海量数据是大型系统架构的核心挑战,随之而来的是巨大的存储与访问压力,其特点通常表现为数据体量庞大、热点分布动态变化、读写并发极高。
在这种背景下,缓存设计的主要目标变得非常清晰:降低后端数据库的压力、缩短用户请求的响应时延、保证系统的整体可用性,并在可接受的范围内维护数据的一致性。一个经典的解决方案,也是本文要重点探讨的,便是“本地缓存 → 分布式缓存 → 数据库/搜索引擎”的三级缓存架构。这三层相互配合,形成了一个从访问速度最快但容量最小,到访问较慢但存储容量巨大的分层体系,共同支撑起高并发场景下的稳定服务。
三级缓存设计详解
第一级:本地缓存 (L1)
本地缓存是进程内的缓存,直接存储在应用服务器的内存中,例如 Guava Cache 或 Caffeine 等库实现。
- 特点:访问延迟最低(纳秒级),但容量受单机内存限制,且数据在每个应用节点上独立存储,存在一致性问题。
- 适用场景:极热的数据、用户会话信息、临时业务上下文等。
- 策略:通常使用LRU(最近最少使用)或TTL(生存时间)来控制缓存项的失效。为了降低一致性问题,可以结合主动更新或订阅通知机制。
第二级:分布式缓存 (L2)
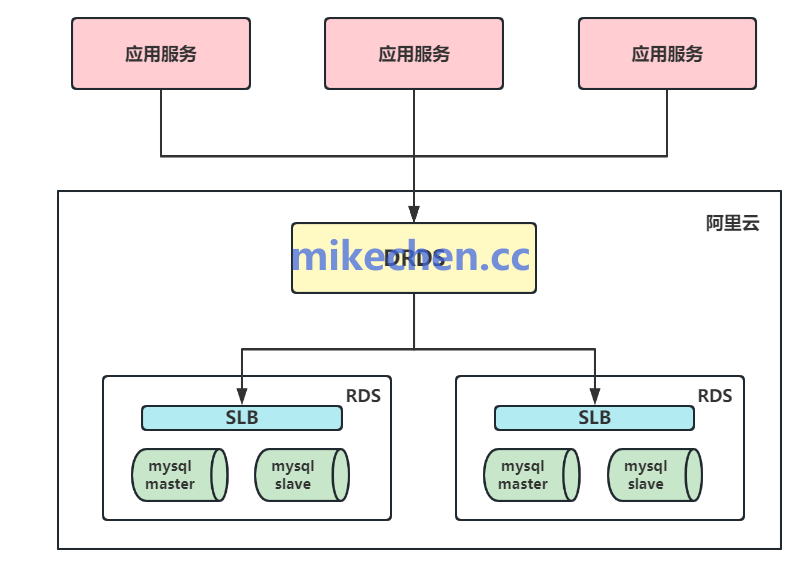
这是缓存架构的核心骨干层,通常由大内存集群组成,例如 Redis Cluster 或基于 Proxy 的架构。
- 特点:集中管理,容量远大于本地缓存,支持高并发访问和横向扩展,数据在集群内共享。
- 适用场景:需要跨多个应用节点共享的热点数据、对一致性要求较高的业务场景。
- 策略:需要采用合理的分片策略、配置持久化与主从复制以保证可用性。必须结合异步刷新与熔断降级机制来防止缓存雪崩与穿透问题。对于写操作,需设计合理的策略,如写通过、写回或主动失效。
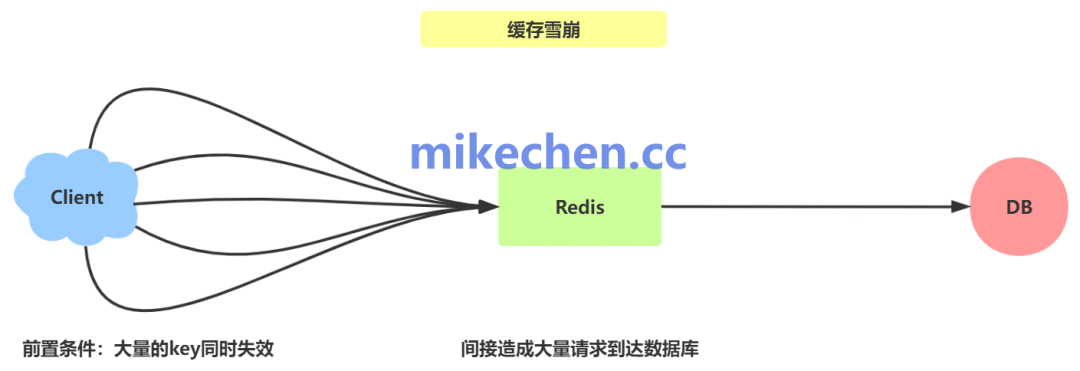
第三级:二级持久化缓存/近源存储 (L3)
这一层可以理解为数据库之前的最后一道屏障,例如使用 SSD 缓存、或读写分离的从库。
- 特点:容量可以做得非常大,成本相对数据库更低,读性能介于分布式缓存和原始数据库之间。
- 适用场景:非实时但被频繁访问的温数据、用于批量预热的全量数据,作为回源减压的缓冲层。
- 策略:定期进行批量数据预热,对数据进行分层归档存储。其主要目的是作为缓存未命中时的后备层,极大降低对主数据库的直接冲击。
整个设计的核心理念是:让访问频率最高的数据停留在最上层,访问频率较低的数据逐渐下沉。所有的读写操作都需围绕“数据库是最终数据源”这一原则展开,通过异步更新、版本控制或最终一致性等手段来维护各层之间的数据一致性。想了解更多此类系统架构的深度解析与实践经验,可以访问 云栈社区 与广大开发者交流探讨。 |  发表于 2026-1-25 12:16:58
|
查看: 163|
回复: 0
发表于 2026-1-25 12:16:58
|
查看: 163|
回复: 0
