“系统又挂了!凌晨3点被叫起来改代码,结果只是Redis缓存没设过期时间——50万条数据把内存撑爆了。”
Redis这东西,用好了是神器,用不好就是深坑。今天,我们从数据结构到分布式锁,从缓存策略到集群部署,把Redis的核心知识点和实战避坑指南一次讲清楚。
01. 先说说 Redis 是什么
Redis,全称 Remote Dictionary Server,远程字典服务。官方的定义是:开源的、基于内存的数据结构存储系统。
说人话就是:Redis是一个主要把数据存在内存里的数据库,读写速度极快,同时也能将数据持久化到硬盘,防止丢失。
为什么Redis这么火?核心就是快!其读取速度可达10万次/秒,写入速度也能达到8万次/秒,传统的关系型数据库难以望其项背。
| 特性 |
说明 |
优势 |
| 基于内存 |
数据主要存储在内存中 |
纳秒级访问速度 |
| 数据结构丰富 |
String, List, Hash, Set, ZSet |
支持多样化的业务场景 |
| 单线程 |
核心命令处理是单线程 |
避免了多线程的锁竞争开销 |
| 支持持久化 |
RDB + AOF |
数据可靠性有保障 |
| 支持集群 |
主从、Sentinel、Cluster |
实现高可用与横向扩展 |
02. Redis 数据结构——不仅是缓存
很多人误以为Redis只能存简单的字符串键值对,这只是它能力的冰山一角。Redis提供了5种基础数据结构,每种都对应着独特的应用场景。
2.1 String(字符串)—— 最常用
String类型是Redis最基础的数据结构,一个Key对应一个Value,常用于缓存、计数器等场景。
// Java 中使用 Redis
String value = redisTemplate.opsForValue().get("user:1001");
redisTemplate.opsForValue().set("user:1001", JSON.toJSONString(user));
// 设置过期时间(验证码场景)
redisTemplate.opsForValue().set("captcha:1234", "abcde", Duration.ofMinutes(5));
// 计数器(阅读量、点赞数)
redisTemplate.opsForValue().increment("page:view:20260315"); // +1
redisTemplate.opsForValue().decrement("stock:product:001"); // -1
面试点:String 最大能存多大?
答:512 MB。
2.2 List(列表)—— 队列神器
List是一个双向链表,支持从头部或尾部进行插入和弹出操作,是构建简单消息队列的理想选择。
// 左边入队(生产者)
redisTemplate.opsForList().leftPush("queue:order", orderJson);
// 右边出队,阻塞等待最多10秒(消费者)
String order = redisTemplate.opsForList().rightPop("queue:order",
Duration.ofSeconds(10));
// 获取列表长度
Long length = redisTemplate.opsForList().size("queue:order");
典型场景:
- 消息队列:生产者左端推入(LPush),消费者右端弹出(RPop)
- 最新列表:存储最新10条微博或评论
- 粉丝列表:按关注时间顺序排列
2.3 Hash(哈希)—— 对象存储
Hash是一个String类型的Field和Value的映射表,特别适合存储对象。
// 存储用户对象
Map<String, Object> userMap = new HashMap<>();
userMap.put("name", "张三");
userMap.put("age", "28");
userMap.put("city", "北京");
redisTemplate.opsForHash().putAll("user:1001", userMap);
// 获取单个字段(无需反序列化整个对象)
String name = (String) redisTemplate.opsForHash().get("user:1001", "name");
// 获取整个对象
Map<Object, Object> user = redisTemplate.opsForHash().entries("user:1001");
面试点:Hash 和 String + JSON 存对象有什么区别?
- String + JSON:存取整个对象方便,但更新任意字段都需要序列化/反序列化整个对象。
- Hash:可以独立更新(
HSet)或读取(HGet)某个字段,更节省网络流量,但Field数量不宜过多。
- 最佳实践:频繁变动的对象字段用Hash,固定的配置信息用String+JSON。
2.4 Set(集合)—— 去重利器
Set是String类型的无序集合,通过哈希表实现,元素不重复。
// 添加用户标签
redisTemplate.opsForSet().add("user:1001:tags", "Java", "Redis", "架构");
// 检查是否拥有某个标签
Boolean hasTag = redisTemplate.opsForSet().isMember("user:1001:tags", "Java");
// 获取所有标签
Set<Object> tags = redisTemplate.opsForSet().members("user:1001:tags");
// 求交集(共同兴趣标签)
Set<Object> javaUsers = redisTemplate.opsForSet().intersect("users:tags:Java", "users:tags:Redis");
典型场景:
- 标签系统:文章标签、用户兴趣标签
- 去重:用户点赞记录、UV统计
- 社交关系:共同关注、共同好友
2.5 ZSet(有序集合)—— 排行榜专用
ZSet在Set的基础上,为每个元素关联了一个score(分数),元素按score排序。
// 添加用户积分
redisTemplate.opsForZSet().add("ranking:score", "user:1001", 9800.0);
redisTemplate.opsForZSet().add("ranking:score", "user:1002", 9600.0);
redisTemplate.opsForZSet().add("ranking:score", "user:1003", 9400.0);
// 获取用户排名(从0开始,reverseRank是降序排名)
Long rank = redisTemplate.opsForZSet().reverseRank("ranking:score", "user:1001");
// 获取前10名
Set<Object> top10 = redisTemplate.opsForZSet().reverseRange("ranking:score", 0, 9);
// 获取用户具体分数
Double score = redisTemplate.opsForZSet().score("ranking:score", "user:1001");
典型场景:
- 排行榜:游戏积分榜、商品热度榜
- 延迟队列:用时间戳作为score,定时取出
- 优先级队列:VIP用户优先处理
03. 缓存策略——怎么用才不翻车?
缓存用得好能极大提升性能,用不好则会导致数据不一致、系统雪崩。下面介绍几种常见的缓存读写策略。
3.1 Cache-Aside(旁路缓存)—— 最常用
应用程序直接与缓存和数据库交互。读时先读缓存,未命中则读库并回填;写时先更新数据库,再删除缓存。
public User getUserById(Long userId) {
// 1. 先查缓存
String cacheKey = "user:" + userId;
String cached = redisTemplate.opsForValue().get(cacheKey);
if (cached != null) {
// 缓存命中,直接返回
return JSON.parseObject(cached, User.class);
}
// 2. 缓存未命中,查数据库
User user = userRepository.findById(userId);
if (user != null) {
// 3. 写入缓存,设置过期时间
redisTemplate.opsForValue().set(
cacheKey,
JSON.toJSONString(user),
Duration.ofHours(1) // 1 小时过期
);
}
return user;
}
public void updateUser(User user) {
// 1. 先更新数据库
userRepository.save(user);
// 2. 删除缓存(注意:是删除,不是更新!)
String cacheKey = "user:" + user.getId();
redisTemplate.delete(cacheKey);
// 思考:为什么是删除而不是更新缓存?
// 答:在并发场景下,更新缓存可能导致数据不一致(数据库更新成功,但另一个线程将旧数据写入了缓存)。
// 删除缓存,则下次读取时自然会从数据库加载最新数据,保证最终一致性。
}
流程图:
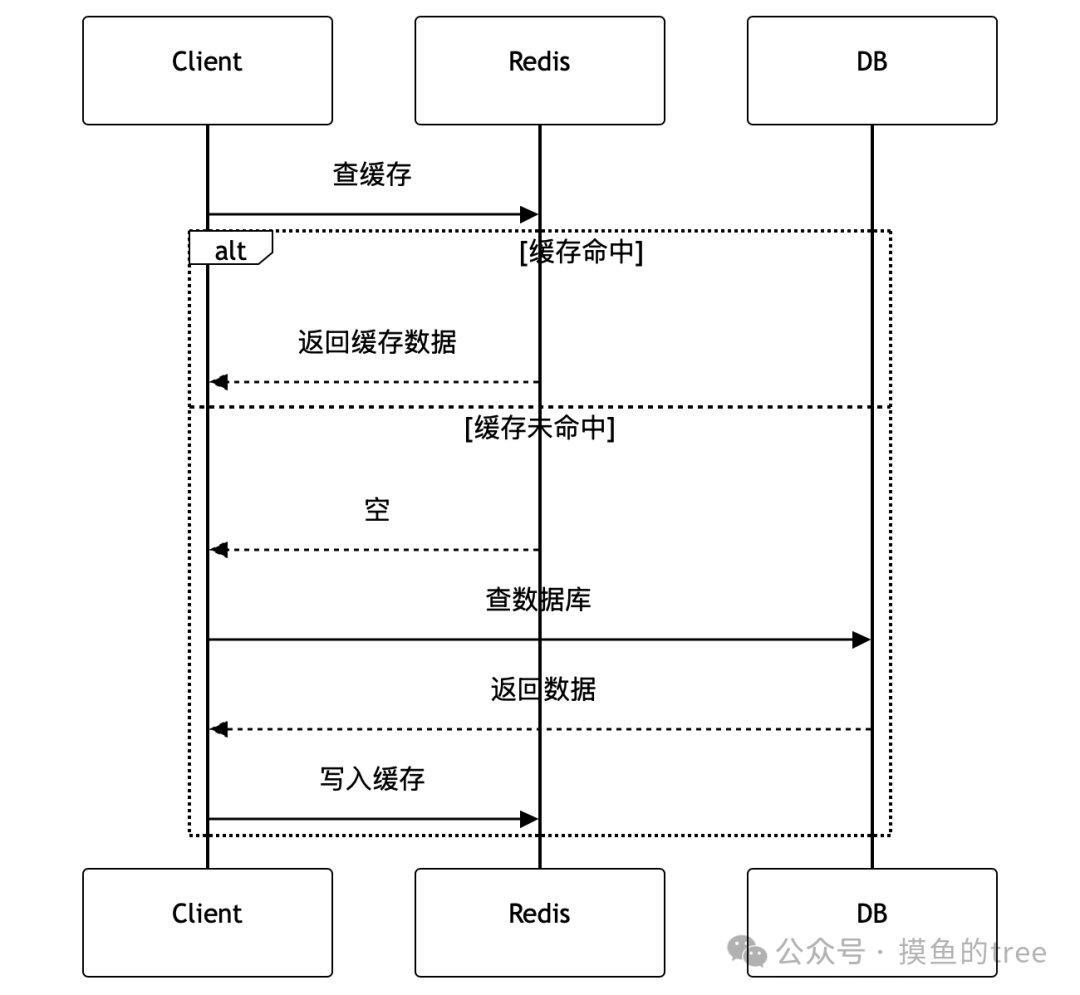
3.2 Read-Through(读穿透)
与Cache-Aside类似,但应用程序只与缓存交互。当缓存未命中时,缓存组件自身负责从数据库加载数据并填充缓存。对应用透明,如Spring Cache。
@Cacheable(value = "users", key = "#userId")
public User getUserById(Long userId) {
// 只有在缓存未命中时,这个方法才会被执行
return userRepository.findById(userId);
}
3.3 Write-Through(写穿透)
应用程序写数据时,同时写入缓存和数据库,且由缓存组件保证这两个写操作的原子性。数据一致性高,但写延迟增加。
public void saveUser(User user) {
// 1. 先写缓存
String cacheKey = "user:" + user.getId();
redisTemplate.opsForValue().set(cacheKey, JSON.toJSONString(user));
// 2. 再写数据库
userRepository.save(user);
}
3.4 Write-Behind(异步写入)
应用程序写数据时,只更新缓存,然后异步批量地将缓存数据持久化到数据库。性能极高,但存在数据丢失风险(缓存宕机)。
public void saveUser(User user) {
// 1. 只写缓存
String cacheKey = "user:" + user.getId();
redisTemplate.opsForValue().set(cacheKey, JSON.toJSONString(user));
// 2. 异步写数据库(例如通过消息队列)
messageQueue.send("user:save", user);
}
| 策略对比: |
策略 |
优点 |
缺点 |
适用场景 |
| Cache-Aside |
简单,灵活,兼容性好 |
存在并发一致性问题 |
绝大多数场景 |
| Read-Through |
对应用透明,代码简洁 |
依赖缓存组件能力 |
读多写少 |
| Write-Through |
数据一致性高 |
写延迟较高,性能一般 |
对数据一致性要求极高的场景 |
| Write-Behind |
写入性能极高 |
可能丢失数据,实现复杂 |
允许最终一致性的高写入场景(如计数、日志) |
04. 缓存问题——面试必问
使用缓存时,有三个经典问题必须面对:缓存穿透、缓存击穿、缓存雪崩。
4.1 缓存穿透——查不到还一直查
问题:查询一个数据库中根本不存在的数据,缓存中自然也没有。导致每次请求都直接穿透到数据库,可能压垮DB。
解决方案:
- 缓存空值:即使数据库没查到,也将一个标识(如
“NULL”)写入缓存,并设置一个较短的过期时间。
- 布隆过滤器:在查询缓存前,先用布隆过滤器判断Key是否可能存在。如果布隆过滤器说“不存在”,则一定不存在,直接返回。
// 方案1:缓存空值
public User getUserById(Long userId) {
String cacheKey = "user:" + userId;
String cached = redisTemplate.opsForValue().get(cacheKey);
if (cached != null) {
if ("NULL".equals(cached)) {
return null; // 缓存了空值
}
return JSON.parseObject(cached, User.class);
}
User user = userRepository.findById(userId);
if (user != null) {
redisTemplate.opsForValue().set(cacheKey, JSON.toJSONString(user), Duration.ofHours(1));
} else {
// 缓存空值,设置短过期时间(如5分钟)
redisTemplate.opsForValue().set(cacheKey, "NULL", Duration.ofMinutes(5));
}
return user;
}
// 方案2:布隆过滤器(伪代码示意)
@Configuration
public class BloomFilterConfig {
@Bean
public RedisBloomFilter<String> bloomFilter() {
// 预期数据量:1000万,误判率:0.01
return new RedisBloomFilter<>(10_000_000, 0.01);
}
}
public User getUserByIdWithBloom(Long userId) {
String key = "user:" + userId;
// 先检查布隆过滤器
if (!bloomFilter.mightExist(key)) {
return null; // 肯定不存在
}
// 再走正常的缓存/数据库查询流程
// ...
}
4.2 缓存击穿——热点 key 失效
问题:一个热点Key在缓存中过期的瞬间,大量并发请求同时发现缓存失效,全部涌向数据库,造成数据库瞬时压力过大。
解决方案:
- 分布式锁:只允许一个请求去数据库查询并回填缓存,其他请求等待或重试。
- 逻辑过期:缓存不设置物理过期时间,而是将过期时间存在Value里。发现逻辑过期后,异步更新缓存,并返回旧数据。
// 方案1:分布式锁(推荐)
public User getUserByIdWithLock(Long userId) throws InterruptedException {
String cacheKey = "user:" + userId;
String cached = redisTemplate.opsForValue().get(cacheKey);
if (cached != null && !"NULL".equals(cached)) {
return JSON.parseObject(cached, User.class);
}
// 获取锁,只允许一个请求查数据库
String lockKey = "lock:user:" + userId;
Boolean acquired = redisTemplate.opsForValue()
.setIfAbsent(lockKey, "1", Duration.ofSeconds(10)); // SET NX PX
if (Boolean.TRUE.equals(acquired)) {
try {
// 双重检查:拿到锁后再次确认缓存是否已被其他线程填充
cached = redisTemplate.opsForValue().get(cacheKey);
if (cached != null && !"NULL".equals(cached)) {
return JSON.parseObject(cached, User.class);
}
// 查数据库
User user = userRepository.findById(userId);
if (user != null) {
redisTemplate.opsForValue().set(cacheKey, JSON.toJSONString(user), Duration.ofHours(1));
} else {
redisTemplate.opsForValue().set(cacheKey, "NULL", Duration.ofMinutes(5));
}
return user;
} finally {
redisTemplate.delete(lockKey); // 释放锁
}
} else {
// 没拿到锁,短暂等待后重试
Thread.sleep(50);
return getUserByIdWithLock(userId);
}
}
4.3 缓存雪崩——大量 key 同时失效
问题:大量缓存Key在同一时间集中过期,导致所有对应请求在短时间内全部穿透到数据库。
解决方案:
- 随机过期时间:为缓存Key的过期时间加上一个随机值,避免同时过期。
- Redis集群:通过集群将数据分散,降低单点故障影响。
- 多级缓存:引入本地缓存(如Caffeine)作为二级缓存。
- 永不失效:结合“逻辑过期”策略,后台异步更新。
// 方案1:随机过期时间
public void setCacheWithRandomExpire(String key, Object value) {
// 基础过期时间 1 小时,加随机偏移量(0-30 分钟)
int randomMinutes = new Random().nextInt(30);
redisTemplate.opsForValue().set(key, value,
Duration.ofMinutes(60 + randomMinutes));
}
05. 分布式锁——Redis 的杀手锏
在单机多线程环境下,我们可以用 synchronized 或 ReentrantLock。但在分布式系统中,多个服务实例部署在不同机器上,就需要一个跨JVM的锁机制,这就是分布式锁。
5.1 Redis 分布式锁基本原理
核心命令:SET lock_key unique_value NX PX expire_time
NX:仅当Key不存在时才设置,保证互斥性。PX:设置过期时间,防止锁持有者崩溃导致死锁。unique_value:唯一标识(如UUID),确保只有锁的持有者才能释放。
@Service
public class RedisLockService {
@Autowired
private StringRedisTemplate redisTemplate;
/**
* 获取锁
* @param lockKey 锁的 key
* @param requestId 唯一标识(UUID)
* @param expireTime 过期时间(毫秒)
* @return 是否获取成功
*/
public boolean tryLock(String lockKey, String requestId, long expireTime) {
// SET key value NX PX expireTime
Boolean result = redisTemplate.opsForValue()
.setIfAbsent(lockKey, requestId, Duration.ofMillis(expireTime));
return Boolean.TRUE.equals(result);
}
/**
* 释放锁(Lua脚本保证原子性)
* @param lockKey 锁的 key
* @param requestId 唯一标识
*/
public void releaseLock(String lockKey, String requestId) {
// Lua 脚本:只有持有锁的请求才能释放
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then " +
"return redis.call('del', KEYS[1]) else return 0 end";
redisTemplate.execute(
new DefaultRedisScript<>(script, Long.class),
Collections.singletonList(lockKey),
requestId
);
}
}
5.2 使用示例:秒杀扣库存
@Service
public class OrderService {
@Autowired
private RedisLockService lockService;
@Autowired
private StockService stockService;
public void createOrder(Long productId, Integer quantity) {
String lockKey = "lock:stock:" + productId;
String requestId = UUID.randomUUID().toString();
try {
// 尝试获取锁(10秒过期)
boolean acquired = lockService.tryLock(lockKey, requestId, 10_000);
if (!acquired) {
throw new RuntimeException("系统繁忙,请稍后重试");
}
// 1. 检查库存
Integer stock = stockService.getStock(productId);
if (stock < quantity) {
throw new RuntimeException("库存不足");
}
// 2. 扣减库存
stockService.decreaseStock(productId, quantity);
// 3. 创建订单...
} finally {
// 释放锁
lockService.releaseLock(lockKey, requestId);
}
}
}
5.3 Redis 分布式锁的进阶问题与解决方案
面试官:Redis分布式锁有什么缺陷?
问题 1:单点故障
如果Redis主节点宕机,锁将丢失。即使有主从复制,主从同步是异步的,在主节点获取锁后宕机,可能导致锁在从节点上未同步,从而出现多个客户端同时持有锁。
解决方案:RedLock算法。在多个独立的Redis实例上尝试获取锁,当且仅当从大多数(N/2+1)实例上获取到锁,并且总耗时小于锁的过期时间时,才认为获取成功。
问题 2:可重入性
同一个线程内,如果方法A获取了锁,方法A又调用了也需要同一把锁的方法B,就会造成死锁。
解决方案:在客户端记录重入次数。可以使用ThreadLocal,或者直接使用成熟的客户端如Redisson,它内置了可重入锁的实现。
问题 3:锁自动过期,业务未执行完
如果业务执行时间超过了锁的过期时间,锁会自动释放,可能导致其他线程进入临界区,造成数据混乱。
解决方案:Watchdog(看门狗)自动续期。Redisson的看门狗机制会在业务执行期间,定时(默认每10秒)检查并延长锁的持有时间,直到业务完成并主动释放锁。
// 使用Redisson框架(已解决上述大部分问题)
RLock lock = redissonClient.getLock("myLock");
lock.lock(30, TimeUnit.SECONDS); // Watchdog会自动续期
try {
// 业务逻辑
} finally {
lock.unlock();
}
06. Redis 持久化——数据怎么不丢?
Redis是内存数据库,数据保存在内存中。持久化机制保证了在服务器重启后数据不丢失。主要有两种方式:RDB和AOF。
6.1 RDB(快照)
原理:在指定时间间隔内,将内存中的数据集快照(Snapshot)写入磁盘二进制文件(dump.rdb)。
触发方式:
- 手动触发:
SAVE(阻塞)或 BGSAVE(后台异步)。
- 自动触发:在配置文件中设置规则。
# redis.conf 配置示例
save 900 1 # 900秒内至少有1个key被改变,则触发bgsave
save 300 10 # 300秒内至少有10个key被改变
save 60 10000 # 60秒内至少有10000个key被改变
优点:文件紧凑,恢复速度快,适合大规模数据恢复和备份。
缺点:可能丢失最后一次快照之后的数据(取决于备份周期)。
6.2 AOF(追加文件)
原理:记录服务器执行的所有写操作命令,并在服务器启动时重新执行这些命令来还原数据。
# redis.conf 配置
appendonly yes
appendfsync everysec # 推荐配置,每秒同步一次,平衡性能与安全
# appendfsync always # 每次写命令都同步,最安全,性能最低
# appendfsync no # 由操作系统决定何时同步,性能最好,最不安全
优点:数据安全性更高,最多丢失一秒数据。AOF文件易于理解,可手动修改(修复)。
缺点:文件体积通常比RDB大,恢复速度慢。
6.3 混合持久化(Redis 4.0+)
结合了RDB和AOF的优点。在AOF重写时,将当前内存数据以RDB格式写入AOF文件头部,后续的写操作继续以AOF格式追加。
# 开启混合持久化
aof-use-rdb-preamble yes
恢复时,先加载RDB部分,再重放AOF日志,速度和安全性兼备。
面试点:生产环境用哪种?
答:通常开启混合持久化,并定期备份RDB文件到远程存储,以应对极端情况。
07. Redis 集群——高可用怎么搞?
单机Redis存在容量和性能瓶颈。Redis提供了三种集群化方案:主从复制、Sentinel哨兵和Cluster集群。
7.1 主从复制(Replication)
一个主节点(Master)负责写,多个从节点(Slave)负责读,数据从主节点异步复制到从节点。
配置从节点:
# 在从节点的 redis.conf 中配置
replicaof 192.168.1.100 6379
Java客户端配置读写分离:
@Bean
public RedisConnectionFactory redisConnectionFactory() {
RedisStandaloneConfiguration config = new RedisStandaloneConfiguration("192.168.1.100", 6379);
LettuceClientConfiguration clientConfig = LettuceClientConfiguration.builder()
.readFrom(ReadFrom.REPLICA_PREFERRED) // 优先读从节点
.build();
return new LettuceConnectionFactory(config, clientConfig);
}
缺点:主节点故障需要手动切换。
7.2 Sentinel(哨兵)—— 自动故障转移
哨兵是一个分布式系统,用于监控主从节点,并在主节点故障时,自动将一个从节点升级为新主节点,并通知客户端。
哨兵配置(sentinel.conf):
sentinel monitor mymaster 192.168.1.100 6379 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
Java客户端连接Sentinel:
@Bean
public RedisConnectionFactory redisConnectionFactory() {
RedisSentinelConfiguration config = new RedisSentinelConfiguration()
.master("mymaster")
.sentinel("192.168.1.101", 26379)
.sentinel("192.168.1.102", 26379);
return new LettuceConnectionFactory(config);
}
7.3 Cluster(集群)—— 数据分片
Redis官方提供的分布式解决方案。采用无中心结构,数据按槽(slot,共16384个) 分布在不同节点上,支持在线水平扩容。
创建集群(3主3从):
redis-cli --cluster create \
192.168.1.101:6379 \
192.168.1.102:6379 \
192.168.1.103:6379 \
192.168.1.104:6379 \
192.168.1.105:6379 \
192.168.1.106:6379 \
--cluster-replicas 1
Java客户端连接Cluster:
@Bean
public RedisConnectionFactory redisConnectionFactory() {
RedisClusterConfiguration config = new RedisClusterConfiguration();
config.addNode("192.168.1.101", 6379);
config.addNode("192.168.1.102", 6379);
// ... 添加所有节点
return new LettuceConnectionFactory(config);
}
08. Redis 性能优化——怎么更快?
8.1 内存优化与淘汰策略
防止内存被撑爆,必须设置最大内存和淘汰策略。
# redis.conf
maxmemory 2gb
maxmemory-policy allkeys-lru # 推荐:当内存不足时,移除最近最少使用的key
其他策略:volatile-lru(只淘汰带过期时间的Key)、allkeys-random、volatile-ttl(淘汰剩余时间最短的)等。
8.2 Pipeline(管道)
将多个命令打包一次发送,减少网络往返延迟(RTT),显著提升批量操作的性能。
// 普通方式:10次网络往返
for (int i = 0; i < 10; i++) {
redisTemplate.opsForValue().increment("counter");
}
// Pipeline方式:1次网络往返
List<Object> results = redisTemplate.executePipelined((RedisCallback<Object>) connection -> {
for (int i = 0; i < 10; i++) {
connection.stringCommands().incr("counter".getBytes());
}
return null;
});
8.3 Lua 脚本
Lua脚本在Redis中原子性执行,可用于实现复杂的原子操作,避免竞态条件。
// Lua 脚本:原子性扣减库存
String luaScript = "local stock = redis.call('get', KEYS[1]) " +
"if tonumber(stock) >= tonumber(ARGV[1]) then " +
" return redis.call('decrby', KEYS[1], ARGV[1]) " +
"else " +
" return -1 " +
"end";
Long result = redisTemplate.execute(
new DefaultRedisScript<>(luaScript, Long.class),
Collections.singletonList("stock:product:001"),
"10" // 扣减数量
);
if (result == -1) {
throw new RuntimeException("库存不足");
}
09. 常见面试问题汇总
Q1:Redis 和 Memcached 有什么区别?
| 对比项 |
Redis |
Memcached |
| 数据结构 |
丰富(5种基础+扩展) |
仅Key-Value字符串 |
| 持久化 |
支持(RDB/AOF) |
不支持 |
| 集群模式 |
原生支持Cluster、Sentinel |
客户端实现分布式 |
| 线程模型 |
单线程(主处理逻辑) |
多线程 |
| 适用场景 |
缓存、消息队列、分布式锁等 |
纯缓存 |
Q2:Redis 为什么快?
- 基于内存操作。
- 单线程模型,避免上下文切换和锁竞争。
- IO多路复用(epoll/kqueue),高效处理大量连接。
- 使用高效的数据结构,如跳表、压缩列表。
Q3:Redis 内存满了怎么办?
- 使用
maxmemory-policy 配置内存淘汰策略。
- 分析内存使用(
redis-cli --bigkeys),优化数据结构。
- 对Value进行压缩。
- 搭建Redis集群,进行数据分片。
Q4:如何保证 Redis 和数据库的数据一致性?
| 这是一个权衡问题,没有银弹。 |
方案 |
一致性 |
性能 |
复杂度 |
| 先更库,再删缓 |
最终一致 |
高 |
低(推荐) |
| 延迟双删(更库→删缓→延迟→再删缓) |
更好 |
中 |
中 |
| 订阅数据库Binlog(如Canal) |
最终一致 |
高 |
高 |
| 分布式事务(如XA) |
强一致 |
低 |
高 |
最佳实践:对于大多数业务,采用 Cache-Aside + 先更新数据库再删除缓存 的策略,并接受秒级的最终一致性。对于极强一致性要求,可考虑使用分布式事务,但需承受性能代价。
Q5:Redis 集群怎么保证数据一致?
Redis主从复制是异步的,默认不保证强一致。
- 强一致性:使用
WAIT 命令,等待写操作同步到指定数量的从节点。但会阻塞并影响性能。
- 最终一致性:异步复制是默认方式,性能好,网络分区或主节点宕机时可能丢数据。
对于高可用的分布式系统设计,通常优先保证可用性和分区容错性(CAP中的AP),接受最终一致性。
掌握以上这些核心知识点和实战代码,足以应对绝大多数与Redis面试相关的问题。技术学习永无止境,在实践中不断思考和总结才能融会贯通。欢迎到云栈社区交流讨论更多技术细节。
 发表于 2026-4-16 20:34:28
|
查看: 269|
回复: 0
发表于 2026-4-16 20:34:28
|
查看: 269|
回复: 0
