面对复杂的数据库查询需求,标准JPA(Java Persistence API)常显得力不从心。你是否也在为构建动态过滤、实现高效分页或处理只读投影而烦恼?传统的JPQL和Criteria API在灵活性或可维护性上往往存在短板。幸运的是,Blaze Persistence这一工具应运而生,它旨在让你在保持JPA优雅的同时,获得接近原生SQL的灵活性与强大功能。
标准JPA的Criteria API常常让开发者感到头疼——代码冗长、难以维护,在处理复杂查询时更是束手束脚。当项目需要执行跨多个实体的聚合查询、复杂条件过滤或应对大数据量的高效分页时,传统JPA方法往往导致性能瓶颈或产生难以维护的代码库。Blaze Persistence扩展了JPA的功能边界,提供了一套更强大、更直观的查询API,彻底改变了这一局面。
一、JPA查询的痛点与局限性
JPA作为Java持久层标准,通过注解极大地简化了对象关系映射(ORM)。然而,在复杂查询场景下,其局限性开始显现。JPQL查询虽然直观,但面对层出不穷的动态查询条件时显得笨拙;而Criteria API虽然支持动态构建,但带来的代价是冗长且难以阅读和维护的代码。
尤其在处理以下几种常见场景时,标准JPA的不足尤为突出:
- 需要构建包含多个动态过滤条件的查询。
- 执行涉及多个聚合函数的复杂报表查询。
- 在大数据量下实现高效的关键集分页(Keyset Pagination),避免传统偏移分页的性能悬崖。
- 仅需返回实体部分属性的DTO投影查询,以优化网络传输与内存占用。
让我们先看一个典型的传统JPA Criteria API实现多条件查询的例子:
// 传统JPA Criteria API实现多条件查询示例
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<Person> query = cb.createQuery(Person.class);
Root<Person> root = query.from(Person.class);
List<Predicate> predicates = new ArrayList<>();
if (name != null) {
predicates.add(cb.like(root.get("name"), "%" + name + "%"));
}
if (minAge != null) {
predicates.add(cb.ge(root.get("age"), minAge));
}
if (departmentId != null) {
predicates.add(cb.equal(root.get("department").get("id"), departmentId));
}
query.where(predicates.toArray(new Predicate[0]));
上述方式不仅代码冗长,而且在添加新查询条件时需要修改多个地方,违反了开闭原则,长期维护成本高。
二、Blaze Persistence核心架构解析
Blaze Persistence 是一个构建于JPA之上的高级查询API套件。其核心设计理念是通过一套流畅的API来简化复杂查询的构建过程,同时保持严格的类型安全和编译时检查。它并非要取代JPA,而是对其进行增强,能够与现有的JPA提供者(如Hibernate)无缝集成。
它的架构包含几个关键模块:Core模块提供基础的查询构建功能;Entity-View模块用于定义强大的只读实体投影;JPA-Criteria模块则用于增强标准JPA Criteria API。其中,实体视图(Entity Views) 功能特别值得关注,它允许开发者定义类似于数据库视图的实体投影,这不仅能显著提高查询效率,还能极大简化数据访问层的代码,并支持嵌套视图、关联过滤等高级特性。
三、流畅的Criteria API:重塑查询构建体验
Blaze Persistence最引人注目的特性是其流畅且强大的Criteria API。它通过连贯接口(Fluent Interface)设计,让开发者能够以更符合直觉的方式构建复杂查询。这种设计不仅大幅减少了代码量,更显著提升了代码的可读性和可维护性。
// 使用Blaze Persistence的CriteriaBuilderFactory
CriteriaBuilder<Person> cb = criteriaBuilderFactory.create(entityManager, Person.class)
.where("name").like().value("%张%").noEscape()
.where("age").ge(18)
.where("department.id").eq(departmentId)
.orderByAsc("name")
.orderByDesc("createTime")
.setFirstResult(0)
.setMaxResults(20);
List<Person> persons = cb.getResultList();
对比之前的传统写法,Blaze Persistence的API更加简洁明了。更重要的是,它支持许多标准JPA中要么不支持、要么实现极其复杂的高级SQL特性,例如CTE(公共表表达式)、递归查询和窗口函数。
关键集分页(Keyset Pagination) 是另一个亮点,尤其适合大数据量下的分页需求。与传统的基于OFFSET和LIMIT的分页不同,关键集分页通过记住上一页最后一条记录的唯一标识(如ID和时间戳组合)来进行查询,其性能不受页码深度影响,更加稳定高效。
四、实体视图:数据投影的革命性方案
实体视图是Blaze Persistence的一项创新,它重新定义了如何查看和操作JPA实体。与传统DTO投影相比,实体视图提供了一个更强大、更灵活的机制来定义只读的实体投影。这不仅仅是简单的属性选择,而是支持复杂映射、关联过滤和嵌套视图的完整解决方案。
// 定义实体视图接口
@EntityView(Person.class)
public interface PersonSummaryView {
@IdMapping
Long getId();
String getName();
Integer getAge();
// 映射到关联实体的属性
@Mapping("department.name")
String getDepartmentName();
// 条件性关联映射:只映射状态为‘ACTIVE’的项目
@Mapping("projects[status = 'ACTIVE']")
Set<ProjectView> getActiveProjects();
}
// 嵌套的实体视图定义
@EntityView(Project.class)
public interface ProjectView {
@IdMapping
Long getId();
String getTitle();
// 使用JPQL表达式进行计算
@Mapping("COALESCE(progress, 0)")
Integer getProgressPercentage();
}
实体视图的类型安全特性确保了所有映射在编译时即可被检查,极大减少了运行时错误的风险。它与Spring Data的无缝集成进一步简化了使用,开发者可以直接在Repository接口中将实体视图类型作为返回类型。
实体视图支持多种高级特性,包括基于JPQL表达式的属性映射、关联集合的条件过滤、聚合函数计算字段以及对多态实体的支持。这些特性使得它成为处理复杂数据投影需求的理想选择。
五、处理复杂关联与声明式过滤策略
在JPA中,处理OneToMany或ManyToMany这类关联关系的过滤一直是个挑战。典型场景是:需要根据子实体的属性来过滤父实体列表,并且希望返回的父实体中,其关联集合也只包含符合条件的子集。传统JPA方法通常只能过滤父实体,返回的关联集合仍包含所有子实体,这就导致了不必要的内存消耗和后续的应用层过滤。
Blaze Persistence通过实体视图的声明式过滤完美解决了这一问题。
@EntityView(Order.class)
public interface OrderWithFilteredItemsView {
@IdMapping
Long getId();
String getOrderNumber();
// 声明式过滤:只映射单价大于100的商品项
@Mapping("items[unitPrice > 100]")
Set<OrderItemView> getHighValueItems();
// 计算属性:高价值商品总金额(直接在SQL中完成计算)
@Mapping("SUM(items[unitPrice > 100].unitPrice * quantity)")
BigDecimal getHighValueTotal();
}
@EntityView(OrderItem.class)
public interface OrderItemView {
@IdMapping
Long getId();
String getProductName();
BigDecimal getUnitPrice();
Integer getQuantity();
}
这种方法将过滤逻辑彻底下推到数据库层面执行,避免了不必要的数据传输和内存消耗。同时,声明式的过滤条件让业务逻辑在代码中一目了然,意图更加清晰。针对经典的N+1查询问题,Blaze Persistence也提供了智能的抓取策略优化,可以通过实体视图的配置精确控制关联数据的加载方式,从而规避性能陷阱。
六、性能优化与最佳实践指南
使用任何ORM或查询工具,合理的性能优化策略都至关重要。索引是数据库查询性能的基石。正确使用单列索引和复合索引可以显著提升查询速度。对于频繁使用单个条件查询的字段,单列索引效率最高。而对于经常组合查询的多个字段,则需要创建复合索引,并注意“最左前缀”原则,即索引列的顺序非常关键。
// 在实体类上定义索引
@Entity
@Table(name = "orders", indexes = {
@Index(columnList = "customer_id, create_date"), // 复合索引,支持(customer_id)和(customer_id, create_date)查询
@Index(columnList = "status"), // 单列索引
@Index(columnList = "create_date") // 单列索引
})
public class Order {
// 实体定义...
}
在查询优化方面,应遵循几个核心原则:
- 只查询需要的数据:充分利用实体视图精确控制返回的字段,避免
SELECT *。
- 减少数据库往返:合理使用批量操作和优化后的关联加载策略。
- 善用缓存:在合适的场景下利用Blaze Persistence或应用层的查询缓存机制。
- 选择正确的分页方式:对于大数据集和深度分页,优先考虑关键集分页。
此外,监控和分析生成的SQL语句及其执行计划是必不可少的步骤,确保你的索引被有效利用。
下面的流程图清晰地展示了如何根据不同的查询需求,选择最合适的Blaze Persistence特性来构建高效、可维护的查询方案:
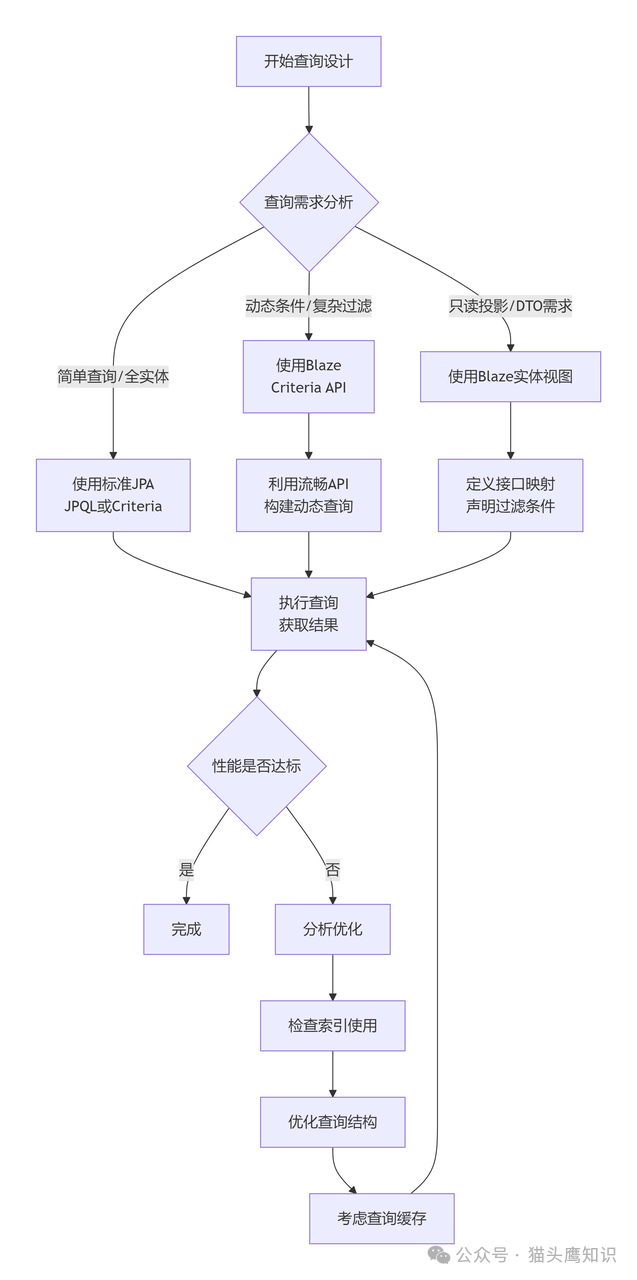
Blaze Persistence与Spring生态的集成非常简便。通过其Spring Data模块,开发者可以在Repository中直接使用实体视图作为返回类型,享受Spring Data自动实现查询方法等便利。在事务管理方面,虽然实体视图本身是只读的,但Blaze Persistence完全支持JPA的事务管理机制,完全可以与读写操作在同一个事务中共存。
七、实际应用场景与渐进式迁移策略
Blaze Persistence在多种实际场景中都能大显身手:
- 大规模数据检索:其关键集分页和高效的查询构建能力,能显著提升列表查询和分页性能。
- 复杂报表生成:丰富的聚合函数和窗口函数支持,让实现复杂的统计查询变得简单。
- 微服务架构下的数据聚合:作为数据访问层的增强组件,在不改变整体架构的前提下,为服务提供灵活强大的数据查询和视图能力,特别适合需要对外提供多种数据形态的API服务。
从传统的JPA迁移到Blaze Persistence,推荐采用渐进式策略,而非一次性重写。可以从新功能模块,或者当前性能瓶颈最明显的复杂查询开始,逐步替换原有的Criteria API代码。重要的是,Blaze Persistence与标准JPA代码可以完美共存于同一项目中,这为平滑迁移提供了可能。
对于团队引入Blaze Persistence,建议建立实体视图的规范,并创建共享的视图基础库,避免在不同地方重复定义相似的视图。在进行代码审查时,应特别关注实体视图中JPQL表达式的正确性及其对查询性能的潜在影响。
总结
复杂的查询逻辑在Blaze Persistence流畅的API下变得直观而清晰。曾经需要数十行标准Criteria API代码才能实现的动态过滤,现在只需寥寥几行声明式映射即可完成。实体视图功能更是将数据投影从简单的字段选择,提升为完整的业务语义表达,条件过滤、关联映射、计算字段等高级特性都直接体现在接口定义之中。
现在,性能优化不再需要开发者绕过JPA去编写难以维护的原生SQL。Blaze Persistence在保持JPA类型安全与开发效率的同时,为复杂查询、高效分页和智能数据加载提供了统一而强大的解决方案。如果你想深入了解类似的高性能数据访问技术,可以访问云栈社区的数据库与架构板块,获取更多实战经验和深度技术文档。
 发表于 2026-1-25 19:02:36
|
查看: 225|
回复: 0
发表于 2026-1-25 19:02:36
|
查看: 225|
回复: 0
