在微服务架构中,服务间调用如果总是跨机房、跨地域,那网络延迟无疑会拖累整个系统的响应速度。作为主流的服务注册与发现中心,Nacos内置了聪明的服务路由策略,特别是同集群优先与就近访问这两大核心规则,它们能有效减少不必要的网络开销。但你知道在代码层面,它们究竟是怎么实现的吗?今天我们就直接进入源码,把这两个策略的工作机制彻底拆解清楚。
一、Nacos服务路由的核心目标:性能与稳定性
对于一个分布式系统而言,服务调用的网络延迟直接影响着用户体验和系统的整体吞吐能力。因此,Nacos在设计服务路由规则时,其核心目标非常明确:最小化网络延迟和提升服务可用性。通过“同集群优先”和“就近访问”的协同工作,它努力确保服务调用尽可能在“近邻”内完成,从而避免因长距离通信带来的性能损耗和不稳定性。
二、同集群优先:源码中的实例筛选逻辑
“同集群优先”是整个路由策略的基础。它的想法很直观:当一个服务消费者(客户端)需要调用某个服务时,优先选择那些和自己处在同一个逻辑集群里的服务提供者实例。
核心代码解析:NacosRule中的实例筛选
让我们直接看Nacos客户端负载均衡规则 NacosRule 中的关键代码。在 choose 方法里,它完成了一次完整的路由选择:
public class NacosRule extends AbstractLoadBalancerRule {
@Override
public Server choose(Object key) {
String clusterName = NacosPropertyUtil.getClusterName();
DynamicServerListLoadBalancer loadBalancer = (DynamicServerListLoadBalancer) getLoadBalancer();
String name = loadBalancer.getName();
NamingService namingService = NacosNamingServiceHolder.getInstance().getNamingService();
try {
// 获取所有健康实例
List<Instance> instances = namingService.selectInstances(name, true);
// 筛选同集群实例
List<Instance> sameClusterInstances = instances.stream()
.filter(instance -> clusterName.equals(instance.getClusterName()))
.collect(Collectors.toList());
// 如果有同集群实例,优先选择;否则选择所有实例
List<Instance> chosenInstances = sameClusterInstances.isEmpty() ? instances : sameClusterInstances;
// 负载均衡选择实例
return chooseInstanceByLoadBalancer(chosenInstances);
} catch (Exception e) {
log.error("Nacos rule choose instance failed", e);
return null;
}
}
}
关键代码分析:
- 集群名称获取:首先,通过
NacosPropertyUtil.getClusterName() 获取当前服务自身所在的集群名称。这个信息通常在应用配置中定义。
- 实例筛选:从 Nacos 服务端拉取到所有健康的服务实例列表后,利用 Java Stream API 进行快速过滤,只留下那些
clusterName 与当前消费者匹配的实例。
- 降级策略(重要):如果过滤后发现没有同集群的实例(
sameClusterInstances.isEmpty()),则自动降级,将chosenInstances设置为所有健康实例。这个策略保证了可用性:当某个集群内没有可用服务时,依然能够从其他集群获得服务,不至于导致调用失败。
三、就近访问:基于网络拓扑的智能路由
“就近访问”可以看作是“同集群优先”策略的延伸和细化。它不仅关心逻辑上的集群划分,还进一步考虑到了物理或网络拓扑上的“远近”,力求选择网络延迟最低的那个实例。Nacos 主要通过权重配置与健康检查的联动来实现这一目标。
核心流程:健康检查与权重分配
Nacos 服务端会定期对所有注册的服务实例进行健康检查,那些心跳失败或不健康的实例会被标记并从可用列表中剔除。同时,管理员可以为不同地域、不同网络状况或不同性能的实例配置不同的“权重”。权重越高,代表该实例处理请求的能力越强,或者网络位置更优,因此它在负载均衡时被选中的概率就应该越大。
源码中的权重计算
在 NacosRule 类中,筛选出目标实例列表(无论是同集群列表还是全部列表)后,会调用 chooseInstanceByLoadBalancer 方法进行最终的实例选择。这个方法实现了加权随机算法:
public Instance chooseInstanceByLoadBalancer(List<Instance> instances) {
if (instances == null || instances.isEmpty()) {
return null;
}
// 计算总权重
double totalWeight = instances.stream()
.mapToDouble(Instance::getWeight)
.sum();
// 随机选择实例(加权随机算法)
double randomWeight = ThreadLocalRandom.current().nextDouble(totalWeight);
double currentWeight = 0;
for (Instance instance : instances) {
currentWeight += instance.getWeight();
if (currentWeight > randomWeight) {
return instance;
}
}
return instances.get(0);
}
关键机制:
- 加权随机算法:算法首先计算所有候选实例的权重总和。然后生成一个
[0, totalWeight) 范围内的随机数。接着遍历实例列表并累加其权重,当累加值首次超过随机数时,就选中当前遍历到的实例。这样,权重越大的实例,其权重区间覆盖的范围就越大,被随机数“命中”的概率也就越高。
- 健康检查联动:请注意,传入这个方法的实例列表 (
instances) 已经是经过健康检查筛选后的“健康实例”。不健康的实例在更早的阶段就被排除了,根本不会参与权重计算。
- 动态调整:实例的权重支持在运行时通过 Nacos 控制台或 API 进行动态调整,无需重启任何服务,这为基于实时监控的流量调配提供了灵活性。
四、源码深度剖析:关键流程与核心代码
为了更直观地理解从客户端发起请求到选中一个具体实例的完整决策链条,我们可以梳理出以下的核心流程:
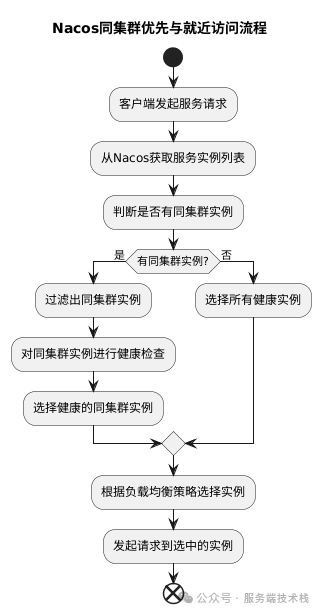
完整流程解析
- 服务发现请求:服务消费者(客户端)发起一次 RPC 调用,其内部的负载均衡器(如 Ribbon 整合
NacosRule)开始工作。
- 集群信息获取:
NacosRule 从本地配置中读取当前服务自己所属的 clusterName。
- 实例列表查询:通过
NacosNamingService 客户端,向 Nacos 服务端发起查询,获取目标服务的所有健康实例列表。
- 同集群筛选:利用获取到的
clusterName 对实例列表进行过滤,得到同集群的实例子集。如果子集为空,则进入降级逻辑,使用全量实例列表。
- 负载均衡选择:对最终确定的候选实例列表(同集群列表或全量列表),执行加权随机算法,选出一个具体的服务实例。
- 服务调用:客户端最终向这个被选中的实例发起网络请求。
整个流程清晰地体现了路由策略的分层设计:先按逻辑集群做粗粒度筛选,保证网络亲近性;再通过权重做细粒度调节,实现负载与性能的平衡。
五、实战优化:如何配置与验证
理解了原理,我们在实际项目中可以这样来应用和优化:
- 明确配置集群名称:这是“同集群优先”生效的前提。在
application.yml 或 bootstrap.yml 中为你的服务明确设置集群名。
spring:
cloud:
nacos:
discovery:
cluster-name: SH-AZ1 # 例如,上海可用区1
- 合理分配权重:根据实例所在的物理位置(如不同机房)、服务器硬件性能(CPU/内存)、或已知的网络质量,在 Nacos 控制台上为不同的服务实例设置不同的权重。给更“近”或更强的实例更高的权重。
- 监控与动态调优:充分利用 Nacos 控制台的“服务列表”和“订阅者列表”功能,监控实例的健康状态、元数据以及调用关系。结合 APM 工具(如 SkyWalking, Pinpoint)监控到的实际调用延迟,动态调整集群划分或实例权重,实现真正的“智能”路由。
结语
通过对 NacosRule 等核心类的源码分析,我们可以看到 Nacos 在服务路由上的设计既直接又巧妙。“同集群优先”用简单的过滤逻辑解决了大部分跨域延迟问题,而“加权随机”的引入则在可用性、负载均衡和性能之间取得了很好的平衡。更重要的是,它预留了降级策略,确保了系统的最终可用性。
下次当你再为微服务间的调用延迟头疼时,不妨先从源码层面检查一下你的集群配置和权重设置。希望这篇深入源码的解析能帮助你更好地理解和运用 Nacos,如果你在实践中遇到了其他有趣的问题或技巧,欢迎在 云栈社区 的论坛板块与我们交流分享。
 发表于 2026-3-9 06:20:57
|
查看: 219|
回复: 0
发表于 2026-3-9 06:20:57
|
查看: 219|
回复: 0
