人工智能时代的到来,意味着AI驱动软件的成本结构与传统软件存在巨大差异。芯片微架构和系统架构的创新,直接关系到新型软件的开发效率与可扩展性。相比于早期软件,AI软件的运行更依赖于底层硬件设施,这对资本支出、运营支出乃至毛利率都有着更显著的影响。因此,投入大量精力优化AI基础设施,对于成功部署AI应用至关重要。在基础设施方面具备优势的企业,无疑将在AI应用的部署和扩展中占据先机。
1. 谷歌TPU芯片发展简史
谷歌早在2006年就提出了构建专用AI基础设施的构想,而这一需求在2013年变得尤为迫切。当时他们意识到,若想大规模部署AI,可能需要将数据中心数量翻倍。这促使他们开始为自研的TPU芯片打下基础,这些芯片最终于2016年投入生产。有趣的是,同年亚马逊也启动了Nitro计划,专注于优化通用CPU计算与存储的定制硅片。两家公司虽然目标不同,但都基于各自对计算时代和软件范式的理解,优化了其基础设施策略。
自2016年以来,谷歌已研发并迭代了6代AI专用芯片,包括TPU、TPUv2、TPUv3、TPUv4i、TPUv4以及最新的TPUv5。这些芯片由谷歌主导设计,Broadcom提供不同程度的协作,并由台积电代工制造。从TPUv2开始,芯片还集成了由三星和SK海力士提供的HBM内存。谷歌芯片的独特架构固然重要,但更值得关注的是其整体化部署能力。
谷歌在以低成本、高性能且可靠地大规模部署AI方面,拥有近乎无与伦比的能力。得益于从微架构到系统架构的整体优化,谷歌在AI工作负载上相对于微软和亚马逊具备显著的性能与总拥有成本优势。
技术领域的竞争是一场永无止境的军备竞赛,而人工智能是其中发展最快的战场。模型架构随着时间推移发生了巨大演变。以谷歌内部数据为例,2016年至2019年间,CNN模型迅速崛起后又逐渐被替代。CNN的计算特性、内存访问模式与DLRM、Transformer和RNN等模型截然不同。RNN也经历了类似的命运,最终被Transformer架构完全取代。
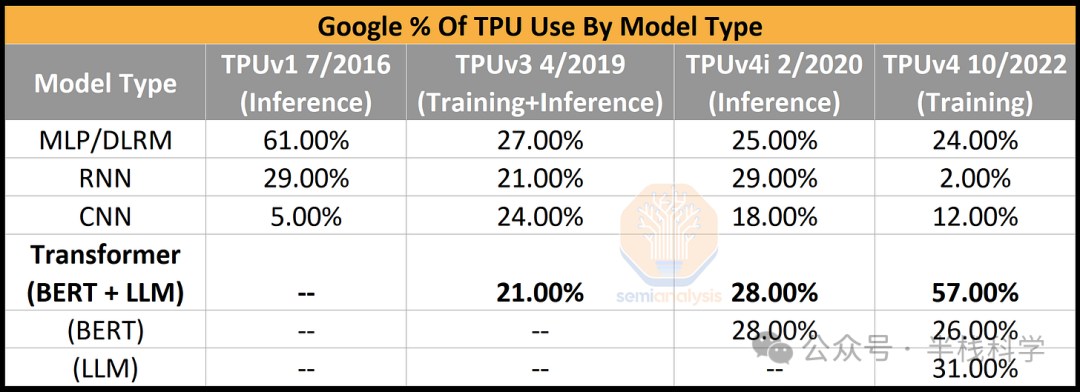
因此,底层硬件必须具备足够的灵活性,以适应行业的快速迭代。硬件不能过度专注于某一特定模型架构,否则将面临随着架构变迁而过时的风险。从芯片开发到大规模量产部署通常需要4年时间,这使得硬件可能滞后于软件的发展需求。这一点已在一些以特定模型为优化目标的AI加速器初创公司身上显现,这也是导致许多AI硬件初创公司失败的原因之一。
谷歌自家的TPUv4i芯片就是一个例证,这款为推理设计的芯片却无法在PaLM等谷歌最佳模型上运行推理。上一代的TPUv4和英伟达A100也显然并非专为大型语言模型设计。同样,近期部署的TPUv5和英伟达H100也非为应对MoE(混合专家)等新策略而开发,而这些策略正是GPT-4等模型的核心部分。
此外,芯片微架构只是AI基础设施真实成本的一小部分,系统级架构和部署灵活性才是更关键的因素。
2. 谷歌的系统基础设施优势
谷歌在基础设施上的核心优势之一,在于始终从系统层面设计TPU。这意味着单个芯片的性能固然重要,但如何在现实系统中高效使用这些芯片更为关键。因此,我们的分析将从系统架构、部署使用一直深入到芯片层面。
虽然英伟达也具备系统思维,但其系统规模通常小于且专精于谷歌的范畴。此外,直到最近,英伟达在云部署方面仍缺乏直接经验。谷歌在AI基础设施上的重大创新之一,是在TPU间使用了自定义的网络堆栈ICI。这种链路相对于昂贵的以太网和InfiniBand部署,具有更低的延迟和更高的性能,其理念更接近于英伟达的NVLink。
谷歌的TPUv2可以扩展到256个芯片,这与英伟达当前一代H100 GPU的单系统规模相当。通过TPUv3,他们将这一数字提升至1024,TPUv4更是达到了4096。根据趋势推测,当前一代的TPUv5有望扩展到16384个芯片,且无需经过低效的以太网交换。这种大规模扩展能力对于训练巨型模型至关重要,但更关键的是谷歌能够高效地将这些资源分配用于实际任务。

谷歌的TPUv4系统每台服务器配备8块TPUv4芯片和2个CPU,这与配备8块A100或H100及2个CPU的英伟达服务器配置相似。然而,对于TPU而言,基本的部署单元是一个更大的“切片”,包含64块TPU芯片和16个CPU。这64块芯片通过直接连接的铜缆,在内部以4^3立方体的形式通过ICI网络互联。

在这个64芯片的单元之外,通信将转移到光域。光收发器的成本是无源铜缆的十倍以上,因此谷歌将切片大小优化为64,旨在从网络角度最小化系统层面的总体成本。
3. 通过拓扑结构最小化网络成本
需要明确的是,谷歌与英伟达的网络拓扑结构截然不同。英伟达系统通常部署“Clos网络”,这是一种“非阻塞”网络,能够在所有输入输出对之间同时建立全带宽连接,无需担心冲突或阻塞。这种设计为连接数据中心内的大量设备提供了可扩展的方法,最小化了延迟并增加了冗余。
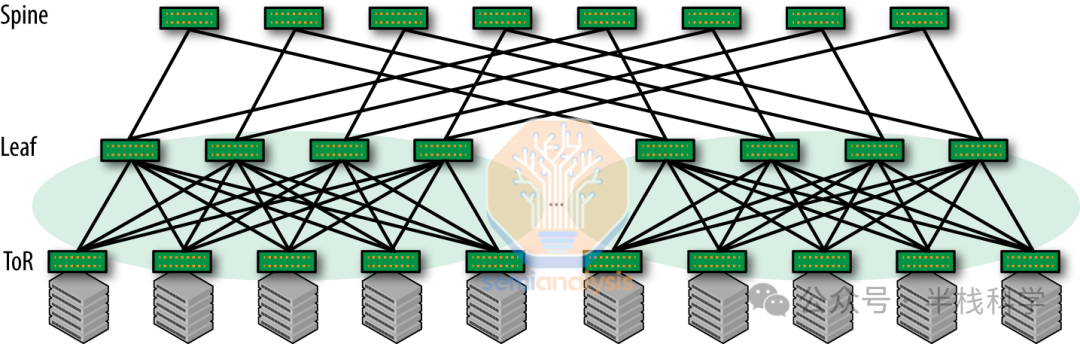
而谷歌的TPU网络则采用了不同的路径。他们使用3D环面拓扑结构,将节点连接在一个三维网格中。每个节点在网格中与六个相邻节点相连(上下、左右、前后),在三个维度上形成闭合环路,从而构建了一个高度互联的网络结构。
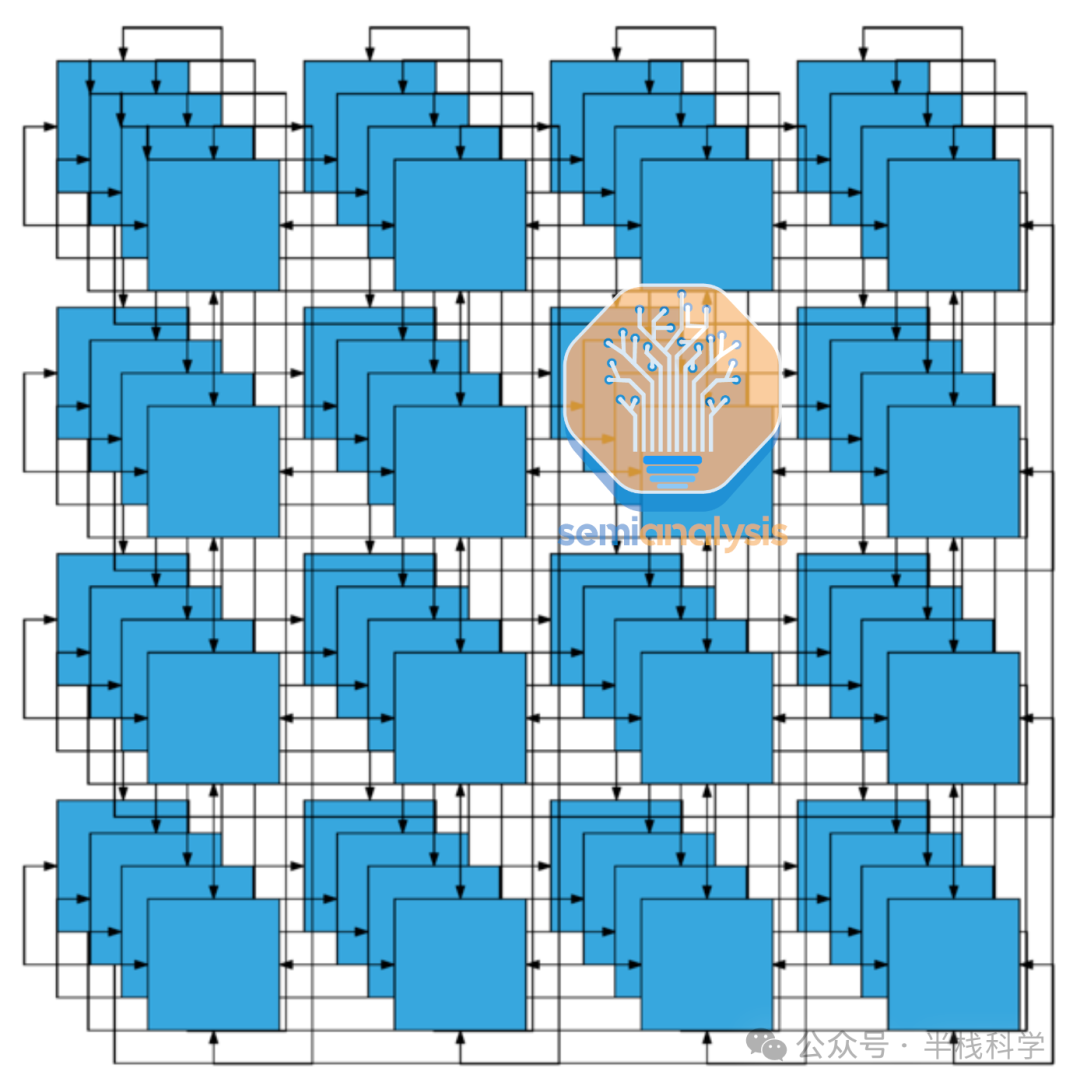
第一张图更合理,但如果你仔细想想,又有点饿了,这个网络拓扑字面意思就是一个甜甜圈!
环面拓扑相较于英伟达使用的Clos拓扑有几个优势:
- 更低的延迟:3D环面拓扑由于相邻节点间具有短而直接的连接,能够提供更低的延迟。这对于需要节点间频繁通信的紧密耦合并行应用程序(如某些AI模型)特别有用。
- 更好的局部性:在3D环面网络中,物理上靠近的节点在逻辑上也靠近,这可以带来更好的数据局部性和更少的通信开销。除了延迟,功耗方面也具有优势。
- 更小的网络直径与成本:对于相同数量的节点,3D环面的网络直径通常小于Clos网络。由于所需的交换机数量显著减少,因此能节省巨大的成本。
另一方面,3D环面网络也存在一些缺点:
- 可预测的性能:Clos网络由于其非阻塞特性,能够提供可预测且一致的性能。它确保所有连接可以同时以全带宽运行,这是3D环面网络无法保证的。
- 更容易扩展:在Clos的脊-叶架构中,添加新的叶交换机以容纳更多服务器相对简单。而扩展3D环面网络则可能需要重新配置整个拓扑,更为复杂和耗时。
- 负载均衡:Clos网络在任意两个节点间提供更多路径,允许更好的负载均衡和冗余。虽然3D环面也提供多条路径,但Clos网络中的替代路径数量通常更高。
总体而言,虽然Clos网络有其优势,但谷歌的光电路交换机(OCS)技术缓解了环面拓扑的许多问题。OCS实现了多个切片和多个Pod之间的简易扩展。
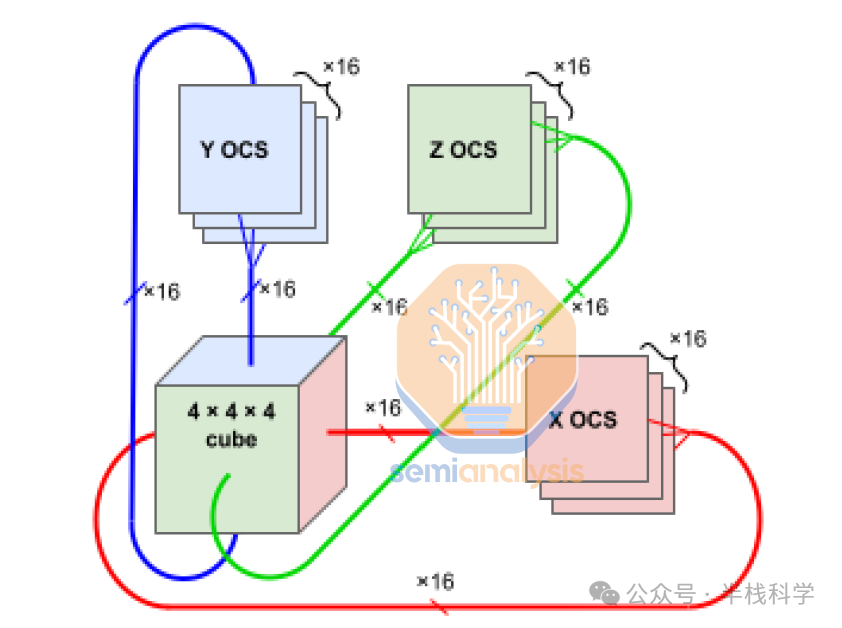
3D环面拓扑面临的最大挑战之一是错误处理。错误难以避免。即使单个主机的可用性达到99%,一个包含2048个TPU的任务切片也几乎无法持续运行。即使在99.9%的可用性下,如果没有谷歌的OCS,使用2000个TPU的训练任务也只有50%的成功率。
4. OCS的动态重配置能力
OCS的精妙之处在于其能够动态重新配置路由。
它需要备用资源来允许在部分节点失败时重新调度任务。操作员无法在不冒失败风险的情况下,从一个4K节点的Pod中调度两个2K节点的切片。基于英伟达GPU的训练任务通常需要大量额外开销用于检查点、拉取失败节点并重启。谷歌通过使用OCS简单地绕过失败节点,在一定程度上简化了这一过程。
OCS的另一个好处是,切片可以在部署后立即投入使用,而无需等待整个网络配置完成。
5. 部署基础设施——用户视角
从成本和功耗角度提升基础设施效率固然重要,这让谷歌每美元能部署比竞争对手更多的算力,但这对于最终用户而言意义不大。谷歌内部用户体验到的最大优势之一,是他们能够根据特定模型的需求来定制基础设施配置。
没有任何芯片或系统能够完美匹配所有用户对内存、网络和计算类型的要求。芯片需要具备通用性,但用户同时也渴望灵活性,而非“一刀切”的解决方案。英伟达通过提供多种不同的GPU SKU变体、内存容量层级以及更紧密的集成方案(如Grace Hopper超级芯片和用于SuperPods的NVLink网络)来解决这一问题。
谷歌则无法承受这种奢侈。每个额外的SKU都意味着单个SKU的总体部署量下降,进而降低基础设施的利用率。更多的SKU也使得用户在需要时更难获得特定的计算类型,因为某些配置 inevitably 会被过度订阅,用户将被迫使用次优配置。
因此,谷歌面临一个难题:既要满足研究人员对特定配置的需求,又要最小化SKU的多样性。与必须为其庞大而多样的客户群支持数百种部署规模和SKU的英伟达不同,谷歌的TPUv4基本上只有一种部署配置:包含4096个TPU的Pod。尽管如此,谷歌能够以独特的方式切割和分配这些资源,使内部用户获得他们所期望的基础设施灵活性。
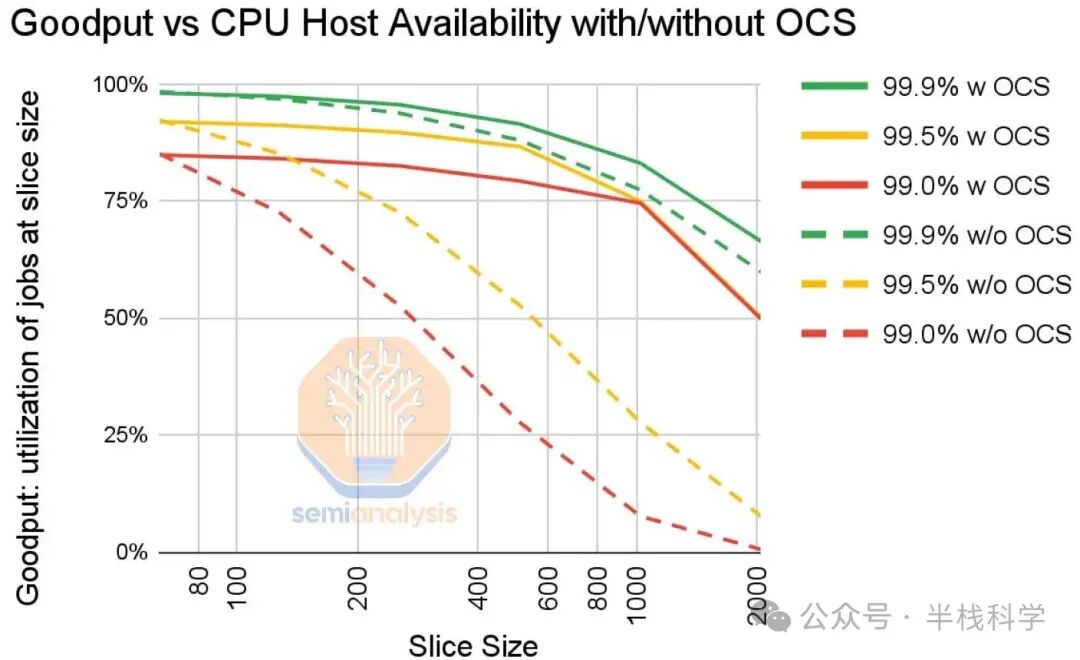
谷歌的OCS还支持创建自定义网络拓扑,例如“扭曲环面”。这是在三维环面网络的基础上,对某些维度进行“扭曲”连接,使得网络边缘的节点以非线性方式连接,从而在节点之间创建额外的“捷径”,这进一步改善了网络直径、负载均衡和性能。
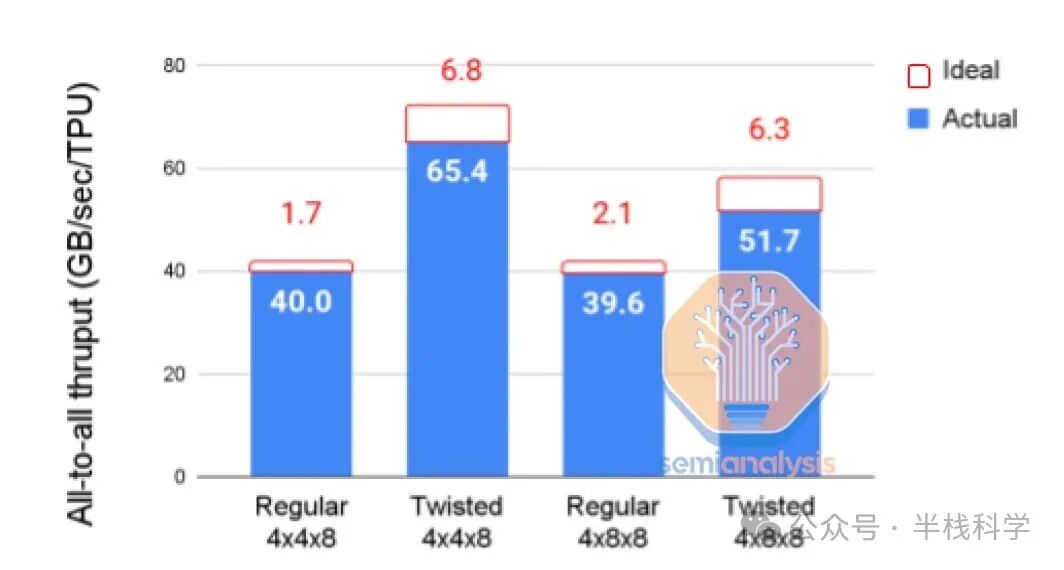
谷歌团队充分利用这一优势来优化特定模型架构。下图是2022年11月某一天中,各种TPU配置在芯片数量和网络拓扑上的使用情况快照。尽管许多配置的芯片总数相同,但仍存在超过30种不同的配置,以适应正在开发的各种模型架构。这深刻体现了谷歌在使用TPU方面的巨大灵活性和洞察力。
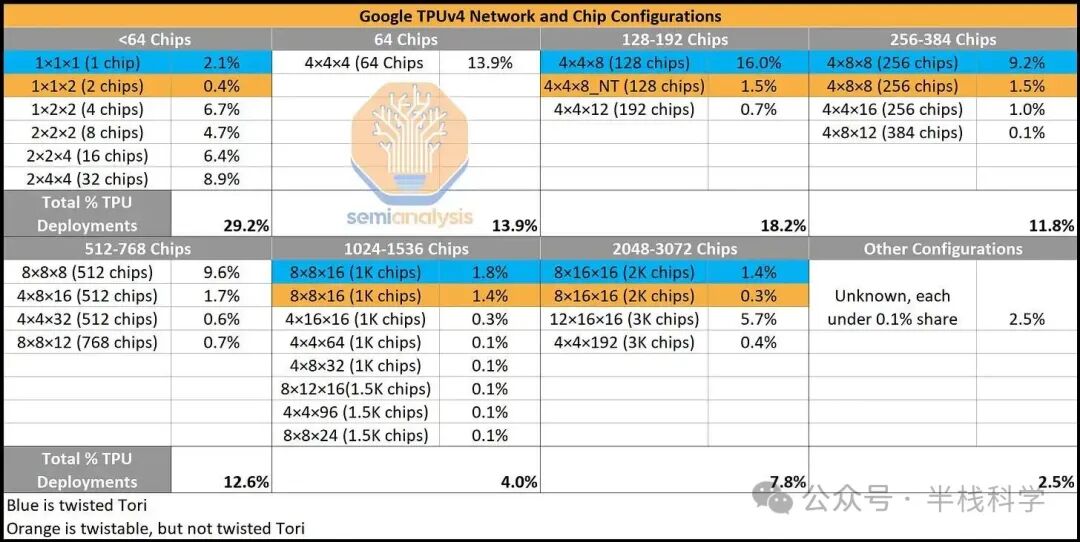
为了充分利用可用带宽,用户通常将数据并行映射到3D环面的一维上,而在其他维度上映射模型并行参数。谷歌声称,选择最佳拓扑能使性能提升1.2倍至2.3倍。
6. 规模最大的 AI 模型架构:DLRM
DLRM旨在通过对分类特征和数值特征进行建模,来学习用户-物品交互的有意义表示。其架构主要由两个部分组成:处理分类特征的嵌入组件和处理数值特征的多层感知器(MLP)组件。
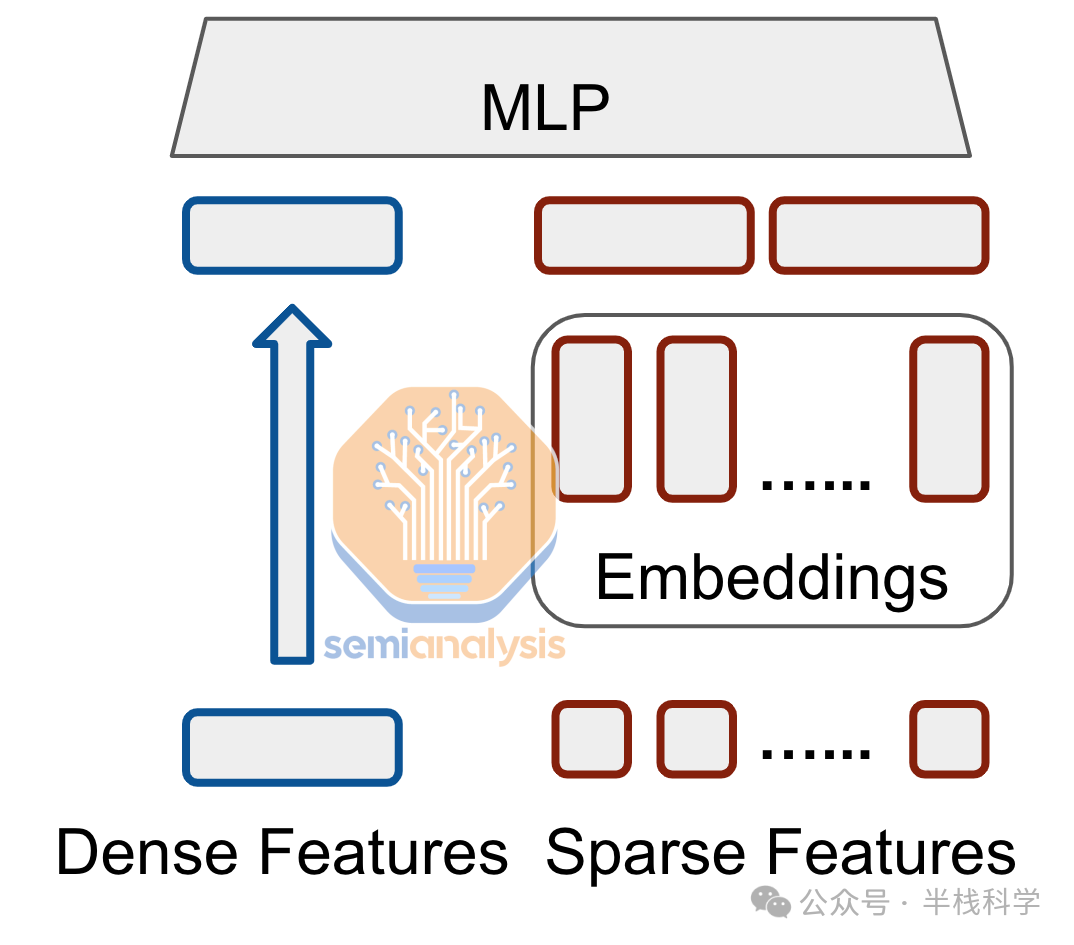
简而言之,MLP组件是密集的。特征被输入一系列全连接层中,这类似于GPT-4之前的老式Transformer架构,它们也是密集计算。密集层能够非常好地映射到硬件上的大规模矩阵乘法单元。
嵌入组件是DLRM高度独特的部分,也是其计算特征如此特殊的原因。DLRM的输入是表示为离散、稀疏向量的分类特征。一次简单的谷歌搜索只包含整个语言中的几个词。由于这些稀疏输入本质上更类似于哈希表而非张量,因此它们无法高效映射到硬件中的大型矩阵乘法单元。为了将分类特征转换为更适合神经网络的密集向量,需要采用嵌入技术。
稀疏输入:[0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0]
密集向量:[0.3261477, 0.4263801, 0.5121493]
嵌入函数将分类空间(如英语单词、社交媒体互动)映射到更小、更密集的空间(例如代表每个单词的100维向量)。这些函数通过查找表实现,这些表是DLRM模型的重要组成部分,并且通常是第一层。嵌入表的大小差异巨大,从几十MB到几百GB甚至TB级别不等。
Meta两年前的一个DLRM模型参数量就超过12万亿,运行推理需要128个GPU。如今,最大的生产级DLRM模型至少还要大数倍,仅模型嵌入部分就需要超过30TB的内存。预计明年嵌入量将增加到超过70TB!因此,这些表需要跨多个芯片的内存进行分区,主要方法包括列分片、行分片和表分片。
DLRM的性能主要受限于内存带宽、内存容量、向量处理性能以及芯片间网络/互连。嵌入查找操作主要包含小规模的聚合或分散式内存访问,算术强度很低(FLOPS几乎不重要)。对嵌入表的访问本质上是无结构的稀疏访问。每个查询都必须从分布在数百或数千个芯片上的超过30TB的嵌入数据中获取数据,这可能导致在运行DLRM推理时出现计算、内存和通信负载的不平衡。
这与MLP和类似GPT-3的Transformer中的密集操作形成鲜明对比。对于密集操作,芯片的FLOPS/sec仍然是主要性能驱动因素之一。除了FLOPs外,虽然还有其他制约因素,但GPU在Chinchilla风格的大型语言模型中仍能实现超过71%的硬件FLOPs利用率。
7. 谷歌的 TPU 架构
谷歌的TPU在架构上引入了一些关键创新,使其区别于传统处理器。与常规处理器不同,TPU v4没有专门的指令缓存,而是采用了类似Cell处理器的直接内存访问(DMA)机制。TPU v4中的向量缓存并非标准缓存层次结构的一部分,而是被用作暂存器。暂存器与标准缓存的不同在于需要手动管理数据写入。
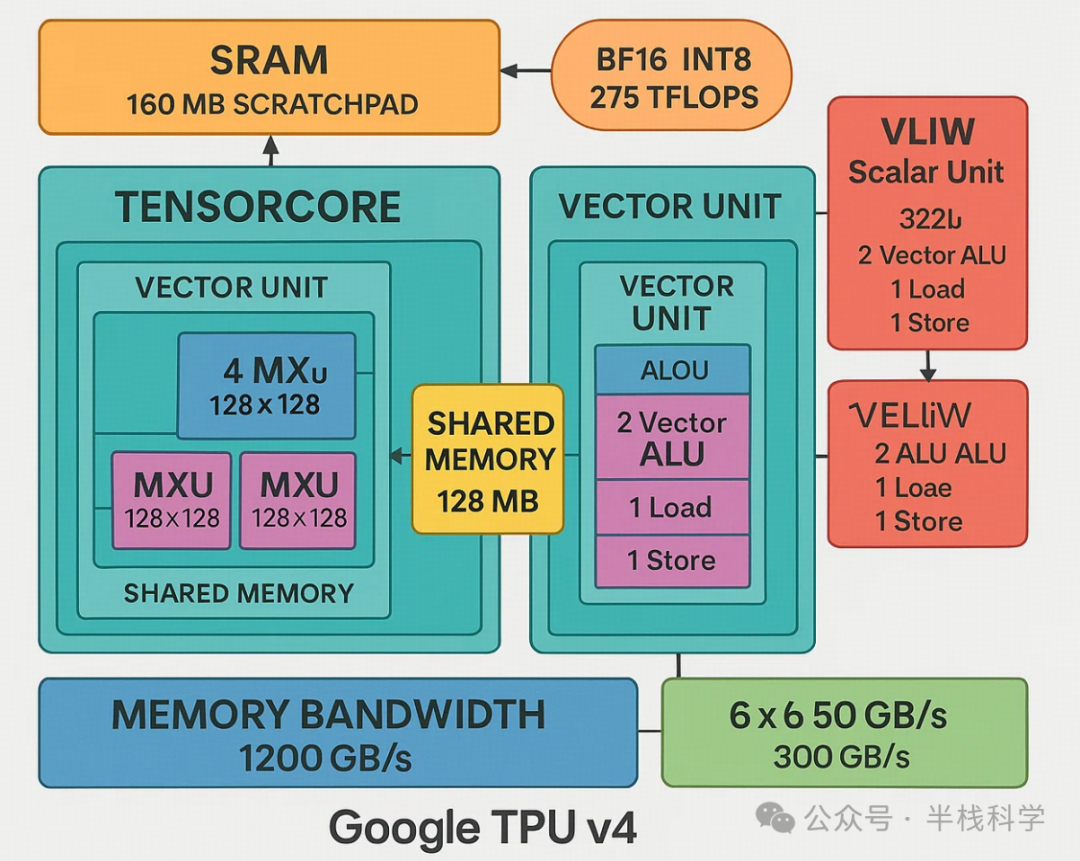
TPU v4配备了160MB的SRAM用作暂存器,并拥有2个张量核心。每个张量核心包含1个向量单元,该向量单元有4个矩阵乘法单元(MXU)和16MB的向量内存。这两个张量核心共享128MB的内存。它们支持275 TFLOPS的BF16运算和INT8数据类型。TPU v4的内存带宽为1200GB/s。芯片间互连(ICI)通过六个50GB/s的链路提供总计300GB/s的数据传输速率。
TPU v4还包含一个322位超长指令字(VLIW)标量计算单元。在VLIW架构中,多条指令在程序编译时被组合成一个长指令字包。一个VLIW包最多可包含2条标量指令、2条向量ALU指令、1条向量加载和1条向量存储指令,以及2个用于向MXU传输数据的槽位。
向量处理单元(VPU)配备了32个2D寄存器,每个寄存器包含128x8个32位元素,使其成为一个2D向量ALU。矩阵乘法单元(MXU)在TPU v2、v3和v4上是128x128的规模(v1为256x256)。谷歌的模拟发现,四个128x128的MXU比一个256x256的MXU利用率高60%,而两者占用芯片面积相同。MXU使用16位浮点数(FP)输入,并以32位浮点数进行累加。
这些大型计算单元的设计,旨在通过高效的数据重用来突破“内存墙”的限制。
8. 谷歌 DLRM 优化
谷歌是率先在其搜索产品中大规模使用DLRM的公司之一。这种独特的需求催生了针对性的解决方案。前述的TPU架构存在一个主要缺陷:无法高效处理DLRM的嵌入操作。谷歌的主张量核心过于庞大,与嵌入计算的特性不匹配。为此,谷歌不得不在其TPU中开发了一种全新的“稀疏核心”,这与用于密集层计算的“张量核心”截然不同。
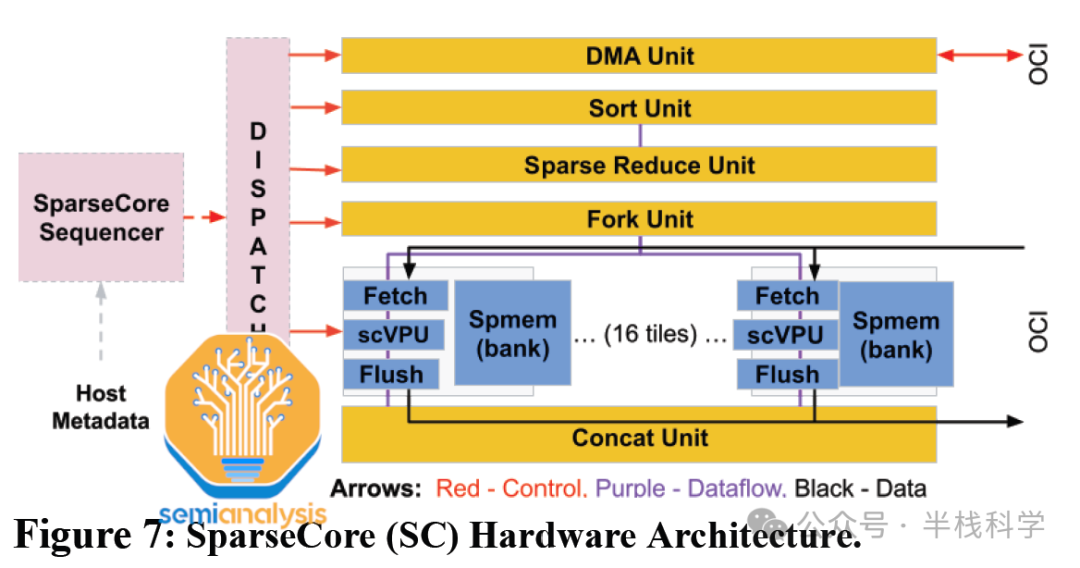
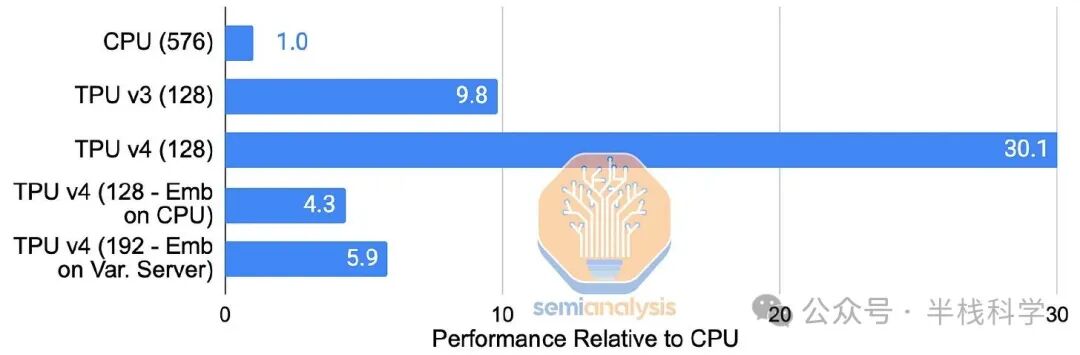
稀疏核心为谷歌TPU中的嵌入操作提供了硬件加速支持。从TPU v2开始,这些特定领域的处理器就直接与每个HBM(高带宽内存)通道/子通道相连。它们加速了训练深度学习推荐模型时最消耗内存带宽的部分,而仅占芯片面积和功耗的约5%。通过在每个TPU v4芯片上使用快速的HBM2内存处理嵌入,而不是依赖CPU的主内存,谷歌将其内部生产DLRM的推理速度提升了7倍。
稀疏核心能够实现从HBM的快速内存访问,配备了专门的获取、处理和刷新单元,将数据移动到稀疏向量内存的存储体中,并由可编程的8位宽SIMD向量处理单元进行更新。16个这样的计算瓦片组成了一个稀疏核心。
额外的跨通道单元执行特定的嵌入操作(如DMA、排序、稀疏归约等)。每个TPU v4芯片有4个稀疏核心,每个核心配备2.5MB的稀疏向量内存。展望未来,推测TPUv5的稀疏核心数量可能会因HBM3子通道增加而提升至6个,计算瓦片数量也可能增至32个。
尽管迁移到HBM带来了巨大的性能提升,但性能扩展仍受限于互连的二分带宽。TPU v4中ICI采用的3D环面结构进一步提升了嵌入查找性能。然而,当扩展到1024个芯片时,性能提升会下降,因为稀疏核心本身的开销成为了瓶颈。
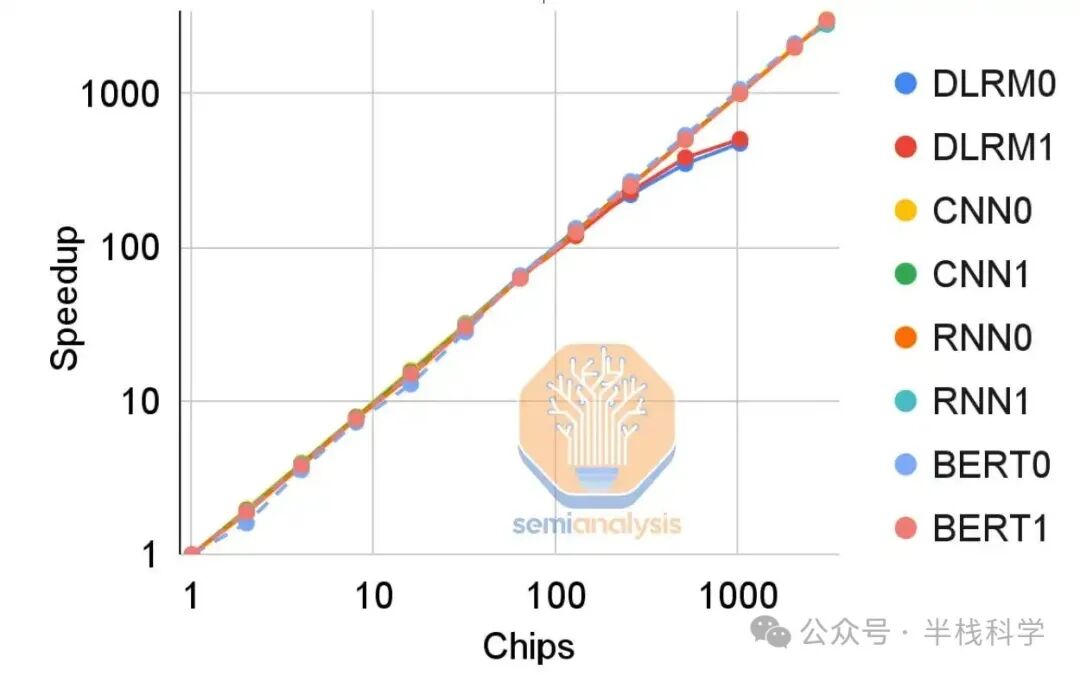
这个瓶颈很可能促使谷歌在TPUv5中增加每块芯片板上的稀疏内存容量,特别是如果他们预见到其DLRM模型需要超过约512个芯片的规模来容纳巨大的嵌入表。
 发表于 2025-12-2 03:53:32
|
查看: 210|
回复: 0
发表于 2025-12-2 03:53:32
|
查看: 210|
回复: 0
