今天,一位朋友向我求助,他们供应商的嵌入式设备遇到了一个棘手问题。供应商老板在群里紧急求助,于是朋友作为原厂开发被派往现场支援。
当他看到现场的实际代码时,着实吃了一惊——厂商竟然用这样的代码,已经生产并部署了数十万台设备。
┄┅┄┅┄┅┄┅┄┅┄┅┄┅
我将那段问题代码简化后如下:
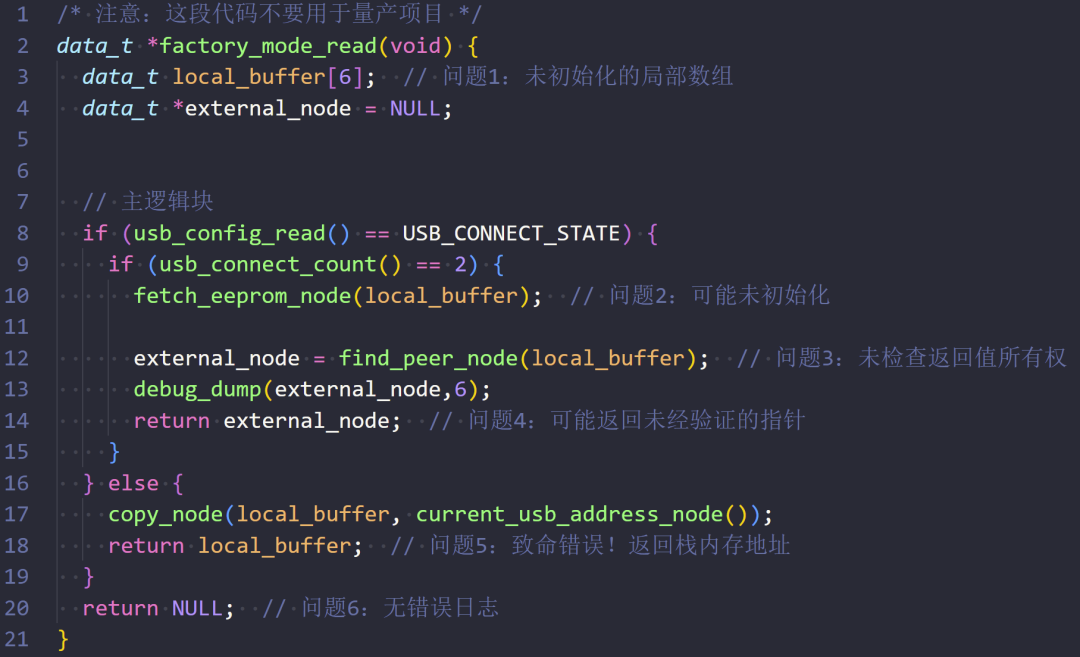
下午,我把这段代码拿给同事看。他的第一反应是:“这好像也不是致命问题吧?顶多就是打印出来的地址是乱码。”
这里需要澄清一个常见的误解:问题的严重性关键在于“踩”内存,即你写入(侵犯)了不属于自己的内存空间,这常常会导致致命且不可恢复的错误。然而,如果你仅仅是读取了不属于自己的内存信息,通常不会直接引发问题。
而返回栈内存地址则是一种典型的“未定义行为”。如果函数返回栈地址后,调用方立即使用这个指针,此时栈帧可能尚未被后续函数调用覆盖,你完全有可能拿到“正确”的值。特别是在一些跑裸机程序的嵌入式设备上,这种代码运行起来可能“要多正常就有多正常”。
下面是一段简短的测试代码,可以帮助我们理解这个现象:
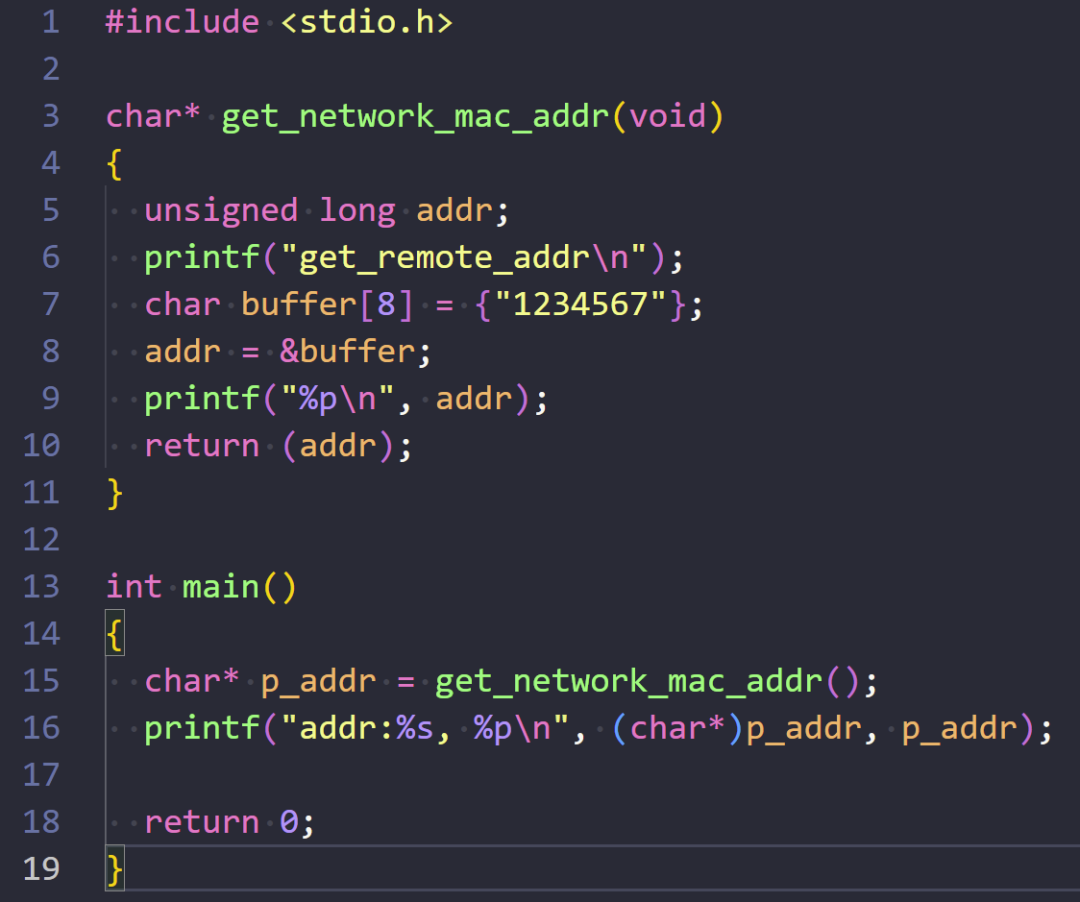
注意,如果代码中没有用 addr 变量显式接收数组地址,执行结果会有所不同,这正体现了未定义行为的不可预测性。
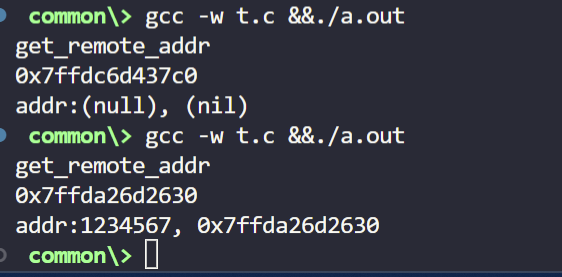
但是,一旦程序运行在多任务系统(如RTOS或Linux)中,任务切换会导致栈空间被快速回收和覆盖。此时,再去使用那个悬垂指针(Dangling Pointer),问题就会立刻显现出来。
┄┅┄┅┄┅┄┅┄┅┄┅┄┅
最让我感到匪夷所思的是,这样充满隐患的代码,经过修修补补,竟然已经在几十万台设备上“稳定”运行。
这引出了一个更现实的困境:当你发现一个这样的Bug时,很可能不敢直接去修复它。因为代码目前可能“表现正常”,一旦你增加了新的逻辑、改变了栈的布局,反而可能触发潜伏的问题,让整个系统崩溃。

这不仅仅是技术问题,更关乎软件工程中的风险管理与代码债。在云栈社区的C/C++板块,常有开发者讨论类似的内存陷阱与编码规范,对于从事底层开发的工程师而言,理解和避免这类问题是保证长期稳定的关键。 |  发表于 2026-1-24 10:25:29
|
查看: 299|
回复: 0
发表于 2026-1-24 10:25:29
|
查看: 299|
回复: 0
