导读:分库分表解决了单表瓶颈,却带来了新问题:不带分片键的查询怎么办?本文从一条“禁止跨分片查询”的军规说起,拆解扇出放大、结果归并、分布式一致性三大核心难题,并系统梳理五种解法的适用场景和演进路径,助你在十万到千万 QPS 的不同阶段做出正确选择。
那条“不允许跨分片查询”的军规
分库分表上线的第一天,DBA 通常会在团队群里发一条公告:“分片键必须出现在每条 SQL 的 WHERE 条件里,不允许跨分片查询。”这条规则简单粗暴,但确实有效。毕竟在百万 QPS 级别的系统里,每一条 SQL 都能精确路由到某一个分片,查询性能可以做到和单表几乎一样。
可是业务从来不会只按一个维度查数据。
订单系统按用户 ID 分片,运营要查“某个商家过去 7 天的全部订单”;支付系统按支付单号分片,财务要拉“某天所有支付金额大于 1 万的流水”;IM 系统按发送者分片,客服要搜“某个群聊里所有包含关键词的消息”。这些查询没有分片键,按规矩就不能执行。
怎么办?最初的做法是告诉业务方“做不了”,让他们自己去离线数据仓库里跑。但当这类需求从每周一两个涨到每天几十个,当产品经理把“实时查询”写进需求文档,当运营在周会上抱怨“为什么我查个数据要等 T+1”的时候,你就知道,“禁止跨分片查询”这条路,迟早走不通。
今天这篇文章,就来聊聊跨分片查询这个分库分表中最棘手的问题:为什么它难,难在哪里,以及从十万 QPS 到千万 QPS 的不同阶段,分别有哪些解法。
跨分片查询为什么这么难
在聊解决方案之前,得先搞清楚这个问题的本质。单库时代,一条 SQL 发到数据库,优化器生成执行计划,存储引擎扫描数据,结果集返回客户端。整个过程在一个进程内完成,事务、排序、聚合都是数据库原生能力。
分库分表之后,数据散落在多个物理节点上。一条不带分片键的查询,中间件不知道数据在哪个分片,只能把 SQL 广播到所有分片,然后把各个分片的结果收集起来,在内存里做合并。这个过程涉及三个核心难题:

第一个难题是扇出放大。 假设系统分了 256 个分片,一条不带分片键的查询会被拆成 256 条 SQL 发到各个分片。如果系统 QPS 是 10 万,其中 5% 是跨分片查询,那就是每秒 5000 条查询被扇出成 128 万条。分片的连接池、线程池、IO 带宽,全部被成倍放大。
第二个难题是结果归并。 各分片返回的结果需要在中间层做二次处理。简单的归并还好,但如果 SQL 里有 ORDER BY、GROUP BY、DISTINCT、聚合函数、子查询,甚至是 JOIN,归并的复杂度会急剧上升。尤其是分页查询,LIMIT 10000, 20 意味着每个分片都要返回前 10020 条数据,中间层收到 256 × 10020 条记录后再做全局排序取 20 条。数据量一上来,内存直接撑爆。
第三个难题是分布式一致性。 跨分片的写操作涉及分布式事务,读操作如果要求强一致性,也需要考虑各分片之间的数据同步延迟。在千万 QPS 级别,这些延迟和不一致会被放大到业务可感知的程度。
跨分片查询的本质困难在于:分库分表把数据的物理分布和业务的查询模式解耦了,而跨分片查询就是在试图重新建立这种耦合。
五种解法的演进路线
面对跨分片查询,业界不是一步到位找到了最终方案,而是随着业务规模的增长,经历了一条清晰的演进路线。从最简单的“绕开问题”到最复杂的“正面解决”,每一步都是在“查询能力”和“系统复杂度”之间做权衡。
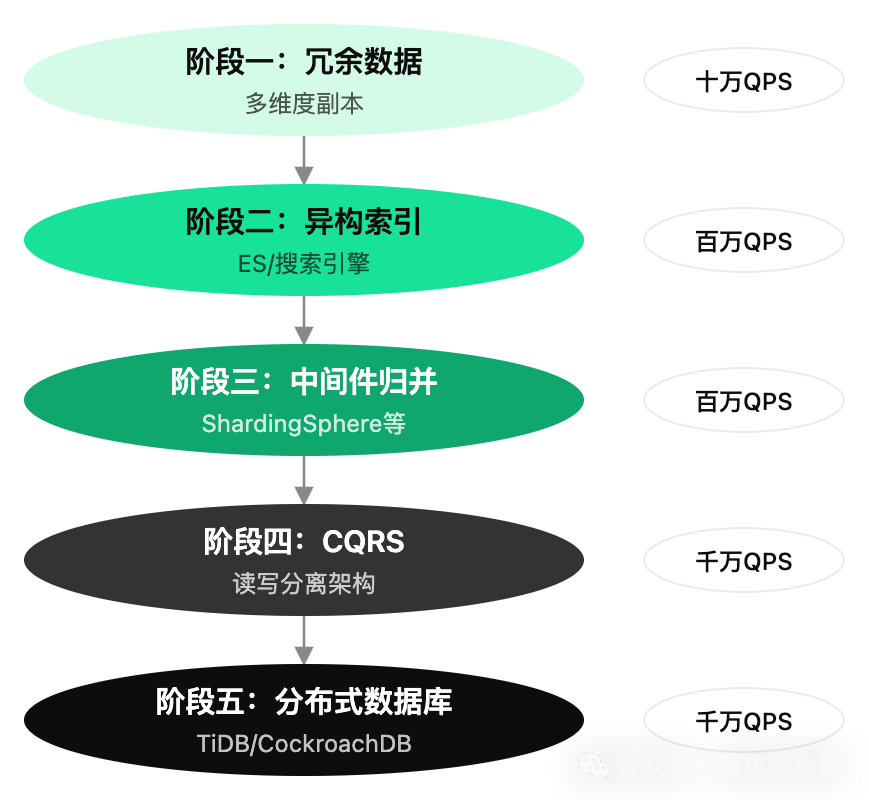
下面逐一展开。
阶段一:冗余数据,用空间换查询能力
最朴素的思路:既然按用户 ID 分片后没法按商家 ID 查,那就再按商家 ID 建一份副本。
具体做法是,在写入订单时,除了写入按用户 ID 分片的主表,同时异步写入一张按商家 ID 分片的副表。运营查商家维度的数据时,直接走副表,查询路由和主表一样简单,不需要跨分片。
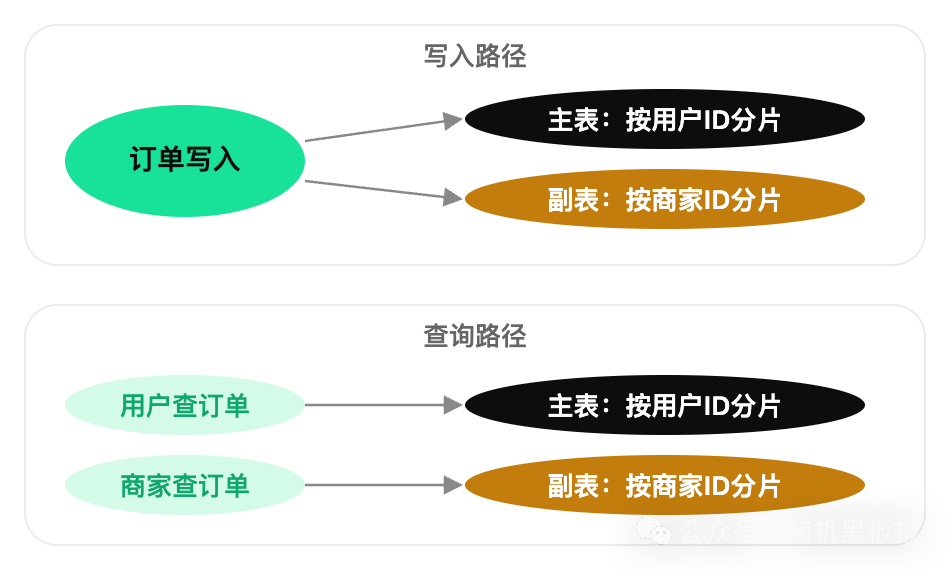
这种方案的优点是查询性能和单表无异,实现也简单。但缺点同样明显:

冗余数据方案的本质是把“运行时的计算问题”转化为“存储时的空间问题”,在查询维度有限的场景下是最简单有效的解法。
在十万 QPS 级别,查询维度通常只有 2~3 个,冗余数据完全扛得住。但当业务发展到需要支持全文搜索、多字段组合筛选、范围查询的时候,你不可能为每种查询组合都建一份副本。这时候就需要更通用的方案。
阶段二:异构索引,把搜索引擎当二级索引用
既然需要灵活的多维度查询,而关系型数据库天然不擅长这个,那就引入一个擅长的组件:搜索引擎。
最常见的做法是引入 Elasticsearch。写入数据时,除了写主库,同时把需要被检索的字段同步到 ES。业务方的复杂查询(多字段组合、全文搜索、范围筛选、聚合统计)全部走 ES,ES 返回命中的主键列表,再回主库查完整数据。
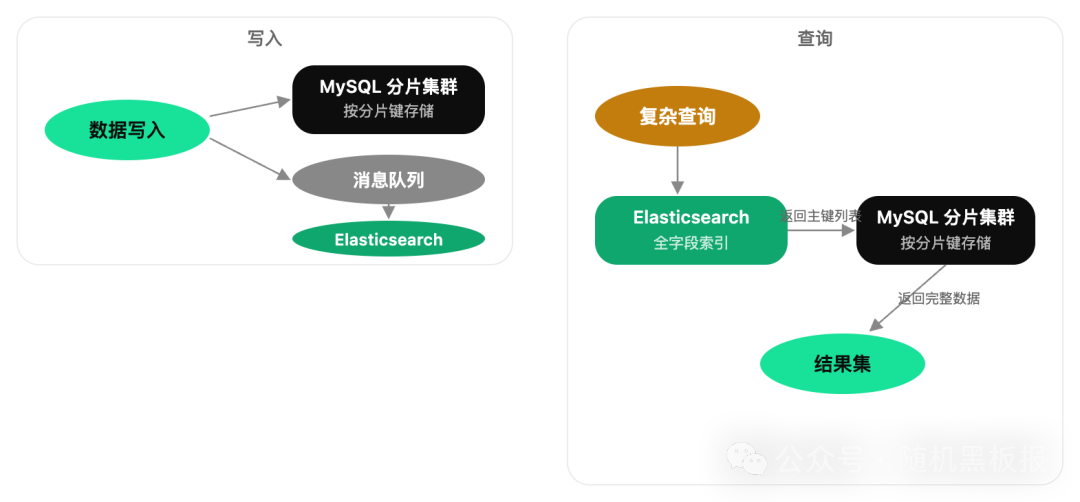
这套架构在百万 QPS 级别的系统中非常普遍,电商的商品搜索、订单搜索,社交平台的消息搜索,几乎都是这个模式。它的核心优势在于:
查询灵活性极高:ES 天然支持多维度组合查询、全文搜索、聚合分析
不影响主库性能:复杂查询全部卸载到 ES,主库只承担主键查询
水平扩展能力强:ES 集群本身支持分片和副本,扩容方便
但这个方案也有它的代价:

这里有一个容易踩的坑:回查放大问题。假设 ES 查到 1000 条匹配记录,这 1000 个主键散布在不同的分片上。回查 MySQL 分片集群 时,如果不做优化,就是 1000 次单条查询,或者按分片键分组后做批量查询。无论哪种方式,当命中量级从百级涨到万级时,回查耗时会急剧上升。
解决回查放大的常见手段有两个:
一是宽索引策略。 在 ES 中存储更多的字段,甚至存储完整的业务数据。这样大部分查询不需要回查 MySQL,直接从 ES 返回结果。代价是 ES 的存储成本上升,索引更新的数据量也更大。
二是查询结果缓存。 对于高频的查询模式,在 ES 和 MySQL 之间加一层缓存。命中缓存直接返回,没命中再回查。这对于运营后台这类查询模式相对固定的场景特别有效。
异构索引方案的核心思路是“查询能力外包”:把关系型数据库不擅长的复杂查询交给专业的搜索引擎,通过异步同步保持数据一致性。
阶段三:中间件归并,让跨分片查询“透明化”
前两种方案都是绕开跨分片查询,要么冗余数据,要么引入外部索引。但有些场景绕不开,比如:事务性的跨分片写入、需要强一致性的跨分片读取、复杂的跨分片 JOIN。这时候就需要中间件来正面解决问题。
分库分表中间件(如 ShardingSphere、Vitess、MyCAT)的核心能力之一就是跨分片查询的自动路由和结果归并。应用层写的是普通 SQL,中间件负责解析 SQL、确定目标分片、分发查询、收集结果、做内存归并,最后返回给应用层一个看起来和单库查询没区别的结果集。
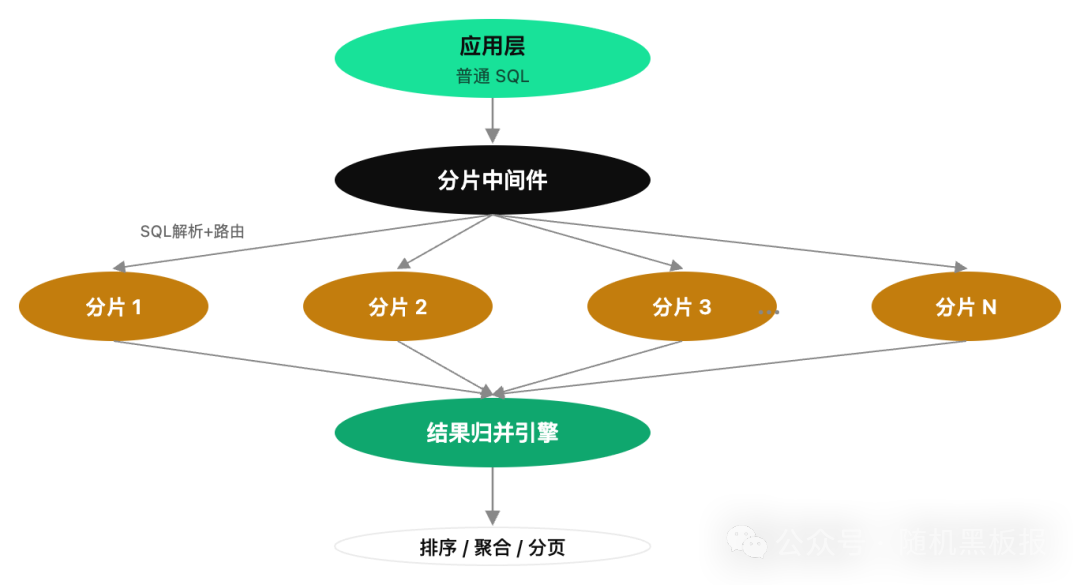
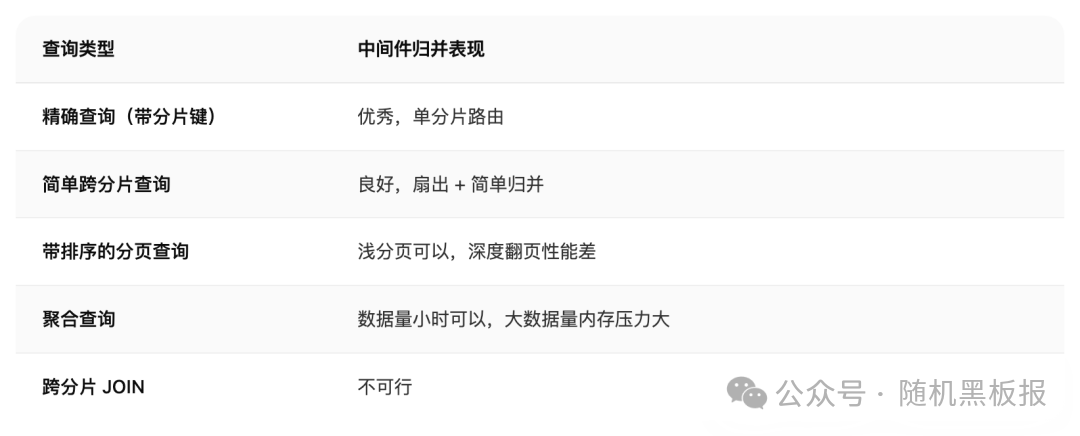
中间件归并看起来很美好,对应用层完全透明,但它面临的性能挑战不容小觑:
分页查询的深度翻页问题
假设有 256 个分片,SQL 是 SELECT * FROM orders ORDER BY create_time DESC LIMIT 100000, 20。中间件需要让每个分片都返回前 100020 条数据,然后在内存中对 256 × 100020 = 2560 万条记录做全局排序,取第 100001 到 100020 条。
这种深度翻页在百万 QPS 级别就已经是性能杀手了。常见的优化策略有:
游标分页:用上一页最后一条记录的排序字段值作为下一页的起始条件,避免 OFFSET。比如 WHERE create_time < ‘2024-03-15 10:00:00‘ ORDER BY create_time DESC LIMIT 20,每个分片只需返回 20 条
禁止深度翻页:产品层面限制翻页深度,超过一定页数要求用户缩小查询范围
预计算:对于固定的排行榜类需求,定时计算并缓存结果
聚合查询的内存压力
SELECT merchant_id, COUNT(*), SUM(amount) FROM orders GROUP BY merchant_id 这条 SQL 在 256 个分片上各执行一次,每个分片可能返回上万个商家的聚合结果。中间件需要在内存里做二次聚合,数据量可能达到 GB 级别。
JOIN 查询几乎不可行
跨分片 JOIN 需要把一张表的数据拉到另一张表所在的分片上做关联,或者在中间件内存里做 Hash JOIN。在数据量大的场景下,这两种方式都不现实。这也是为什么分库分表的系统设计中,有一条几乎不成文的规矩:所有 JOIN 必须在同一个分片内完成,跨分片 JOIN 不是“不推荐”,而是“不要做”。
中间件归并方案的适用边界很清晰:
阶段四:CQRS,读写分离的终极形态
当系统规模到了千万 QPS,前面三种方案往往需要组合使用,但组合的结果是系统复杂度急剧上升。这时候需要在架构层面做一次根本性的调整:CQRS(Command Query Responsibility Segregation),命令查询职责分离。
CQRS 的核心思想很朴素:写操作和读操作的需求完全不同,那就让它们走完全不同的技术栈。
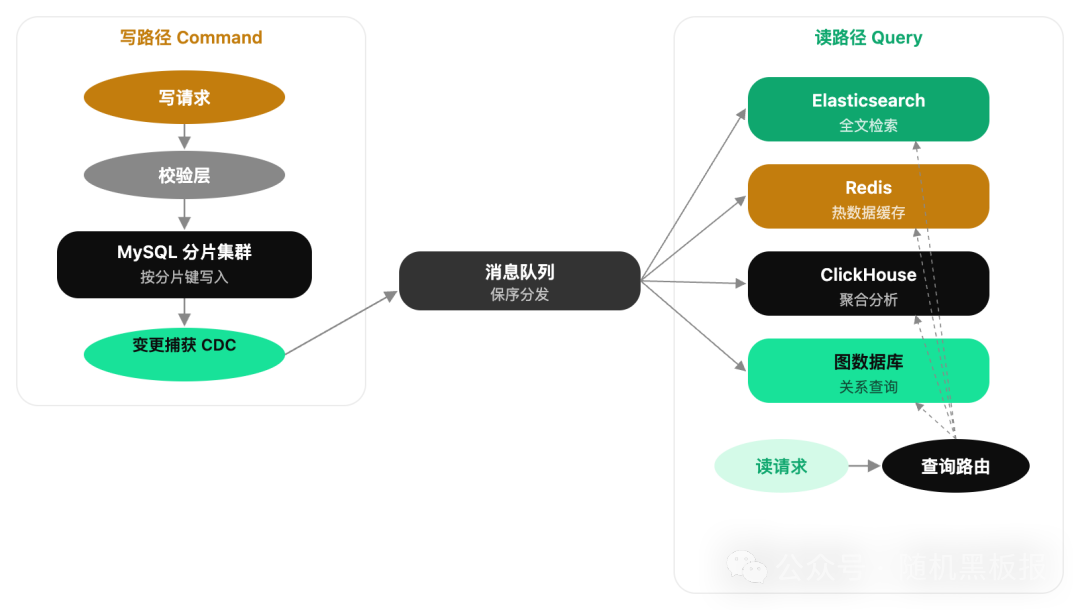
写路径只关注数据完整性和分片键路由,保持最简的写入逻辑。所有写入产生的变更通过 CDC(Change Data Capture)捕获,经由消息队列分发到多个读侧存储引擎。每个读侧引擎针对特定的查询场景做了优化:
ES:处理全文搜索和多维度组合查询
Redis:承载热数据的点查和缓存
ClickHouse:处理大数据量的聚合分析
图数据库:处理复杂的关系查询
读请求根据查询类型路由到最合适的引擎。一条复杂查询不再是“跨分片查询”,而是直接在一个为该查询模式优化过的存储引擎上执行,天然不需要跨分片。
CQRS 架构的核心优势在于:
一是彻底消除了跨分片查询。 每个读侧存储都是按照查询需求组织数据的,不存在“分片键”的限制。ES 可以按任意字段检索,ClickHouse 可以按任意维度聚合,Redis 可以按任意键查询。
二是读写独立扩展。 写路径的瓶颈在 MySQL 的写入吞吐,读路径的瓶颈在各引擎的查询容量。两者互不影响,可以独立扩容。在千万 QPS 的系统中,读写比通常在 10:1 到 100:1 之间,读侧需要的扩展能力远大于写侧。
三是读侧可以随时演进。 如果新增了一种查询需求,只需要新增一个消费者,把数据同步到新的存储引擎即可,不需要动写路径的任何代码。
但 CQRS 的代价也是实实在在的:

CQRS 不是一个技术方案,而是一种架构哲学:承认没有一种存储能完美满足所有查询需求,用“正确的工具做正确的事”来替代“一个工具做所有事”。
这里有一个经常被忽略的点:CQRS 并不意味着要一步到位搭建上面画的那种全套架构。大多数团队的演进路径是:先引入 ES 做搜索(阶段二),发现效果不错,再加上 Redis 做缓存,后来又加了 ClickHouse 做分析。回过头来看,这不就是自然演化成了 CQRS 吗?所以 与其说 CQRS 是一个被设计出来的架构,不如说它是一个被演进出来的架构。
阶段五:分布式数据库,从根本上消灭问题
如果说前面四种方案都是在分库分表的框架内“打补丁”,那么分布式数据库则是换了一条路:从根本上消灭“分片”这个概念对业务的影响。
TiDB、CockroachDB、YugabyteDB 这类分布式数据库的核心理念是:数据在底层确实是分片存储的,但这个分片对应用层完全透明。 应用层写的是标准 SQL,分布式数据库的优化器会自动决定如何路由、如何归并、如何做分布式事务。
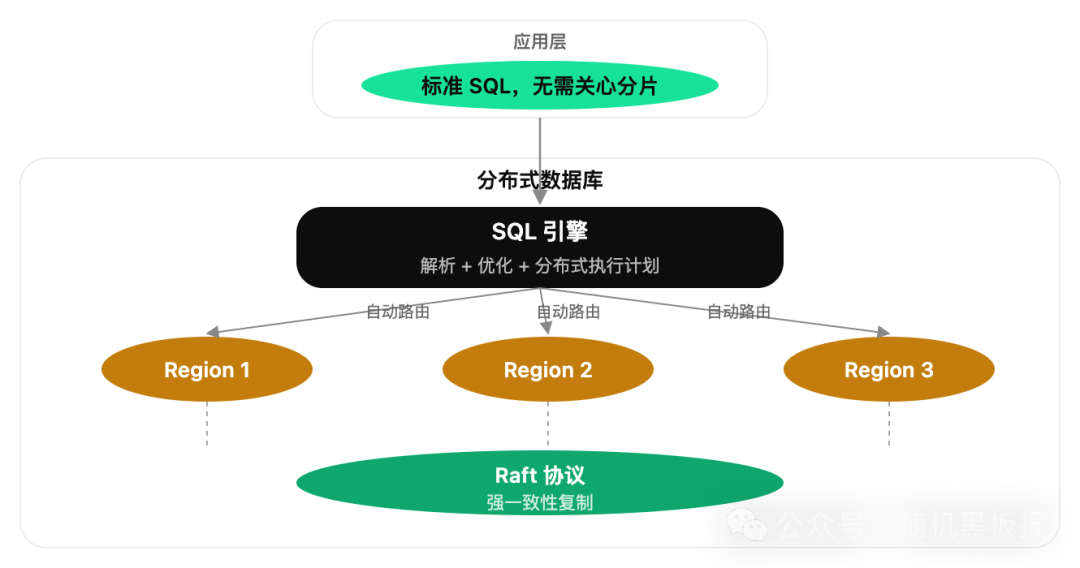
以 TiDB 为例,它的架构可以这样理解:
TiDB Server:无状态的 SQL 解析层,负责接收 SQL、生成分布式执行计划、协调各节点执行。水平扩展,加机器就能提升 QPS
TiKV:分布式 KV 存储层,数据按 Region(默认 96MB)自动分片,Region 之间通过 Raft 协议保证强一致性。自动分裂、自动迁移、自动负载均衡
PD(Placement Driver):调度中心,负责 Region 的分配和负载均衡
这种架构下,“跨分片查询”对应用层来说根本不存在。你写一条 SELECT * FROM orders WHERE merchant_id = 12345 ORDER BY create_time DESC LIMIT 20,TiDB 的优化器会自动判断需要扫描哪些 Region,如何并行执行,如何归并结果。应用层完全不需要知道数据分布在哪里。
但分布式数据库也不是银弹。在千万 QPS 场景下,它面临几个现实挑战:
一是分布式事务的延迟开销。 TiDB 使用 Percolator 模型实现分布式事务,每个事务需要至少两次 Raft 写入(Prewrite + Commit)。跨 Region 事务的延迟通常在 10~30ms,而分库分表方案中单分片事务可以做到 1~3ms。在对延迟极其敏感的核心交易路径上,这个差距会影响用户体验。
二是复杂查询的优化器成熟度。 分布式数据库的优化器需要处理分布式执行计划,比单机优化器复杂得多。在某些复杂 SQL 场景下(多表 JOIN、嵌套子查询、复杂聚合),优化器生成的执行计划可能不是最优的,需要手动加 Hint 调优。
三是运维复杂度。 分布式数据库虽然对应用层透明,但对运维团队来说并不简单。Region 的自动分裂和迁移、热点 Region 的处理、慢查询的诊断(涉及多节点),都需要专门的运维能力。

分布式数据库并不是要取代分库分表,而是提供了另一条路径:如果你的系统需要频繁的跨分片查询和分布式事务,而且对延迟的要求不是极端苛刻,分布式数据库可能是更好的选择。
在实际工程中,很多千万 QPS 级别的系统是混合使用的:核心交易路径用分库分表(追求极致延迟),复杂查询和分析场景用分布式数据库或 CQRS 架构(追求查询灵活性)。
不同规模下的选型策略
回过头来看这五种方案,它们不是非此即彼的关系,而是在不同规模和场景下的最优选择。选型的核心维度有三个:系统 QPS、查询复杂度、一致性要求。
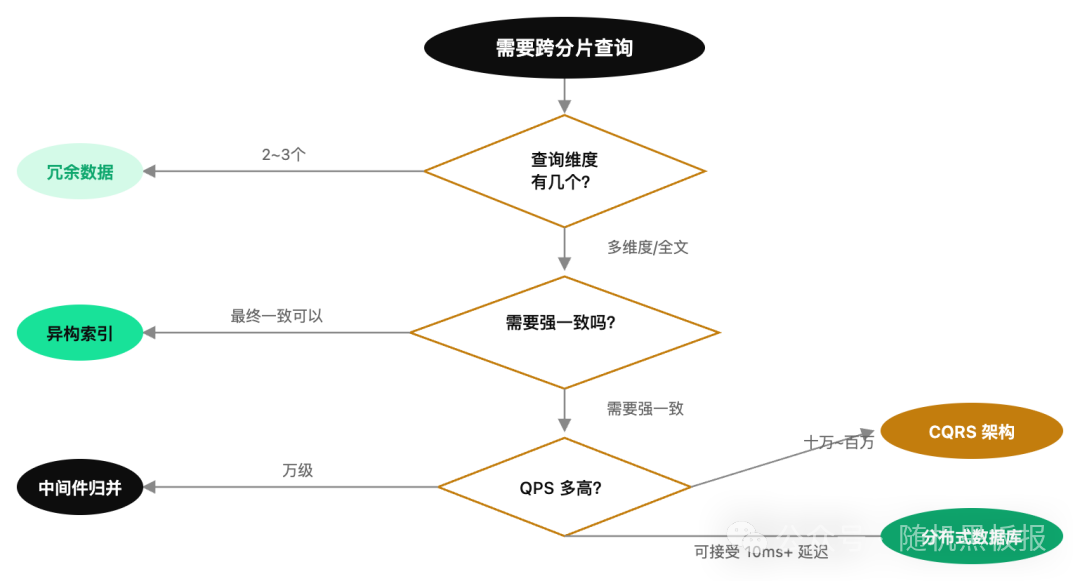
给出一些经验性的建议:
十万 QPS 以下:优先考虑冗余数据方案。实现简单,运维成本低,查询性能好。如果跨分片查询的需求不多,这就够了。
百万 QPS 级别:引入 ES 做异构索引,配合中间件处理简单的跨分片查询。这是大部分互联网公司的标准配置。
千万 QPS 级别:CQRS 架构几乎是必选项。核心交易路径保持分片键路由,复杂查询分流到专门的读侧引擎。如果新建系统,可以直接评估分布式数据库。
有一点需要特别强调:跨分片查询的最优解不是找到一个万能方案,而是在系统设计阶段就把查询需求和数据模型放在一起考虑,让大部分查询都不需要跨分片。
好的分片键设计能消灭 80% 的跨分片查询需求。剩下的 20%,根据具体场景选择上述方案中的一种或几种组合。
从“禁止”到“支持”,变的不只是技术
回顾跨分片查询的演进历程,从最初的“一律禁止”到如今的“按需支持”,表面上看是技术方案的进化,更深层的变化是工程团队对“数据访问”这件事的理解在不断加深。
在系统规模小的时候,一个分片键就能满足绝大部分查询需求,“禁止跨分片”是性价比最高的选择。但当业务复杂度上升、数据维度增多、查询模式多样化之后,数据的使用方式已经远远超出了单一分片键能覆盖的范围。
这个演进过程中有一个不变的原则:数据的物理分布应该服务于业务的访问模式,而不是反过来让业务去适应数据的物理分布。
冗余数据是让数据按多种方式分布;异构索引是让数据在不同引擎里以不同方式组织;CQRS 是让读写各自按照最优的方式存储和查询;分布式数据库则是让物理分布对业务完全透明。手段不同,方向一致。
在你自己的系统中,跨分片查询的解法不需要一步到位。先把分片键设计好,能不跨分片就不跨分片。当跨分片需求出现时,从最简单的冗余数据开始,随着业务规模的增长自然演进。每一步都有明确的触发条件和回报,不需要在十万 QPS 的时候就为千万 QPS 的场景买单。
最后留一个思考题:如果你的系统同时有强一致性要求和复杂查询需求,在 CQRS(最终一致)和分布式数据库(强一致但延迟高)之间,你会怎么选?或者说,有没有可能把它们组合起来用?欢迎在 云栈社区 的架构版块分享你的见解。
 发表于 2026-4-20 09:16:45
|
查看: 90|
回复: 0
发表于 2026-4-20 09:16:45
|
查看: 90|
回复: 0
