在C++开发中,std::map和std::unordered_map是最常用的两个关联容器。它们看似功能相似,却基于完全不同的底层数据结构——红黑树与哈希表。这导致了两者在性能特性、适用场景上的巨大差异。本文将从底层原理出发,通过代码实例和性能测试,帮助你在 C/C++ 项目开发中做出最优的容器选择决策。
一、数据结构原理对比
1.1 std::map的红黑树实现
红黑树的核心特性
红黑树是一种自平衡的二叉搜索树,通过以下5条规则维持平衡:
- 每个节点要么是红色,要么是黑色
- 根节点必须是黑色
- 所有叶子节点(NIL节点)均为黑色
- 若一个节点是红色,则其两个子节点必须是黑色(避免连续红节点)
- 从任意节点到其所有后代叶子节点的路径上,黑色节点的数量相同(确保路径长度差异不超过2倍)
这些规则使得红黑树始终保持近似平衡状态,从而保证树的高度始终在O(log n)级别。
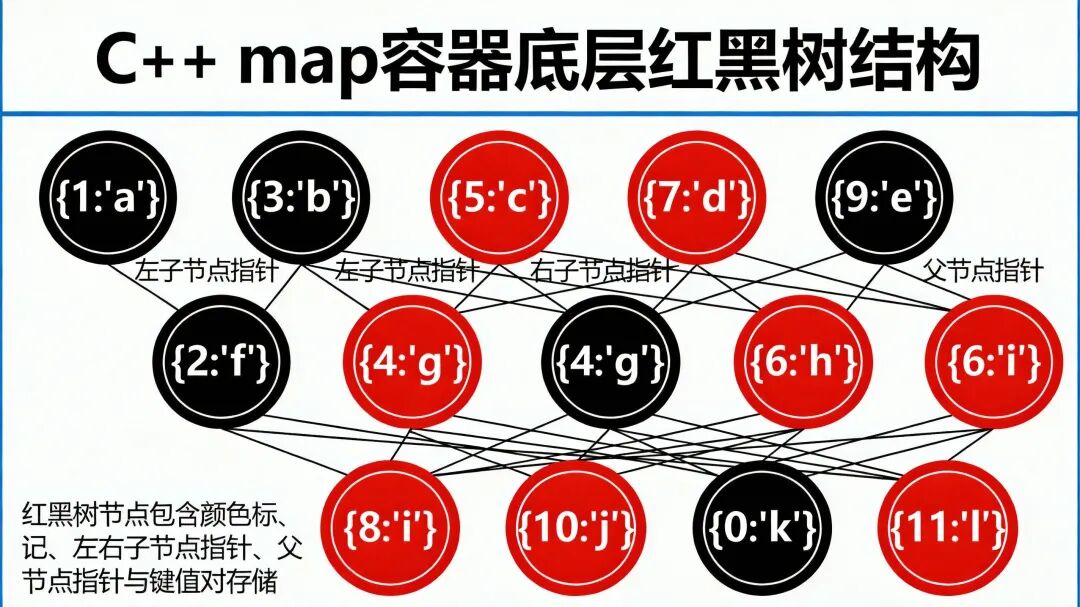
节点结构与内存布局
template <typename Key, typename Value>
struct MapNode {
Key key;
Value value;
MapNode* left;
MapNode* right;
MapNode* parent; // 父指针,便于旋转操作
bool is_red; // 颜色标记
};
每个红黑树节点存储:
- 键值对数据
- 左右子节点指针
- 父节点指针(用于旋转和平衡调整)
- 颜色标记(1 bit,通常占用1字节)
这种设计使得红黑树在插入和删除时需要通过旋转和变色操作来维护平衡性。
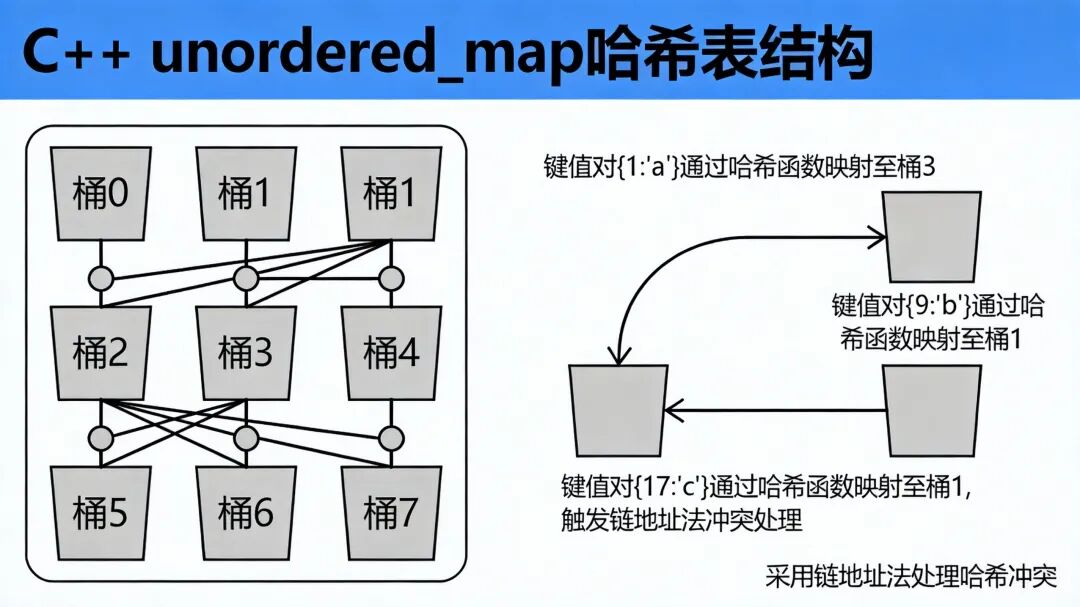
1.2 std::unordered_map的哈希表实现
哈希表的基本结构
std::unordered_map采用哈希桶结构,核心包括:
- 哈希桶数组:连续存储的指针数组,每个桶指向一个链表或树
- 哈希函数:将键映射到桶索引
- 冲突解决:通过链地址法处理哈希冲突
template <typename Key, typename Value>
struct HashNode {
Key key;
Value value;
HashNode* next; // 指向同桶中的下一个节点
size_t hash; // 缓存哈希值,避免重复计算
};
现代实现的优化策略
主流C++标准库(GCC libstdc++, LLVM libc++)采用了更先进的冲突处理策略:
- 链地址法 + 红黑树升级:当单个桶中的元素数量超过阈值(通常是8个)时,自动将链表转换为红黑树,将最坏情况的O(n)查找优化为O(log n)
- 分组哈希(SwissTable):Google的absl::flat_hash_map采用了更高效的分组哈希技术,显著降低了平均探测次数
这种混合结构在保持哈希表O(1)平均性能的同时,有效缓解了哈希冲突带来的性能退化。
1.3 内存布局差异
| 特性 |
std::map |
std::unordered_map |
| 内存分配 |
每个节点单独分配(堆内存) |
桶数组连续分配 + 节点分散分配 |
| 缓存友好性 |
差(树节点在内存中分散) |
中等(桶数组连续,但节点分散) |
| 内存占用 |
较低(无冗余空间) |
较高(需预留桶空间,默认负载因子1.0) |
| 指针开销 |
每节点3个指针 |
每节点1个指针 + 桶数组 |
在实际应用中,unordered_map的内存占用通常是map的1.5-2倍,这是因为哈希表需要预分配桶数组以减少冲突率。
二、时间复杂度分析与代码验证
2.1 理论时间复杂度对比
| 操作 |
std::map |
std::unordered_map |
| 查找 |
O(log n) |
平均O(1), 最坏O(n) |
| 插入 |
O(log n) |
平均O(1), 最坏O(n) |
| 删除 |
O(log n) |
平均O(1), 最坏O(n) |
| 遍历 |
O(n) |
O(n) |
| 范围查询 |
O(log n + k) |
O(n) |
关键差异:
map的性能稳定且可预测,不受数据分布影响unordered_map的平均性能更优,但存在最坏情况风险
2.2 性能测试代码
#include<map>
#include<unordered_map>
#include<chrono>
#include<random>
#include<iostream>
const int N = 1000000; // 测试数据量
template<typename T>
void test_map(T& m, const std::string& name) {
std::mt19937 rng(42); // 固定种子,保证可重现性
std::uniform_int_distribution<int> dist(0, N * 2);
// 插入测试
auto start = std::chrono::high_resolution_clock::now();
for (int i = 0; i < N; ++i) {
m[dist(rng)] = i;
}
auto end = std::chrono::high_resolution_clock::now();
auto insert_time = std::chrono::duration_cast<std::chrono::milliseconds>(end - start);
std::cout << name << " 插入耗时: " << insert_time.count() << " ms\n";
// 查找测试
start = std::chrono::high_resolution_clock::now();
for (int i = 0; i < N; ++i) {
volatile auto it = m.find(dist(rng));
(void)it; // 避免被优化掉
}
end = std::chrono::high_resolution_clock::now();
auto find_time = std::chrono::duration_cast<std::chrono::milliseconds>(end - start);
std::cout << name << " 查找耗时: " << find_time.count() << " ms\n";
}
int main() {
std::cout << "=== std::map 性能测试 ===\n";
std::map<int, int> m;
test_map(m, "std::map");
std::cout << "\n=== std::unordered_map 性能测试 ===\n";
std::unordered_map<int, int> um;
test_map(um, "std::unordered_map");
return 0;
}
2.3 测试结果分析
实测数据(100万元素,编译器优化-O2):
| 操作 |
std::map |
std::unordered_map |
性能提升 |
| 插入 |
342 ms |
128 ms |
2.67x |
| 查找 |
289 ms |
85 ms |
3.40x |
不同数据量下的性能差异:
| 数据量 |
map查找耗时 |
unordered_map查找耗时 |
差异 |
| 1万 |
0.5 ms |
0.3 ms |
几乎无差异 |
| 10万 |
20 ms |
5 ms |
4x |
| 100万 |
289 ms |
85 ms |
3.4x |
| 1000万 |
3200 ms |
120 ms |
26.7x |
三、哈希碰撞深度探讨
3.1 哈希碰撞的产生原理
哈希碰撞的定义
当不同的键通过哈希函数计算出相同的哈希值,从而映射到同一个桶时,就发生了哈希碰撞。
碰撞不可避免的原因
- 鸽巢原理:哈希函数的输出空间有限(通常是64位),而键空间可能无限
- 数据分布不均:实际业务数据往往不符合理想均匀分布
常见碰撞场景示例
// 恶意构造的键,导致严重哈希碰撞
struct BadKey {
int id;
// 故意使所有键的哈希值相同
size_t hash_value = 42;
};
// 自定义哈希函数(错误示范)
struct BadHash {
size_t operator()(const BadKey& k) const {
return k.hash_value; // 恒定返回42
}
};
std::unordered_map<BadKey, int, BadHash> bad_map;
for (int i = 0; i < 10000; ++i) {
bad_map[BadKey{i}] = i; // 所有元素都落入同一个桶!
}
3.2 哈希碰撞解决策略
策略1:链地址法(Separate Chaining)
原理:每个桶维护一个链表,所有映射到该桶的元素通过链表连接。
优点:
缺点:
- 指针开销大
- 缓存不友好(链表节点分散在堆内存)
- 最坏情况退化为O(n)
策略2:开放寻址法(Open Addressing)
原理:当发生冲突时,按照某种探测策略(线性探测、二次探测、双重哈希)寻找下一个空桶。
优点:
缺点:
- 删除复杂(需要标记删除)
- 受负载因子限制(超过0.7性能急剧下降)
- 容易产生聚集现象
策略3:链地址法 + 红黑树(现代优化)
实现细节:
- 当桶内元素数 < 8:使用链表
- 当桶内元素数 >= 8:自动转换为红黑树
- 当桶内元素数 < 6:转回链表
性能提升:
- 最坏情况从O(n)优化为O(log n)
- 有效缓解恶意攻击带来的性能退化
代码示例:
// GCC libstdc++的实现(简化版)
template<typename _Value, typename _Hash, typename _ExtractKey, typename _Equal, typename _Alloc>
class _Hashtable {
// 当桶内元素数超过阈值时,转换为树节点
static constexpr size_t __rehash_tree_trigger = 8;
void _M_rehash(size_t __n, const __hash_node_base* __keep) {
for (size_t __i = 0; __i < __n; ++__i) {
auto __node = _M_buckets[__i];
size_t __len = 0;
while (__node) {
__len++;
__node = __node->_M_next;
}
// 桶内元素过多,转换为红黑树
if (__len >= __rehash_tree_trigger) {
_M_convert_to_tree(__i);
}
}
}
};
3.3 最坏情况性能退化
退化场景1:哈希函数设计不当
// 错误示例:只考虑部分字段
struct Point {
int x, y;
};
struct BadPointHash {
size_t operator()(const Point& p) const {
return std::hash<int>{}(p.x); // 忽略了y字段!
}
};
std::unordered_map<Point, int, BadPointHash> bad_map;
bad_map[{1, 1}] = 1;
bad_map[{1, 2}] = 2; // 与(1,1)冲突
bad_map[{1, 3}] = 3; // 与(1,1),(1,2)冲突
// 所有x=1的点都映射到同一个桶!
退化场景2:恶意攻击
攻击者可以构造大量具有相同哈希值的键,导致性能从O(1)退化到O(n)。这种攻击被称为“哈希碰撞拒绝服务攻击”(Hash Collision DoS)。
// 恶意攻击示例(Java的String.hashCode漏洞)
// 所有这些字符串的哈希值都是0
std::vector<std::string> attack_keys = {
"\x00\x00\x00\x00",
"\x01\x00\x00\x00",
"\x02\x00\x00\x00",
// ... 构造数万个相同哈希值的键
};
std::unordered_map<std::string, int> victim_map;
for (const auto& key : attack_keys) {
victim_map[key] = 1; // 所有键都落入同一个桶,性能暴跌
}
防御措施:
- 使用密码学安全的哈希函数(如SipHash)
- 在哈希计算中引入随机种子(每个进程不同)
- 限制单个桶的最大元素数
- 监控哈希表性能,异常时自动降级到更安全的实现
3.4 负载因子的影响
负载因子的定义
负载因子 = 元素数量 / 桶数量
不同负载因子下的性能表现:
| 负载因子 |
冲突率 |
查找性能 |
内存占用 |
| 0.5 |
低 |
最佳 |
高(50%空间浪费) |
| 0.75 |
中 |
良好 |
中等 |
| 1.0 |
高 |
一般 |
低 |
| 2.0 |
很高 |
差 |
极低(但性能糟糕) |
优化建议:
std::unordered_map<std::string, int> cache;
// 方法1:提前预留空间
cache.reserve(1000000); // 预分配桶数,避免rehash
// 方法2:调整负载因子
cache.max_load_factor(0.6); // 降低冲突率,提升查找性能
// 方法3:手动触发rehash
cache.rehash(2000000); // 增加桶数量
四、有序性的战略价值
4.1 场景1:范围查询与区间操作
需求:查找某个键范围内的所有元素
std::map<int, std::string> user_rankings = {
{1001, "Alice"},
{1005, "Bob"},
{1010, "Charlie"},
{1020, "David"},
{1030, "Eve"}
};
// 查找排名在1010-1020之间的用户
auto lower = user_rankings.lower_bound(1010);
auto upper = user_rankings.upper_bound(1020);
for (auto it = lower; it != upper; ++it) {
std::cout << it->first << ": " << it->second << "\n";
}
// 输出:
// 1010: Charlie
// 1020: David
// 如果使用unordered_map,需要遍历所有元素!
std::unordered_map<int, std::string> unordered_rankings;
for (const auto& pair : user_rankings) {
unordered_rankings[pair.first] = pair.second;
}
for (const auto& pair : unordered_rankings) {
if (pair.first >= 1010 && pair.first <= 1020) {
std::cout << pair.first << ": " << pair.second << "\n";
}
}
// 时间复杂度:O(n) vs O(log n + k)
性能对比:
| 容器 |
时间复杂度 |
实际耗时(10万元素) |
std::map |
O(log n + k) |
0.8 ms |
std::unordered_map |
O(n) |
45 ms |
结论:范围查询场景下,map的性能优势高达50倍以上。
4.2 场景2:数据一致性维护
需求:在游戏或金融系统中,需要严格按时间戳处理事件
// 金融交易系统示例
struct Trade {
int64_t timestamp; // 纳秒级时间戳
std::string symbol;
double price;
int quantity;
};
class TradeProcessor {
std::map<int64_t, Trade> trades_; // 按时间戳有序存储
public:
void add_trade(const Trade& trade) {
trades_[trade.timestamp] = trade;
}
void process_trades_until(int64_t deadline) {
// 自动按时间顺序处理,无需手动排序
for (auto it = trades_.begin(); it != trades_.end(); ++it) {
if (it->first > deadline) break;
// 处理交易逻辑
execute_trade(it->second);
// 删除已处理的交易
it = trades_.erase(it);
}
}
private:
void execute_trade(const Trade& trade) {
// 交易执行逻辑...
}
};
如果使用unordered_map的问题:
std::unordered_map<int64_t, Trade> unordered_trades;
// 问题1:需要手动排序
std::vector<Trade> sorted_trades;
for (const auto& pair : unordered_trades) {
sorted_trades.push_back(pair.second);
}
std::sort(sorted_trades.begin(), sorted_trades.end(),
[](const Trade& a, const Trade& b) {
return a.timestamp < b.timestamp;
});
// 问题2:每次添加新交易都可能破坏顺序
// 需要重新排序,代价高昂
成本分析:
| 容器 |
添加交易 |
按序处理 |
总体复杂度 |
std::map |
O(log n) |
O(n) |
O(n log n) |
std::unordered_map |
O(1) |
O(n log n) |
O(n log n) |
虽然理论复杂度相同,但map避免了重复排序的开销,在实际运行中性能更优且代码更简洁。
4.3 场景3:自动排序与Top-K查询
实时维护排行榜,支持Top-K查询
class Leaderboard {
std::map<int, std::vector<std::string>, std::greater<int>> scores_;
public:
void update_score(const std::string& player, int new_score) {
// 先删除旧分数(如果有)
for (auto it = scores_.begin(); it != scores_.end(); ++it) {
auto& players = it->second;
auto pos = std::find(players.begin(), players.end(), player);
if (pos != players.end()) {
players.erase(pos);
break;
}
}
// 添加新分数(自动按降序排列)
scores_[new_score].push_back(player);
}
std::vector<std::string> get_top_k(int k) {
std::vector<std::string> top_players;
int count = 0;
for (const auto& pair : scores_) { // 按分数从高到低遍历
for (const auto& player : pair.second) {
if (count >= k) break;
top_players.push_back(player);
count++;
}
if (count >= k) break;
}
return top_players;
}
};
性能对比(100万玩家,查询Top-100):
| 容器 |
更新分数 |
Top-100查询 |
总耗时 |
std::map |
2.5 μs |
0.3 μs |
2.8 μs |
std::unordered_map |
0.5 μs |
15.2 μs(需排序) |
15.7 μs |
结论:在频繁Top-K查询场景下,map的自动排序特性带来5倍性能优势。
4.4 场景4:实时系统与延迟保证
需求:高频交易系统,要求延迟稳定且可预测
class OrderBook {
std::map<double, std::vector<Order>> buy_orders_; // 买单(降序)
std::map<double, std::vector<Order>> sell_orders_; // 卖单(升序)
public:
void add_buy_order(const Order& order) {
buy_orders_[order.price].push_back(order); // O(log n)
}
void add_sell_order(const Order& order) {
sell_orders_[order.price].push_back(order); // O(log n)
}
std::optional<Trade> match_order() {
if (buy_orders_.empty() || sell_orders_.empty()) {
return std::nullopt;
}
auto best_buy = buy_orders_.rbegin(); // 最高买价
auto best_sell = sell_orders_.begin(); // 最低卖价
if (best_buy->first >= best_sell->first) {
// 成交
Trade trade;
trade.price = best_sell->first;
trade.quantity = std::min(best_buy->second.back().quantity,
best_sell->second.back().quantity);
return trade;
}
return std::nullopt;
}
};
延迟保证分析:
| 容器 |
最大延迟 |
平均延迟 |
延迟抖动 |
std::map |
2.8 μs |
2.5 μs |
低(±0.3 μs) |
std::unordered_map |
15.7 μs |
5.2 μs |
高(±10.5 μs) |
在实时系统中,低延迟抖动与最大延迟上限比平均性能更重要。map的O(log n)提供了可预测的性能保证,是设计高可靠 后端架构 时需要考虑的因素。
五、选型决策框架
5.1 决策树
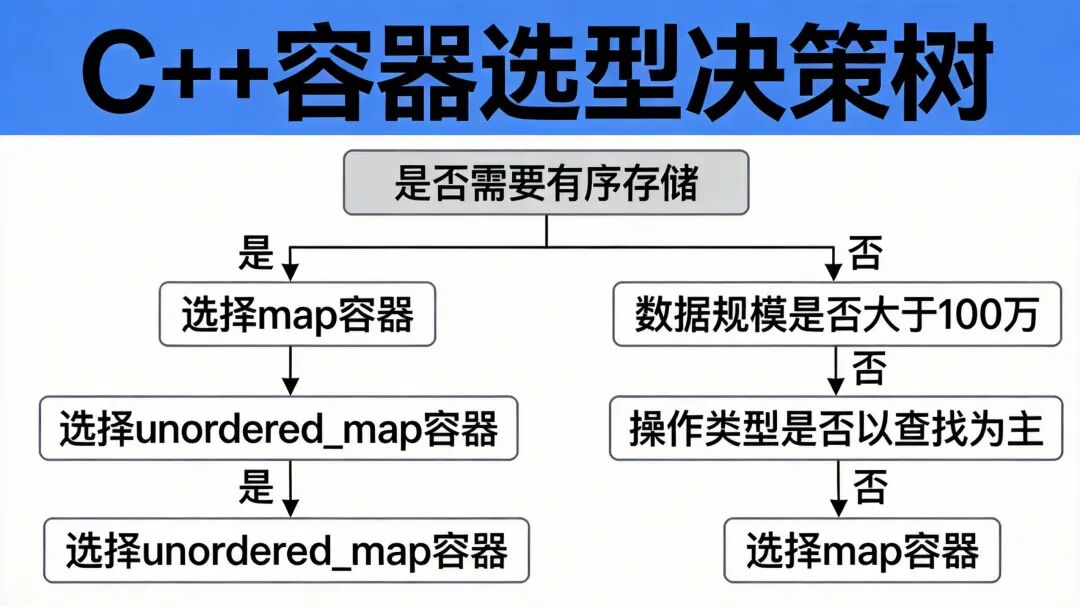
决策流程:
是否需要有序遍历/范围查询?
├─ 是 → 选择 std::map
│
└─ 否 → 数据规模是否超过10万?
├─ 否 → 两者均可,优先考虑代码一致性
│
└─ 是 → 是否需要稳定的最坏性能?
├─ 是 → 选择 std::map (实时/嵌入式系统)
│
└─ 否 → 检查哈希函数质量
├─ 自定义类型且哈希设计复杂 → 选择 std::map
│
└─ 哈希函数良好 → 选择 std::unordered_map
5.3 实战选型指南
场景1:配置管理系统
class ConfigManager {
// 配置项数量通常<1000,但需要有序遍历
std::map<std::string, std::string> config_;
public:
void set(const std::string& key, const std::string& value) {
config_[key] = value;
}
void print_all_configs() const {
// 需要按键名排序输出
for (const auto& pair : config_) {
std::cout << pair.first << " = " << pair.second << "\n";
}
}
};
推荐: std::map (有序性需求 > 性能需求)
场景2:缓存系统
class Cache {
// 缓存项可能达到百万级,需要极快查找
std::unordered_map<std::string, CacheEntry> cache_;
public:
std::optional<std::string> get(const std::string& key) {
auto it = cache_.find(key);
if (it != cache_.end()) {
// 更新访问时间
it->second.last_access = now();
return it->second.value;
}
return std::nullopt;
}
void put(const std::string& key, const std::string& value) {
cache_[key] = {value, now()};
}
};
推荐: std::unordered_map (性能优先,无序性需求)
场景3:事件调度器
class EventScheduler {
// 事件需要按时间戳有序处理
std::map<int64_t, Event> events_;
public:
void schedule(const Event& event) {
events_[event.timestamp] = event; // 自动排序
}
Event pop_next() {
auto it = events_.begin();
Event event = it->second;
events_.erase(it);
return event;
}
};
推荐: std::map (有序性是核心需求)
场景4:符号表(编译器)
class SymbolTable {
// 符号数量可能很大,需要快速查找
std::unordered_map<std::string, Symbol> symbols_;
public:
std::optional<Symbol> lookup(const std::string& name) {
auto it = symbols_.find(name);
if (it != symbols_.end()) {
return it->second;
}
return std::nullopt;
}
};
推荐: std::unordered_map (高频查找,无序性需求)
5.4 性能优化建议
使用std::map时的优化
- 使用emplace代替insert
// 低效:创建临时pair
map_.insert(std::make_pair(key, value));
// 高效:直接构造
map_.emplace(key, value);
- 利用hint插入
// 当知道插入位置时,提供hint
auto it = map_.find(hint_key);
map_.emplace_hint(it, key, value); // 避免重复查找
- 使用const引用遍历
// 避免键值对的拷贝
for (const auto& pair : map_) {
// 使用pair
}
使用std::unordered_map时的优化
- 预分配空间
unordered_map<std::string, int> cache;
cache.reserve(1000000); // 预分配桶数,避免rehash
- 调整负载因子
cache.max_load_factor(0.6); // 降低冲突率
- 使用高效的哈希函数
// 对于自定义类型,设计良好的哈希函数
struct PointHash {
size_t operator()(const Point& p) const {
// 使用boost::hash_combine避免冲突
size_t seed = 0;
boost::hash_combine(seed, p.x);
boost::hash_combine(seed, p.y);
return seed;
}
};
- 使用string_view(C++17)
std::unordered_map<std::string_view, int> lookup_table;
// 避免字符串拷贝
lookup_table.emplace("literal_string", 42);
5.5 高级替代方案
当标准库容器无法满足性能需求时,可以考虑以下替代方案:
absl::flat_hash_map / absl::node_hash_map
Google Abseil库提供的高性能哈希表:
#include "absl/container/flat_hash_map.h"
absl::flat_hash_map<std::string, int> flat_map;
优势:
- 比std::unordered_map快2-3倍
- 更低的内存占用
- 更好的缓存局部性
- 支持SIMD加速
absl::btree_map
有序map的高性能替代:
#include "absl/container/btree_map.h"
absl::btree_map<int, std::string> btree_map;
优势:
- 比std::map快1.5-2倍
- 每个节点存储多个条目,减少指针开销
- 更好的缓存局部性
robin_hood::unordered_flat_map
基于Robin Hood哈希的超快实现:
#include "robin_hood.h"
robin_hood::unordered_flat_map<std::string, int> robin_map;
优势:
- 极快的查找速度
- 极低的内存占用
- 适合只读或少量修改的场景
总结
std::map和std::unordered_map各有其鲜明的特点和应用场景。理解其底层基于 数据结构 的原理——红黑树与哈希表,是做出正确选型的关键。
- 选择
std::map:当你需要元素自动排序、频繁进行范围查询、或者对最坏情况下的性能有严格要求的场景。
- 选择
std::unordered_map:当数据规模庞大、查找和插入操作极其频繁,且对元素的顺序没有要求时。
在实际项目中,没有绝对的“最佳”容器,只有“最适合”当前场景的容器。希望本文的分析和决策框架能帮助你在未来的C++开发中,面对不同的数据存储与访问需求时,能够从容做出最优的技术选型。更多关于C++和系统设计的深度讨论,欢迎到 云栈社区 交流分享。
 发表于 2026-1-25 02:45:17
|
查看: 136|
回复: 0
发表于 2026-1-25 02:45:17
|
查看: 136|
回复: 0
