数据量对于 Redis 来说不算大,但 1000 万 QPS 意味着需要大约 70 到 100 个 Redis 分片(按单分片 10 万到 15 万 QPS 计算)。加上主从复制,整个 Session 集群可能需要 200 多个 Redis 实例。
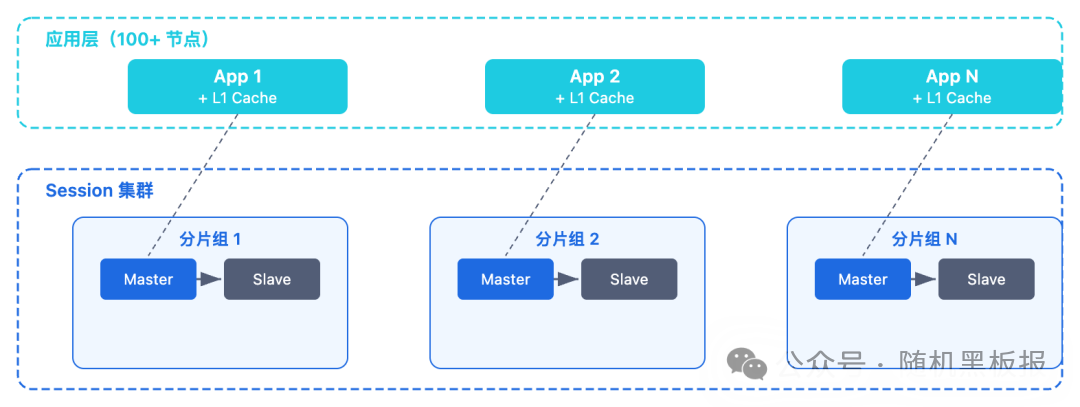
这时候本地缓存的价值就体现出来了。如果 L1 缓存命中率能达到 80%,Redis 集群只需要承受 200 万 QPS,分片数量可以缩减到 15 到 20 个,运维成本和硬件成本都会大幅下降。
热点 Session 问题
不是所有 Session 都是平等的。在电商大促场景下,某些“超级用户”(比如直播间的主播、秒杀活动的发起者)的 Session 可能被高频访问。如果这些热点 Session 恰好落在同一个 Redis 分片上,就会出现“热点分片”问题。
解决热点问题的常见策略:
- 本地缓存兜底:热点 Session 几乎一定会命中 L1 缓存,大部分请求不会打到 Redis
- 读写分离:对 Session 做读写分离,读请求分散到从节点,写请求(更新 Session)只发到主节点
- Session 拆分:把 Session 中频繁更新的部分(比如最后活跃时间)和相对稳定的部分(比如用户身份信息)拆成两个 Key,减少写入频率
跨机房会话同步
当系统部署在多个数据中心时,Session 的跨机房同步是另一个挑战。
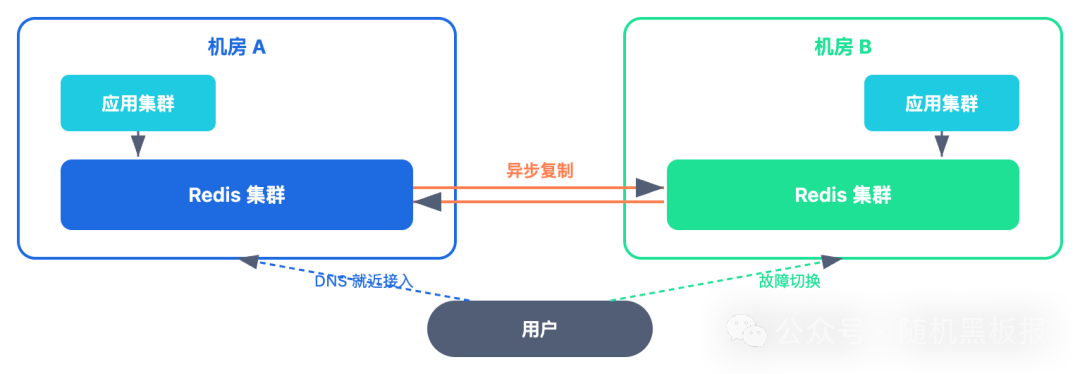
两种主流方案:
方案一:异步复制。每个机房有独立的 Redis Session 集群,通过异步复制保持数据同步。正常情况下用户请求只访问本机房的 Redis,延迟极低。但机房间的复制延迟通常在 50ms 到 200ms,这意味着用户被切换到另一个机房后,可能有短暂的 Session 不一致。
方案二:全局写本地读。所有 Session 的写操作都发往一个“主机房”,读操作在本地机房完成。这样保证了 Session 的最终一致性,但写操作的延迟会增加(跨机房 RTT)。适合读多写少的场景,而 Session 恰好大部分操作都是读。
跨机房 Session 同步的核心取舍是延迟与一致性:异步复制延迟低但有不一致窗口,同步复制一致性强但延迟高。
大多数千万级系统选择异步复制 + 容忍短暂不一致。原因很简单:用户被切换机房本身就是一个低概率事件(通常只在机房故障时发生),为了这个小概率场景让所有正常请求都承受额外延迟,不值得。
Session 生命周期治理
在大规模系统中,Session 的生命周期管理也需要精细化:
- 分级过期策略:不同类型的 Session 设置不同的过期时间。普通浏览 Session 可以 30 分钟过期,已登录用户 Session 可以延长到 7 天,“记住我”的 Session 可以 30 天
- 惰性续期:不是每次请求都刷新 Session 的过期时间,而是在 Session 剩余有效期低于某个阈值时(比如不到总有效期的 1/3 时)才续期。这样可以减少大量无意义的 Redis 写操作
- 优雅退出:服务器主动下线时,不要直接杀进程,而是先停止接收新请求,等待已有请求处理完成,确保 Session 更新操作不会丢失
演进路线图:从单体到千万
回顾整个演进历程,会话存储的架构选择本质上是一致性、性能和复杂度之间的三角权衡。
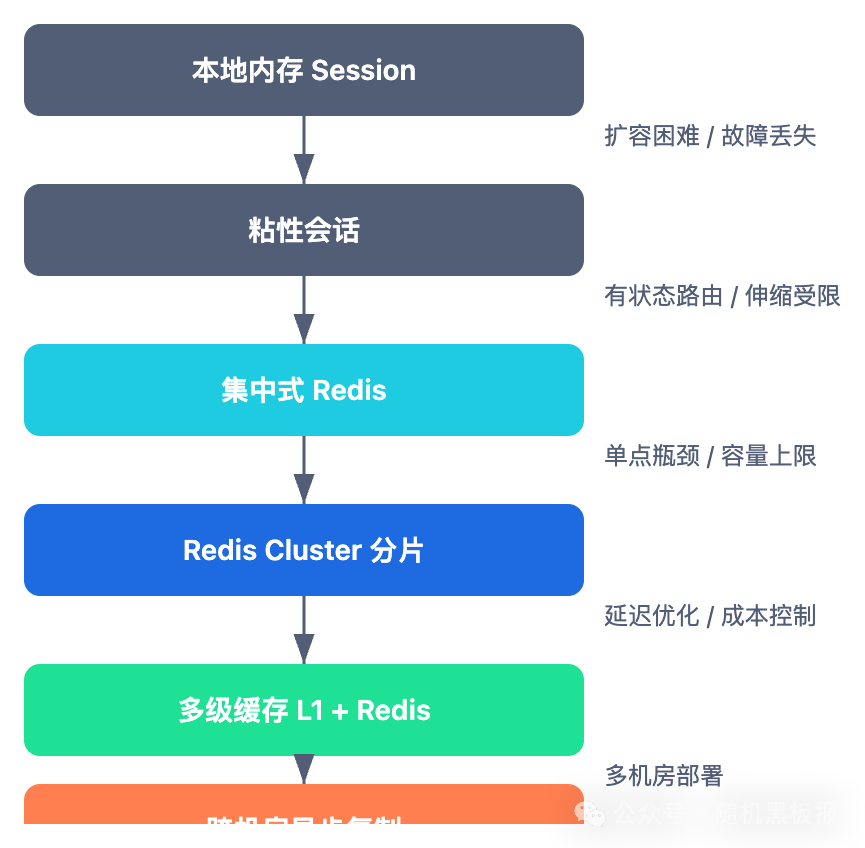

没有一种方案适合所有阶段。在系统规模还小的时候,过早引入分布式 Session 架构只会增加不必要的复杂度和运维负担。但如果你的系统正在从百万向千万 QPS 迈进,提前做好 Session 架构的规划,能帮你避开很多扩容路上的坑。
架构演进的本质不是追求最优解,而是在当前约束下找到最合适的平衡点,并且为下一次演进留好接口。
下一次当你看到系统里的 Session 相关代码时,不妨想想:如果流量翻 10 倍,现在的方案还能撑住吗?如果不能,瓶颈在哪?这个思考本身,比任何具体方案都更有价值。特别是在应对极端高并发场景时,一个稳固的会话管理基础至关重要。
 发表于 2026-4-19 03:17:10
|
查看: 163|
回复: 0
发表于 2026-4-19 03:17:10
|
查看: 163|
回复: 0
