本文作者:@羑悻的小杀马特.( youxing.blog.csdn.net )来源:CSDN
《云栈知识库》导读:
说实话,搞 高并发 架构,缓存就是咱们的半条命。平时大家闭着眼睛都在用 LRU,但 LRU 有个巨坑:稍微碰上点突发的扫库流量,真正的“长期热点”(像电商爆款、CDN 经典视频)分分钟被洗得干干净净,直接导致缓存击穿。
想死死护住这些长期热点,就得靠 LFU(最不经常使用)算法。但坦白讲,原生的 LFU 每次更新频率都得遍历,O(n) 的时间复杂度在生产环境简直是灾难。今天,咱们在 云栈社区 ( YunPan.Plus ) 拆解一篇硬核干货,看看大佬是怎么用“双哈希表 + 双向链表”这种反直觉的 数据结构,把 LFU 硬生生优化到 O(1) 的。这波操作,确实有点东西。
在处理高并发系统的缓存策略时,如何精准留住那些长期被频繁访问的热点数据?
今天,我们探讨一下 LFU(Least Frequently Used,最不经常使用)缓存淘汰算法。本文将带你深入理解 LFU 的核心原理,并通过双哈希表结合双向链表的方式,手把手实现具有 O(1) 时间复杂度的高效缓存结构。

一、LFU 缓存淘汰算法核心原理
LFU 的底层逻辑其实很粗暴:优先淘汰历史访问频率最低的数据。这是一种基于长期统计维度的淘汰策略。
在 LFU 缓存中,每个条目都需要维护两个核心属性:键值对数据本身,以及一个访问频率计数器。
当缓存容量达到预设上限时,系统会找出当前所有数据中访问频率最低的条目并将其淘汰。如果碰巧有多个数据的最低频率相同,则会退化为类似 LRU 的兜底逻辑,淘汰其中最久未被访问的那个。
核心操作流程如下:
- 访问数据时:如果命中缓存,该数据的访问频率加 1 ,并在频率排序中调整位置,确保高频数据优先保留(通常移至双向链表的头部)。
- 写入新数据时:如果缓存未满,直接插入新数据,初始频率通常设为 1 。如果缓存已满,必须先淘汰频率最低的数据,腾出空间后再写入新条目。如果写入的 key 已经存在,则更新对应的 value ,并调整其访问频率。
二、用双哈希表与双向链表实现 O(1) 复杂度
1. 数据结构设计(高效实现的核心)
真要把 LFU 扔进生产环境,性能是道坎。为了达到极致的性能,LFU 通常采用双哈希表配合频率双向链表的组合,以此来实现 O(1) 时间复杂度的各项操作。
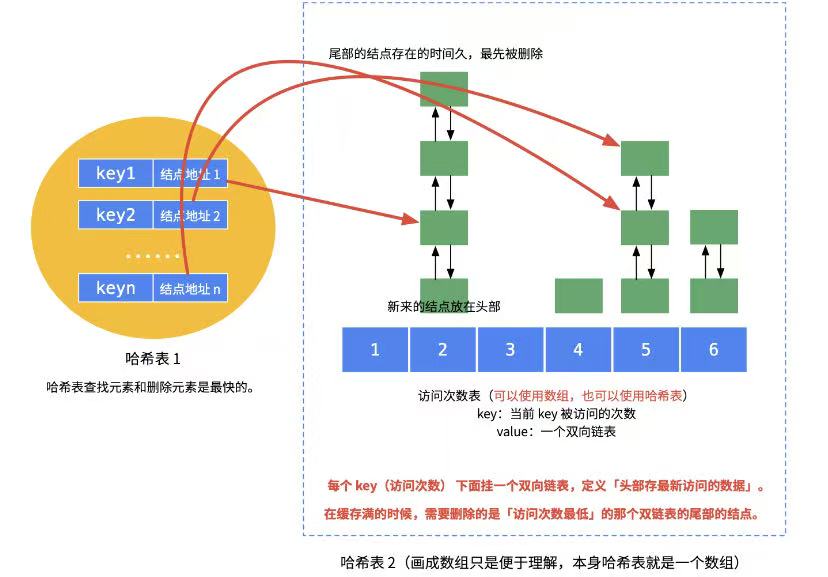
- 存储哈希表(Key-Node):负责存储键到缓存条目节点(Node)的映射。这能让我们快速定位数据,方便后续的频率更新操作。
- 频率哈希表:以频率值作为键,对应的值是一个存储 key 的双向链表。它维护了某个特定频率下的所有数据节点。双向链表支持快速的插入和删除。
- 最小频率计数器:实时记录当前缓存中最低的频率值。当触发淘汰机制时,可以直接通过它定位到需要淘汰的频率链表。
举个例子:当数据 A 被访问,其频率从 1 变成 2 ,系统需要将其从频率 1 的链表中移除,并插入到频率 2 的链表头部。如果有新数据 B 写入,它的初始频率为 1 ,就会被插入到频率 1 的链表中。
2. 频率动态更新
每次对缓存数据进行读写访问时,都会触发频率加 1 的更新操作:
- 首先,从原频率对应的链表中移除该数据节点。
- 其次,将频率值加 1 ,并把节点插入到新频率对应链表的头部,以此保证最近访问的数据始终在链表前端。
- 最后,更新全局最小频率。如果原最小频率所在的链表被清空了,最小频率计数器就需要加 1 。
3. C++ 核心代码实现与测试
接下来,我们用 C++ 来实现这个 LFU 算法逻辑。为了方便管理,我们存储的不是自定义节点的地址,而是 Node 对象本身。
对应的节点结构定义如下:
// 定义对应的节点结构:
template <class K, class V>
struct Node
{
Node() {} //表明对应的默认对象必须存在,hash[key] = Node()!!
Node(const K& key, const V& value, int access_count)
: key(key), value(value), access_count(access_count) {
}
K key;
V value;
// 存储对应key的访问次数:
int access_count;
// 对应节点的key值所在的list处的迭代器:
// 表明是类型不是list中的成员变量:
typename list<K>::iterator it; // 方便找到对应的list的具体位置,方便进行删除。
};
我们需要维护两个哈希表,以及缓存容量和最小频率计数器:
unordered_map<K, Node<K, V>> _hash_map; // 储存对应key值与对应的上述节点的hash
unordered_map<int, list<K>> _access_map; // 储存对应的访问次数的存放key的那个list
size_t _capacity; // 缓存最大容量,根据它进行决定进行对应的LFU策略更新
int _min_access_count; // 储存最少的访问次数,方便进行删除
LFU 最大的特色在于它的访问频率更新策略。当我们 put 或 get 一个数据时,对应的访问频次增加(默认加 1 ),此时必须调整维护频率的哈希表,及时进行链表节点的删除与重新挂载。
需要特别注意的是:
- 操作过程中必须时刻维护
_min_access_count,这是高效淘汰的关键。
- 两个哈希表是强关联的。如果移除了链表中的节点,第一个哈希表中的映射也要视情况处理。
- 如果某个频率的链表在删除节点后变为空,必须及时移除第二个哈希表中的对应槽位。
// 对于put或者get后进行对应的数据的访问次数等操作进行统一处理(比如进行LFU策略删除等)
void accessCountAdd(const K& key)
{
// 获取对应节点
Node<K, V>& node = _hash_map[key];
int old_access_cnt = node.access_count;
list<int>& cur_list = _access_map[old_access_cnt];
cur_list.erase(node.it);
// 删除后进行判断,如果访问的hash对应list空了,直接删除这个hash槽即可
if (cur_list.empty())
{
_access_map.erase(old_access_cnt);
// 如果恰好是最少的,更新下最小的即可
if (old_access_cnt == _min_access_count)
// 如果删除完对应的之前的key所在的list后,为空了而且此时对应的min_cnt也是当前key的cnt,此时说明min_cnt必须要+1完成更新了
_min_access_count++;
}
// 此时除了有可能它俩相同,就是cur_list不为空的情况,或者不等:
// 进行更新访问次数:
int new_access_cnt = old_access_cnt + 1;
node.access_count = new_access_cnt;
// 再次更新下,这里保险起见:
_min_access_count = min(_min_access_count, new_access_cnt);
// 把对应的key加入到新的list中:
auto& new_list = _access_map[new_access_cnt]; // 这里需要引用,因为后续会进行修改
new_list.push_front(node.key);
// 务必要更新对应迭代器:
node.it = new_list.begin();
}
接下来提供核心的 get 与 put 接口。
对于 get 操作,通过哈希表快速查找。如果不存在则返回默认构造;如果存在,返回对应 value 并触发频率更新策略。
V get(const K& key)
{
// 先判断是否存在这个key:
if (_hash_map.find(key) == _hash_map.end())
return V(); //有点瑕疵,一般都是int int ,直接返回-1
// 存在这个key,进行访问次数+1:
accessCountAdd(key);
return _hash_map[key].value;
}
对于 put 操作,先去第一个哈希表查找 key 是否存在:
- 如果存在,直接更新 value ,再执行频率更新策略。
- 如果不存在,需要插入新数据。插入前检查容量是否已满,若满则根据
_min_access_count 淘汰数据,然后再执行插入。
bool put(const K& key, const V& val)
{
// 1.判断容量是否为0:
if (_capacity <= 0)
return false;
//进行查找:
auto it = _hash_map.find(key);
if (it != _hash_map.end()) {
// 存在这个key,直接更新对应的值并根据对应LFU策略进行对应处理:
_hash_map[key].value = val;
// 2.更新访问次数:
accessCountAdd(key);
return true;
}
// 不存在,检查容量(根据LFU策略更新),插入新的:
// it==_hash_map.end()
if (_capacity <= _hash_map.size())
{
// 容量已满,执行LFU策略:
// 找到访问次数最少的list,也就是是最不经常使用的那一批数据:
auto& min_list = _access_map[_min_access_count];
// 根据LRU策略删除最近最少使用的key:
auto evict_key = min_list.back();
min_list.pop_back();
// 判断是否这个list为空了,进行删除:
if (min_list.empty())
_access_map.erase(_min_access_count);
_hash_map.erase(evict_key);
}
// 不存在直接构造插入:
// 3.插入新节点:
auto& new_list = _access_map[1]; // 这里是1,因为是新插入的节点,访问次数为1
_hash_map[key] = Node<K, V>(key, val, 1); // 这里也需要告诉编译器是个类型不是变量!!
// 4.更新访问次数hash:
new_list.push_front(key);
// 更新对应的key的node的迭代器
_hash_map[key].it = new_list.begin();
_min_access_count = 1;
return true;
}
避坑指南:必须先从哈希表中查找节点,确认不存在后,再去判断容量是否已满并执行淘汰。绝对不能一上来就判满。否则,如果缓存已满,你先淘汰了一个数据,但随后发现要插入的 key 其实已经存在(本应只是更新操作),这就导致了无辜数据的误删。
联合测试代码如下:
LFUCache<int, int> cache(3);
cache.put(1, 10);
cache.put(2, 20);
cache.put(3, 30);
cache.printCache();
cout << endl;
// 访问键1,增加其访问次数
cout << "Get key 1: " << cache.get(1) << endl;
cache.printCache();
cout << endl;
// 添加新键4,应淘汰访问次数最低的键2
cache.put(4, 40);
cache.printCache();
cout << endl;
// 再次访问键3,增加其访问次数
cout << "Get key 3: " << cache.get(3) << endl;
cache.printCache();
cout << endl;
// 添加新键5,应淘汰访问次数最低的键4
cache.put(5, 50);
cache.printCache();
运行效果展示:
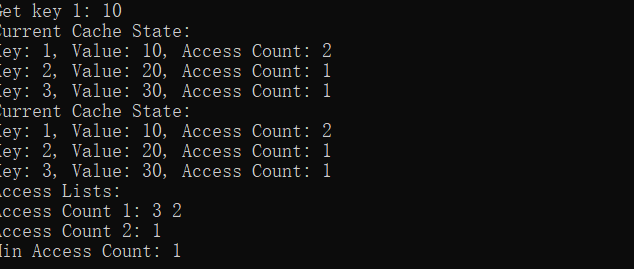
插入 key 为 1、2、3:

查询 key 为 1 的数据:
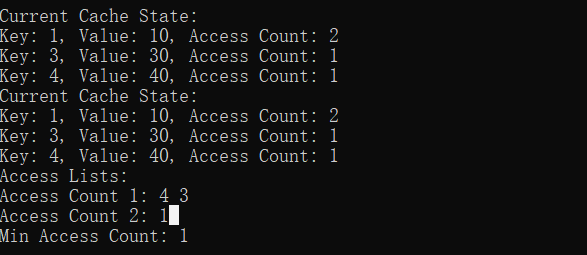
插入 key 为 4 时,必然淘汰之前 key 为 2 的数据:
访问 key 为 3 ,然后插入 key 为 5 ,必然淘汰 key 为 4 的数据:
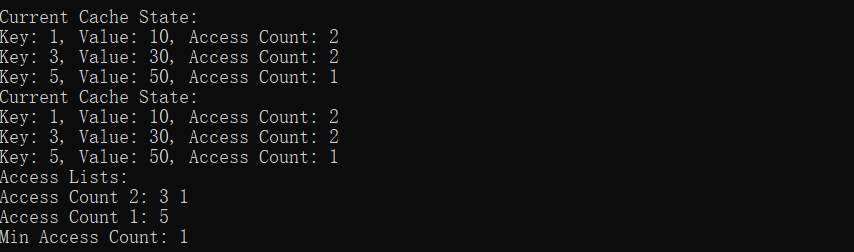
测试结果完全符合预期,证明这个简易版本的 LFU 缓存算法逻辑是可靠的。
4. 为什么 LFU 要用双哈希表 + 双向链表?
LFU 最大的麻烦在于:缓存满时需要快速淘汰访问频率最低的数据,且每次访问数据都要快速更新其频率。如果使用普通数组或单链表,寻找最低频率或移动节点往往需要 O(n) 的遍历时间,这在生产环境场景下是不可接受的。
为了保证所有操作(查、增、删、频率更新)都具备 O(1) 的时间复杂度,我们采用了如下设计策略:
- 哈希表 1(键值映射):存储
key → 节点,实现 O(1) 快速定位数据。
- 哈希表 2(频率链表映射):存储
频率 → 双向链表,将相同频率的数据串联起来,方便整组操作。
- 双向链表:每个频率对应的链表内部,数据按访问时间排序(头部最新,尾部最久)。这相当于在相同频率的数据中引入了 LRU 机制,方便 O(1) 找到同频率中最该淘汰的尾部节点。
- 最小频率计数器:直接记录当前最低频率,淘汰时无需遍历所有频率即可 O(1) 定位。
三、典型优势与劣势
优势场景

- 长期热点稳定:非常适合访问频率长期集中的数据,例如经典文章、爆款商品、CDN 热门视频。高频数据因为频率持续累积,会被牢牢锁定在缓存中,大幅减少后端计算和加载开销。
- 理论最优性:在访问频率完全可预测且稳定的理想场景下,LFU 能够最大化缓存命中率,长期高频数据几乎永远不会被淘汰。
劣势与挑战

- 冷启动问题(新数据劣势):新来的数据初始频率通常为 0 或 1 。即使它在近期被疯狂访问,也极有可能因为总频率拼不过历史高频数据,而在缓存满时被无情淘汰。比如突然爆火的新商品根本挤不进缓存池。
- 旧高频霸占问题:有些数据曾经是绝对的热点(如过季商品、旧闻),积累了极高的频率,但当前已经无人问津。它们凭借早期的频率优势长期霸占缓存槽位,导致真正的新热点无法进入。
- 实现复杂度高:需要同时维护频率链表、最小频率计数器等多个结构,代码实现难度显著高于 LRU 。
四、LFU 算法在生产环境的冷启动优化
1. 新数据冷启动优化

- 初始频率加成:将新数据的初始频率适当调高(如设为 1 或 2 ),避免一进来就因为频率垫底被秒杀。
- 预热机制:对于已知即将爆发的高频新数据(如运营主推的新品),系统可以手动为其初始化一个较高的频率。
- 混合策略:借鉴 LRU 的思想,给新数据设置一个短期的“保护期”。例如,新数据的前 N 次访问不参与频率竞争。
2. 频率衰减(避免历史权重过高)
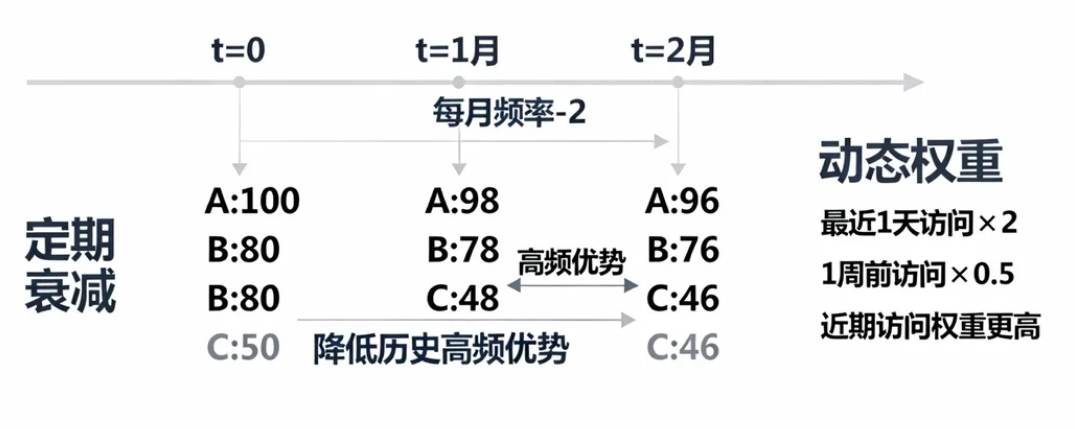
- 定期衰减:设计一个定时任务,每隔一段时间将所有数据的频率值减半(或减去固定值)。这样可以有效削弱历史高频数据的绝对优势,让近期活跃的数据更容易脱颖而出。
- 动态权重:引入时间衰减因子,赋予近期访问更高的频率权重。例如,最近 1 天的访问算作 2 次,而 1 周前的访问只算作 0.5 次。
五、适用场景与典型用例
| 场景类型 |
具体例子 |
为什么适合 LFU ? |
| 长期稳定热点 |
CDN 热门视频缓存、经典文档/教程页 |
这些内容长期被高频访问,频率持续累积,LFU 能确保其长期驻留缓存。 |
| 爆款商品/内容 |
电商平台的限时爆款、社交媒体的热帖 |
爆款期间访问频率极高,LFU 会优先保留,支撑高并发请求。 |
| 低更新频率服务 |
在线词典的热门词条、百科经典词条 |
词条热度长期稳定,高频词条(如“人工智能”)会被持续缓存。 |
六、LFU 与 LRU 缓存算法深度对比
| 维度 |
LFU(最不经常使用) |
LRU(最近最少使用) |
| 判断依据 |
历史访问频率(总次数) |
最近一次访问时间(时间戳) |
| 核心优势 |
保护长期高频热点数据,命中率高 |
快速响应新流量,适应突发热点 |
| 主要劣势 |
新数据易被淘汰,旧高频数据可能霸占 |
旧高频数据可能被误淘汰,不保护长期热点 |
| 实现复杂度 |
较高(需维护频率结构) |
较低(只需维护访问时间顺序) |
| 典型场景 |
经典内容、爆款商品、CDN 稳定热点 |
浏览器缓存、数据库 Buffer Pool、新热点 |
| 变种优化 |
LFU-LRU 混合、频率衰减、初始频率加成 |
LRU-K(考虑最近 K 次访问)、ARC(自适应) |
七、总结与源码
LFU 是缓存世界里“时间的朋友”——谁被访问的次数越多,谁就越容易被保留。但在实际工程中,纯粹的 LFU 往往需要配合频率衰减、初始加成等优化策略,或者与 LRU 结合,才能在长期热点与短期突发流量之间找到完美的平衡。
附上完整的模板源码供大家参考实践:
👉 https://gitee.com/wang-yimingq/crazy-learning-cpp/blob/master/LFU-algorithm/LFU.cpp

《云栈知识库》点评:
看完这套源码级拆解,估计大家对“空间换时间”的套路又有了新感觉。用两个哈希表搞定定位和归类,再挂个双向链表维系时序,这种底层设计的确精妙。
但我觉得,纯粹的 LFU 在真实的业务里其实是个“半成品”。如果不加“时间衰减因子”和“冷启动保护”,新数据根本挤不进来,老热点占着茅坑不拉屎,最后缓存池直接变成一潭死水。业界很多中间件里的近似 LFU 实现,本质上都是在给这些坑打补丁。强烈建议大家把文中的 C++ 源码跑一遍,特别是 put 逻辑里“先查存在,再查容量”那个坑,真遇上面试手撕或者自己造轮子,能帮你省掉几个小时的 Debug 时间。
那么问题来了:既然 LFU 这么护着老数据,如果在电商大促这种“旧爆款迅速过气、新爆款瞬间涌入”的极端场景下,你觉得是该魔改 LFU,还是干脆退回去用 LRU 配合双层缓存?欢迎在评论区聊聊你的实战方案。
推荐探索云栈社区更多相关板块:
标签:#云栈社区 #云栈知识库 #LFU缓存算法 #数据结构 #高并发架构 #C++ #LRU
 发表于 2026-3-12 00:30:09
|
查看: 193|
回复: 0
发表于 2026-3-12 00:30:09
|
查看: 193|
回复: 0
