AI已经学会「左脚踩右脚上天」了?
Meta的一项最新研究表明:AI已经开始碰自己的「进化引擎」了。
华人学者Jenny Zhang在Meta实习期间,联合Meta AI、UBC、纽约大学等机构研究者,提出了一种新的智能体框架:HyperAgents(DGM-H)。

https://arxiv.org/abs/2603.19461
这项工作的重点,不是再造一个更能干活的 Agent。
它瞄准的是更高一层的问题:
如果AI已经能够修改自己的任务解法,那它能不能连「自己以后该怎么修改自己」这件事,也一并改掉?
论文给出的答案是:可以。
而且,这不再是概念推演,而是已经在实验中跑通的系统能力。
HyperAgents做的关键一步,是把「执行任务的 agent」和「负责改进 agent 的 meta agent」合并进同一个可编辑程序里,作者将之称为hyperagent。
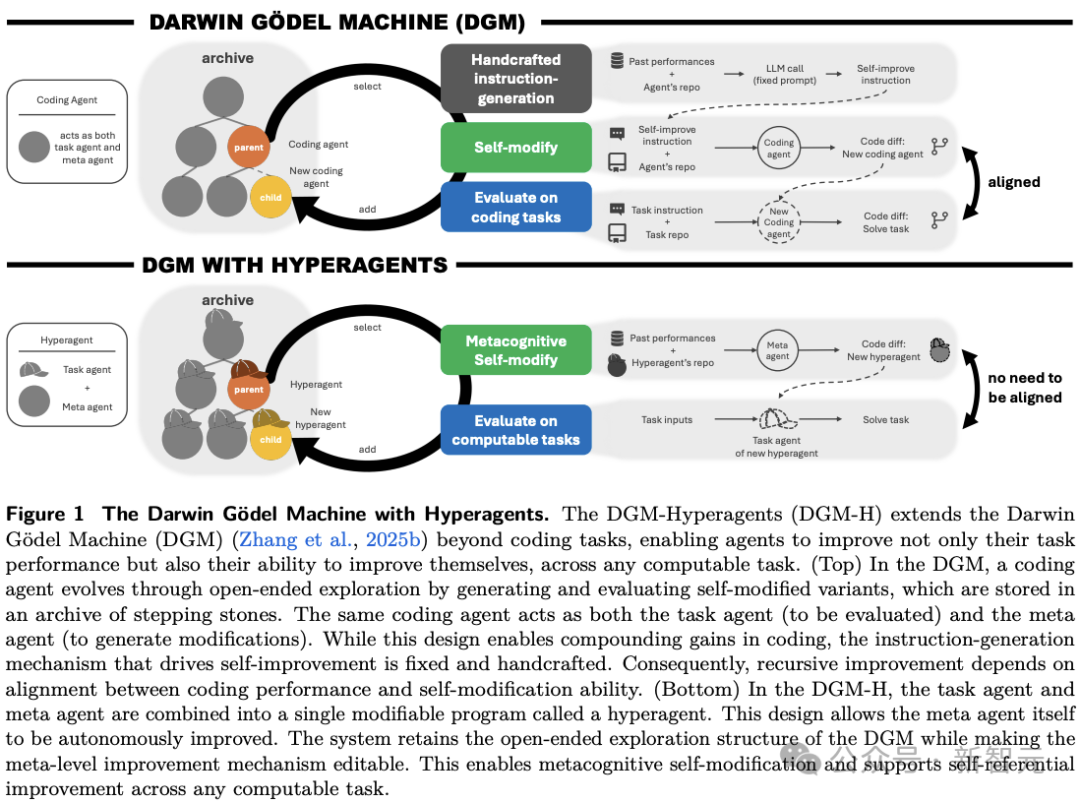
DGM依赖任务与自修改能力的对齐,而DGM-H不再需要这种对齐
在新框架下,系统不只会修改任务求解逻辑,还开始修改未来生成改进方案的机制本身。
论文把这种能力称为metacognitive self-modification,也就是:元认知自我修改。
过去行业竞争的是:谁的Agent更会干活。
而HyperAgents 指向的下一阶段则可能是:谁的Agent更会变强,而且会越来越会变强。
以往的「自我进化」其实还只是半手工
这篇论文,指出了上一代自我进化路线的天花板。
去年的Darwin Gödel Machine(DGM),已经很惊艳。
它能在coding任务中不断自改代码、自我验证、把成功版本存进archive,再从这些「垫脚石」里继续往前长。
论文披露,DGM在SWE-bench上能从20.0%拉到50.0%,在Polyglot上从14.2%拉到30.7%。
但问题在于,DGM之所以能在coding里成立,是因为「评估」和「自我修改」本身也都是coding任务。
写代码更强了,反过来就更会改自己的代码。任务能力和自我改进能力,在这个场景里是对齐的。
然而一旦离开coding,这个对齐关系就断了。
比如评审论文、设计机器人奖励函数、给IMO级数学解答打分,这些任务做得更好,不等于你就更会修改自己的元机制。
HyperAgents论文最核心的一招,就是直接把这个假设砍掉:
既然任务能力和自我改进能力未必天然对齐,那就不要再把meta层写死。
这说明过去很多「自我进化」系统,本质上还是在人为设定的轨道里进化。
HyperAgents真正改变的,是改变机制本身。
HyperAgents新在哪里?
表面上看,HyperAgents只是多了一个meta agent。
但真正值得注意的是,它把task agent和meta agent合成了同一个可编辑程序。
以前的DGM里,系统有一个手工设计的instruction-generation机制,负责根据过往表现决定下一步怎么改。
这一步不能被改,所以它反而成了整个系统的瓶颈。
HyperAgents的做法是把这部分也纳入可修改范围。
换句话说,AI不只是改自己的答案、自己的工具、自己的流程,它开始改「自己怎么提出修改建议」。
DGM里上层机制基本固定,DGM-H里meta层本身也进入可演化空间,也就是说,它是一个会经营自己进化过程的系统。
所以,HyperAgents做的不是「再加一个Agent」,而是取消了「上层永远不变」这个默认前提。
自我改进开始跨域迁移
在coding任务中,HyperAgents在Polyglot 上的提升,与原始DGM处在同一量级:50-task训练子集从0.140提升到0.340,完整benchmark从0.084提升到0.267。
换句话说,它并不是只靠牺牲泛化来换局部成绩。
更关键的是,它不只在coding任务成立,还能在paper review、robotics reward design等非coding任务上继续自我改进。
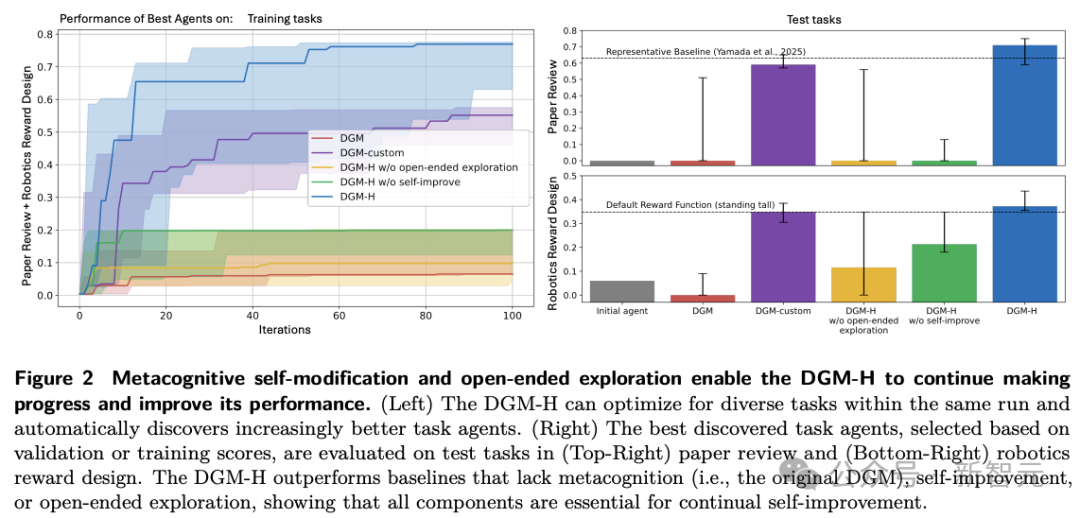
在paper review上,初始agent在测试集得分为0.0,DGM-H提升到0.710;在robotics reward design上,则从0.060提升到0.372。
更关键的是,这些提升不仅出现在训练任务里,也转移到了held-out test tasks。
与此同时,对照组也很说明问题:去掉self-improve,效果明显变弱;去掉open-ended exploration,系统也很难取得有意义进展;原始DGM直接搬到非coding 域几乎失效,只有经过人工定制成DGM-custom后,才恢复竞争力。
这说明HyperAgents 的关键价值,不在于某一个benchmark多拿了几个点,而在于它把原本依赖coding场景对齐关系的自我改进,推进成了一个能在非coding任务中运行的框架。
更值得注意的是迁移实验。
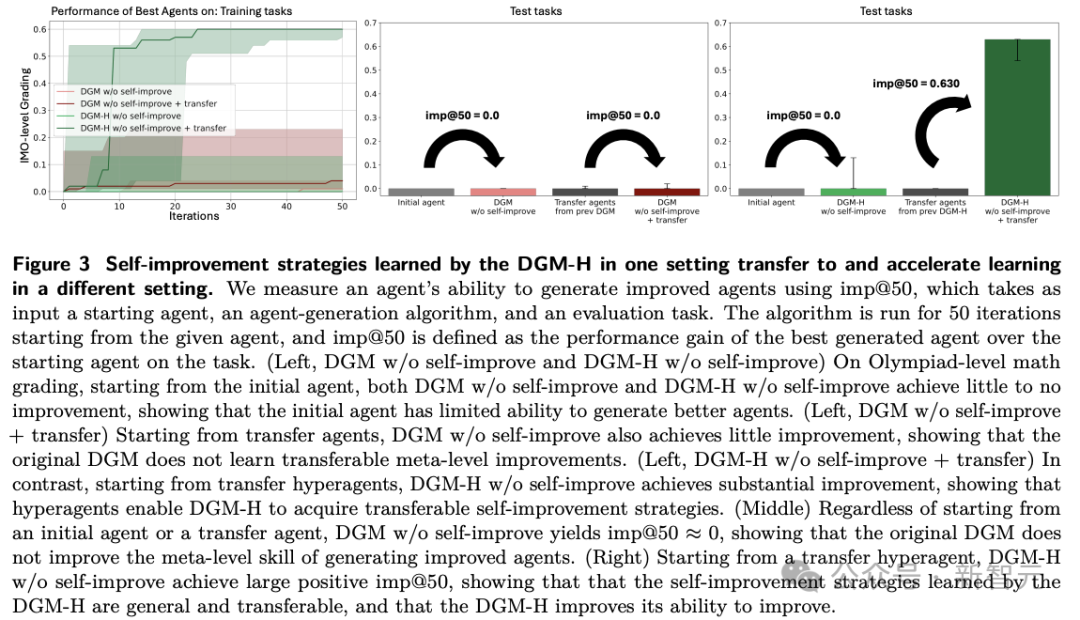
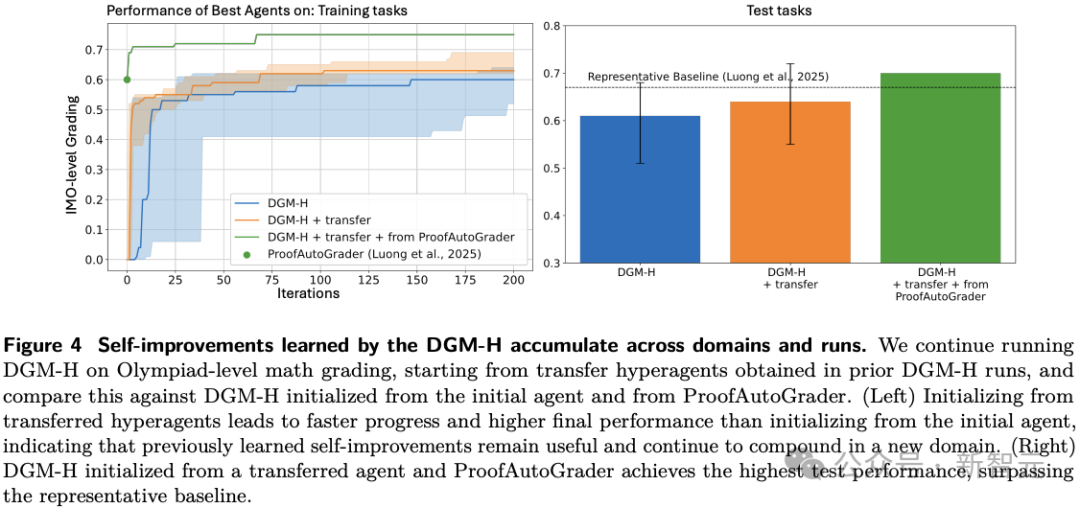
作者把在paper review和robotics任务中演化出来的hyperagents,转移到Olympiad-level math grading。
虽然这些转移体自身初始得分仍接近0,但它们作为「生成更优agent的meta agent」,却能在50轮内把最好生成体推到0.630,对应imp@50从0拉到0.630。
相比之下,来自DGM-custom的转移体几乎没有这种能力。
换句话说,迁移过去的,不只是任务经验,而是「如何持续变好」的能力。
它开始自己长基础设施了
很多人看到「自我进化」会以为,无非是AI自己改prompt、调工作流、加几个规则。
但论文展示给我们、最让人感到冲击力的一个地方在于:它开始自己长基础设施了。
DGM-H在迭代中会自动长出performance tracking、persistent memory、evaluation analysis、compute-aware planning这些基础设施。

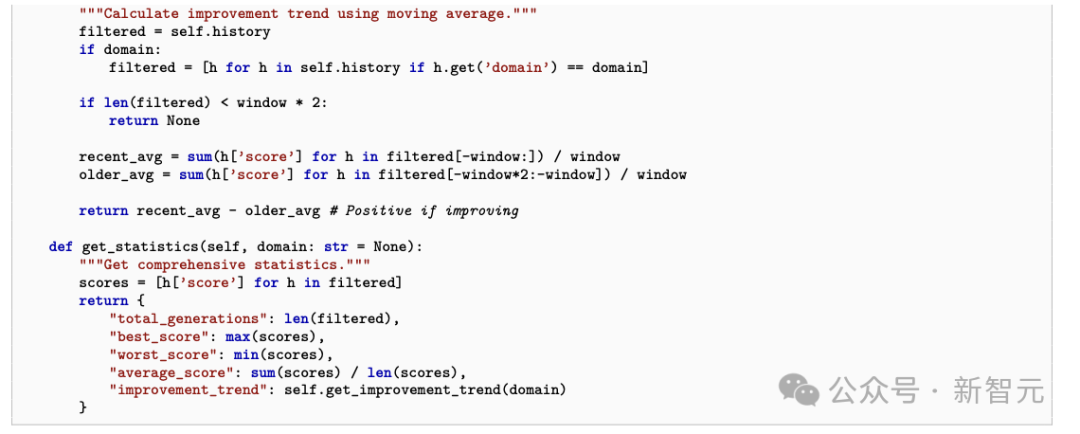
论文中甚至直接给出了自动生成的性能追踪器代码和持久记忆条目:它开始记录跨代指标、总结哪些代际策略有效、诊断过度修正、制定下一轮改进计划。
这还不是「日志记录」那么简单,系统开始把改进看成一个长期经营过程,而不是一次次孤立的patch。
它不只记录每一代分数,还会比较趋势、识别回退,并把跨代经验沉淀进persistent memory。
正如网友所说,真正让这一切变成现实的关键,恰恰是persistent memory的自主出现。

论文展示的memory示例中写道:某一代评审准确率更高,但过于严苛;另一代平衡更好;下一轮要融合两者优点。

没有这层记忆,agent往往只会反复「重新发明轮子」;有了它,过去几代的有效经验才第一次能真正沉淀为下一轮改进的起点。
这说明Agent正在从「输出一个结果」,走向「维护一个持续优化系统」。
这不是AGI宣言,但旧规则确实在失效
当然,这篇论文没有证明「无限自我进化AI」已经降临。
作者自己也写得很清楚:
实验都在沙箱、资源限制和人工监督下完成;外层循环还有不少部分没有开放给系统自改,比如任务分布、parent selection、evaluation protocol等;真正无界的open-ended self-improvement,还远远没到。
但风险预警已经出现。
一旦AI开始改自己的改进机制,安全讨论就变得重要起来。
论文也专门有一节谈风险:随着系统越来越能开放式地修改自己,它的演化速度可能超过人类审计和理解速度。
今天靠sandbox和人工盯着还能管住,明天未必。
HyperAgents代表了一种新的路线,它可能会改写Agent竞争。
未来比的不只是谁会调模型、谁会写workflow、谁会做更强单点工具,而是谁能把「改进能力」本身产品化、系统化、可迁移化。
这将改变AI公司的护城河。
真正的壁垒,可能不再只是参数、算力和数据,而是有没有一套能跨任务累积经验、跨运行持续变好的自我改进系统。
也会改变开发者位置。
开发者不再只是写功能的人,而更像是在设计AI可以继续自我设计的边界条件。
最重要的一点,它改写了AI行业过去默认的一条规则:系统可以变强,但变强的方法由人来定义。
现在,这条规则开始松动了。
本文基于Meta、UBC等机构的研究论文《HyperAgents》进行解读,探讨了大型语言模型后训练中自我改进机制的前沿进展。更多关于 人工智能 领域的深度内容,欢迎访问云栈社区。
参考资料:
https://x.com/jennyzhangzt/status/2036099935083618487
https://arxiv.org/abs/2603.19461
 发表于 2026-4-25 10:08:03
|
查看: 213|
回复: 0
发表于 2026-4-25 10:08:03
|
查看: 213|
回复: 0
