在分布式系统的复杂网络中,服务之间的高效通信是构建稳定、高性能应用的基石。Dubbo 作为一款卓越的分布式服务框架,其序列化机制犹如一座隐形的桥梁,默默承载着对象在网络间的高效传输,是实现高性能 RPC 调用的关键所在。因此,深入理解其序列化的核心实现机制,是帮助我们更快定位问题、进行性能优化的必要能力。今天,就让我们系统地探讨一下 Dubbo 的序列化机制。
序列化的基本概念
什么是序列化和反序列化?
在计算机系统中,数据通常以特定数据结构(对象、数组等)存在,其底层是“111110000”这样的二进制数据,本质上对应着电位的高和低,可以理解为是开关的两种状态。计算机正是通过这些不同的开关组合来完成特定功能的。所谓序列化,就是把对象转换为二进制数据序列的过程;反之,反序列化就是把二进制数据序列重新转换回对象的过程。
基本特点
- 跨平台:通过序列化和反序列化,可以在不同平台之间实现数据交换。
- 跨语言:通过实现对应的序列化和反序列化算法,可以在不同编程语言之间实现数据的转换。
使用场景
- 数据持久化:在写入数据库或文件时,需要将数据序列化为特定格式存储;使用时再读取并进行反序列化。
- 网络通信:这是最常见、最广泛的用法。在网络通信中,需要将数据序列化为特定的 JSON、XML 等格式,便于数据接收方进行反序列化。
常见的序列化算法
- XML(eXtensible Markup Language):一种标记语言,具有严格的语法规则,常用于配置文件和数据交换。它能清晰地表示数据的层次结构,但相比 JSON,其语法更复杂,数据量更大。
- JSON(JavaScript Object Notation):轻量级的数据交换格式,易于阅读和编写,也易于机器解析和生成。它以键值对的形式表示数据,支持多种数据类型。在 Web 开发和移动应用开发中被广泛用于前后端数据交互。
- Protocol Buffers:由 Google 开发的一种高效的结构化数据序列化格式。它使用紧凑的二进制格式,相比 JSON 和 XML,序列化后的数据体积更小,解析速度更快。常用于性能要求较高的场景,如网络通信和数据存储。
- Apache Avro:提供了丰富的数据结构类型,支持动态模式,适合在大数据处理场景中使用。它的模式与数据存储在一起,使得数据的可读性和互操作性更强,在 Hadoop 生态系统中被广泛应用。
- 编程语言特定实现:不同编程语言通常有自己的序列化和反序列化机制。例如,Java 通过实现
java.io.Serializable 接口来标记对象可序列化;Python 使用 pickle 模块;C# 通过 System.Runtime.Serialization 命名空间下的类来实现。
Dubbo 中序列化的核心机制
默认协议:Hessian2 的性能与特性深度剖析
在 Dubbo 3.0 的序列化体系中,Hessian2 作为默认的序列化协议,占据着举足轻重的地位。它是一种轻量级的二进制跨语言序列化协议,其设计理念旨在实现高效的数据传输与跨语言交互。
从性能角度来看,Hessian2 具备序列化速度快、生成的字节流体积小的显著优势。在实际的微服务应用场景中,当服务间频繁进行方法调用时,Hessian2 能够快速地将方法参数和返回值进行序列化与反序列化操作,大大减少了数据在网络传输和处理过程中的时间开销。Dubbo 3.0 对 Hessian2 进行了针对性优化,例如改进对象引用的处理逻辑,避免不必要的重复序列化,进一步提升了其在复杂场景下的性能表现。
Hessian2 的跨语言特性也是其被选为默认协议的重要原因之一。它支持 Java、C++、Python 等多种编程语言,这使得基于 Dubbo 3.0 构建的微服务系统能够轻松实现与其他语言编写的服务进行通信,为构建异构 分布式系统 提供了便利。
多元化选择:JSON/Kryo/Protobuf 协议特性对比
除了默认的 Hessian2 协议,Dubbo 还支持 JSON、Kryo、Protobuf 等多种序列化协议,每种协议都有其独特的特性和适用场景。
- JSON:作为一种广泛应用的文本格式序列化协议,具有极高的可读性和良好的跨平台兼容性,便于调试。但其性能相对较低,序列化/反序列化速度较慢,生成的数据体积较大。
- Kryo:一种专为 Java 设计的高性能二进制序列化框架,序列化效率极高,生成的字节流体积非常小。但其明显缺点是不支持跨语言。
- Protobuf:由 Google 开发的一种高性能、跨语言的序列化协议。它通过
.proto 文件定义数据结构,然后生成对应语言的代码,序列化速度快且数据体积小。在对性能和跨语言兼容性要求都很高的场景中是一个非常好的选择。
序列化协议选型的核心考量因素
在 Dubbo 中选择合适的序列化协议,需要综合考虑多个核心因素:
- 性能需求:高并发场景下应优先选择性能卓越的 Kryo 或 Protobuf。如果对性能要求不是特别苛刻,Hessian2 或 JSON 也可满足需求。
- 跨语言需求:如果系统需要与非 Java 服务通信,则不支持跨语言的 Kryo 不再适用,应选择 Hessian2 或 Protobuf。
- 调试与维护需求:在开发测试阶段,JSON 的可读性优势使其便于调试。但在生产环境,通常会切换到二进制协议(如 Hessian2、Kryo、Protobuf)以提高性能。
Dubbo 序列化原理
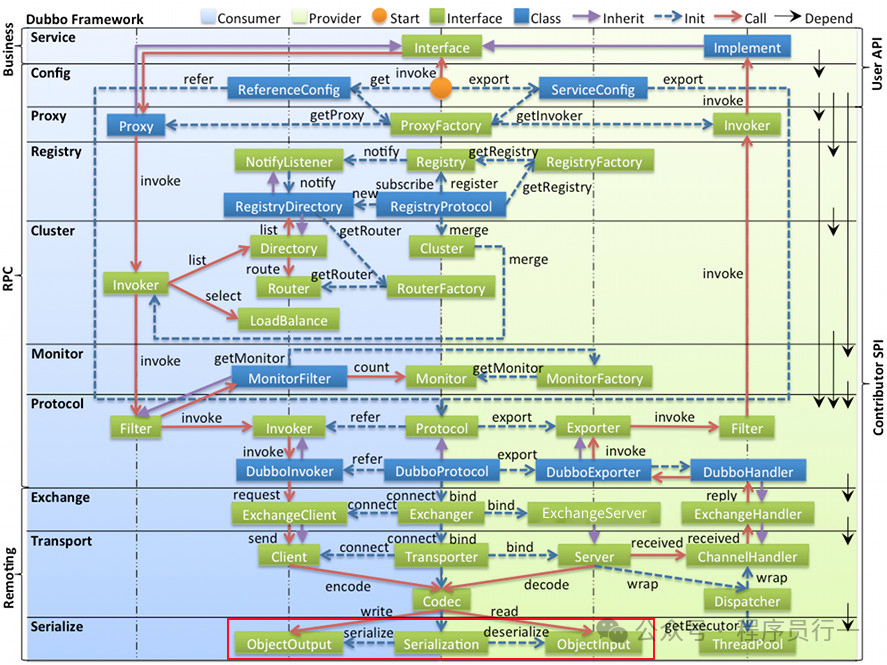
整体架构
下图是 Dubbo 官方的整体架构设计图,可以看出序列化实际上位于最底层,即真正要进行网络通信时才会进行序列化操作。序列化的顶层接口是 ObjectOutput(序列化),反序列化则是 ObjectInput。
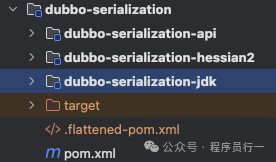
Dubbo 3.0 代码中默认支持的序列化模块如下:
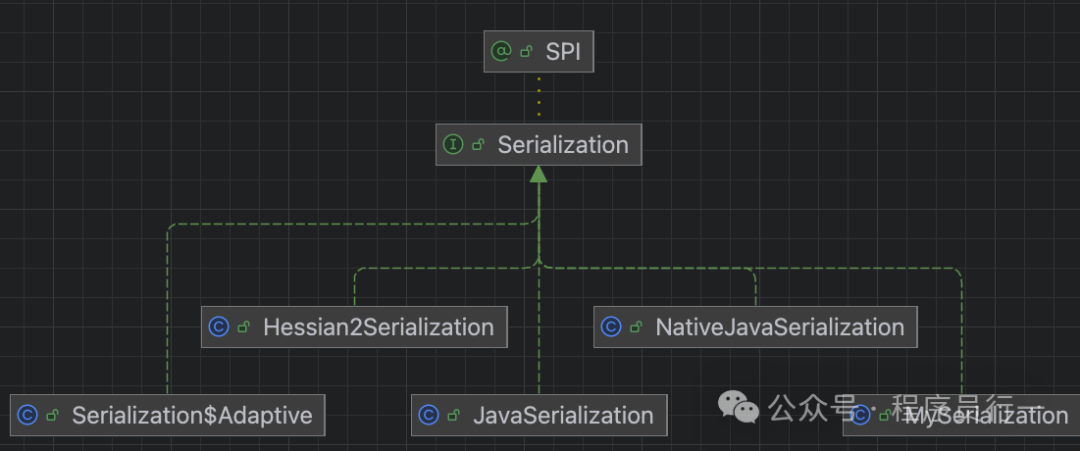
序列化的顶层接口继承关系如下图所示,它基于 SPI 机制实现,允许灵活扩展。
客户端请求序列化
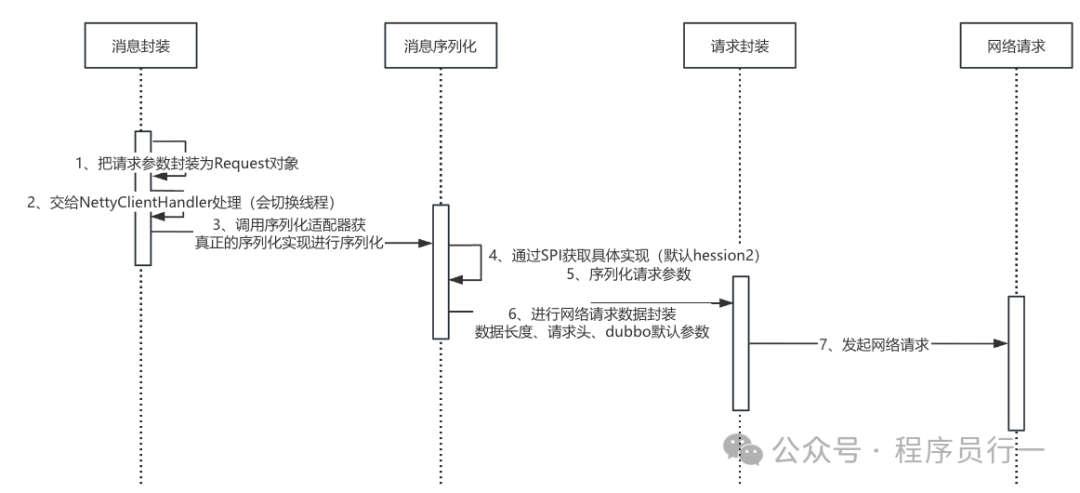
源码分析
第一步:NettyClientHandler 构建,需要设置编码器。代码位置:org.apache.dubbo.remoting.transport.netty4.NettyClient#doOpen。
protected void doOpen() throws Throwable {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
// 通过适配器封装了解码器和编码器
NettyCodecAdapter adapter = new NettyCodecAdapter(getCodec(), getUrl(), NettyClient.this);
ch.pipeline()
.addLast("decoder", adapter.getDecoder())
.addLast("encoder", adapter.getEncoder())
第二步:发起客户端请求时进行序列化,入口在 io.netty.handler.codec.MessageToByteEncoder#write。
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
ByteBuf buf = null;
try {
if (this.acceptOutboundMessage(msg)) {
I cast = (I) msg;
buf = this.allocateBuffer(ctx, msg, this.preferDirect);
try {
// 调用编码
this.encode(ctx, cast, buf);
接着调用 org.apache.dubbo.remoting.transport.netty4.NettyCodecAdapter.InternalEncoder#encode。
protected void encode(ChannelHandlerContext ctx, Object msg, ByteBuf out) throws Exception {
org.apache.dubbo.remoting.buffer.ChannelBuffer buffer = new NettyBackedChannelBuffer(out);
Channel ch = ctx.channel();
NettyChannel channel = NettyChannel.getOrAddChannel(ch, url, handler);
codec.encode(channel, buffer, msg);
}
之后会调用到 org.apache.dubbo.remoting.exchange.codec.ExchangeCodec#encode。
public void encode(Channel channel, ChannelBuffer buffer, Object msg) throws IOException {
if (msg instanceof Request) {
// 序列化请求参数(消费端)
encodeRequest(channel, buffer, (Request) msg);
} else if (msg instanceof Response) {
// 序列化返回值(服务端)
encodeResponse(channel, buffer, (Response) msg);
} else {
super.encode(channel, buffer, msg);
}
}
核心序列化逻辑在 org.apache.dubbo.remoting.exchange.codec.ExchangeCodec#encodeRequest。这里可以先看下 Dubbo 的数据包结构:

protected void encodeRequest(Channel channel, ChannelBuffer buffer, Request req) throws IOException {
// 通过SPI获取序列化器
Serialization serialization = getSerialization(channel, req);
// 请求头长度16字节
byte[] header = new byte[HEADER_LENGTH];
// 设置魔数,魔数的作用主要是防止数据被误操作,数据版本区分等
Bytes.short2bytes(MAGIC, header);
// 设置数据包类型和序列化器编号
header[2] = (byte) (FLAG_REQUEST | serialization.getContentTypeId());
// 设置请求方式为单向或者双向
if (req.isTwoWay()) {
header[2] |= FLAG_TWOWAY;
}
// 设置事件标志
if (req.isEvent()) {
header[2] |= FLAG_EVENT;
}
// 设置请求id
Bytes.long2bytes(req.getId(), header, 4);
// 设置读写位置
int savedWriteIndex = buffer.writerIndex();
buffer.writerIndex(savedWriteIndex + HEADER_LENGTH);
ChannelBufferOutputStream bos = new ChannelBufferOutputStream(buffer);
if (req.isHeartbeat()) {
// 心跳检查请求数据为空
bos.write(CodecSupport.getNullBytesOf(serialization));
} else {
// 请求数据序列化
ObjectOutput out = serialization.serialize(channel.getUrl(), bos);
if (req.isEvent()) {
// 对事件数据进行序列化操作
encodeEventData(channel, out, req.getData());
} else {
// 请求数据序列化
encodeRequestData(channel, out, req.getData(), req.getVersion());
}
out.flushBuffer();
if (out instanceof Cleanable) {
((Cleanable) out).cleanup();
}
}
bos.flush();
bos.close();
// 将消息体长度写入到消息头中
int len = bos.writtenBytes();
checkPayload(channel, len);
// 设置消息头(header)
Bytes.int2bytes(len, header, 12);
buffer.writerIndex(savedWriteIndex);
// 写入消息头
buffer.writeBytes(header);
// 设置新的原写下标 + 消息头长度 + 消息体长度
buffer.writerIndex(savedWriteIndex + HEADER_LENGTH + len);
}
最后看一下 request 对象数据的序列化过程 encodeRequestData:
protected void encodeRequestData(Channel channel, ObjectOutput out, Object data, String version) throws IOException {
// 强转,为了读取后续字段
RpcInvocation inv = (RpcInvocation) data;
// 序列化版本号
out.writeUTF(version);
// https://github.com/apache/dubbo/issues/6138
String serviceName = inv.getAttachment(INTERFACE_KEY);
if (serviceName == null) {
serviceName = inv.getAttachment(PATH_KEY);
}
// 序列化服务名
out.writeUTF(serviceName);
out.writeUTF(inv.getAttachment(VERSION_KEY));
// 序列化方法名
out.writeUTF(inv.getMethodName());
out.writeUTF(inv.getParameterTypesDesc());
Object[] args = inv.getArguments();
if (args != null) {
for (int i = 0; i < args.length; i++) {
out.writeObject(callbackServiceCodec.encodeInvocationArgument(channel, inv, i));
}
}
out.writeAttachments(inv.getObjectAttachments());
}
到这里,客户端发起请求时的序列化就完成了,下一步就是网络请求。
服务端请求反序列化
服务端接收到请求后,会由 Netty 调用 NettyServerHandler 的反序列化器进行反序列化,之后会调用实际的实现类。流程如下:
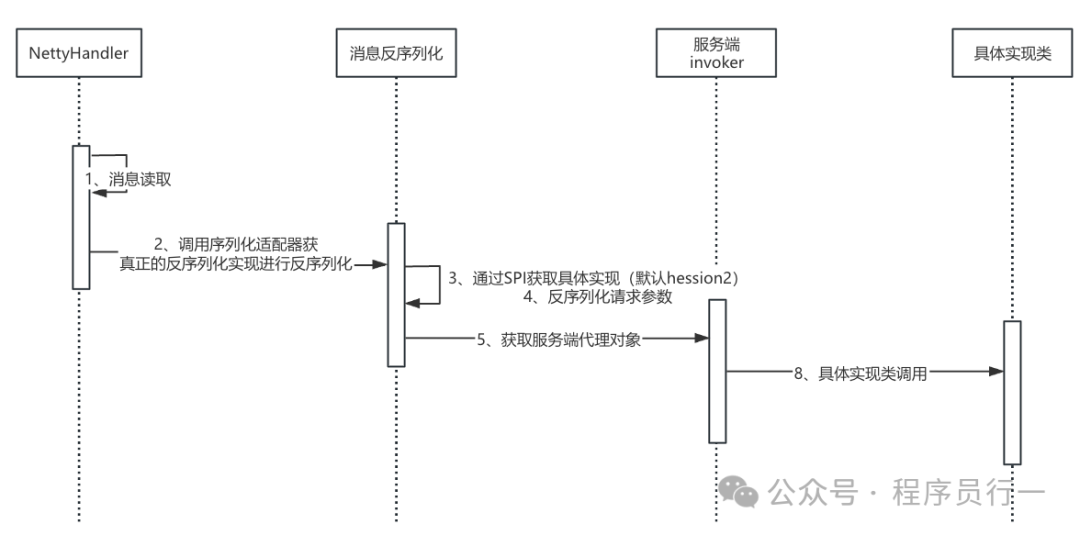
源码分析
第一步:接收数据,在 netty 调用链路中会触发各类 handler,反序列化入口在 io.netty.handler.codec.ByteToMessageDecoder#channelRead。
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
if (msg instanceof ByteBuf) {
// 调用反序列化
callDecode(ctx, cumulation, out);
第二步:调用到 org.apache.dubbo.remoting.transport.netty4.NettyCodecAdapter.InternalDecoder#decode。
protected void decode(ChannelHandlerContext ctx, ByteBuf input, List<Object> out) throws Exception {
ChannelBuffer message = new NettyBackedChannelBuffer(input);
NettyChannel channel = NettyChannel.getOrAddChannel(ctx.channel(), url, handler);
// 反序列化请求参数
do {
int saveReaderIndex = message.readerIndex();
Object msg = codec.decode(channel, message);
if (msg == Codec2.DecodeResult.NEED_MORE_INPUT) {
message.readerIndex(saveReaderIndex);
break;
} else {
//is it possible to go here ?
if (saveReaderIndex == message.readerIndex()) {
throw new IOException("Decode without read data.");
}
if (msg != null) {
out.add(msg);
}
}
} while (message.readable());
}
第三步:真正的反序列化逻辑 org.apache.dubbo.remoting.exchange.codec.ExchangeCodec#decode。
protected Object decode(Channel channel, ChannelBuffer buffer, int readable, byte[] header) throws IOException {
// 检查魔数是不是一致
if (readable > 0 && header[0] != MAGIC_HIGH
|| readable > 1 && header[1] != MAGIC_LOW) {
// ... 处理魔数不匹配,尝试定位正确起始位置或调用父类解码(如Telnet)
return super.decode(channel, buffer, readable, header);
}
// 检查可读取数据长度
if (readable < HEADER_LENGTH) {
return DecodeResult.NEED_MORE_INPUT;
}
// 获取数据长度
int len = Bytes.bytes2int(header, 12);
// When receiving response, how to exceed the length, then directly construct a response to the client.
// see more detail from https://github.com/apache/dubbo/issues/7021.
Object obj = finishRespWhenOverPayload(channel, len, header);
if (null != obj) {
return obj;
}
// 验证消息体的长度是不是超过请求头传递的长度,超过则抛出异常
checkPayload(channel, len);
// 可读数据总长度如果小于数据长度+header长度,说明客户端没传完,需要继续等待数据
int tt = len + HEADER_LENGTH;
if (readable < tt) {
return DecodeResult.NEED_MORE_INPUT;
}
// 限制输入流长度
ChannelBufferInputStream is = new ChannelBufferInputStream(buffer, len);
try {
// 反序列化操作
return decodeBody(channel, is, header);
} finally {
// ...
}
}
实际的反序列化操作在 org.apache.dubbo.rpc.protocol.dubbo.DubboCodec#decodeBody。
protected Object decodeBody(Channel channel, InputStream is, byte[] header) throws IOException {
// 获取消息头中的第三个字节(数据包类型),并通过逻辑与运算得到序列化器编号
byte flag = header[2], proto = (byte) (flag & SERIALIZATION_MASK);
// 获取请求id
long id = Bytes.bytes2long(header, 4);
if ((flag & FLAG_REQUEST) == 0) {
// 如果不是请求的话说明是响应,这是客户端收到响应的时候会走到这里,暂时忽略
Response res = new Response(id);
// todo 下节
} else {
// 构建request对象
Request req = new Request(id);
// 设置版本号
req.setVersion(Version.getProtocolVersion());
req.setTwoWay((flag & FLAG_TWOWAY) != 0);
if ((flag & FLAG_EVENT) != 0) {
req.setEvent(true);
}
try {
Object data;
// 请求事件
if (req.isEvent()) {
byte[] eventPayload = CodecSupport.getPayload(is);
// 心跳探测,没有request数据
if (CodecSupport.isHeartBeat(eventPayload, proto)) {
// heart beat response data is always null;
data = null;
} else {
//对事件请求参数进行反序列化
ObjectInput in = CodecSupport.deserialize(channel.getUrl(), new ByteArrayInputStream(eventPayload), proto);
data = decodeEventData(channel, in, eventPayload);
}
} else {
//对请求参数进行反序列化,重点看这个
DecodeableRpcInvocation inv;
// 构建反序列化对象DecodeableRpcInvocation
inv = new DecodeableRpcInvocation(frameworkModel, channel, req,
new UnsafeByteArrayInputStream(readMessageData(is)), proto);
inv.decode();
data = inv;
}
req.setData(data);
} catch (Throwable t) {
// bad request
req.setBroken(true);
req.setData(t);
}
return req;
}
}
上面的 decodeBody 只是进行了部分字段的解码和封装,之后会调用 DecodeableRpcInvocation 的 decode 方法完成详细数据的反序列化。
public Object decode(Channel channel, InputStream input) throws IOException {
// 通过缓存获取序列化器,这里的序列化器是在服务启动的时候就初始化好的,
// 调用序列化得到ObjectInput
ObjectInput in = CodecSupport.getSerialization(channel.getUrl(), serializationType)
.deserialize(channel.getUrl(), input);
this.put(SERIALIZATION_ID_KEY, serializationType);
// 读取dubbo版本
String dubboVersion = in.readUTF();
request.setVersion(dubboVersion);
setAttachment(DUBBO_VERSION_KEY, dubboVersion);
// 读取调用的具体实现类路径
String path = in.readUTF();
setAttachment(PATH_KEY, path);
String version = in.readUTF();
setAttachment(VERSION_KEY, version);
// 读取方法
setMethodName(in.readUTF());
// 读取参数类型描述
String desc = in.readUTF();
setParameterTypesDesc(desc);
// ... (安全检查、查找服务描述器、设置类加载器等逻辑)
// 读取参数值数组
Object[] args = new Object[pts.length];
for (int i = 0; i < args.length; i++) {
try {
args[i] = in.readObject(pts[i]);
} catch (Exception e) {
if (log.isWarnEnabled()) {
log.warn("Decode argument failed: " + e.getMessage(), e);
}
}
}
// 设置参数类型
setParameterTypes(pts);
// 读取attachments
Map<String, Object> map = in.readAttachments();
if (map != null && map.size() > 0) {
Map<String, Object> attachment = getObjectAttachments();
if (attachment == null) {
attachment = new HashMap<>();
}
attachment.putAll(map);
setObjectAttachments(attachment);
}
// 反序列化参数 (处理回调等)
for (int i = 0; i < args.length; i++) {
args[i] = callbackServiceCodec.decodeInvocationArgument(channel, this, pts, i, args[i]);
}
// 设置参数
setArguments(args);
// 构建目标服务唯一标识
String targetServiceName = buildKey((String) getAttachment(PATH_KEY),
getAttachment(GROUP_KEY),
getAttachment(VERSION_KEY));
setTargetServiceUniqueName(targetServiceName);
return this;
}
经历上述步骤,请求参数就被解析成为一个完整的 Request 对象,接着会触发下一个 Handler,最终通过反射调用目标对象的具体方法。
服务端响应序列化
服务提供方调用完具体方法后,会把返回值封装为 Response,再经过序列化写回服务消费方。其核心流程与请求序列化类似。
调用到 org.apache.dubbo.remoting.exchange.codec.ExchangeCodec#encode,此时会走到处理响应的分支。
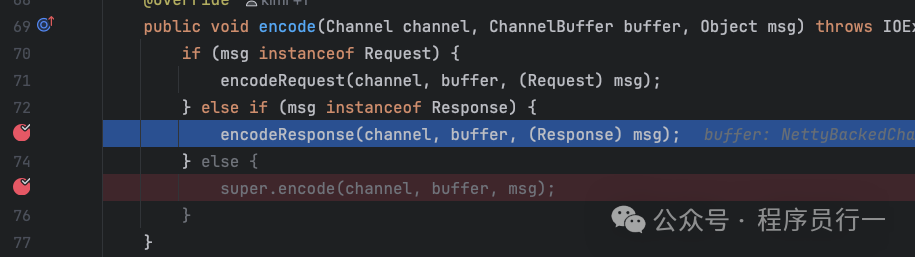
public void encode(Channel channel, ChannelBuffer buffer, Object msg) throws IOException {
if (msg instanceof Request) {
// 序列化请求参数(消费端)
encodeRequest(channel, buffer, (Request) msg);
} else if (msg instanceof Response) {
// 序列化返回值(服务端)
encodeResponse(channel, buffer, (Response) msg);
} else {
super.encode(channel, buffer, msg);
}
}
继续看 org.apache.dubbo.remoting.exchange.codec.ExchangeCodec#encodeResponse。
protected void encodeResponse(Channel channel, ChannelBuffer buffer, Response res) throws IOException {
int savedWriteIndex = buffer.writerIndex();
try {
Serialization serialization = getSerialization(channel, res);
// 创建消息头字节数组,长度16
byte[] header = new byte[HEADER_LENGTH];
// 设置魔术
Bytes.short2bytes(MAGIC, header);
// 设置序列化标识
header[2] = serialization.getContentTypeId();
if (res.isHeartbeat()) {
header[2] |= FLAG_EVENT;
}
// 设置响应状态
byte status = res.getStatus();
header[3] = status;
// 设置请求id
Bytes.long2bytes(res.getId(), header, 4);
// 更新writerIndex并且为消息头预留 16 个字节的空间
buffer.writerIndex(savedWriteIndex + HEADER_LENGTH);
// 设置输出流对象
ChannelBufferOutputStream bos = new ChannelBufferOutputStream(buffer);
// 对返回值序列化
if (status == Response.OK) {
if (res.isHeartbeat()) {
// 心跳数据返回值为空
bos.write(CodecSupport.getNullBytesOf(serialization));
} else {
// 序列化
ObjectOutput out = serialization.serialize(channel.getUrl(), bos);
// 事件类型
if (res.isEvent()) {
encodeEventData(channel, out, res.getResult());
} else {
// 正常请求编码
encodeResponseData(channel, out, res.getResult(), res.getVersion());
}
out.flushBuffer();
if (out instanceof Cleanable) {
((Cleanable) out).cleanup();
}
}
} else {
// 异常情况,序列化错误信息
ObjectOutput out = serialization.serialize(channel.getUrl(), bos);
out.writeUTF(res.getErrorMessage());
out.flushBuffer();
if (out instanceof Cleanable) {
((Cleanable) out).cleanup();
}
}
// 完成序列化flush
bos.flush();
// 关闭流
bos.close();
int len = bos.writtenBytes();
checkPayload(channel, len);
// 将消息体长度写入到消息头中
Bytes.int2bytes(len, header, 12);
// 将 buffer 指针移动到 savedWriteIndex,为写消息头做准备
buffer.writerIndex(savedWriteIndex);
// 从 savedWriteIndex 下标处写入消息头
buffer.writeBytes(header);
// 设置新的 writerIndex
buffer.writerIndex(savedWriteIndex + HEADER_LENGTH + len);
} catch (Throwable t) {
// 忽略异常
}
}
继续看 encodeResponseData,代码位置 org.apache.dubbo.rpc.protocol.dubbo.DubboCodec#encodeResponseData。
protected void encodeResponseData(Channel channel, ObjectOutput out, Object data, String version) throws IOException {
Result result = (Result) data;
// currently, the version value in Response records the version of Request
boolean attach = Version.isSupportResponseAttachment(version);
// 异常处理
Throwable th = result.getException();
if (th == null) {
// 返回值获取
Object ret = result.getValue();
if (ret == null) {
// 返回值为空序列化响应类型
out.writeByte(attach ? RESPONSE_NULL_VALUE_WITH_ATTACHMENTS : RESPONSE_NULL_VALUE);
} else {
// 返回值不为空,序列化返回值
out.writeByte(attach ? RESPONSE_VALUE_WITH_ATTACHMENTS : RESPONSE_VALUE);
out.writeObject(ret);
}
} else {
// 异常情况也需要序列化,标记类型,并把异常信息序列化返回
out.writeByte(attach ? RESPONSE_WITH_EXCEPTION_WITH_ATTACHMENTS : RESPONSE_WITH_EXCEPTION);
out.writeThrowable(th);
}
if (attach) {
// 返回dubbo版本
result.getObjectAttachments().put(DUBBO_VERSION_KEY, Version.getProtocolVersion());
// 序列化attachments
out.writeAttachments(result.getObjectAttachments());
}
}
经过以上流程,就完成了服务端序列化返回值的核心逻辑。
客户端响应反序列化
客户端接收到响应数据后的反序列化流程与服务端接收请求的逻辑大致类似。关键流程在 org.apache.dubbo.rpc.protocol.dubbo.DubboCodec#decodeBody 的 response 部分。
protected Object decodeBody(Channel channel, InputStream is, byte[] header) throws IOException {
byte flag = header[2], proto = (byte) (flag & SERIALIZATION_MASK);
// get request id.
long id = Bytes.bytes2long(header, 4);
if ((flag & FLAG_REQUEST) == 0) {
// 构建response对象
Response res = new Response(id);
if ((flag & FLAG_EVENT) != 0) {
res.setEvent(true);
}
// 获取服务端返回的状态
byte status = header[3];
res.setStatus(status);
try {
// 正常返回处理
if (status == Response.OK) {
Object data;
if (res.isEvent()) {
// ... 处理事件响应
} else {
DecodeableRpcResult result;
if (channel.getUrl().getParameter(DECODE_IN_IO_THREAD_KEY, DEFAULT_DECODE_IN_IO_THREAD)) {
// 在IO线程解码
result = new DecodeableRpcResult(channel, res, is,
(Invocation) getRequestData(id), proto);
result.decode();
} else {
// 包装反序列化数据,构建完成后,会交给下一个handler调用decode
result = new DecodeableRpcResult(channel, res,
new UnsafeByteArrayInputStream(readMessageData(is)),
(Invocation) getRequestData(id), proto);
}
data = result;
}
res.setResult(data);
// ... (后续处理)
接着看 DecodeableRpcResult 的 decode 方法。
public Object decode(Channel channel, InputStream input) throws IOException {
ObjectInput in = CodecSupport.getSerialization(channel.getUrl(), serializationType)
.deserialize(channel.getUrl(), input);
// 这里的flag跟前面服务端设置返回类型对应起来的
byte flag = in.readByte();
switch (flag) {
// 返回值为空
case DubboCodec.RESPONSE_NULL_VALUE:
break;
// 正常返回
case DubboCodec.RESPONSE_VALUE:
handleValue(in);
break;
// 异常
case DubboCodec.RESPONSE_WITH_EXCEPTION:
handleException(in);
break;
// 返回值为空,但是携带了Attachments
case DubboCodec.RESPONSE_NULL_VALUE_WITH_ATTACHMENTS:
handleAttachment(in);
break;
// 正常返回,同时携带了Attachments
case DubboCodec.RESPONSE_VALUE_WITH_ATTACHMENTS:
handleValue(in);
handleAttachment(in);
break;
// 异常,但是携带了Attachments
case DubboCodec.RESPONSE_WITH_EXCEPTION_WITH_ATTACHMENTS:
handleException(in);
handleAttachment(in);
break;
default:
throw new IOException("Unknown result flag, expect '0' '1' '2' '3' '4' '5', but received: " + flag);
}
return this;
}
处理方法示例:
handleValue(in):根据调用信息中的返回类型,反序列化具体的返回值对象。handleException(in):读取并反序列化服务端抛出的异常。handleAttachment(in):读取附加信息。
至此,就介绍完了从客户端发起请求到接收到响应的完整序列化与反序列化流程。作为 中间件 的核心组成部分,序列化的高效与稳定至关重要。
序列化完成后回调业务线程进行数据返回
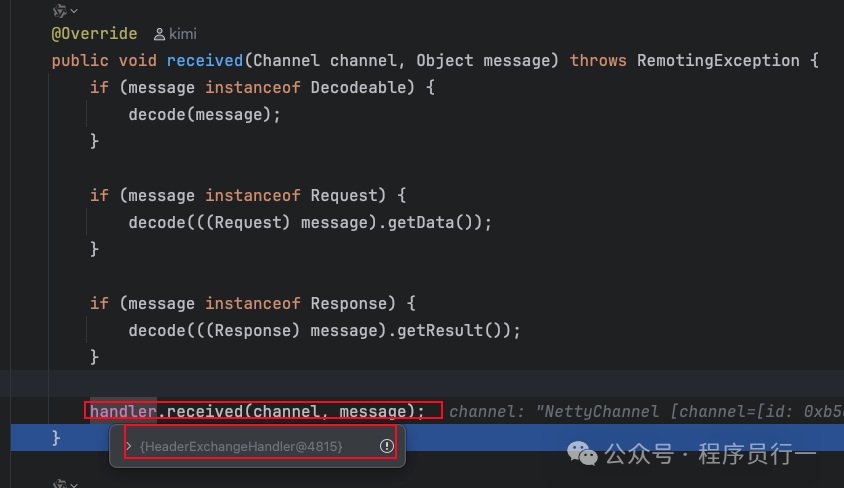
在 HeaderExchangeHandler#received 中处理响应:
if (message instanceof Request) {
// ...
} else if (message instanceof Response) {
// 处理响应
handleResponse(channel, (Response) message);
} else if (message instanceof String) {
之后调用 DefaultFuture#doReceived 完成异步回调:
private void doReceived(Response res) {
if (res == null) {
throw new IllegalStateException("response cannot be null");
}
if (res.getStatus() == Response.OK) {
// 这里会返回给dubbo代理了
this.complete(res.getResult());
}
}
最终,结果通过 AsyncRpcResult 返回给 Dubbo 的代理调用方。
写在最后
核心内容回顾
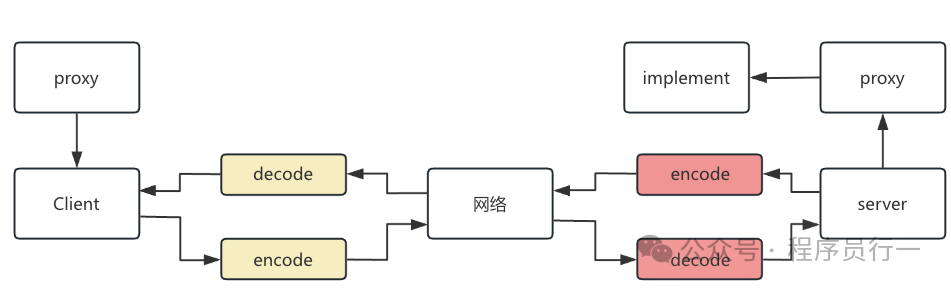
一次完整的 Dubbo RPC 调用涉及四次序列化操作:客户端请求序列化、服务端请求反序列化、服务端响应序列化、客户端响应反序列化。流程示意图如下:
Dubbo 将这些关键操作封装到独立的序列化模块中,并通过 SPI 机制支持多种协议,代码复用度高,体现了良好的可读性和可维护性。深入理解这一机制,对于性能调优、问题排查及自定义扩展都大有裨益。希望本篇深度解析能帮助你在 云栈社区 的交流学习中更进一步。
 发表于 2026-1-26 03:30:24
|
查看: 204|
回复: 0
发表于 2026-1-26 03:30:24
|
查看: 204|
回复: 0
