Kubernetes 已成为容器编排的事实标准,但很多团队在可观测性方面仍面临巨大挑战。本文将深入探讨 Kubernetes 可观测性的复杂性,分析常见误区,并提供一个从技术选型到实施落地的完整实践路径,帮助你构建真正高效、可持续的可观测性体系。
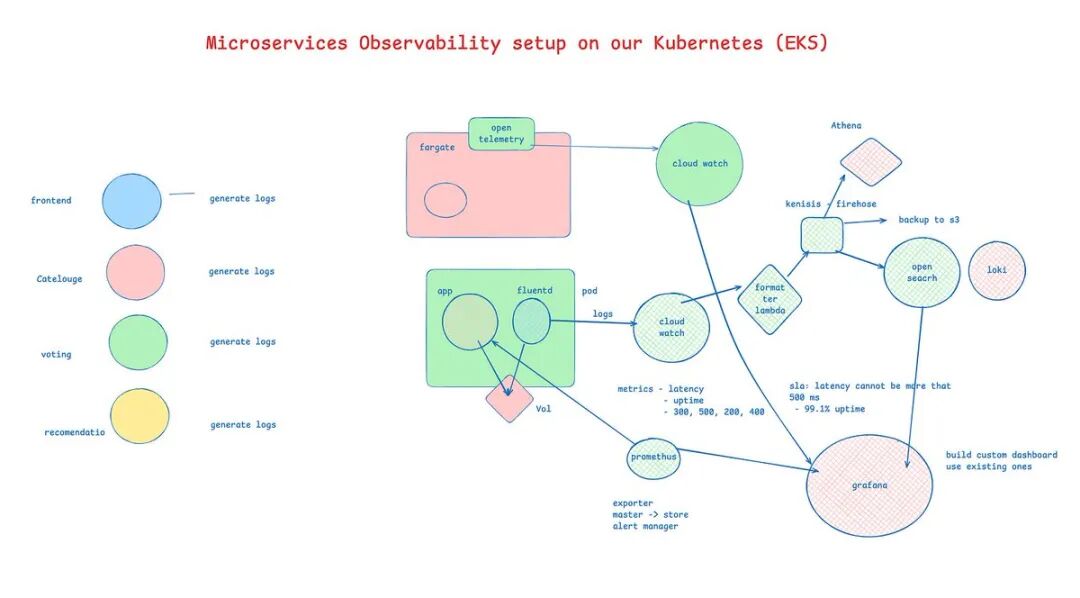
一、Kubernetes 可观测性的复杂性
1.1 动态性带来的挑战
Kubernetes 的核心特性是动态调度和自动扩缩容,这直接导致了传统监控手段的失效:
- Pod 生命周期短暂:容器随时可能被创建、销毁或迁移。
- IP 地址不固定:每次重启 Pod 都会获得新的 IP。
- 服务发现复杂:需要实时跟踪服务的实际位置。
- 标签和注解多变:元数据可能随部署而改变。
1.2 多层架构的监控难题
在 Kubernetes 环境中,你需要监控的层级远不止应用本身,还包括:
- 基础设施层:节点、网络、存储。
- Kubernetes 层:控制平面、API Server、调度器。
- 容器运行时层:Docker/containerd 性能。
- 应用层:业务指标、日志、追踪。
- 服务网格层:如使用 Istio/Linkerd 时的额外复杂性。
二、常见的错误做法
2.1 直接迁移传统监控方案
许多团队试图将传统的监控工具直接应用到 Kubernetes 上,这往往会失败。
❌ 错误示例:
- 使用静态 IP 配置监控目标。
- 依赖固定的主机名。
- 手动配置每个服务的监控规则。
✅ 正确做法:
- 采用服务发现机制。
- 使用标签选择器动态发现监控目标。
- 实现自动化的监控配置。
2.2 忽视 Cardinality(基数)问题
在 Kubernetes 环境中,指标的维度(标签)数量会急剧增加,这是一个容易被忽视的成本与性能杀手。
http_requests_total{
namespace="production",
pod="app-xyz123",
container="web",
node="node-5",
service="api",
version="v1.2.3",
endpoint="/users",
method="GET",
status="200"
}
问题:
- 标签组合数量呈指数级增长。
- 时序数据库存储压力巨大。
- 查询性能严重下降。
- 成本失控。
解决方案:
- 谨慎选择标签维度。
- 使用标签重写(relabeling)机制。
- 定期清理无用的时序数据。
- 使用采样策略。
2.3 缺乏统一的可观测性策略
常见问题:
- 日志、指标、追踪各自为政。
- 不同团队使用不同的工具栈。
- 数据孤岛严重,难以关联分析。
- 缺乏统一的数据模型。
三、构建 Kubernetes 可观测性的正确路径
3.1 建立可观测性的三大支柱
(1)指标(Metrics)
推荐技术栈:
- Prometheus:Kubernetes 原生指标收集。
- Thanos/Cortex:长期存储和联邦查询。
- Grafana:可视化展示。
关键指标:
# 集群健康度
- node_cpu_usage
- node_memory_usage
- node_disk_usage
- kube_node_status_condition
# Pod 状态
- kube_pod_status_phase
- kube_pod_container_status_restarts_total
- kube_pod_container_resource_requests
- kube_pod_container_resource_limits
# 应用性能
- http_request_duration_seconds
- http_requests_total
- grpc_server_handling_seconds
(2)日志(Logging)
推荐技术栈:
- Fluentd/Fluent Bit:日志收集。
- Loki:轻量级日志聚合。
- ELK Stack:传统方案(较重)。
最佳实践:
// 结构化日志示例
{
"timestamp": "2024-01-22T10:30:00Z",
"level": "error",
"message": "Database connection failed",
"service": "user-service",
"trace_id": "abc123xyz",
"span_id": "def456",
"pod": "user-service-7d9f8b-k2n4p",
"namespace": "production",
"error": "connection timeout after 30s"
}
关键要点:
- 使用结构化日志(JSON 格式)。
- 包含追踪 ID 以关联分布式调用。
- 添加 Kubernetes 元数据(pod、namespace 等)。
- 设置合理的日志级别和保留策略。
(3)追踪(Tracing)
推荐技术栈:
- OpenTelemetry:统一的可观测性标准。
- Jaeger:分布式追踪。
- Tempo:Grafana 的追踪后端。
价值:
- 可视化微服务间的调用关系。
- 定位性能瓶颈。
- 分析延迟来源。
- 排查跨服务的错误。
3.2 实施服务网格可观测性
如果使用服务网格(Istio/Linkerd),可以获得强大的、自动化的可观测性数据。
自动化指标:
- 请求成功率。
- 请求延迟(P50, P95, P99)。
- 服务间流量拓扑。
- 错误率和重试次数。
配置示例(Istio):
apiVersion: telemetry.istio.io/v1alpha1
kind: Telemetry
metadata:
name: custom-metrics
spec:
metrics:
- providers:
- name: prometheus
dimensions:
source_service: source.workload.name
destination_service: destination.workload.name
response_code: response.code
3.3 告警策略设计
告警分级:
| 级别 |
响应时间 |
示例 |
| P0 - 紧急 |
立即 |
生产环境服务完全不可用 |
| P1 - 严重 |
15 分钟内 |
性能严重下降,影响用户体验 |
| P2 - 重要 |
2 小时内 |
非核心功能异常 |
| P3 - 一般 |
下个工作日 |
潜在问题,需关注 |
告警规则示例:
groups:
- name: kubernetes-apps
rules:
# Pod 频繁重启
- alert: PodCrashLooping
expr: rate(kube_pod_container_status_restarts_total[15m]) > 0
for: 5m
labels:
severity: critical
annotations:
summary: "Pod {{ $labels.pod }} 正在频繁重启"
description: "命名空间 {{ $labels.namespace }} 中的 Pod {{ $labels.pod }} 在过去 15 分钟内重启了 {{ $value }} 次"
# 内存使用率过高
- alert: PodMemoryUsageHigh
expr: |
(container_memory_usage_bytes / container_spec_memory_limit_bytes) > 0.9
for: 5m
labels:
severity: warning
annotations:
summary: "Pod {{ $labels.pod }} 内存使用率超过 90%"
# 节点磁盘空间不足
- alert: NodeDiskSpaceLow
expr: |
(node_filesystem_avail_bytes / node_filesystem_size_bytes) < 0.1
for: 10m
labels:
severity: critical
annotations:
summary: "节点 {{ $labels.node }} 磁盘空间不足"
告警最佳实践:
- 避免告警疲劳:不要设置过多低优先级告警。
- 提供可操作性:告警信息应包含排查建议。
- 使用合理的阈值和持续时间。
- 定期审查和优化告警规则。
四、实战案例:构建端到端的可观测性
4.1 场景描述
假设我们有一个电商微服务应用:
frontend:Web 前端。product-service:商品服务。order-service:订单服务。payment-service:支付服务。inventory-service:库存服务。
4.2 可观测性实施步骤
第一步:部署 Prometheus Operator
# 使用 Helm 安装
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm install prometheus prometheus-community/kube-prometheus-stack \
--namespace monitoring \
--create-namespace
第二步:应用程序埋点
# Python 应用示例
from prometheus_client import Counter, Histogram
from opentelemetry import trace
from opentelemetry.instrumentation.flask import FlaskInstrumentor
# 初始化追踪
tracer = trace.get_tracer(__name__)
# 定义指标
http_requests_total = Counter(
'http_requests_total',
'Total HTTP requests',
['method', 'endpoint', 'status']
)
request_duration = Histogram(
'http_request_duration_seconds',
'HTTP request duration',
['method', 'endpoint']
)
@app.route('/api/products')
def get_products():
with tracer.start_as_current_span("get_products") as span:
with request_duration.labels('GET', '/api/products').time():
try:
products = fetch_products_from_db()
http_requests_total.labels('GET', '/api/products', '200').inc()
return jsonify(products)
except Exception as e:
http_requests_total.labels('GET', '/api/products', '500').inc()
span.set_attribute("error", True)
raise
第三步:配置 ServiceMonitor
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: product-service
namespace: production
spec:
selector:
matchLabels:
app: product-service
endpoints:
- port: metrics
interval: 30s
path: /metrics
第四步:配置日志收集
apiVersion: v1
kind: ConfigMap
metadata:
name: fluent-bit-config
namespace: logging
data:
fluent-bit.conf: |
[INPUT]
Name tail
Path /var/log/containers/*.log
Parser docker
Tag kube.*
Refresh_Interval 5
Mem_Buf_Limit 5MB
[FILTER]
Name kubernetes
Match kube.*
Kube_URL https://kubernetes.default.svc:443
Merge_Log On
K8S-Logging.Parser On
[OUTPUT]
Name loki
Match *
Host loki.monitoring.svc
Port 3100
第五步:创建 Grafana 仪表板
关键面板:
- 服务概览
- 请求速率(QPS)。
- 错误率。
- 延迟分布(P50, P95, P99)。
- 资源使用
- 业务指标
- 依赖关系
五、成本优化建议
5.1 指标优化
策略:
5.2 日志优化
策略:
- 按重要性分级存储:
- ERROR/FATAL:保留 90 天。
- WARN:保留 30 天。
- INFO:保留 7 天。
- DEBUG:不持久化(或仅保留 1 天)。
- 采样:对高频日志进行采样。
import random
def should_log():
仅记录 10% 的 INFO 日志
return random.random() < 0.1
if level == "INFO" and should_log():
logger.info(message)
### 5.3 追踪优化
**策略**:
* **头部采样**:仅追踪 1-5% 的请求。
* **尾部采样**:优先保留慢请求和错误请求。
```yaml
# OpenTelemetry Collector 配置
processors:
tail_sampling:
policies:
- name: error-policy
type: status_code
status_code: {status_codes: [ERROR]}
- name: slow-policy
type: latency
latency: {threshold_ms: 1000}
- name: random-policy
type: probabilistic
probabilistic: {sampling_percentage: 1}
六、常见陷阱与解决方案
6.1 陷阱 1:监控数据过载
问题:
- Prometheus 存储爆炸。
- 查询超时。
- 成本失控。
解决方案:
- 启用联邦和分片:使用 Thanos/Cortex。
- 实施数据保留策略。
- 使用降采样(Downsampling)。
- 清理僵尸指标。
6.2 陷阱 2:缺乏关联性
问题:
- 日志、指标、追踪无法关联。
- 排障需要在多个系统间切换。
解决方案:
- 统一使用
trace_id 和 span_id。
- 在日志中包含追踪信息。
- 使用 Grafana Tempo 等支持关联的工具。
- 实施 OpenTelemetry 标准。
6.3 陷阱 3:忽视多集群场景
问题:
- 多个 Kubernetes 集群各自为政。
- 缺乏全局视图。
解决方案:
- 使用 Thanos 进行跨集群指标聚合。
- 部署中心化的 Loki。
- 使用 Grafana 多数据源。
- 实施统一的 Kubernetes 标签规范。
七、组织和流程层面的准备
7.1 建立可观测性团队
职责分工:
- 平台团队:负责可观测性基础设施。
- SRE 团队:制定告警规则和 SLO。
- 开发团队:实施应用层面的埋点。
7.2 制定 SLO(服务等级目标)
示例:
# product-service SLO
service: product-service
slo:
- name: availability
target: 99.9% # 每月最多 43 分钟停机
measurement:
expr: |
sum(rate(http_requests_total{job="product-service",code!~"5.."}[7d]))
/
sum(rate(http_requests_total{job="product-service"}[7d]))
- name: latency
target: 95% # 95% 的请求在 200ms 内完成
measurement:
expr: |
histogram_quantile(0.95,
rate(http_request_duration_seconds_bucket{job="product-service"}[7d])
) < 0.2
7.3 建立事故响应流程
OnCall 轮值:
- 明确响应时间要求。
- 提供完善的 Runbook。
- 定期进行混沌工程演练。
事后总结:
- 每次重大事故后进行无责复盘。
- 更新 Runbook 和告警规则。
- 改进可观测性盲点。
八、总结:你准备好了吗?
8.1 自我评估清单
在开始 Kubernetes 可观测性建设之前,请确认:
- [ ] 理解 Kubernetes 的动态特性对可观测性的影响。
- [ ] 选择了适合的指标、日志、追踪技术栈。
- [ ] 实施了服务发现和自动化配置。
- [ ] 解决了高基数(high cardinality)问题。
- [ ] 建立了统一的数据关联机制。
- [ ] 制定了合理的告警策略。
- [ ] 考虑了成本优化。
- [ ] 组织和流程已就绪。
- [ ] 定义了清晰的 SLO。
- [ ] 建立了事故响应机制。
8.2 循序渐进的实施路径
阶段 1:基础监控(1-2 个月)
- 部署 Prometheus + Grafana。
- 监控集群和节点健康度。
- 配置基本的告警规则。
阶段 2:应用可观测性(2-3 个月)
- 应用程序埋点。
- 部署日志收集系统。
- 创建应用级别的仪表板。
阶段 3:分布式追踪(1-2 个月)
- 引入 OpenTelemetry。
- 部署 Jaeger/Tempo。
- 实现跨服务调用追踪。
阶段 4:优化与深化(持续)
- 成本优化。
- SLO 细化。
- 自动化响应。
- 预测性告警(基于 AI/ML)。
Kubernetes 可观测性是一个复杂但必要的系统工程。记住,可观测性不是目的,而是手段。最终目标是构建可靠、高性能、可持续运营的系统。不要期望一蹴而就,而应从小处着手,持续迭代,注重实效,并拥抱行业标准。希望这份指南能为你提供清晰的路径,也欢迎在 云栈社区 分享你的实践心得或遇到的挑战,与更多开发者共同探讨。
 发表于 2026-1-25 07:01:08
|
查看: 155|
回复: 0
发表于 2026-1-25 07:01:08
|
查看: 155|
回复: 0
