智能驾驶正以惊人的速度成为汽车的标配,而智驾芯片则是其算力基石,也成了各大车企宣传的重点。有的车企更是宣称已研发出单颗算力高达1000TOPS的芯片。这颗犹如汽车“大脑”的芯片,研发门槛极高。今天,我们就来模拟一次从零开始,设计一款算力达到1000TOPS的智能驾驶芯片的全过程。
一、炼气期(L1)——算力的概念
首先得弄明白,1000TOPS的算力到底意味着什么。
熟悉计算机的朋友可能立刻想到,OPS就是Operations Per Second(每秒操作次数)的缩写。1次操作就是1OPS。那么1TOPS需要多少次操作?我们简单换算一下:
1TOPS = 1000GOPS = 1,000,000MOPS = 1,000,000,000KOPS = 1,000,000,000,000OPS。
结果是,每秒执行10的12次方次操作,也就是一万亿次。
假设有一颗单发射的1GHz CPU,要达到1TOPS,大约需要1000颗这样的CPU。要达到1000TOPS,则需要一百万颗。这意味着,如果用“堆CPU”这种简单粗暴的方式,这一百万颗处理器至少需要一个火车车厢才能装下。想在普通汽车上靠堆CPU来实现,显然不太现实,我们必须另辟蹊径。
二、筑基期(L2)——矩阵乘法
新思路从何而来?归根结底,要看清问题本质。智驾芯片的核心任务是运行人工智能算法,而AI算法最基础的操作就是矩阵乘法。因此,矩阵乘法的计算效率,是智驾芯片要攻克的核心。
我们花点时间来梳理一下矩阵乘法。假设有两个矩阵A和B,A为m行n列,B为n行p列。
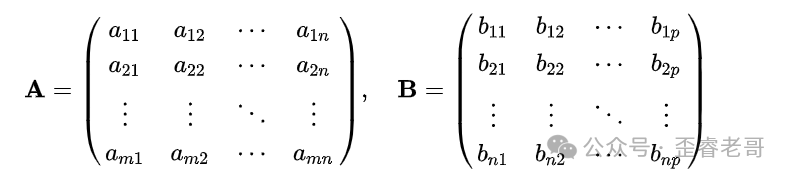
计算矩阵C = A * B,结果C是一个m行p列的矩阵。
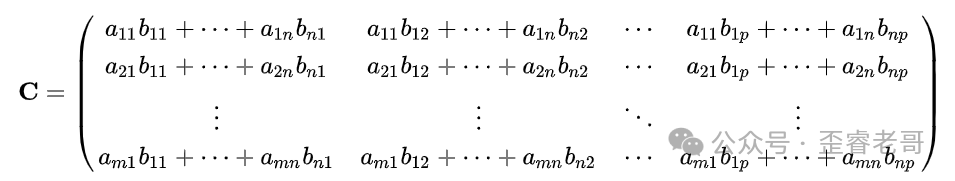
也可以简写为:
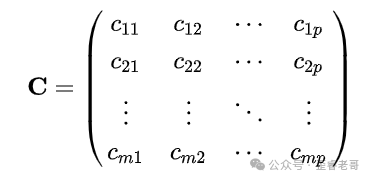
来看一个具体的例子,两个2x2矩阵相乘:
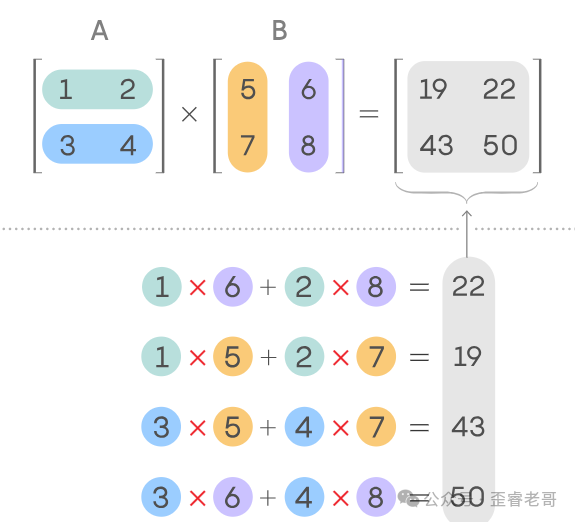
对于一个N*N的矩阵,总共需要执行 $N \times (N \times N)$ 次乘法和 $N \times (N \times (N-1))$ 次加法。在这个2x2的例子中,一共用到了8次乘法和4次加法才得到最终答案。
三、金丹期(L3)——乘累加器
从上面的分析可以看出,矩阵乘法最基础的算子单元就是乘法和加法。因此,我们可以设计一种电路,先计算两个数的乘积,比如 $1 \times 5 = 5$,然后将结果与下一次乘法的结果相加,比如 $5 + (2 \times 7) = 19$。每次都把上次的累加结果与当次的乘法结果相加,就实现了矩阵一行与一列先相乘后求和的过程。
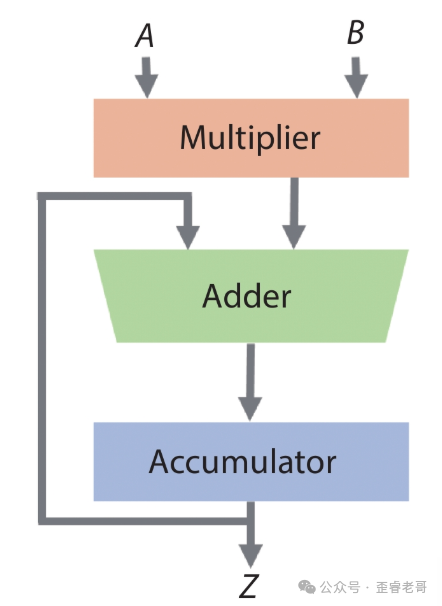
恭喜,你刚刚设计出了一个乘累加器(Multiply Accumulate, MAC)。一个MAC单元一次可以完成一次乘法和一次加法。
但问题随之而来:一个MAC只能算一个点。为了并行加速,一个N x N的矩阵就需要N x N个MAC单元。对于这个2x2的矩阵,我们就可以用4个MAC单元并行计算。
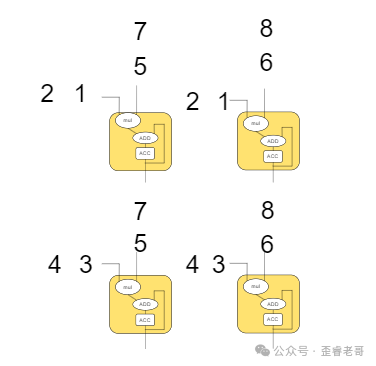
眼尖的你一定发现了规律:矩阵A的数据从左向右“流动”,矩阵B的数据从上向下“流动”,两者在MAC单元相遇相乘。这种数据流动的方式,就可以通过一种叫做“脉动阵列”(Systolic Array)的架构来实现,这个名字和任何饮料都无关,纯粹描述了数据的脉动式移动。
第一步: 数据1和5流入左上角单元。
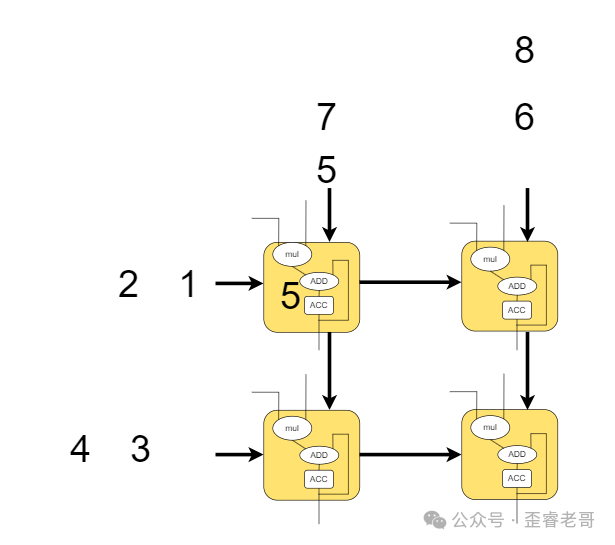
第二步: 数据继续向右、向下扩散。
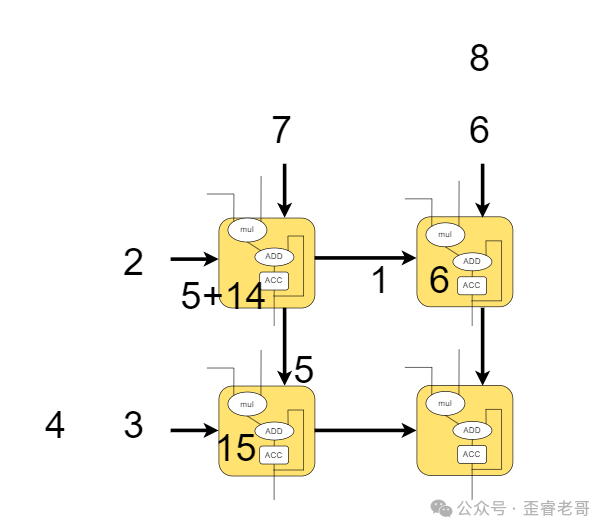
第三步:
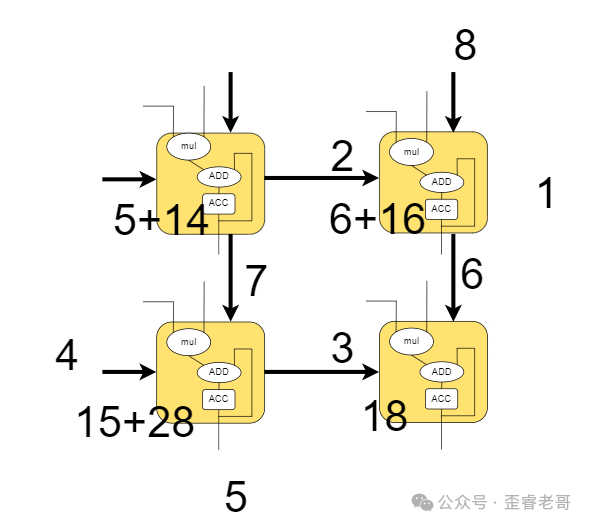
第四步:
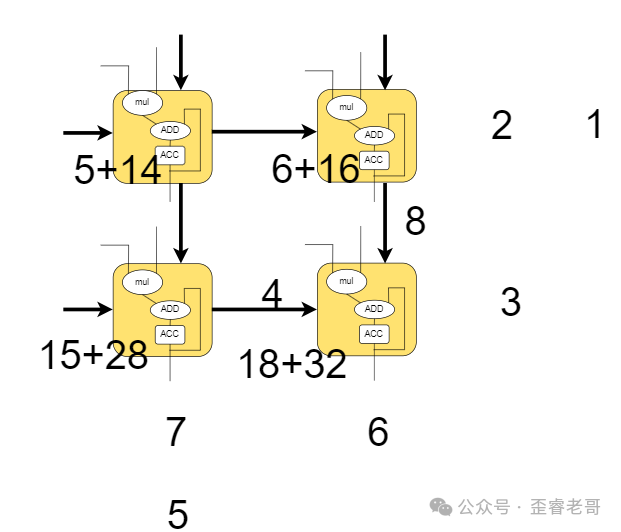
第五步: 所有结果计算完成,并“流出”阵列。
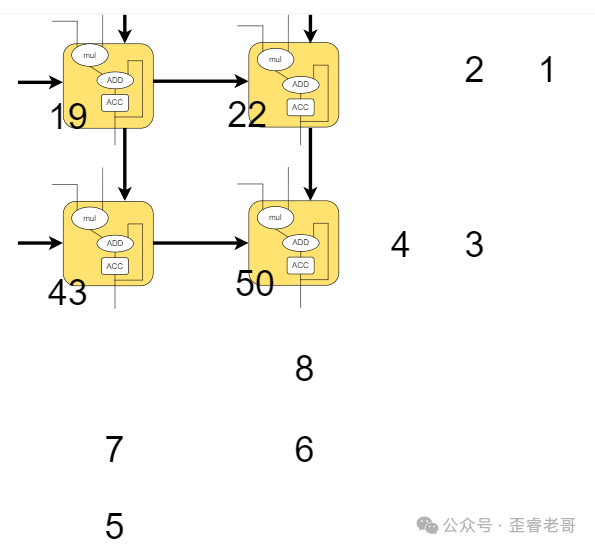
就这样,我们得到了最终的矩阵相乘结果。脉动阵列架构的优势在于,每个MAC单元的数据输入只来自上方和左侧,大大减少了芯片内部的连线复杂度,使得我们可以将更多的MAC单元集成在一起。
于是,你可以将2x2的阵列扩展得很大,形成一个大规模的乘累加矩阵。
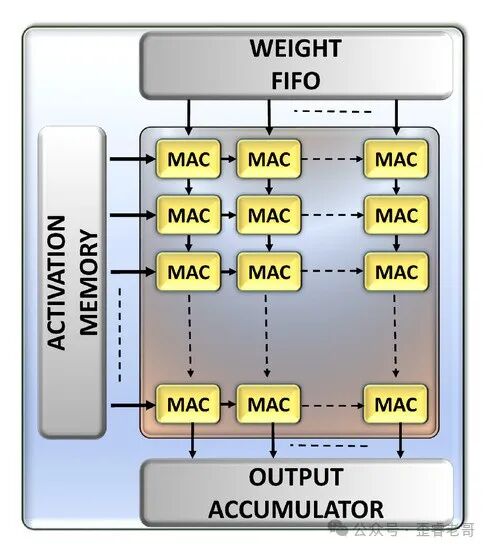
至此,你已设计出了一个矩阵乘法处理单元。上方的Weight FIFO和左侧的Activation Memory分别存储权重矩阵和激活矩阵。这个能高效执行矩阵乘法的专用单元,就是人工智能处理器(NPU)的最核心模块。
四、元婴期(L4)——NPU的设计与算力评估
那么这个矩阵的行和列设置为多少合适?在神经网络的运算中,每一层的计算量都很大,行和列可以设置为8、16、32、64、96甚至更大。我们暂且将行列都设为96,这样就得到了一个 $96 \times 96 = 9216$ 个MAC单元的阵列。为了给它喂足数据,还得配备一个足够大的缓存,比如32MB。
矩阵乘法完成后,结果并非最终输出。数据还需要进行池化(Pooling)、激活函数(如ReLU, SiLU, TanH)、归一化等一系列操作。因此,我们在矩阵输出后面再串联上可编程的SIMD单元、池化模块、反卷积(Deconv)模块等,一个完整的NPU就设计完毕了。
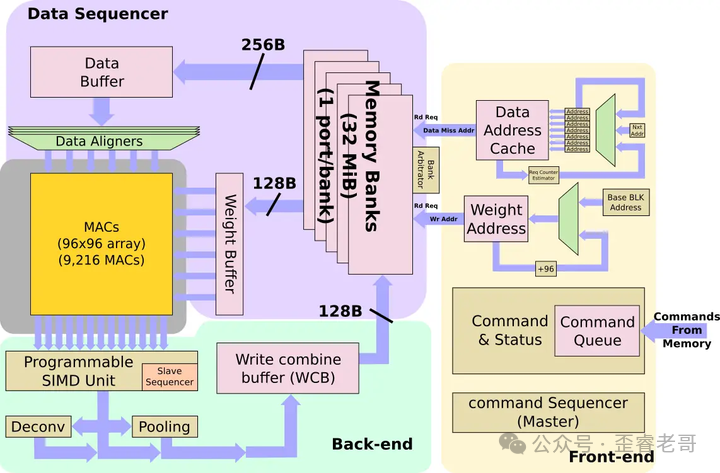
设计完毕,最关键的问题来了:这个NPU的性能是多少?
核心算力来自那个96x96的MAC阵列,共9216个MAC。每个MAC单元在每个时钟周期内可以完成一次乘法和一次加法,即2次操作。所以,整个阵列每个时钟周期能执行18,432次操作。假设我们将其做成芯片,运行频率定为2GHz,那么它的算力就是:
$2GHz \times 18432 = 36864 GOPS = 36.864 TOPS$。
看,是不是很简单明了?
五、大乘期(L5)——智能驾驶芯片的集成与算力博弈
正当你洋洋得意时,“马老板”发话了:“才37TOPS?性能太差,至少翻倍!”
你刚想解释功耗、面积、利用率等问题,但老板不听。你灵机一动:在一个SoC(片上系统)里放两个NPU不就行了?
说干就干。在一个芯片内集成两个NPU,算力一下就到了 $36.86 \times 2 \approx 73.72 TOPS$,四舍五入就是74TOPS。当然,一个完整的智驾SoC除了提供算力的NPU,还需要负责控制调度的CPU(如3个四核Cortex-A72集群,共12个核心,2.2GHz)和负责图像处理的GPU(如1GHz的Mali G71 MP12)。
至此,你设计出了一款芯片,它的架构与特斯拉第一代FSD芯片如出一辙。这款芯片采用三星14nm工艺,核心面积约为 $260mm^2$。
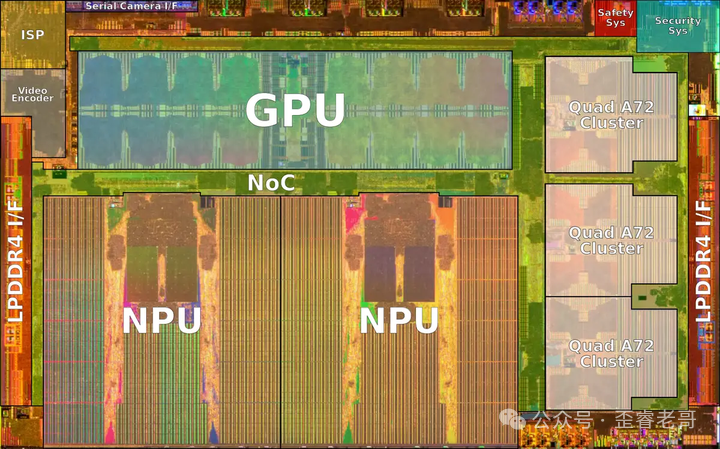
可以看到,提供核心算力的NPU几乎占据了整个芯片面积的50%。结果芯片刚设计出来,“马老板”又说了:“74TOPS的性能指标还是太低,不好宣传,至少要超过100TOPS。”
有了之前的经验,你再次想到:在电路板上放两颗芯片不就行了?系统最终采用了两颗FSD芯片,总算力达到了148TOPS,一举迈过了高阶智驾的门槛。

即使这样,离1000TOPS的目标还很远。要达到这个量级,无非是增加NPU数量或扩大MAC阵列面积。比如,设计一个 $128 \times 128$ 的MAC阵列NPU,2GHz频率下算力就能超过64TOPS。一个芯片放4个这样的NPU,单芯片算力256TOPS,板载4颗芯片就正好是1024TOPS。
这个计算过程听起来毫不费力。你可能会问,算力真能这么粗暴地叠加吗?现实中,某家车企正是通过堆叠四颗智驾芯片(Orin-X),宣称达到了1024TOPS的算力。
但行内人都明白,硬件提供的算力不等于智驾软件能用到的有效算力。通过简单的计算也能明白,如果处理一个 $96 \times 96$ 的矩阵,却用 $128 \times 128$ 甚至 $256 \times 256$ 的硬件单元去算,大量的MAC单元会处于空闲状态,这就是硬件利用率的问题。
所以有句话说得好:算力不是万能的,但没有算力也是万万不能的。看得见的是芯片的算力指标,看不见的是跑在上面的软件和算法。这些软件算法的能力,才是拉开各家智驾体验差距的关键所在。
芯片的算力、算法的智力、系统的合力,唯有三者融为一体,形成合力,才能驱动智能驾驶突破现有边界。穿梭于全地形、全天候的三界亦如履平地,方能最终证得“无人驾驶”之天道。
后记:本想一并介绍另外两款典型的智驾芯片——英伟达的Orin-X和华为的昇腾610,但篇幅所限,留待下次再续。
 发表于 2026-4-25 09:44:40
|
查看: 123|
回复: 0
发表于 2026-4-25 09:44:40
|
查看: 123|
回复: 0
