微服务雪崩问题场景分析
想象这样一个典型场景:
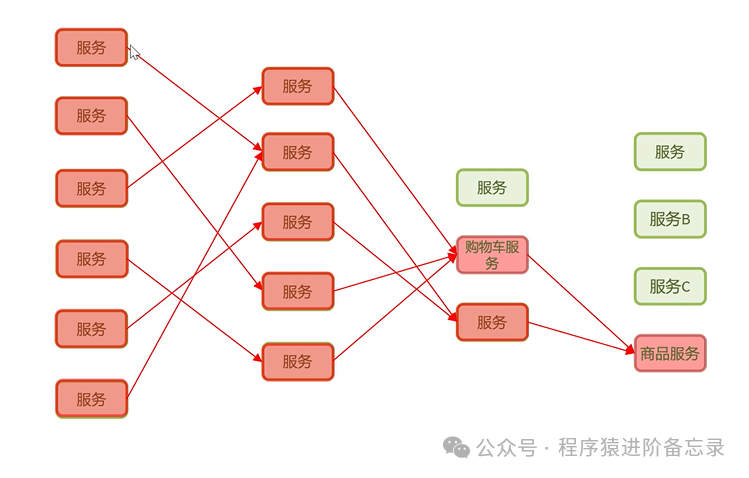
一个电商系统采用微服务架构,包含用户服务、购物车服务、商品服务、支付服务等多个独立模块。在某次促销活动期间,大量用户涌入下单,导致商品服务因数据库慢查询而响应变慢(例如,响应时间从50ms激增至2秒)。
其连锁反应如下:
- 购物车服务调用商品服务时,线程被长时间阻塞;
- 大量请求线程堆积,耗尽购物车服务的线程池资源;
- 线程池满后,购物车服务无法处理任何新请求,自身陷入瘫痪;
- 依赖于购物车服务的用户服务也随之调用失败;
- 最终,整个系统崩溃——即使其他服务本身功能完好。
这就是典型的微服务雪崩效应。其核心并非单一服务崩溃,而是由故障传播与资源耗尽引发的连锁反应。
雪崩问题的定义与诱因
什么是雪崩?
在微服务调用链路中,某个下游服务的故障(如响应缓慢或不可用),导致整个调用链路上的所有上游服务都不可用,这种现象被称为雪崩。
雪崩的三大诱因

解决雪崩问题的核心方案
1. 超时控制
核心原则:绝不无限等待!
为每个远程服务调用设置合理的超时时间,避免调用线程被长时间阻塞而耗尽资源。
例如,在基于 Spring Cloud OpenFeign 的项目中,可以进行如下配置:
feign:
client:
config:
default:
connectTimeout: 1000 # 连接超时 1秒
readTimeout: 3000 # 读取(响应)超时 3秒
作用:快速释放被阻塞的线程,防止故障扩散。
2. 限流
核心思路:将流量控制在系统能够稳定处理的范围内。
当请求量超过服务的最大处理能力时,主动拒绝部分超额请求(如返回友好提示),以保护系统核心逻辑不被突发流量压垮。
作用:防止突发流量(如秒杀、爬虫攻击)成为系统崩溃的导火索。
3. 线程隔离
核心思路:为不同的服务调用分配独立的线程池资源。
例如,将调用商品服务的线程与调用支付服务的线程隔离开。这样,即使商品服务出现故障、占满其专用线程池,也不会影响支付服务相关线程的正常工作。
作用:将故障的影响范围隔离在可控的局部,避免“一颗老鼠屎坏了一锅粥”。
4. 熔断器
核心思路:模仿电路中的保险丝。
当对某个服务的调用失败率(如超时、异常)超过预设阈值时,熔断器会自动“跳闸”。在接下来的短时间内,所有对该服务的请求都会快速失败(或执行降级逻辑),而不再真正发起可能失败的远程调用。经过一段冷却时间后,熔断器会进入半开状态,尝试放行少量请求,若成功则关闭熔断,恢复链路。
作用:快速失败,避免持续调用不可用服务而浪费宝贵的系统资源(如线程、连接)。
5. 服务降级
核心原则:主路不通,则走备胎。
当服务不可用或熔断器被触发时,提供一个备选方案(Fallback),返回兜底数据或执行简化逻辑,以保证核心业务流程的可用性,牺牲部分非核心功能或数据准确性。
降级示例:
- 商品详情页:若库存服务不可用,则展示“库存充足”的默认状态。
- 支付页面:若优惠券服务异常,则忽略优惠计算,允许用户按原价完成支付。
- 用户中心:若头像加载失败,则显示系统默认头像。
作用:提升系统整体的可用性与用户体验。
总结:构建雪崩防护体系
一个完整的微服务雪崩防护体系通常遵循以下层次:
用户请求
│
▼
[API 网关层] —— 实施第一道限流防线
│
▼
[服务A] —— 超时控制 + 熔断器 + 降级逻辑
│
▼
[服务B] ←— 本地缓存兜底 / 异步消息补偿
│
▼
数据库 / 第三方服务
核心思想可以概括为:快速失败、优雅降级、资源隔离、提前防御。
微服务架构在带来灵活性与可扩展性的同时,也显著增加了系统的复杂性。雪崩问题并非远在天边的理论风险,而是潜伏在每一个未设防的远程调用链路之中。对于开发者而言,构建高可用的系统不仅意味着实现功能,更意味着建立完善的故障防御机制,确保系统在部分组件异常时仍能保持核心服务的稳定。这正是 云原生 时代韧性架构的重要组成部分。 |  发表于 2025-12-2 02:58:51
|
查看: 216|
回复: 0
发表于 2025-12-2 02:58:51
|
查看: 216|
回复: 0
