
在当下,持续投入精力认真打造开源模型的团队已不多见。通义千问团队在这方面的努力显得尤为突出,其开源节奏连贯且充满力量。
随着Qwen3-TTS的正式发布,不禁让人思考,像Elevenlabs这样的闭源商业服务是否会感到压力?当开源模型的效果与闭源产品不相上下时,用户还会倾向于选择价格高昂的服务吗?
与其罗列枯燥的数据,不如让结果说话。官方宣称其在多个维度达到了SOTA(当前最优)水平,下面的性能对比图足以说明其强大实力。但更重要的是,我们需要直观地感受其生成效果。
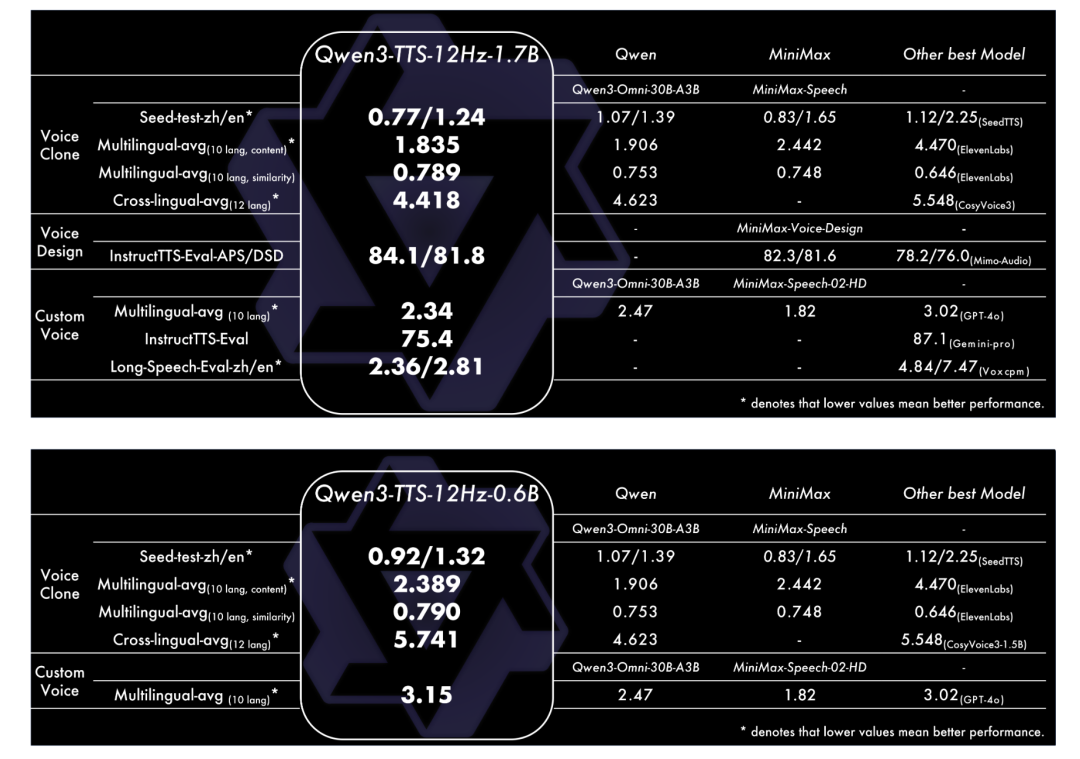
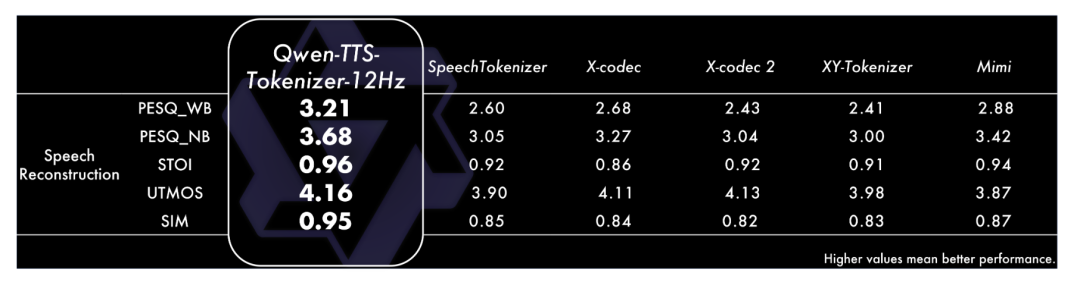
项目简介
Qwen3-TTS是由通义千问团队开发的一套全栈式、高性能语音生成模型系列。
核心功能
- 全能生成:全面支持音色克隆、音色创造、超高质量拟人化语音生成。
- 自然语言控制:支持通过自然语言描述来控制语音的语气、情感和节奏。
- 智能理解:具备强大的上下文理解能力,能根据文本语义自适应调整表达,且对文本噪声有很强的鲁棒性。
模型规格与支持
- 多尺寸开源:提供1.7B和0.6B两个参数量级的系列模型,均完全开源。
- 多语言覆盖:支持10种主流语言(中、英、日、韩、德、法、俄、葡、西、意)及多种方言。
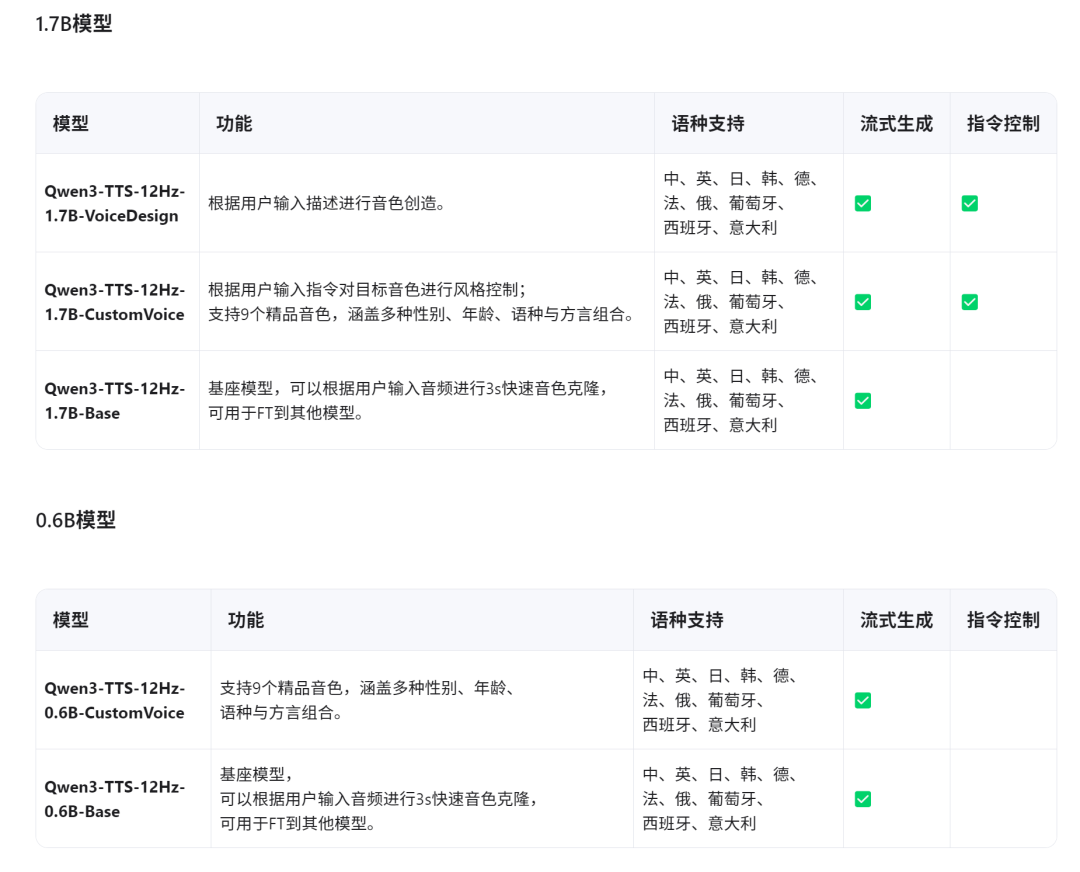
效果演示
实践是检验真理的唯一标准。亲眼所见(亲耳所闻)其效果,你便会明白,开源模型在TTS领域已经取得了突破性的进展。
由于展示渠道限制,音频样例数量有限,因此我们挑选了最具代表性的功能进行展示。
音色创造
声学属性控制
- 指令控制:采用高亢的男性嗓音,语调随兴奋情绪不断上扬,以快速而充满活力的节奏传达信息。音量要足够响亮,近乎喊叫,以体现紧迫感。发音务必清晰精准、字字分明,让每个词都铿锵有力。整体表达需流畅自然、明亮生动,富有戏剧性,展现出外向、自信且张扬的个性,同时传递出一种威严而宏大的宣告语气,洋溢着满溢的激动之情。
- 合成文本:好了各位,往后退,往后退!我有个天大的好消息要宣布:Qwen-TTS正式开源啦!
年龄控制
- 指令控制:体现撒娇稚嫩的萝莉女声,音调偏高且起伏明显,营造出黏人、做作又刻意卖萌的听觉效果。
- 合成文本:哥哥,你回来啦,人家等了你好久好久了,要抱抱!
渐变控制
- 指令控制:

- 合成文本:你在干什么?有什么好看的?喂!我叫你走,你在干什么?给我走啊!
音色复用
用户可以将Qwen3-TTS创建的音色进行持久化存储和重复调用,从而生成生动自然的多轮次、多角色长篇章对话。这一特性使其在配音、广播剧制作等场景下极具潜力。

音色克隆
此处仅展示中文语音的克隆能力,其对其他语言及跨语种克隆的支持,有兴趣的读者可以自行探索。
- 原音频:(此处原为音频,文本描述略)
- 克隆音频
- 合成文本:祝您在马年里事业一马当先,业绩万马奔腾,在新的一年里快马加鞭,再创辉煌!
许多方向的人工智能模型性能都存在物理极限,达到一定程度后便会遭遇瓶颈。但我坚信,未来将有更多优秀的开源实战项目能够追平甚至超越闭源方案。
技术特点
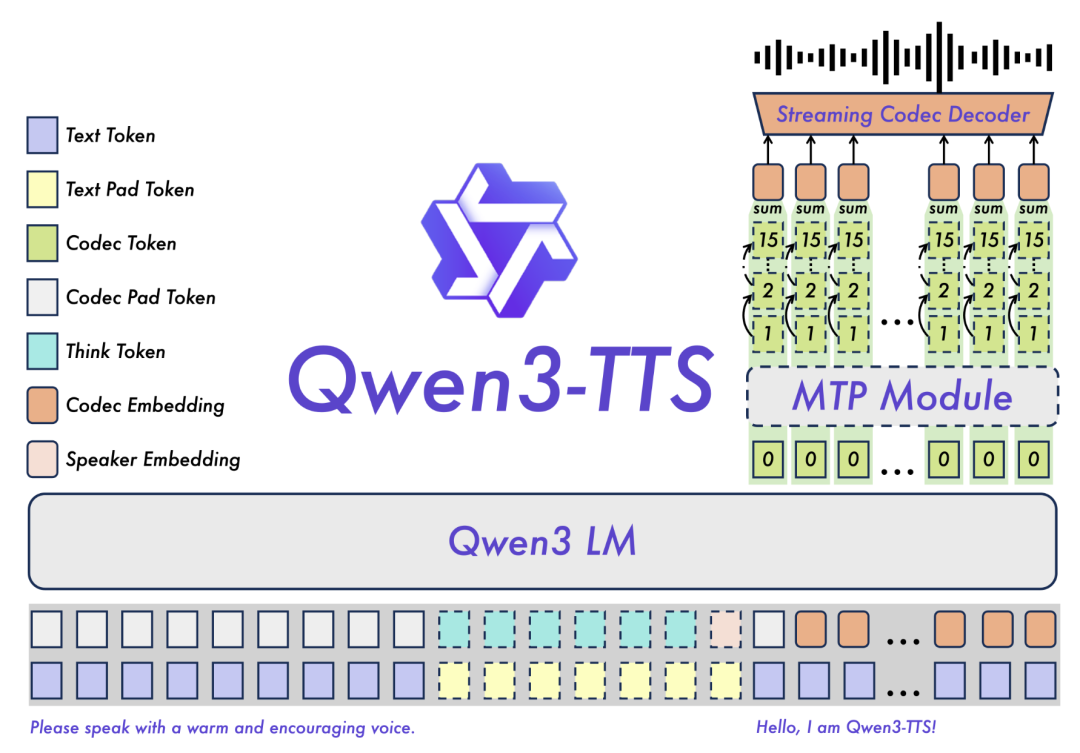
- 还原度高:自研的编码器能在高压缩率下完整保留语气、呼吸声甚至环境音,实现高保真语音的原汁原味还原。
- 架构统一:采用通用的端到端架构,摒弃了传统方案中多个模型拼凑的方式,避免了误差累积,在生成效率和质量上限方面都有显著提升。
- 实时对话:独创的双轨流式架构,使得模型在接收到第一个文本token时即可开始生成语音,延迟低至97ms,完全满足实时语音交互的需求。
- 听得懂指令:支持用通俗的自然语言指令控制语气和情感,模型同时具备对文本语义的理解能力,可自动调整表达节奏,真正实现“所想即所听”。
项目链接
开源链接:https://github.com/QwenLM/Qwen3-TTS
官方博客:https://qwen.ai/blog?id=qwen3tts-0115
在线试用:https://huggingface.co/spaces/Qwen/Qwen3-TTS
技术的发展离不开社区的交流与共享。如果你想了解更多关于智能 & 数据 & 云领域的前沿动态,或与其他开发者探讨技术实践,欢迎访问云栈社区进行深入交流。 |  发表于 2026-1-26 10:29:40
|
查看: 281|
回复: 0
发表于 2026-1-26 10:29:40
|
查看: 281|
回复: 0
