告别本地大模型环境配置地狱!DreamServer 现已实现一键部署
搞定一张显卡驱动,配好 CUDA 环境,把一个本地大语言模型跑起来——这往往只是折磨的开始。想给模型加上长期记忆?得去折腾向量数据库。想接入语音输入?又得额外挂一个语音识别容器。等你终于把各种代码勉强缝合,一个显存溢出报错就能让整套系统瞬间崩盘。
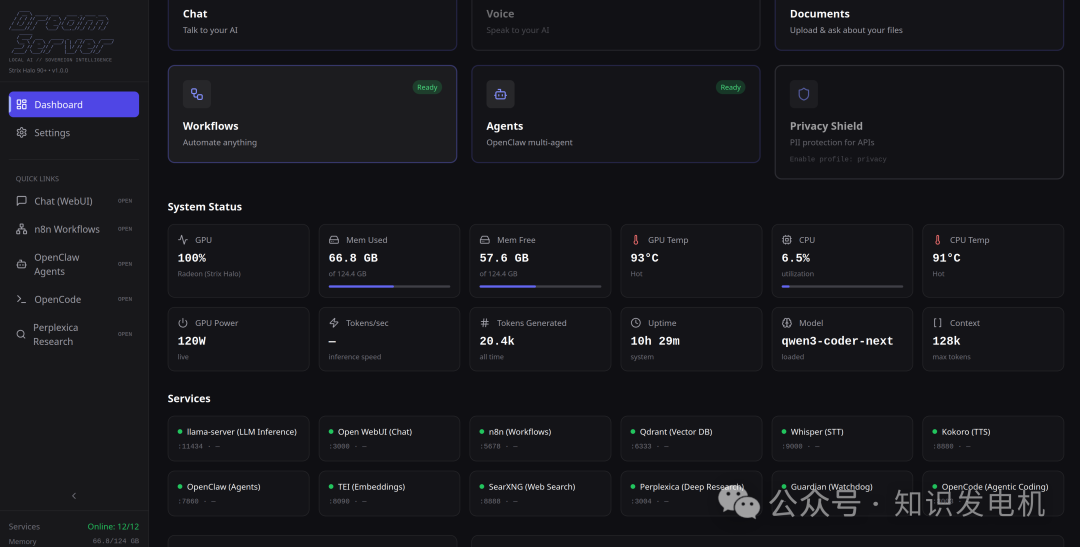
很多人以为搭建本地 AI 生态最大的门槛是算力不够。但实际上,最让人崩溃的是极其琐碎的环境依赖配置。现在,想在自己的硬件上跑通一个包含对话、语音、检索增强生成、AI 代理乃至画图的完整工作流,你根本不需要亲手编写任何配置文件。DreamServer 直接把这一整套逻辑打了包:它是一套完全运行在本地的 AI 基础设施环境,仅用一条命令,就能在你的设备上拉起来 13 个彼此联通的服务节点。
把业务数据一股脑发给第三方 API,无异于把底牌交到别人手里。从原则上来讲,任何核心数据的流转,都应该被限制在物理隔离的局域网内。当你自己掌握基础设施,数据的流转规则就由你定义,系统也不会在某天凌晨被官方一纸通知强制降级——这种掌控感,才是本地部署真正的价值所在。
没必要手动拼接十几个容器
每次系统重启或者升级某个组件,不同服务之间的网络端口和数据映射关系就极容易发生错乱。维护一套本地多模态 AI 架构的隐性成本,往往比写具体业务代码还要高昂。一旦某个节点依赖包的版本出现不兼容,整套工作流就会当场瘫痪。
打个比方,这就像你拿到了一堆散落的高铁车厢零件,得自己焊接底盘,自己拼装座椅,还得确保两节车厢对接时信号线能精准匹配。
DreamServer 采用的是一套预置好网络拓扑与通信协议的容器编排方案。它在后台静默处理了模型推理后端、对话交互前端、工作流调度器等 13 个服务的依赖关系。当你执行启动指令时,系统会绕过人工干预,直接在内存中建立起各组件的直连通道。假如推理过程中某个服务节点意外崩溃,它内置的健康检查机制就会自动尝试重新拉起对应进程。为了保证各个组件能够无摩擦地交换数据,DreamServer 在底层架构里预先锁定了所有 API 的通信鉴权方式与端口映射规则,这让跨容器的数据调用变得异常稳定——直接避开了冲突。
你自己组装的时候,经常遇到 PyTorch 的 CUDA 版本与系统驱动不匹配,导致容器根本起不来,而其他类似的环境冲突错误更是层出不穷。DreamServer 直接把经过验证的底层镜像打包好了,这就隔离了风险。省时省力,干净利落。
顺便提一句,之前我扫了一眼代码仓库,发现他们在八天时间里提交了三千多次代码。说实话,这个迭代速度相当消耗体力。
硬件环境的脏活它替你干了
过去要在 Windows、macOS 和 Linux 不同平台上分配显卡资源,你需要针对性地编写三套完全不同的显存管理逻辑。而 DreamServer 内置了硬件侦测探针,能在启动瞬间自动识别宿主机的 GPU 架构。对于 Windows 设备,它直接调用 Docker Desktop 的 WSL2 后端进行显卡直通;如果是苹果的 M 系列芯片,则会原生调用 Metal 接口来做硬件加速计算。一旦安装器介入,它便会自动识别可用的加速硬件,下载对应的基础模型文件,同时将所有依赖项写入临时缓存目录——全程无需人工干预。 更令人意外的是,它还能在 深度学习 框架层面自动匹配最佳配置。
我以前一直以为,在 Windows 环境下跑多容器 AI 应用,必然得手动挂载冗长的 NVIDIA 驱动路径和环境变量。直到上周在老设备上测试这个项目时,我才发现自己想错了:它的安装器在硬件检测阶段,就已经自动生成了适配当前设备的编排配置文件。
你不再需要自己去查阅官方支持矩阵。底层框架把算力分配的细节隐藏了起来,而你直接拿到的,就是一个暴露在本地特定端口的可用服务接口。
这种感觉类似于微信支付。你在便利店扫码的时候,根本不用关心理赔资金是通过哪家银行的网关结算,或者调用了哪个清算系统。
不过,在处理 WSL2 动态内存分配时,如果物理内存不够大,系统很容易出现极其隐蔽的显存溢出报错。不知道有没有其他人在跑大模型时,也踩过这个内存限制的坑?
扩展功能就像插 U 盘一样
业务需求总是会随着时间不断膨胀。今天你可能只需要一个简单的问答模型,明天你就会想接入公司内部的知识库,后天可能又需要用工作流工具处理定时任务。传统做法是强行往现有代码库里塞新接口,最终把整个系统变成一团乱麻。
而在它的架构里,任何独立的服务都被定义为扩展模块。你只需要准备一个单独的文件夹,里面放上规定格式的 manifest.yaml 配置声明和 compose.yaml 编排文件。命令行工具在执行扫描动作时,会自动捕捉到这些新加入的配置文件,将它们动态挂载到现有的运行环境中。只要把扩展文件夹丢进指定目录,再敲一行启用命令,网关服务就会在极短时间内刷新路由表,把新的功能端点暴露给前端应用。模块即插即用。
现在添加新功能,逻辑就像快递包裹分拣单号:只要你在包裹上贴一张符合标准格式的面单,传送带就会自动把它送进对应的分发轨道。
它默认提供了一种引导模式,能在几分钟内迅速拉起一个基础模型供你测试连通性——不对,确切地说,是在后台满负荷下载完整模型文件的同时,前台先用一个小体积的临时模型让你进行验证操作。那些由社区打包好的图像生成引擎或者语音克隆工具,都可以用这种方式直接挂载到主程序上。无论是在本地运行 AI Agent 、构建私有的 RAG 知识库,这些扩展都能轻松嵌入。
系统底层重构了核心调度逻辑,理论上能在极低内存占用的情况下维持多个代理进程的常驻运行。但如果并发请求数量突然激增,稳定性是否还能撑住,恐怕还得留个问号。
如何用一行命令把系统拉起来
在开始部署之前,确保你的设备上已经安装并启动了 Docker 环境。
- 获取最新的引导脚本
为了避开复杂的版本检查,官方提供了一个聚合式的下载执行指令,它会自动拉取最新的配置清单。
# 从远程仓库静默下载v2版本安装脚本并通过管道直接丢给Bash执行
curl -fsSL https://raw.githubusercontent.com/Light-Heart-Labs/DreamServer/v2 | bash
执行完毕后,终端界面会开始滚动显示硬件侦测的反馈日志。
- 启用特定的业务模块
当你需要加载非默认启动的组件时,直接调用它的内置扩展管理命令。
# 扫描本地扩展目录,找到名称匹配的组件文件夹进行挂载激活
dream enable <EXTENSION_NAME>
挂载过程容易因为网络波动导致镜像拉取中断,保持网络稳定很重要。
- 清理并重建环境
有时候配置文件被意外改乱了,需要彻底重置整个系统状态。
⚠️ 注意:
# 强制停止所有关联的容器进程,同时销毁对应的挂载数据卷
dream down --volumes
跑完这条命令,所有之前积累的对话历史和本地知识库索引都会被彻底清空。
搭建本地 AI 环境的核心逻辑,不再是去死磕各种晦涩难懂的驱动文档。DreamServer 提供了一条直接可用的物理链路,把你从无止境的报错日志里拽了出来,并把控制权重新交回到你自己的硬件设备上。
对于普通人来说,这意味着即使完全不懂代码,也能在自己的电脑里养一个数据完全隔离的数字助手;而对于开发者而言,你可以直接在这个稳定底座上编写核心业务逻辑,少熬几个修环境配置的通宵。说实话,这种把复杂留给工具、把简单留给用户的思路,才是真正让人感到解放的地方。
如果你也想在本地快速构建一个属于自己的、数据不外传的完整 AI 工作流,不妨到 云栈社区 和更多开发者一起交流实战经验,看看大家是怎么把这一整套“全家桶”玩出花样的。
 发表于 2026-4-25 04:04:08
|
查看: 209|
回复: 0
发表于 2026-4-25 04:04:08
|
查看: 209|
回复: 0
