词元(Token)调用量的指数级增长,正在催生一批公司估值的飙升。
被称作“Token第一股”的迅策科技,上市仅108天,股价较发行价上涨近6倍,总市值已经冲至1050亿港元。今年1月登陆港股的智谱,上市首日市值约580亿港元,交出首份年报后股价迅速突破1000港元大关,市值也冲破4000亿港元。智谱CEO张鹏将2026年的关键词直接定义为“Token量”,认为智能上界突破与Token消耗的指数级增长,共同构成了AGI时代的商业价值。
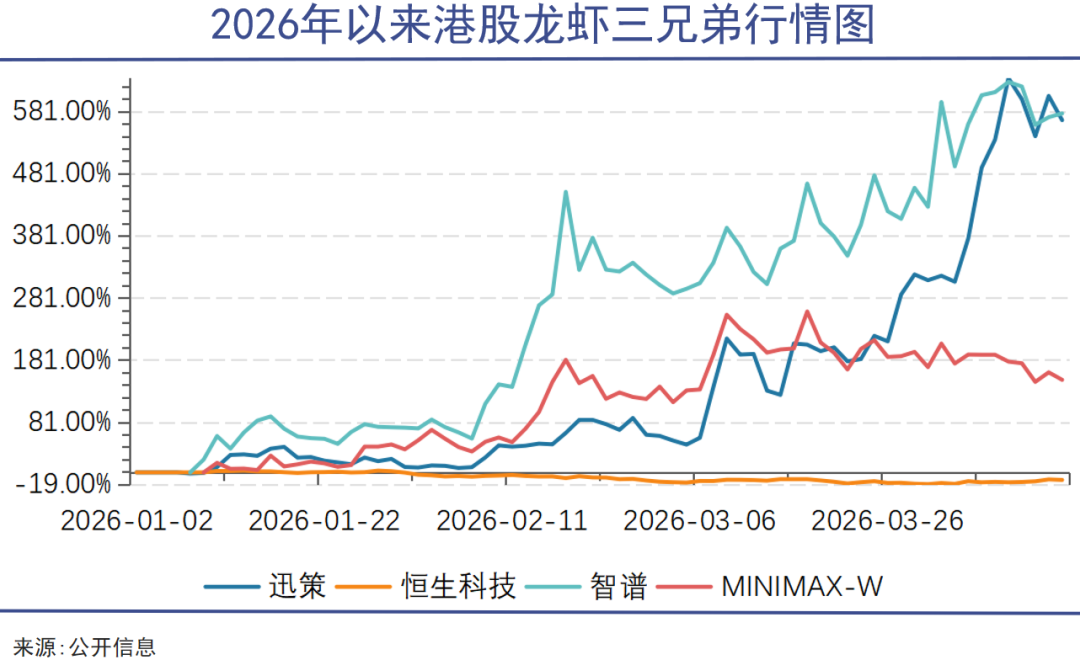
尚未上市的玩家也在刷新估值纪录。月之暗面上个月刚完成新一轮超10亿美金融资,估值达到180亿美元,而去年底的一轮5亿美元融资中,其估值仅为43亿美元。这种估值的短时间跃迁,与今年2月OpenClaw宣布将Kimi K2.5设为其官方主力模型直接相关——K2.5发布仅一个月,月之暗面ARR(年度经常性收入)即突破1亿美元。业绩增速不仅支撑了估值,也打开了公司IPO的可能性。
无论国内国外,资本市场都在以惊人的热情为Token经济的腾飞定价。这场轰轰烈烈的繁荣,正以“大跃进”的方式完成对所有人的认知普及,同时也累积着风险。
增长
聊天Bot刚问世时,很少有人想到,两年之后仅豆包一款大模型的日均Token使用量就能突破120万亿。即便按每百万Token两块钱的便宜价格计算,每天仍有3亿元的成本在豆包上空燃烧。
国内外各家大模型公司都在上演着相似的剧本——全球Token日均消耗量正以指数级规模增长。据工信部旗下中国信息通信研究院发布的数据,截至2026年3月,中国日均Token调用量已突破140万亿,较2024年初暴涨超过1000倍。
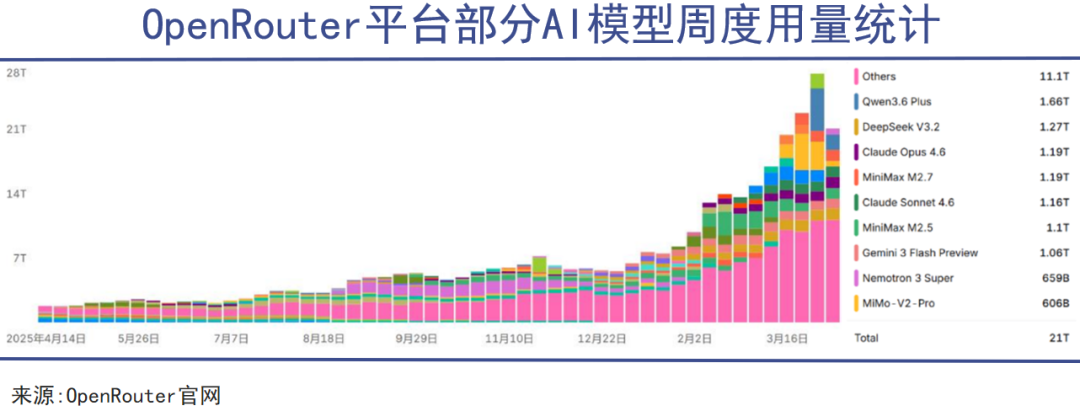
全球最大的AI模型API聚合平台OpenRouter的统计则显示,其平台每周处理的Token数量从2025年3月的1.62万亿飙升至2026年3月的16.90万亿,一年内增长超过10倍。OpenRouter连接着Anthropic、OpenAI、谷歌、Meta等几乎所有主流模型厂商的API接口,它的周度Token消耗曲线,本质上就是全球AI应用活跃度的实时监测图。
这条消耗曲线几乎是垂直向上的,既不像GDP的线性增长,也不像互联网用户渗透率的S型曲线,完全走出了人工智能经济自己的发展轨迹。
是什么在驱动Token需求的大爆发?答案是人工智能的技术演进。
早期AI应用以聊天机器人(Bot)为主,用户输入一句话,模型返回一段回答,一个来回消耗几百到几千Token。但从去年下半年开始,以 Agent 和Claw为代表的新型应用范式以更快的速度、更广的范围流行开来。它们的共同特征是让AI不再只是“一问一答”的对话工具,而是一个能够自主规划、调用工具、长周期执行任务的数字员工。这种技术架构底层的变化,让Token消耗量出现了远超很多人预期的暴涨。
行业内部测算表明,完成同一个业务目标,Agent模式消耗的Token大约是Bot模式的50到200倍。因为Agent在执行任务时需要将整个历史对话上下文全量携带,一个复杂任务动辄累积数十万Token的上下文窗口;每次思考都需经过多轮推理、触发API请求,并持续加载系统配置文件和记忆库以维持任务的一致性与个性化体验。这导致Agent模式下的Token消耗,更像是一个不受用户主观控制的黑箱操作。
更值得警惕的是,这个阶段Token表面的消耗量,并不等同于真实的需求量。当AI转型成为企业的政治正确,当Token消耗量被越来越多的公司纳入员工的考核指标,一种“Token伪需求”便诞生了。
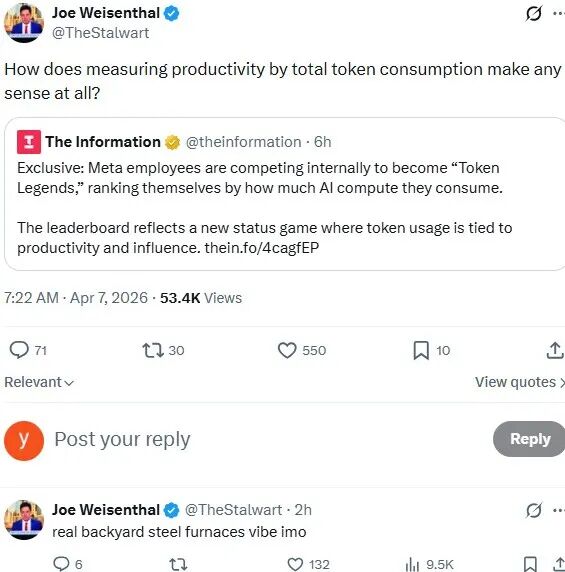
Meta内部已经有团队将Token消耗量作为AI渗透率的衡量标尺,部分员工为了“显得自己很懂AI”,会故意运行大量冗余的模型调用任务;国内腾讯等大厂也被爆料存在类似现象,一些业务线甚至发明了“Token刷量”的灰色操作。这种为了不被时代抛弃而制造多余消耗、夸大不存在的业绩的行为,充满了大跃进式的荒诞。
核心
当Token消耗量以指数级增长时,一个严肃的产业问题浮出水面——谁来买单,谁会受益?
4月15日,国家数据局就《关于推进行业高质量数据集建设行动的实施方案(征求意见稿)》公开征求意见,首次在官方政策文件中提出“探索词元交易等新型交易模式,构建以词元为基础,可量化、可定价的数据集价值体系”。
从“词元交易”被写入国家顶层设计的那一刻起,Token就不再仅仅是一个技术概念,而是会逐渐成为人工智能经济的法定计价单位。某种意义上来说,Token化收费是人工智能经济的核心。

迅策科技被称为“Token第一股”,就是因为其率先在商业模式上做出了调整,全面转向了按Token消耗付费与分成的新模式,构建了“收入=Token价格×调用次数×模块应用数”的增长模型。目前,Token付费收入占迅策科技总营收的5%左右,公司预计到年底这一比例将快速提升至20%至30%。市场对迅策的估值逻辑也因此发生了重大变化,脱离了传统市销率的限制,打开了更大的想象空间。
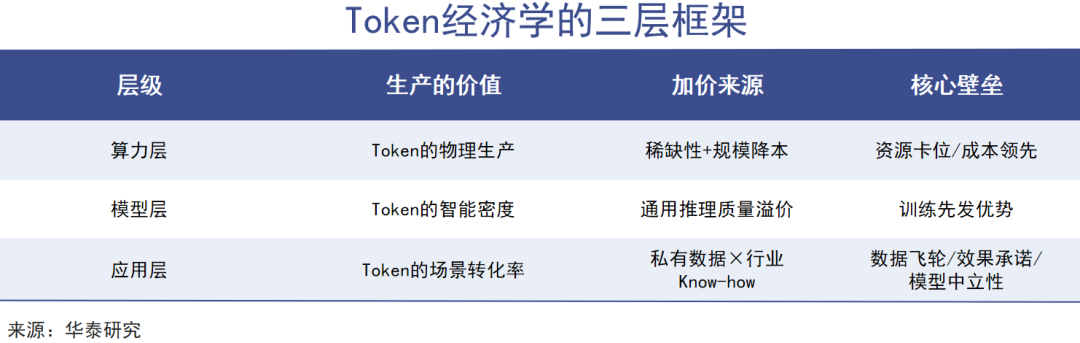
迅策科技的转变也揭示出,在人工智能经济中,大模型厂商大概率会扮演“精炼厂”的角色——将底层的算力与数据,加工成可以被直接消费、以Token计价的“成品”、“结果”,并掌握着价值分配体系中的关键生态位。
而云服务厂商则更像“发电厂”和“电网”,它们不直接定价Token,却决定了Token的底层成本。以阿里云为例,截至2026年2月底,阿里云2026财年累计外部商业化收入突破1000亿元,AI相关产品收入延续高增长态势,实现连续第十个季度三位数同比增长。紧随需求而来的就是涨价——上周阿里云四天连发三条产品涨价公告,调整百炼部分模型单元服务价格及DataWorks部分API免费额度。云服务厂商对Token成本的影响力,可见一斑。
在Agent时代,云服务厂商完全可以以Token使用量为基础计费,并通过Agent平台订阅、开发者生态套件、行业级解决方案等获得长期合同收入。而在更上游,算力厂商则像是原材料和燃料供应方。英伟达的高端GPU至今仍处于产业链最核心位置,高带宽内存(HBM)供应同样紧张,三星、SK海力士及美光三大存储原厂一边产能受限,一边抬升毛利率。
也许有人会担心算力实际已经过剩,英伟达和存储厂商的股价已经过高,但这都不影响Token化收费的历史进程。Token收费,让整条产业链的价值分配有了清晰的计算依据。就像千瓦时的确立让电力市场得以形成,流量/曝光量成为抖音和视频号的收费标准单位一样,Token正在让人工智能经济从“感觉有用”走向“可以算账、可以收税”,成为一种真实存在的经济构成。
狂欢
Token化收费让人工智能经济运转的逻辑变得清晰起来,但人工智能作为一种划时代的技术革命,其经济运转的逻辑,是否与传统的经济学规律一致呢?
至少传统经济学的供需平衡理论,在人工智能经济中并不完全适用。在传统模型中,供给和需求是两条独立的曲线相交;而在人工智能经济中,供给本身会通过数据飞轮改进供给质量,需求曲线向右移动不是因为外部收入变化,而是因为供给曲线本身向下、向右移动了。
当前阶段,我们更可能看到蒸汽时代的“杰文斯悖论”在人工智能时代重演。所谓杰文斯悖论是指,当蒸汽机效率提升、单位马力耗煤量下降时,煤炭的总消耗量反而暴增,因为更便宜的蒸汽动力催生了更多工厂、火车和轮船。现在,Token的单位生产成本越低,愿意消耗Token的群体就越多,舍得用Token而非人力去完成任务的场景就越多,最后Token的总成本就越高——或者说,人工智能经济的总价值就越大。
数据显示,过去两年多,Token生产成本下降了超过99%,GPT-4每百万Token的成本已经从37.5美元降至2025年的0.14美元。但根据硅谷风投Menlo Ventures的统计,全球企业2025年在AI上的支出反而比2024年增长了3.2倍。如果这种趋势延续下去,那么哪怕单位Token的价格趋近于零,全人类消耗的Token总价值(总量 × 单价)及其撬动的GDP比重,仍可能成百上千倍地增长。
这正是智谱、MiniMax等公司在巨额亏损的情况下,仍然被资本市场赋予超过许多传统互联网企业估值的深层原因——市场定价的不是今天的利润,而是未来Token经济的总价值。更何况,用Token生产出来的东西,本身也会越来越有价值。同一百万个Token,在不同场景下创造的价值差距可达十万倍——用于闲聊的Token只值几分钱,用于写代码的Token值几百几千元,用于量化投资、企业并购的Token完全可以价值几万元。斯坦福大学2026年AI指数报告估算,仅2024年生成式AI就为美国消费者创造了约1720亿美元的消费者剩余,用户获得的价值远超实际支付的费用。

值得警惕的是,在AI取代了大量人类的脑力劳动后,传统的劳动力供给理论也将面临挑战——传统的需求曲线会因购买力萎缩而整体坍塌,而供给端由于自动化依然强劲,这正是凯恩斯所说的“技术性失业导致的有效需求不足”。
只不过在这个阶段,围绕着Token消耗量指数级增长的一切都还披着繁荣的外衣,引领着产业链上下游和资本市场的狂欢。历史已经反复证明,每当一种新技术被资本市场赋予无限想象空间时,泡沫总是比价值更先抵达终点。
 发表于 2026-4-25 04:36:20
|
查看: 152|
回复: 0
发表于 2026-4-25 04:36:20
|
查看: 152|
回复: 0
