今天我们来探讨一个在PostgreSQL中遇到的奇特现象:同一个SQL查询,使用索引扫描(IndexScan)返回的结果竟然比全表顺序扫描(SeqScan)要少。这通常是索引损坏的强烈信号。本文将深入分析一例由glibc版本差异导致的索引排序规则损坏案例,并通过源码调试来验证PostgreSQL的索引扫描过程。
问题现象
首先,我们看看在启用索引扫描时的查询情况,仅返回1条数据。
testidx=# explain analyze select * from user_info where userid ='1230005998';
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------
Index Scan using index_userid on user_info (cost=0.28..35.61 rows=9 width=57) (actual time=0.030..0.032 rows=1 loops=1)
Index Cond: ((userid)::text = '1230005998'::text)
Planning Time: 0.118 ms
Execution Time: 0.057 ms
(4 rows)
testidx=# select ctid,userid,region_id from user_info where userid ='1230005998';
ctid | userid | region_id
--------+-------------+-----------
(4,39) | 1230005998 | abc
(1 row)
接着,我们关闭索引扫描,强制使用顺序扫描,查询到了11条数据。
testidx=# set enable_indexscan to off;
SET
testidx=# explain analyze select * from user_info where userid ='1230005998';
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------
Seq Scan on user_info (cost=0.00..51.50 rows=9 width=57) (actual time=0.093..0.460 rows=11 loops=1)
Filter: ((userid)::text = '1230005998'::text)
Rows Removed by Filter: 1309
Planning Time: 0.116 ms
Execution Time: 0.478 ms
(5 rows)
testidx=# select ctid,userid,region_id from user_info where userid ='1230005998';
ctid | userid | region_id
----------+-------------+-----------
(4,39) | 1230005998 | abc
(9,14) | 1230005998 | abc
(9,32) | 1230005998 | abc
(10,32) | 1230005998 | abc
(12,5) | 1230005998 | abc
(26,23) | 1230005998 | abc
(27,4) | 1230005998 | abc
(27,9) | 1230005998 | abc
(27,11) | 1230005998 | abc
(34,38) | 1230005998 | abc
(34,39) | 1230005998 | abc
(11 rows)
对比两次结果,索引扫描只查到了第一条匹配数据 (4,39)。这是否意味着索引已经损坏了呢?
问题分析
当我们怀疑索引损坏时,可以使用 amcheck 插件对索引进行校验。
testidx=# select * from bt_index_check('index_userid',true);
DEBUG: StartTransaction(1) name: unnamed; blockState: DEFAULT; state: INPROGRESS, xid/subid/cid: 0/1/0
DEBUG: verifying level 1 (true root level)
DEBUG: verifying 7 items on internal block 3
DEBUG: verifying level 0 (leaf level)
DEBUG: verifying 207 items on leaf block 1
DEBUG: verifying 204 items on leaf block 2
DEBUG: verifying 204 items on leaf block 4
DEBUG: verifying 204 items on leaf block 5
DEBUG: verifying 204 items on leaf block 6
DEBUG: verifying 235 items on leaf block 7
DEBUG: verifying 78 items on leaf block 8
ERROR: item order invariant violated for index "index_userid"
DETAIL: Lower index tid=(8,24) (points to heap tid=(4,14)) higher index tid=(8,25) (points to heap tid=(9,14)) page lsn=1/331E9F98.
输出显示,叶子页(leaf page)8的第24和第25个条目(itemoffset)违反了顺序不变性规则。按照升序原则,24号槽位的键值应小于等于25号槽位,但检查结果是大于,这表明排序规则已经混乱。
接下来,使用 pageinspect 扩展查看问题页面的详细信息。可以看到叶子页8共有78条存活记录。
testidx=# select * from bt_page_stats('index_userid',8);
blkno | type | live_items | dead_items | avg_item_size | page_size | free_size | btpo_prev | btpo_next | btpo | btpo_flags
-------+------+------------+------------+---------------+-----------+-----------+-----------+-----------+------+------------
8 | l | 78 | 0 | 31 | 8192 | 5356 | 7 | 0 | 0 | 1
(1 row)
我们查看第22至25号条目的具体数据:
testidx=# select * from bt_page_items('index_userid',8) where itemoffset in (22,23,24,25);
itemoffset | ctid | itemlen | nulls | vars | data
------------+---------+---------+-------+------+-----------------------------------------------------------------------------------------
22 | (4,39) | 32 | f | t | 2b 4c 54 34 33 36 32 35 31 33 34 00 00 00 00 00 00 00 00 00 00 00 00 00
23 | (4,9) | 32 | f | t | 31 09 0d 0a 4c 54 34 33 36 32 35 31 33 34 37 33 36 30 30 37 39 30 30 32
24 | (4,14) | 32 | f | t | 31 09 0d 0a 4c 54 34 33 36 32 35 31 33 34 37 33 36 30 30 37 39 30 30 32
25 | (9,14) | 32 | f | t | 2b 4c 54 34 33 36 32 35 31 33 34 00 00 00 00 00 00 00 00 00 00 00 00 00
(4 rows)
从十六进制数据可以看出,24号条目的键值(以31 09开头)确实大于25号条目(以2b 4c开头),证实了索引损坏。
那么,索引是如何损坏的呢?可能的原因包括BUG、系统异常导致数据库崩溃等。一个常见且容易被忽略的场景是 glibc版本差异,尤其是在glibc 2.28前后,其对locale和排序规则的处理发生了显著变化。经排查,本次案例正是由于glibc从2.17升级到2.28所导致的。
遇到此类索引损坏,最直接的修复方法是使用 REINDEX 命令重建对应索引。
问题至此已基本清晰。但我们将更进一步,通过调试PostgreSQL源码,来验证为什么索引扫描只返回了一条数据就提前结束。
原理分析与调试验证
B树索引的结构大家应该不陌生。简单回顾一下,B树(作为btree访问方法实现)是一种平衡多路搜索树,数据在叶子节点中按键值顺序存储,并形成双向链表,便于范围扫描。
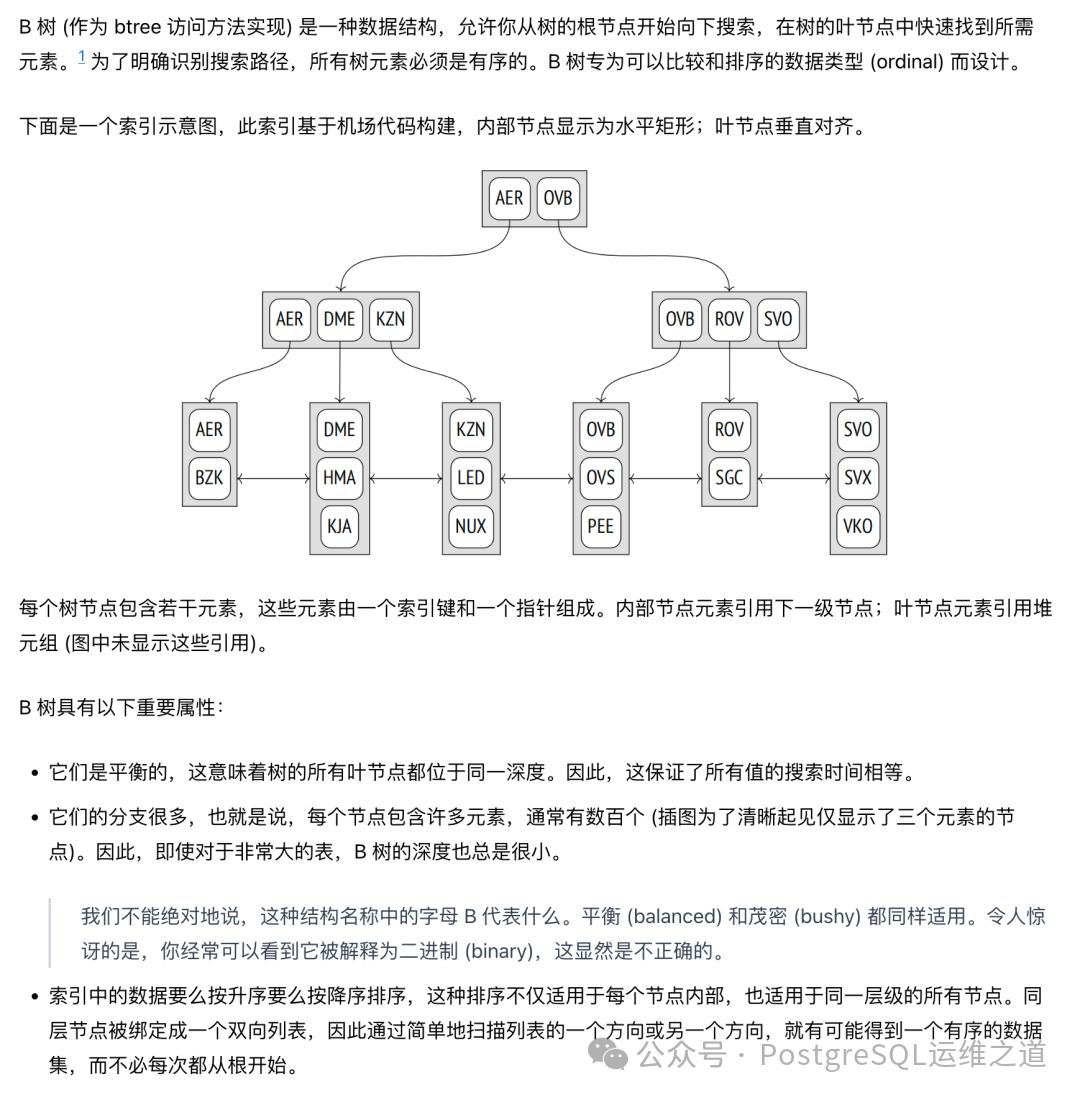
检索时从根节点开始,通过内部节点的键值导航至叶子节点,在叶子节点中找到匹配的键值后,获取其指向的堆元组ID(CTID)。
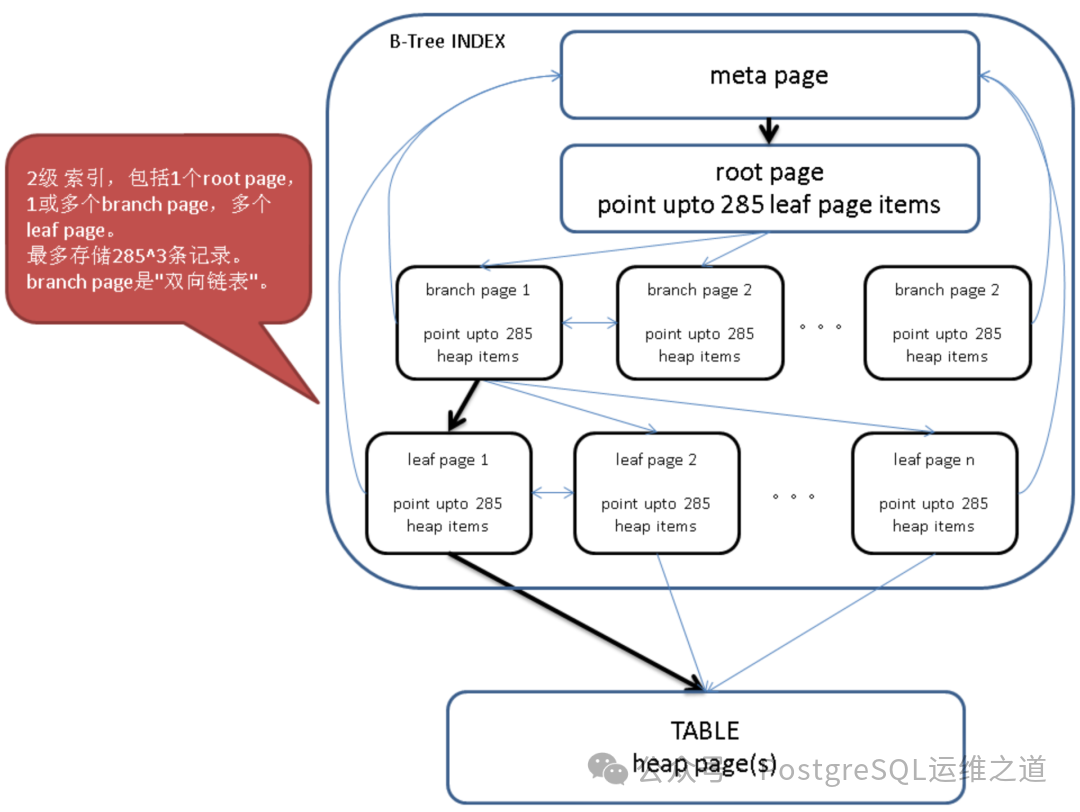
以查找键值49为例,其检索路径在下图中以黄色高亮和蓝色箭头标出:从根节点找到首个匹配的叶子节点后,会沿着叶子节点的链表向右扫描,直到找完所有匹配的叶子节点。
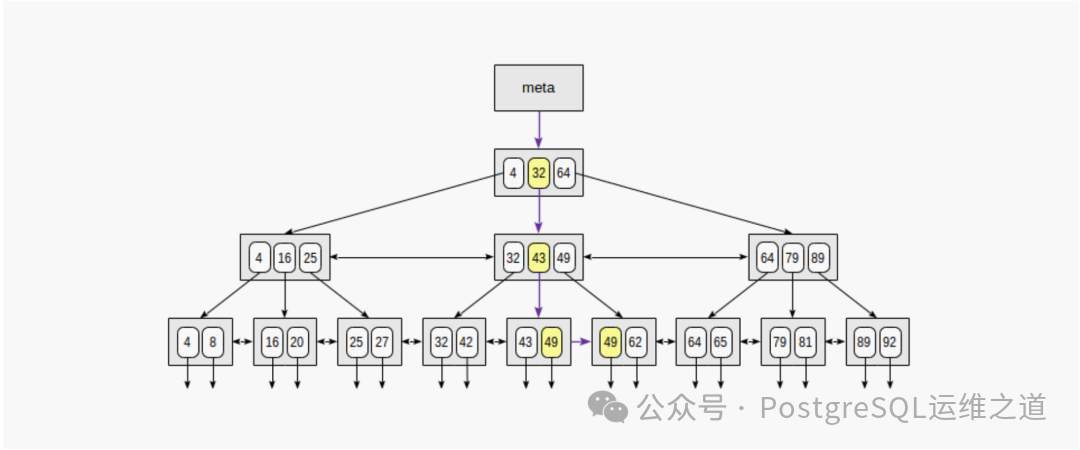
了解原理后,我们通过调试来追踪查询 userid =‘1230005998’ 的扫描过程。
1. 定位首个叶子页 (First Leaf Page)
首次扫描会进入 _bt_first 函数。它通过 _bt_search 和 _bt_binsrch 函数,在索引的根节点和中间节点进行二分查找,最终定位到包含(或可能包含)目标键值的叶子页。
在调试中,初始的 low 为1,high 为8(对应此索引的叶子块1和8)。经过一系列二分查找和键值比较(_bt_compare -> btextcmp),最终确定 high = low = 8,即目标数据在叶子页8上。
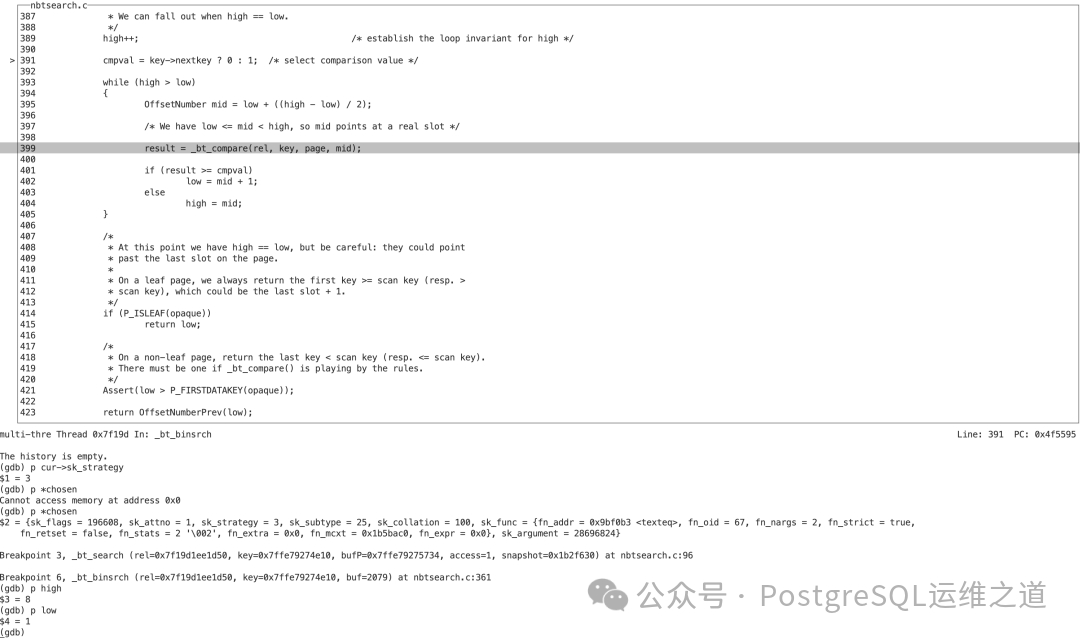

2. 定位首个匹配项 (First Item)
确定叶子页后,在页内同样使用二分查找定位第一条匹配的记录。_bt_binsrch 函数中,初始 high=78, low=1(对应页内78个条目)。
当二分查找的中间位置 mid 为22时,_bt_compare 调用 btextcmp 进行比较,发现参数 arg1 和 arg2 完全相同(都是“1230005998”),result 返回0,表示匹配成功。

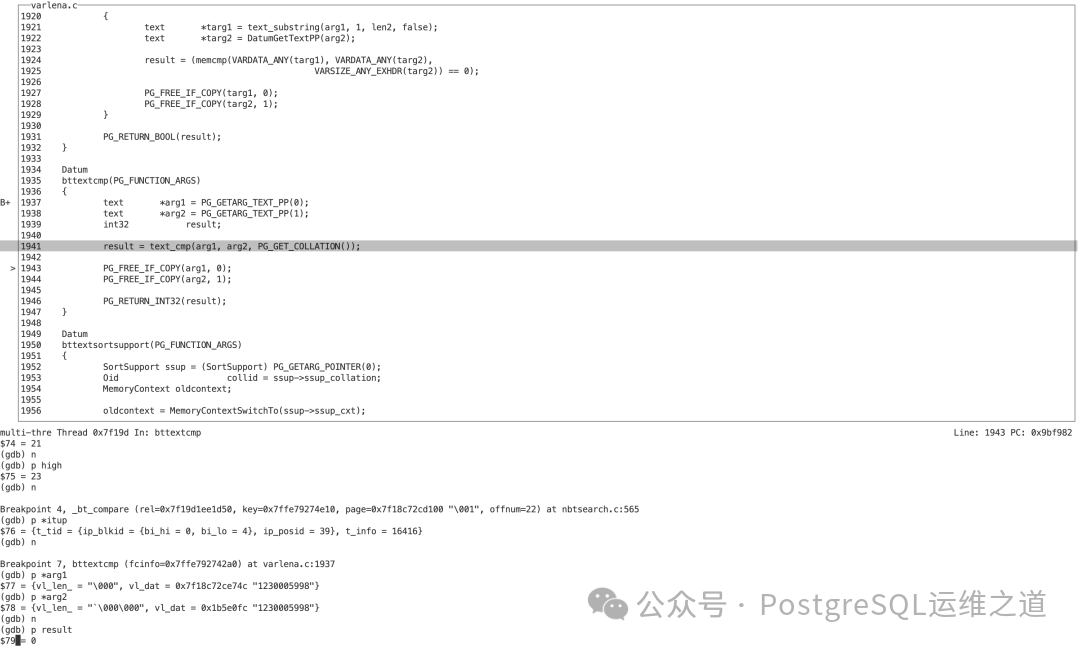
因此,最终 low = high = 22,找到了第一条匹配的索引条目,对应 itemoffset 22。
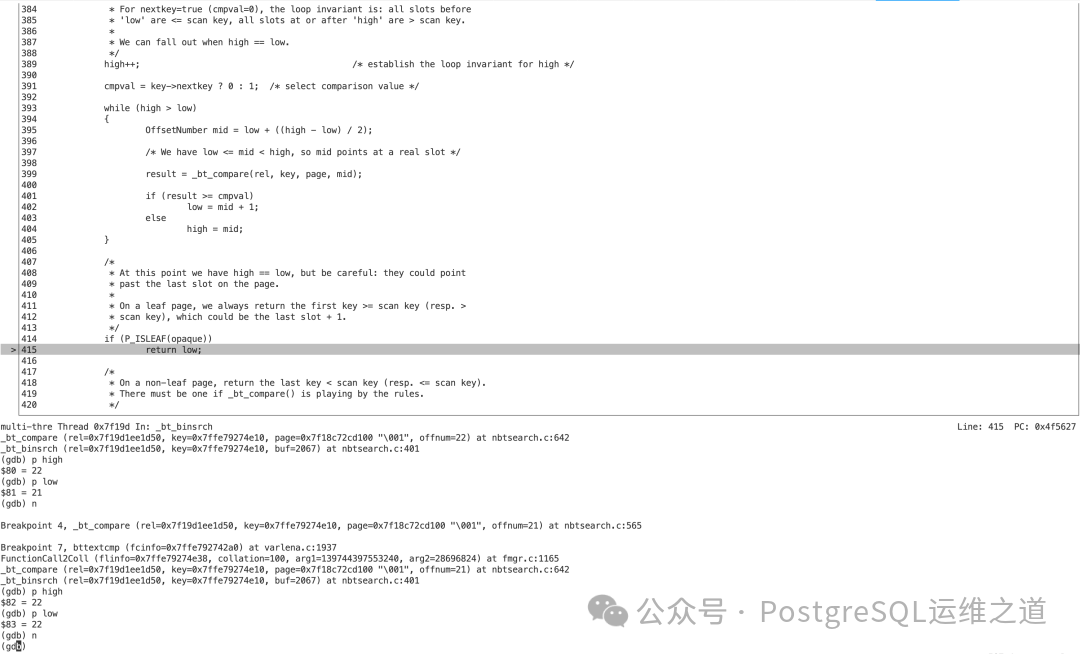
3. 遍历页内元组并设置扫描边界
_bt_readpage 函数从 offnum=22 开始,在一个 while (offnum <= maxoff) 循环中遍历页内元组。
- 首次循环(
offnum=22):调用 _bt_checkkeys 检查,键值匹配,itemIndex 增加为1,continuescan 保持为 true,offnum 递增到23。
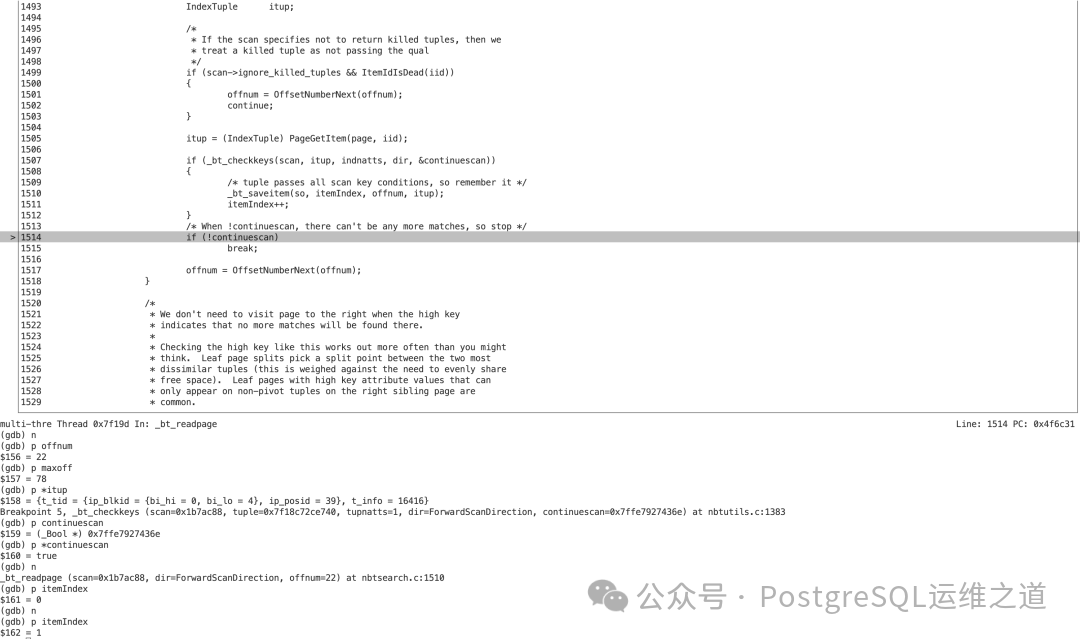
- 第二次循环(
offnum=23):再次调用 _bt_checkkeys。实际的比较函数是 texteq,它发现当前条目(itemoffset 23)的键值与查询条件的长度不同,因此 result 为 false。

- 由于比较失败,
_bt_checkkeys 内部将 *continuescan 设置为 false,并返回 false。
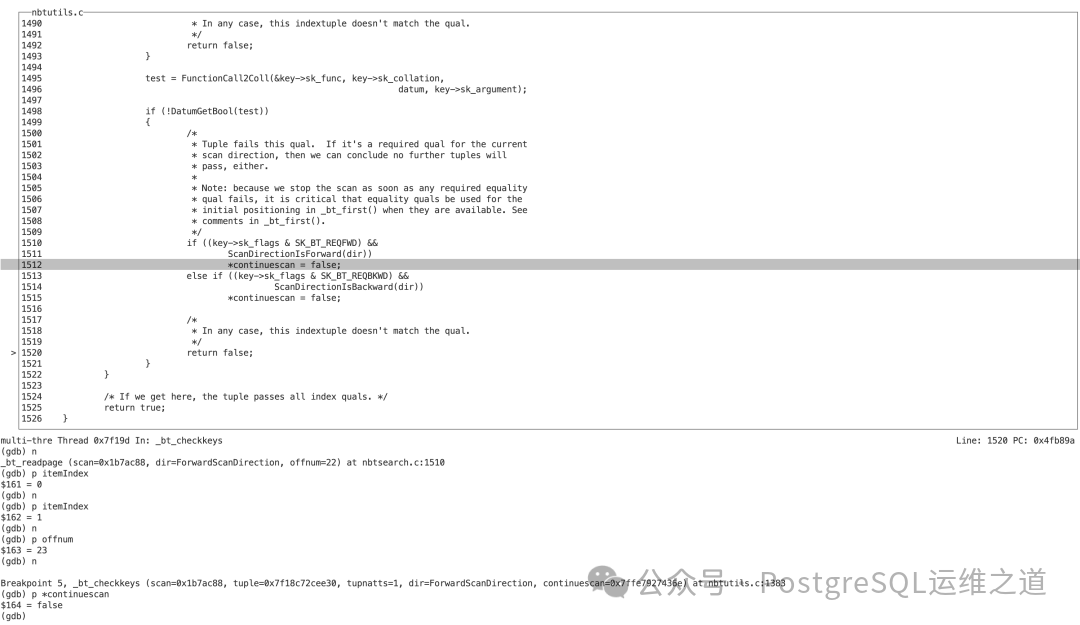
continuescan 变为 false 导致循环退出,并设置了关键的扫描状态:
so->currPos.moreRight = false (右边没有更多匹配项了)so->currPos.firstItem = 0so->currPos.lastItem = itemIndex - 1 = 0so->currPos.itemIndex = 0
firstItem 和 lastItem 均为0,这意味着当前扫描位置(currPos)的有效范围只有第一条数据(itemIndex 0)。

随后,index_getnext_slot 函数根据找到的CTID (4,39) 调用 index_fetch_heap 获取堆表数据并返回给客户端。
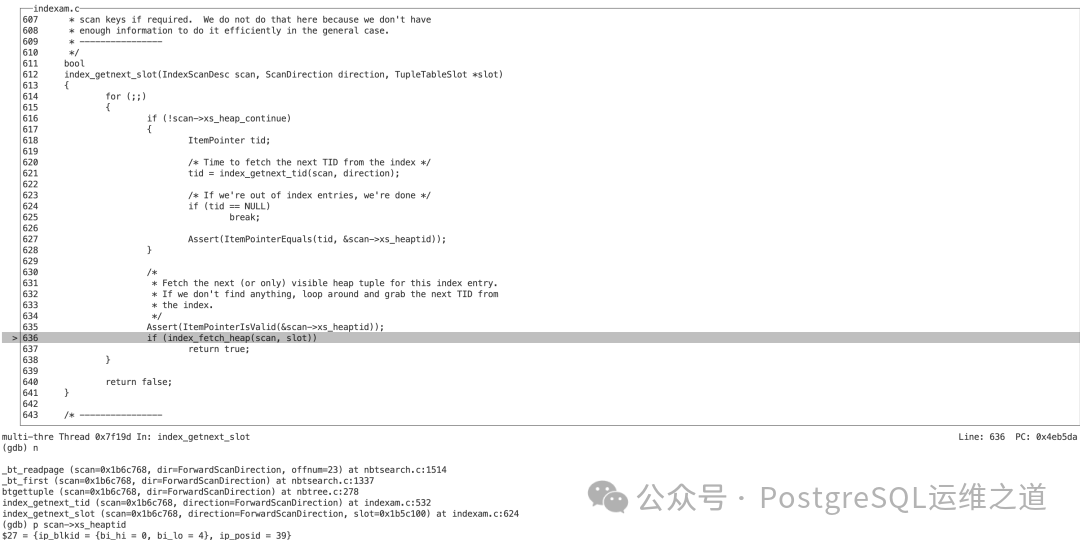
4. 获取下一条数据 (Next Item)
当执行器尝试获取下一条数据时,会调用 _bt_next。
- 由于
so->currPos.moreRight 为 false,_bt_readnextpage 函数直接返回 false。
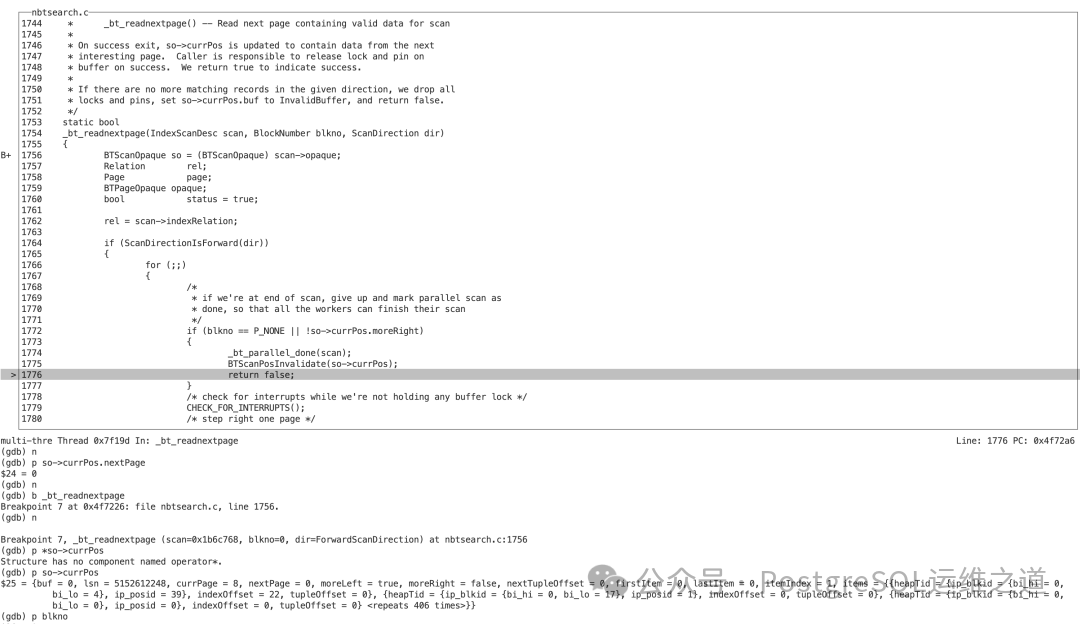
- 这导致
_bt_steppage 返回 false,进而 _bt_next 也返回 false。
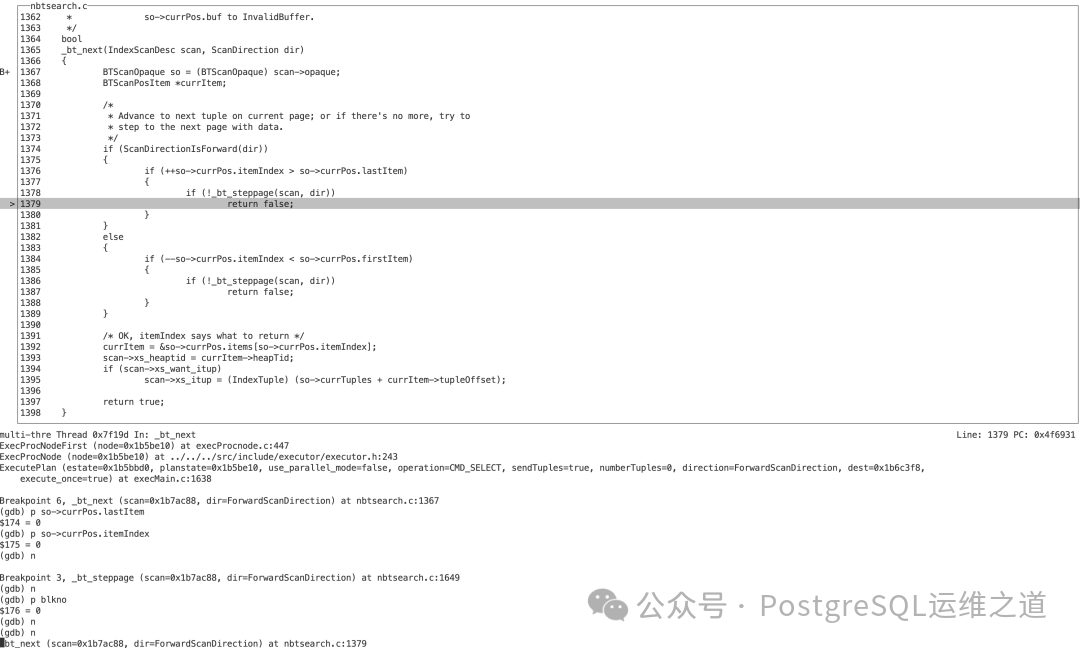
- 索引访问方法层 (
index_getnext_tid) 因此返回 NULL。

- 最终,
index_getnext_slot 返回 false,向执行器报告没有更多数据了,扫描结束。
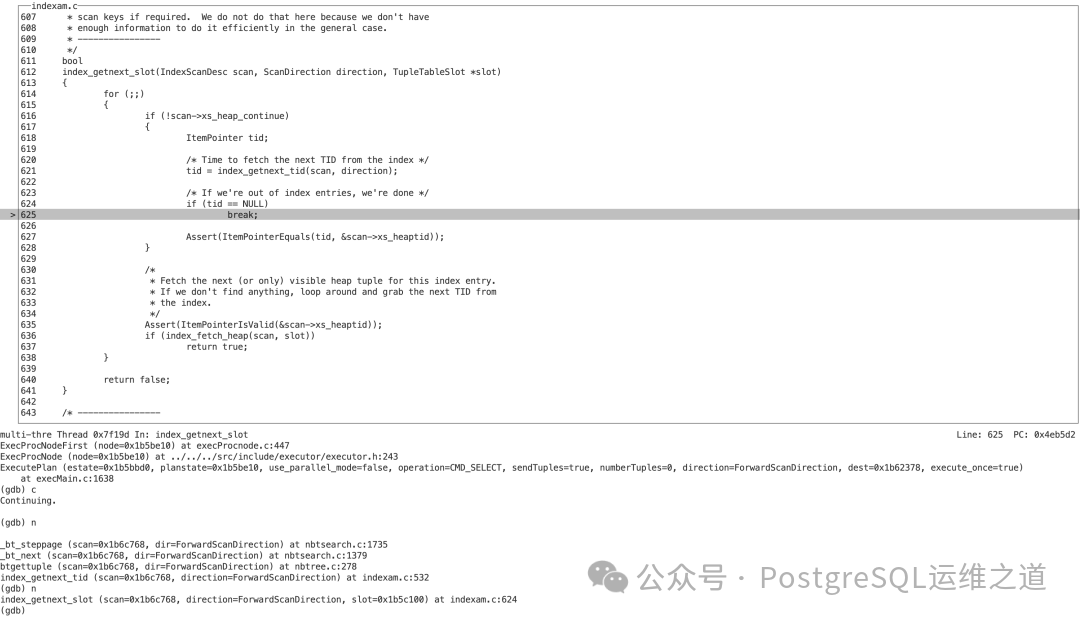
小结调试过程:
索引扫描在叶子页8的 itemoffset 22 处找到了第一个匹配项 (4,39),但在紧接着检查 itemoffset 23 时,由于索引损坏导致键值比较失败,使得 continuescan 被设置为 false。这错误地告知扫描逻辑“本页及后续页都没有更多匹配项了”,导致扫描提前终止。
从顺序扫描的结果看,下一个符合条件的堆元组是 (9,14),它本应对应索引条目 itemoffset 25。但从 bt_page_items 的输出看,itemoffset 23 和 24 的键值相同,且都大于25,这证实了索引的排序规则已经混乱,导致了上述异常行为。
总结
本文深入分析了一起因glibc版本升级引发的PostgreSQL B树索引排序规则损坏案例。当遇到索引扫描与全表扫描结果不一致的诡异现象时,可以借助 amcheck 和 pageinspect 这两个强大的扩展进行诊断和定位。同时,我们也通过源码调试,直观地验证了索引扫描的核心流程,理解了在索引损坏的具体情况下,查询为何会过早结束。
希望这个案例能为你排查类似问题提供清晰的思路。如果你在数据库运维中遇到了其他棘手的难题,欢迎到云栈社区交流探讨。
Reference
[1] https://wiki.postgresql.org/wiki/Locale_data_changes
[2] https://postgres-internals.cn/docs/chapter25/
[3] https://github.com/digoal/blog/blob/master/201605/20160528_01.md
[4] https://postgrespro.com/blog/pgsql/4161516
 发表于 2026-1-24 22:25:53
|
查看: 198|
回复: 0
发表于 2026-1-24 22:25:53
|
查看: 198|
回复: 0
