为大型语言模型接入企业知识库,已成为构建智能应用的基础能力。通过检索增强生成(RAG),模型能够基于企业内部资料进行分析与作答,不再仅仅依赖于其参数记忆。
然而,在真实业务场景中,知识库很少是“纯文本”形态。越来越多的企业资产是由文档、图片、图纸、表格、音视频共同构成的复合型数据。一旦用户问题需要跨模态的联动检索与推理,传统的 RAG 方案往往会遇到明显的瓶颈。
近期,通义实验室(Tongyi Lab)开源了 VimRAG:一个面向文本、图像、视频统一处理的多模态 RAG 框架。其目标正是帮助 AI 模型在复杂、混合形态的知识库中进行更清晰、更高效的检索、记忆与推理。

真实企业知识库,难点早已不止“查文档”
以制造业为例,一个完整的知识体系可能同时包含:
- 大量的 PDF 技术资料与规范文档。
- 设计图、CAD 图纸、设备照片等视觉资料。
- 培训视频、会议录像、操作演示视频等时序内容。
在这类场景下,用户的提问往往不再是单一模态的查询,而是跨资料、跨模态的综合检索。例如:
“去年 Q3 某产品的设计变更主要有哪些?相关讨论在会议视频里是如何展开的?”
要回答这类问题,系统不仅要在 PDF 技术资料里找到相关文字描述,还要识别图纸中的变化标注、定位视频中涉及该产品操作演示的关键片段,并将这些分散在多模态内容中的证据关联起来。这对传统 RAG 的能力提出了更高的要求。
为什么多模态长上下文 RAG 难落地?
目前常见的方案大致有两类,但都存在各自的不足。
把一切都转成文本
一种做法是将图片做 OCR、视频转字幕、图纸转成描述文本,然后全部走文本检索流程。
这种方式虽然统一了流程,但问题也很明显:
- 图片中的布局、颜色、空间关系等视觉信息容易丢失。
- 图纸中的结构细节和标注层信息难以被完整表达。
- 视频中的动作、画面变化、关键时间节点难以还原。
换句话说,信息被“压平”成文本后,模型读到的只是文字描述,未必能真正理解原始内容的丰富含义。
文本、图片、视频分开查,再强行拼接
另一种做法是为不同模态分别建立索引库,分别进行检索,最后将结果拼接后交给模型。
这种方式的主要问题在于缺乏统一的推理结构,常常会出现:
- 文本中提到“见下图”,但模型找不到对应的图片证据。
- 视频里引用了某段文档内容,模型却无法将这个引用联想回原文。
- 检索过程容易重复兜圈,导致上下文越堆越乱、效率低下。
特别是在多轮 Agent 式推理中,如果只是线性地堆叠上下文,很容易出现“状态盲区”:模型记不清已经检索过什么、哪些证据是互相支持的、下一步应该继续追踪视频线索还是回查文档。
VimRAG 的思路:把线性上下文换成“动态记忆图”
VimRAG 的核心设计,不再是简单地将每次检索的结果串接起来,而是将整个推理过程组织成一张 动态记忆图。
你可以将其理解为:模型不是在“阅读一本流水账”,而是在维护一张不断生长、演化的知识路径图。这类似于人类观看一部电影时,遇到新的情节,不会去逐帧回忆所有画面,而是根据脑海中已有的“关键情节节点”与“视觉高光时刻”来理解新事件的发生。
VimRAG 借鉴了这种机制,在每一轮行动前实现多模态记忆的重构,在保留关键信息的同时,果断剪断无效的搜索分支。相比简单的上下文拼接,这种结构化的记忆方式更适合复杂问题的逐步求解。

三个关键机制,解决多模态检索中的核心问题
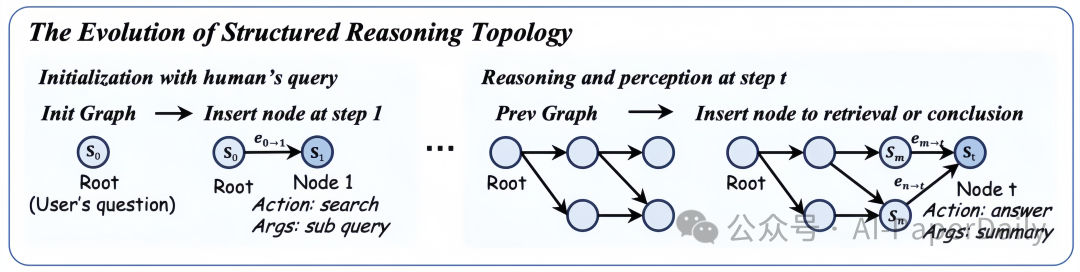
1. 动态记忆图:让探索过程可追踪、可剪枝
VimRAG 使用有向无环图(DAG)来表征推理过程。每次检索操作或信息总结都会形成一个新的节点,并与已有的相关节点建立连接。
这带来了几个直接的好处:
- 已探索路径可回看:清晰地记录了推理的历史轨迹。
- 错误方向可及时剪枝:避免在无效路径上浪费资源。
- 关键证据链可持续保留:确保重要信息不会被后续内容冲刷。
- 减少重复查询与无效循环:通过图结构避免陷入检索死循环。
简而言之,模型不再只是“想到哪查到哪”,而是在持续构建并管理一张可视化的推理地图。
2. 视觉资源按重要性分配:关键内容保真,次要内容压缩
多模态 RAG 面临的一个现实问题是:视觉信息(如图像 token、视频帧)非常占用上下文窗口。
如果每张图片、每段视频都高精度保留,计算成本会迅速上升;但如果压缩过头,又会丢失关键细节。VimRAG 对此进行了动态化处理:
- 对推理图中的关键节点,保留更多、更高精度的视觉 token。
- 对边缘或辅助节点,只保留文本摘要或低成本的语义表示。
- 对已经确认价值较低的路径,直接进行裁剪。
这种机制类似于人类处理资料时的习惯:核心材料仔细研读原件,辅助材料快速浏览摘要,毫无价值的内容则果断放弃。
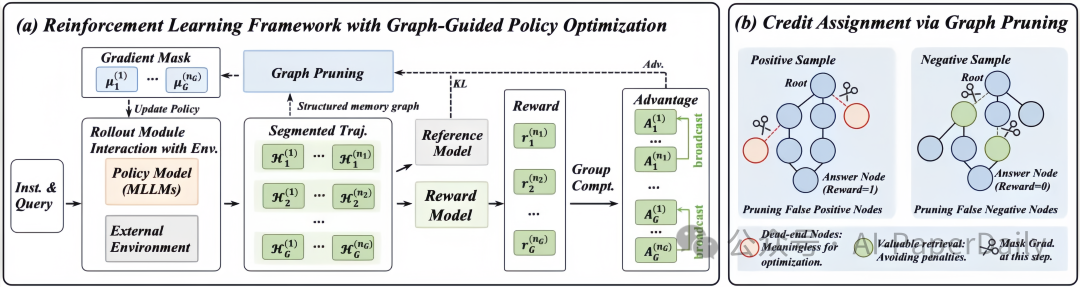
3. 图引导策略优化:让模型学会“哪些步骤真正有用”
除了改进推理结构,VimRAG 还为模型训练提出了 GGPO(Graph-Guided Policy Optimization,图引导策略优化)。
在传统的强化学习训练中,通常根据最终答案的正确与否来整体奖励或惩罚一整条行动轨迹。但在多模态检索这种多步决策场景中,这样的反馈过于粗糙:
- 有些检索步骤虽然没有直接推导出最终答案,但却是有效的铺垫和探索。
- 有些行动路径看起来热闹,实际上对解题没有实质性贡献。
GGPO 借助记忆图的结构,能够进行更细粒度的价值判断:
- 在正样本中,对“无贡献分支”进行剪枝,避免模型误学冗余动作。
- 在负样本中,对“有效检索”的中间步骤予以保留,给予部分正向信号,防止误伤。
这有助于降低训练中的不稳定性,让模型更快地学会结构化的检索与推理方式。
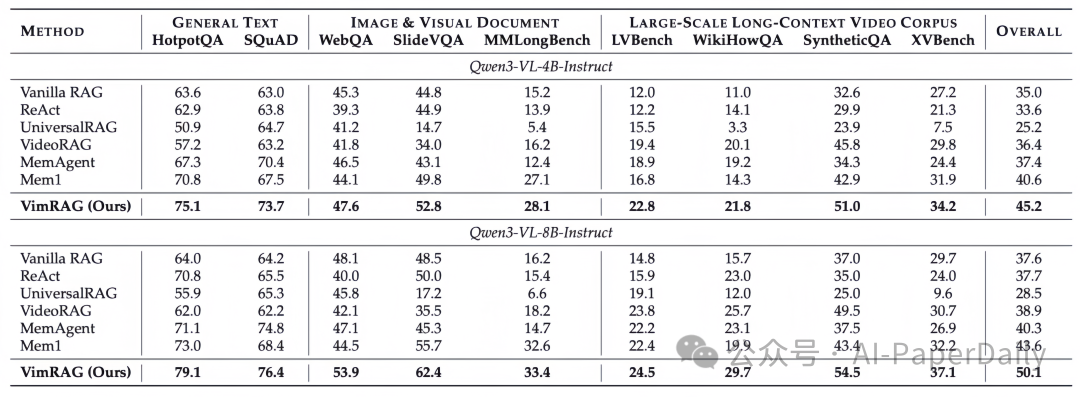
实验结果:面向统一多模态语料库进行评估
为了更贴近真实业务环境,该研究并未为不同任务单独构建知识库,而是将多种数据类型混合进同一个统一的语料库中,包括:
在这样的设定下,模型需要同时完成跨模态检索、多源证据组织以及最终的答案生成。
根据论文披露的实验结果,在 Qwen3-VL-8B 模型上,VimRAG 取得了 50.1% 的平均准确率,相比 Vanilla RAG、ReAct、VideoRAG 等多种基线方法均表现出优势,显示了其在处理多模态长上下文场景时的有效性。
从进一步的实验分析来看,VimRAG 主要体现出三方面特点:
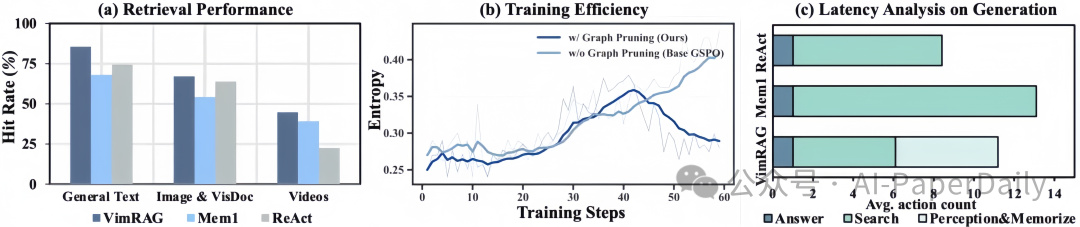
- 检索效果更强:根据图(a),VimRAG 在文本、图像/视觉文档、视频等多个类别上,整体命中率(Hit Rate)优于部分对比方法。结构化的状态建模帮助它减少了“查过又忘、忘了又查”的问题。
- 训练过程更稳:根据图(b),采用 GGPO 后,训练曲线的熵值变化更平稳,说明图结构带来的细粒度信用分配(credit assignment)对策略优化有积极作用。
- 整体推理效率更高:根据图(c),虽然 VimRAG 引入了额外的记忆管理动作,但由于有效减少了无效检索,其整体生成时延并未显著增加,在综合效率上表现更优。
一个典型案例:从课程资料中还原完整解题过程
论文中展示了一个较有代表性的跨模态查询场景:
用户提问:Dr. Smith 的微积分课程第 4 章中,关于优化问题的拉格朗日乘数法,其完整的解题流程和数学证明是什么?
这是一个典型的跨模态问题。答案可能分散在:
- 课程讲义的文本中。
- 黑板板书的截图里。
- 例题讲解的视频片段内。
- 不同章节之间概念的上下文关系中。
传统方法的困难
- 若把视频全部转为文本,其中的数学公式和板书布局细节容易丢失。
- 若分别为文本、图片、视频建立检索,再手动拼接结果,极易遗漏或错误关联关键逻辑环节。
VimRAG 的处理路径
VimRAG 并不会一开始就盲目检索全部资料,而是进行结构化的逐步探索:
- 先检查第 3 章是否相关:快速检索发现第3章内容偏重单变量微积分基础,与目标问题(多变量约束优化)关联较弱,于是将其标记为低价值路径,避免深入。
- 锁定第 4 章核心小节:进一步将搜索范围聚焦到与“约束优化”相关的 Section 4.3。
- 跨模态收集证据:
- 从文本中提取拉格朗日乘数法的定义与数学表述。
- 从图像中抓取关键公式的板书截图。
- 从视频中定位并总结例题的逐步推导过程。
- 沿关键路径生成答案:最终将来自不同模态的定义、证明和例题推导,沿着构建好的记忆图关键路径,整合为一份完整的回应。
这个例子清晰地体现了 VimRAG 的核心价值:它不仅仅是“检索了更多内容”,而是能在复杂的多模态证据之间,建立一条清晰、可管理、可回溯的推理链路。

多模态知识库,正在成为企业 AI 的新常态
过去,许多知识库应用只需处理 FAQ、说明文档、制度文件等纯文本内容。但现在,越来越多的业务问题必须结合图纸、照片、操作视频等多种模态的“知识”才能解决。这意味着,当下的 RAG 系统真正要解决的,已经不再是“能不能检索到”,而是:
- 能否跨模态理解同一个实体或概念?
- 能否在长上下文中有效管理推理状态,避免遗忘和混乱?
- 能否在检索、记忆、推理三者之间形成高效的认知闭环?
因此,VimRAG 的意义,不只在于提供了一个新的开源框架,更重要的是展示了一种解决复杂问题的思路:用结构化的动态记忆图去管理海量上下文,用统一的框架去连接和理解不同模态,并用可训练、可优化的方式提升检索与推理的整体质量与效率。
对于正在探索多模态知识库、复杂问答、长视频理解与行业智能体落地的团队来说,这一方向值得持续关注。
体验与开源信息
如果你希望进一步了解或尝试这一方向,可以参考以下资源:
- 论文:
https://arxiv.org/abs/2602.12735v1
- GitHub 开源项目:
https://github.com/Alibaba-NLP/VRAG
- Hugging Face:
https://huggingface.co/collections/Alibaba-NLP/vrag
- Modelscope:
https://modelscope.cn/collections/iic/VRAG
此外,阿里云百炼平台的知识库功能目前已支持文本、表格、图片、音视频等多模态检索与生成能力,VimRAG 的相关能力也在逐步集成中。
- 快速体验:
https://bailian.console.aliyun.com/cn-beijing/?tab=app#/knowledge-base
对多模态 AI 和知识库技术感兴趣的开发者,欢迎到云栈社区的相关板块交流讨论,分享你的实践与见解。
 发表于 2026-4-20 12:39:15
|
查看: 143|
回复: 0
发表于 2026-4-20 12:39:15
|
查看: 143|
回复: 0
