
AI的竞争焦点,正从单纯的模型能力转向规模化推理能力。随着大模型在企业级场景的深入应用,推理系统的性能、成本与资源利用率,已成为决定AI商业化成功与否的关键。在这个过程中,存储作为AI基础设施的核心支撑,正成为释放算力潜力、重构推理效率结构的决定性力量。
为了系统评估智算中心的“存力”水平、打通技术研发与产业应用之间的壁垒,在NVIDIA、美团、三星、Solidigm等产业链领军企业的支持下,ODCC(开放数据中心委员会)成立了AI存储实验室。针对推理场景中普遍存在的数据响应瓶颈,实验室聚焦于大模型推理的关键制约因素——KVCache(Key-Value Cache,键值缓存),启动了面向存储软硬件的专项协同测试。这项工作的目标,是构建一套适配推理场景的KV Cache存储解决方案及测试规范,切实推动AI存储技术走向标准化、规范化与规模化落地。
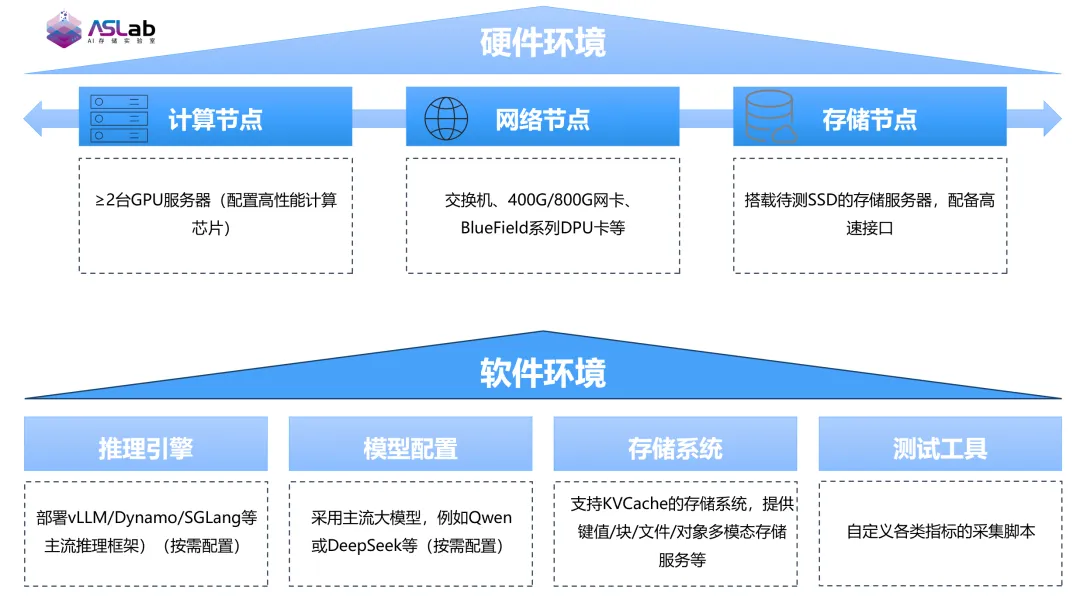
ODCC AI 存储实验室 KVCache 评测环境
焱融科技作为国内专业的AI存储厂商,其自主研发的YRCache推理存储系统参与了首批测试,并取得了优异的成果。测试结果不仅验证了YRCache对推理性能的显著提升,更揭示了一个关键价值:YRCache可以让中低配置的GPU跑出接近高配置GPU的推理性能,从而优化推理成本,从根本上重构企业在AI推理基础设施上的投入产出比。
本次测试的核心亮点数据:
-
推理性能实现数量级提升
- TTFT(首Token延时)降低97%,实现实时响应。
- TPOT(每个输出Token生成时间)降低97%,确保流式输出流畅。
- Token吞吐量(每秒生成token数)提升22倍,单token成本可同比降低。
-
低配GPU性能逼近高配,成本结构优化
- 在YRCache加持下,中端GDDR GPU的各项推理性能指标接近高端HBM GPU,投资回报率(ROI)提升高达14倍。
- 为企业提供了一条“用更低的算力预算获得更高推理能力”的可行路径。
测试背景:长上下文带来的KVCache挑战
随着大语言模型(LLM)的持续演进,应用场景不断拓展,上下文长度也快速增长。以 DeepSeek-R1 为代表的新一代推理模型,已支持超过100K的超长上下文。这虽然提升了模型处理复杂任务的能力,但也导致了KVCache的爆炸式增长。
KVCache是 Transformer 架构在推理阶段的核心数据结构,用于缓存注意力机制的中间结果,是影响推理效率的关键变量。随着上下文长度的增加,KVCache占用的显存呈线性膨胀,已成为推理系统的主要性能瓶颈。因此,如何高效管理KVCache,是决定大模型推理系统能否实现规模化的关键。
测试目的:验证存储对推理的加速效果
焱融YRCache推理存储系统是专为大规模推理设计的KVCache存储管理平台。它通过构建GPU显存、主机内存、本地NVMe SSD和YRCloudFile高性能分布式文件存储等多级KV缓存架构,显著扩展了KV缓存空间,旨在加速推理性能提升。本次测试的目的,就是在基于NVIDIA计算和网络平台的标准化环境下,客观评估YRCache对实际推理性能的提升效果。
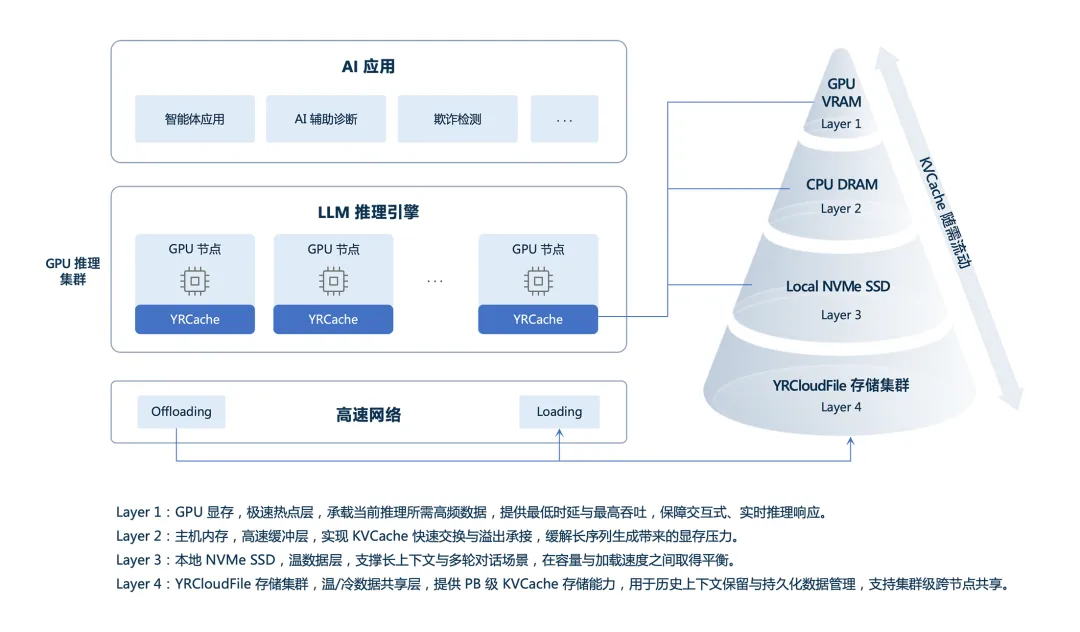
YRCache 架构图
测试环境与方法
本次测试主要围绕PD(Prefill-Decode)一体化推理场景,基于 DeepSeek-R1 等主流大模型,对比原生 vLLM 框架与集成YRCache后的系统,在不同网络带宽配置下的性能表现。
- 测试模型:
DeepSeek-R1-0528-FP4(671B参数,FP4量化),支持128K tokens上下文。
- 测试框架:
vLLM + YRCache(焱融客户端),基于RDMA/RoCEv2协议。
- 测试网络:采用NVIDIA Spectrum-X 400Gbps以太网,通过Spine-Leaf网络拓扑实现高速互联。
测试分别在两类典型的GPU算力环境中进行,以评估YRCache在不同硬件配置下的普适性:
- 中端GDDR GPU服务器:显存容量和带宽相对较低,面向成本敏感型的大规模推理部署、中等规模模型服务等场景。在此类环境下,系统对显存资源更为敏感。
- 高端HBM GPU服务器:显存容量和带宽更高,面向超大规模推理、高并发及长上下文推理等需求,如100K+ Tokens长文本处理、高端智算中心部署等。
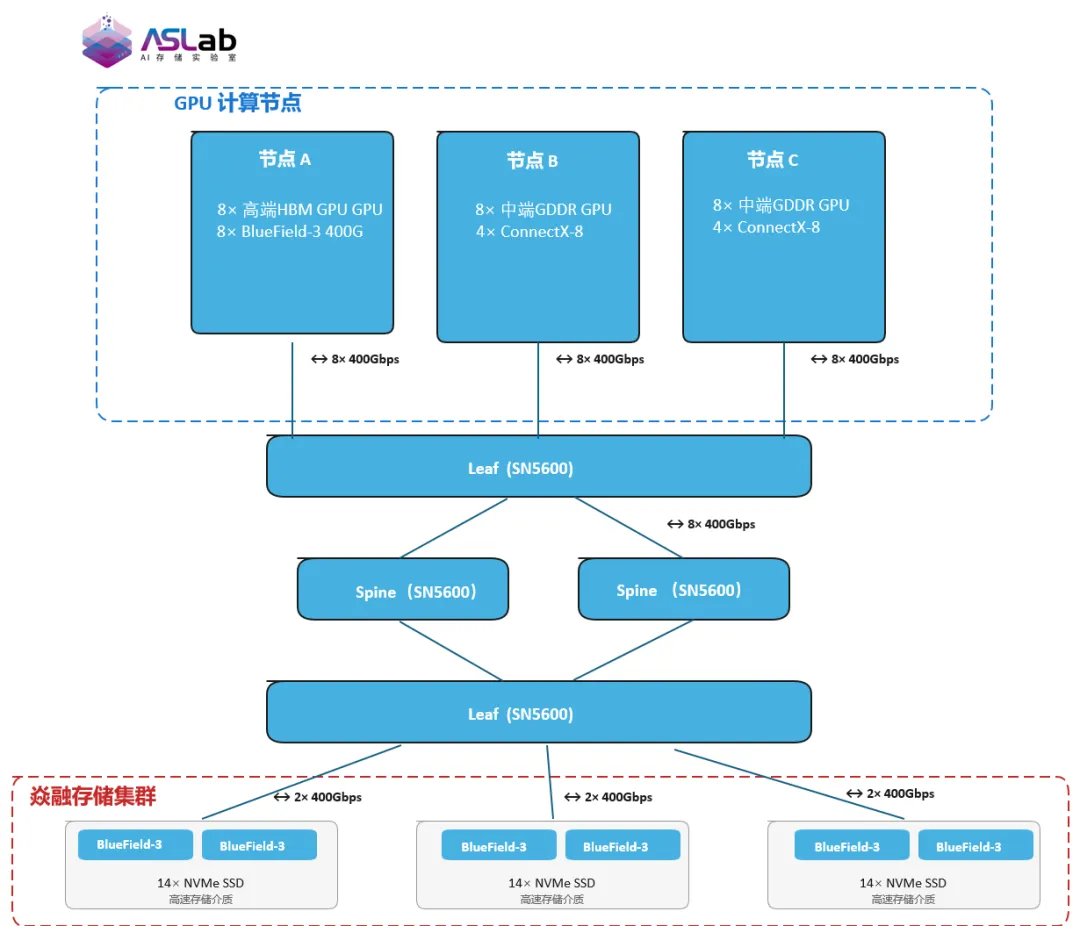
测试环境网络拓扑图
测试结果分析:性能飞跃与成本重塑
1. 推理性能的全面维度提升
在ODCC的严格测试中,对比原生vLLM框架,YRCache在不同GPU和网络配置下,均实现了TTFT、TPOT、Token吞吐量等核心指标的跨越式优化。

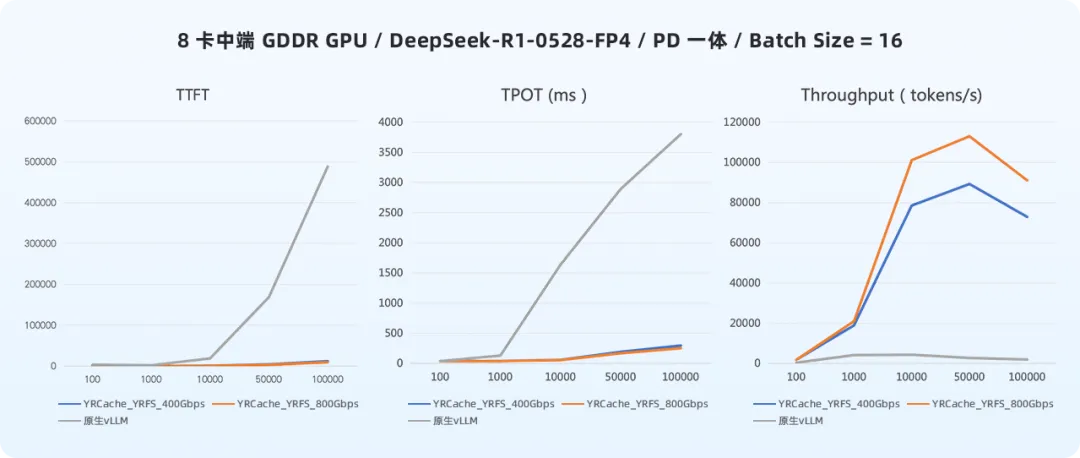
中端GDDR GPU环境下的表现:
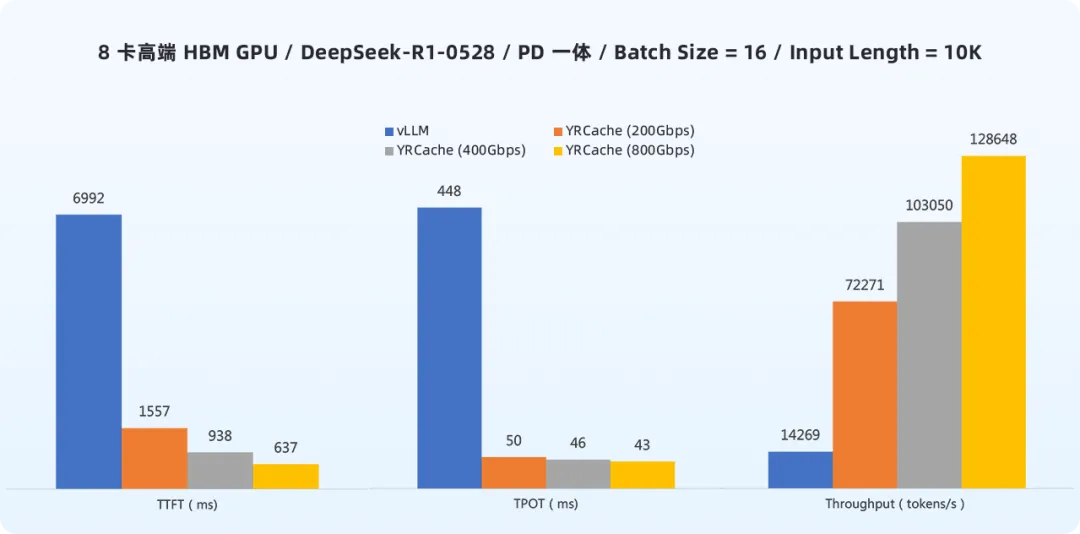
在8卡中端GDDR GPU、batch size=16、输入长度10K tokens的条件下:
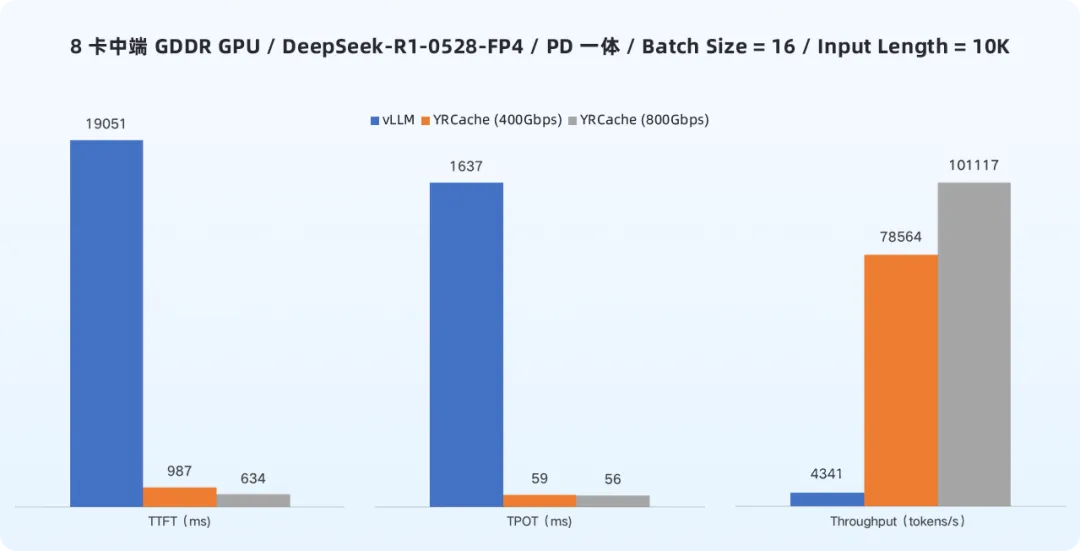
- 在400Gbps网络下,使用YRCache后,TTFT降低95%,TPOT降低96%,Token吞吐量提升17倍。
- 在800Gbps网络下,使用YRCache后,TTFT降低97%,TPOT降低97%,Token吞吐量提升22倍。
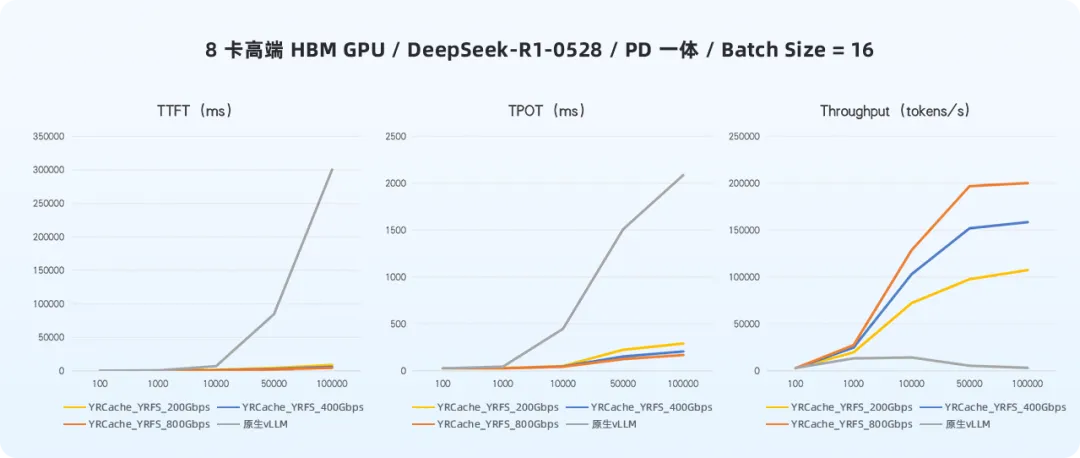
高端HBM GPU环境下的表现:
在同等负载条件下,高端HBM GPU环境同样受益显著。
| 网络配置 |
TTFT 降低 |
TPOT 降低 |
Token 吞吐量提升 |
| 200Gbps |
78% |
89% |
4 倍 |
| 400Gbps |
87% |
90% |
6 倍 |
| 800Gbps |
91% |
90% |
8 倍 |
不同网络带宽下,YRCache在高端HBM GPU上的性能提升
长上下文场景的稳定增益:
在模拟不同上下文长度的测试中,随着输入序列从100 tokens增长到100K tokens,YRCache实现了全程稳定的性能提升,且增益随着上下文增长呈放大趋势。这意味着企业在部署长文档分析、代码生成、多轮对话等重负载任务时,无需担心性能出现断崖式下跌。
2. 跨越硬件代差,实现革命性成本优化
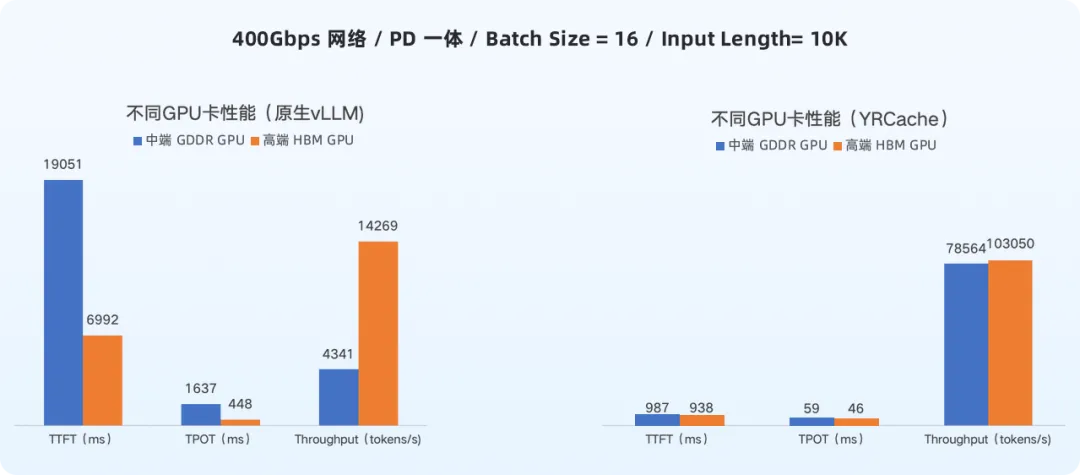
如果说性能提升是预期之内,那么YRCache能够缩小甚至弥合不同档次GPU之间的性能鸿沟,则为企业带来了更具战略意义的成本优化价值。
测试结果显示:在YRCache的加持下,配置较低的中端GDDR GPU服务器,其综合推理性能指标大幅逼近高端HBM GPU服务器。
性能差距对比(以400Gbps网络为例):
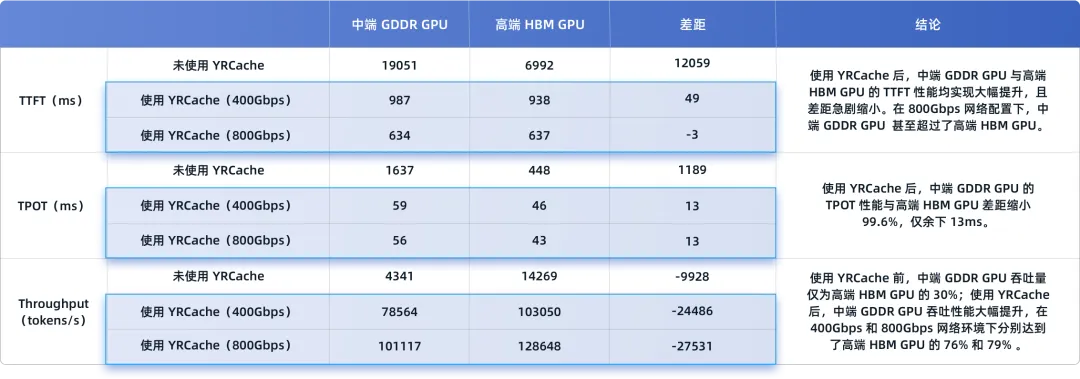
投资回报率(ROI)的爆发式增长:
硬件采购成本与实际产出吞吐量是衡量ROI的关键。测试数据清晰地揭示了YRCache带来的成本效益优化。
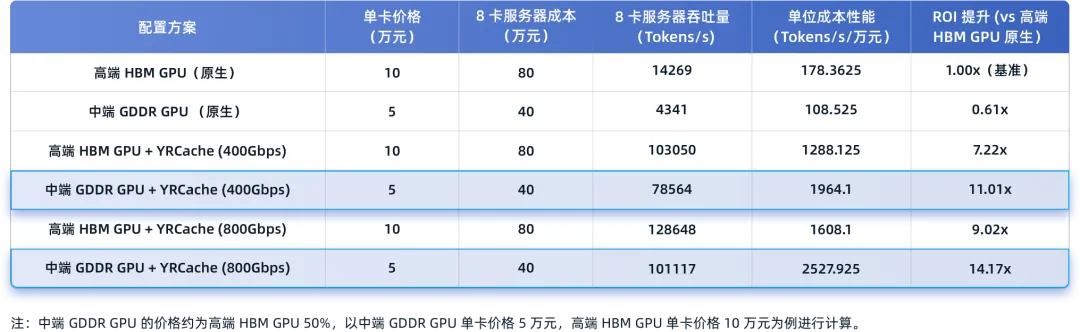
从上表可以看出,虽然在原生状态下中端GDDR GPU的推理表现不占优,但引入YRCache后,其ROI呈现出爆发式增长。在800Gbps网络环境下,“中端GDDR GPU + YRCache”方案的ROI达到了“高端HBM GPU原生”方案的14.17倍。
这意味着,投入相同的资金,采用优化方案能带来远超顶级硬件原生方案的产出效率。这对于企业而言,是AI成本结构的根本性重构:
- 选择更灵活:不必盲目追求最昂贵的GPU,通过部署YRCache,现有或性价比更高的硬件也能释放卓越性能。
- 总拥有成本(TCO)优化:在规模化部署时,TCO可实现显著降低。
- 降低门槛:使中小企业也能以更低的初始投入,构建高性能的AI推理服务。
对于正处于商业化关键期的AI企业而言,这不仅是性能和成本的优化,更是商业模式的拓展——当推理成本从“高端硬件依赖”转向“存储架构创新”,更多AI应用场景将具备经济可行性。
总结与展望
此次参与ODCC AI存储实验室首批KVCache场景测试,不仅有力印证了焱融YRCache的技术实力,也为整个AI推理行业指明了一条“通过存储驱动性能、通过架构优化成本”的全新路径。
除了面向大规模推理的YRCache,焱融科技目前已围绕AI全流程数据需求,构建了覆盖数据采集、模型训练、推理加速与数据治理的完整产品体系,为企业的人工智能规模化落地提供全栈支撑。
未来,随着模型复杂度和上下文长度的持续增长,高效的数据与缓存管理将变得愈发关键。类似YRCache这样的存储技术创新,将继续在提升算力利用率、降低推理成本方面扮演核心角色。对于关注智能 & 数据 & 云前沿技术的开发者与架构师而言,深入理解存储与计算的协同优化,将是构建下一代高效AI基础设施的必修课。欢迎在云栈社区继续探讨相关技术实践与架构选型。
 发表于 2026-3-11 00:48:46
|
查看: 212|
回复: 0
发表于 2026-3-11 00:48:46
|
查看: 212|
回复: 0
