
“它将成为有史以来产量最高的 AI 芯片之一。”
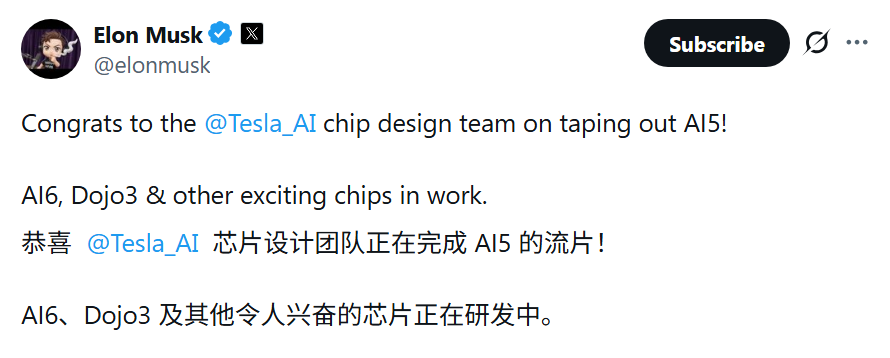
刚刚,埃隆·马斯克在社交平台X上发布消息:“恭喜 @Tesla_AI 芯片设计团队正在完成 AI5 的流片!AI6、Dojo3 及其他令人兴奋的芯片正在研发中。”
对于行业外的人来说,“流片”这个词听起来可能令人困惑。实际上,这是一个源于半导体行业早期生产流程的古老术语。在过去,工程师们真的需要将最终的芯片设计数据存储到物理磁带卷轴上,再寄送给芯片制造工厂。如今,数据传输早已数字化,但“流片”(Tape-out)这个说法作为行业经典被保留了下来,标志着芯片设计完成并正式进入试生产环节。
回顾特斯拉的芯片演进之路:从2019年推出的HW3(算力144 TOPS)到2023年的AI4(算力500+ TOPS),大约用了4年时间,这属于业内的常规研发节奏。
然而,从已被提前45天完成设计的AI5,到目前正在研发的AI6,马斯克提出了一个惊人的“九个月迭代周期”。他预计AI6将在今年12月完成“流片”。如此高效的研发速度,特斯拉是如何做到的?这引发了广泛的关注。
AI5芯片规格如何?将用于哪些场景?
这是AI5芯片的实物外观图:

根据官方信息,单颗AI5芯片的实际算力,大约是当前双芯片AI4配置的5倍!整体性能比AI4有巨大飞跃——计算能力提升约8倍,内存容量增加9倍,内存带宽提升5倍。
预计搭载AI5的完整系统算力将达到2000-2500 TOPS,而AI4系统只有300-500 TOPS左右。单从芯片性能来看,AI5已能与英伟达的Hopper架构芯片(H100)比肩,若使用两颗AI5芯片,其性能则接近英伟达最新的Blackwell级别。
在社交平台上,已有技术爱好者仅从芯片照片就推断出了相当详细的数据:
- 内存芯片疑似是SK海力士的H58G66DK9QX170N 8GB LPDDR5X,带宽为9600Mbps。12个模块总计提供96GB内存和约1.15TB/s的带宽。
- 芯片尺寸似乎是半光罩(约430平方毫米),这使其在芯片良率和生产成本上优于英伟达H100等采用全光罩(>800平方毫米)的芯片。若特斯拉采用台积电3纳米工艺,该芯片将包含约1080亿至1250亿个晶体管。
- 凭借如此高的晶体管密度和内存性能,在功耗限制在约150W时(例如在汽车或Optimus机器人系统中),其性能可达2000-2500 TOPS,与H100相当。若在数据中心等不受限场景,性能可能更高。
- 这种将内存集成在封装内的方式相当先进,相比传统的板载内存配置,在延迟方面优势明显。分析认为,图中展示的可能主要是数据中心版本。对于汽车或Optimus机器人平台,可能会采用传统的板载内存配置(容量较小,例如32GB)。
- 据估计,其成本大概是英伟达H100的10%。
那么,这款性能强劲的AI5芯片未来将主要应用于哪些领域呢?
- 特斯拉自动驾驶:这是最核心的应用场景。真正大规模量产装车可能要到2026年底或2027年。马斯克在多次公开场合提到,当前的HW3/HW4硬件仍可通过软件更新持续提升自动驾驶能力,但面向大规模Robotaxi(自动驾驶出租车)运营,特斯拉正在开发新一代AI5硬件。其核心目标是提供更高算力与更强的系统冗余,从而支撑真正无人驾驶的商业化落地。关于自动驾驶技术更深入的讨论,可以关注人工智能领域的相关进展。
- 特斯拉人形机器人Optimus:特斯拉的自动驾驶软件与机器人软件是高度通用的。Optimus机器人同样需要处理来自视觉、力反馈和关节传感器的海量实时数据,强大的AI5芯片将为其提供关键的“大脑”算力。
- xAI数据中心与分布式计算:尽管马斯克强调AI5主要针对边缘推理(如在汽车和机器人上实时处理数据),但其强大的性能也可用于xAI的部分模型训练和推理场景。
AI5研发逻辑:软硬协同,放弃“通用性”
AI5芯片为何能实现如此优异的性能与能效比?特斯拉的秘诀在于硬件与软件的深度协同,并主动放弃了传统GPU的“通用性”。
一位独立研究员Shanaka Anslem Perera对此评价道:“90亿英里的驾驶数据被浓缩成了一块芯片。”
这款芯片最有趣的设计思路在于:特斯拉没有遵循英伟达等公司的传统GPU生产方式,而是从他们积累的90亿英里FSD(完全自动驾驶)实际道路推理数据入手,提出了一个根本性问题:神经网络的计算周期都浪费在哪里?
答案是:softmax计算和量化精度损失。
这两种特定的数学运算在所有通用GPU中都消耗了不成比例的硅片面积和功耗。特斯拉的解决方法是,将定制的量化和softmax加速器模块直接集成到芯片内部。这使得AI5芯片在执行这些关键操作时的效率,比任何通用GPU高出五倍。此外,他们还大幅增加了相对于AI4的原始计算能力和内存容量。
这种“软硬件垂直整合”的模式,基于海量的、真实的应用数据反向定义芯片架构,极大加速了芯片的迭代速度,形成了一个高效的技术闭环。
与英伟达芯片的比较:赛道不同,目标迥异
将AI5与英伟达的芯片直接对比,实际上并不完全公平,因为它们的设计初衷和目标赛道本就不同。
- 英伟达生产通用型GPU:他们将晶体管封装在一个完整的芯片上,预装CUDA等通用计算框架,然后让客户(开发者)自行决定运行哪些模型和运算。例如Blackwell B200的运算能力高达4.5 petaFLOPS,功耗最高可达1000瓦。它可以运行任何客户想要的任何模型——这种强大的通用性是其核心护城河,但也意味着需要为通用性付出晶体管和能效上的代价。
- 特斯拉的AI5是专用型SoC(系统级芯片):其设计初衷只有一个:极致高效地运行一个基于90亿英里摄像头观测数据构建的、可微分的物理世界模型。AI5的每个晶体管都服务于这个特定目标,没有硅片的浪费,也没有为通用性付出的额外成本。这使得其在运行特斯拉自身工作负载时,能效比高出3到5倍,性价比高出约10倍。
因此,AI5并非一款旨在与英伟达在通用人工智能计算市场正面竞争的芯片。它的诞生,标志着特斯拉在针对特定垂直领域(自动驾驶)的定制化芯片道路上越走越远。
网友热议:AI5能否用于现有的HW3/HW4车型?
在AI5芯片的消息公布后,众多特斯拉车主最关心的问题莫过于:这款强大的新芯片,未来能否用于目前搭载HW3或HW4/AI4硬件的车型升级?
马斯克本人对此的回复是:“HW4 已经足够实现无人监管的 FSD。”
在Reddit等开发者广场上,车主们的讨论则更为直接。有网友指出:“特斯拉的计划是‘等待你’,希望你‘自愿’升级到HW4(或未来的HW5)汽车,这样他们就不必对你的HW3汽车进行强制或免费的硬件改装了。”

综合来看,AI5作为面向下一代平台和Robotaxi运营的核心硬件,大概率不会用于现有车型的大规模硬件改装。它更可能率先应用于新款车型、Optimus机器人以及特斯拉自家的数据中心。
写在最后
马斯克为何如此执着于自研芯片?他曾在一次直播中直言:“目前芯片的全球制造能力只够满足我们未来需求的2%。”
长期以来,无论是前沿的大模型还是落地的自动驾驶,全球科技公司都严重依赖英伟达等少数几家公司的芯片供应。通过自研芯片,特斯拉能够将芯片迭代的节奏牢牢掌握在自己手中,以“9个月一个周期”的惊人速度进化,而无需被动等待外部供应商的产能分配和产品路线图。
从HW3到AI4,再到即将到来的AI5和AI6,特斯拉正在构建一条独立于传统芯片巨头的垂直技术栈。这条路不仅关乎成本与效率,更关乎对未来技术发展主导权的争夺。对于AI5芯片的亮相以及特斯拉的芯片战略,你有什么看法?欢迎在云栈社区与更多技术爱好者一同探讨。
参考链接:
https://x.com/elonmusk/status/2044315118583066738
 发表于 2026-4-20 11:20:29
|
查看: 197|
回复: 0
发表于 2026-4-20 11:20:29
|
查看: 197|
回复: 0
