注:本文源自一次真实的线上事故与性能优化经验。
那是一个凌晨四点,财务部发来的Slack消息很简单,只有一行字:四万美元。
这不是问我,是通知我——上个月的AWS账单长得像个电话号码。我打开监控面板,看到64个vCPU核心利用率全部飚到100%,丢包率超过25%。那一刻,我甚至还天真地想过:“是不是该换个更大的实例?”
我们运营的是一个实时竞价平台,数据包极小(平均50字节),但流量巨大,每秒数百万个,延迟必须控制在毫秒级。这种数字写在PPT里很漂亮,但当它们真的在网线上奔涌时,又是另一番景象了。
有个残酷的事实,没人会提前告诉你:当每秒数据包数(PPS)突破200万,传统的 Linux内核网络栈 会直接“躺平”。这不是优雅降级,而是像溺水的人一样,徒劳地挣扎。
这就是C10M问题。如果说C10K是处理一万个并发连接,那C10M直接把零加了一位——千万级数据包。这个概念早在2012年就被提出,但直到今天,默认的 Linux内核 设计仍然难以胜任。

C10M问题:当每秒数据包突破200万时,Linux网络栈就达到了设计瓶颈
Linux网络栈的“门房困境”
Linux内核的网络栈已经兢兢业业服务了几十年。对于绝大多数应用,它都工作得很好。但当你真的把流量“顶”上去时,它的瓶颈就开始暴露无遗。
这套架构诞生于90年代或21世纪初,那时每秒处理10万个数据包已经是极限。每个数据包都被当作VIP贵宾来招待:有自己专属的中断、独立的内存拷贝,还要在netfilter的“检查站”走上一圈。
想象一下这样的流程:数据包抵达网卡,门铃(中断)响了。CPU必须放下手头所有工作,切换到内核模式,将数据从网卡缓冲区拷贝出来,然后让它穿越复杂的iptables规则迷宫,再推入TCP/IP协议栈,最后还要再拷贝一次到用户空间的应用缓冲区。每个数据包都要完整地走完这套流程。
当数据包速率达到每秒100万时,CPU绝大部分时间都花在“应门”上了,根本没空处理“邮件”(数据包内容)本身。一次上下文切换就要消耗1500到3000个CPU周期。当速率冲击200万PPS时,你还没看清数据是啥,CPU的预算就已经耗光了。这就是为什么应对C10M需要完全不同的思路。
我们当时的配置里有50条iptables规则,包括连接跟踪和一些基础检查。在低速时毫无感觉,一旦上量,它们就成了沉重的铅块。每个包都要接受这上亿次的规则检查。此时,你运行的不是一个数据处理程序,而是世界上最昂贵的电话交换机。
第一次遭遇流量高峰时,我盯着htop,感觉就像看着汽车的发动机在空挡状态下疯狂拉高转速。所有核心满载,但我们的应用线程只能抢到大约5%的CPU时间。剩下95%全被内核占用,用来争论“下一个数据包该轮到哪个CPU核心来处理”。
DPDK:让操作系统“靠边站”
第一次听说DPDK(Data Plane Development Kit,数据平面开发套件)这种“内核旁路”技术时,我觉得很扯。它的核心思想是告诉操作系统:“谢谢,但不用您插手了”,然后直接把网卡的DMA内存映射到你的用户态应用程序里。
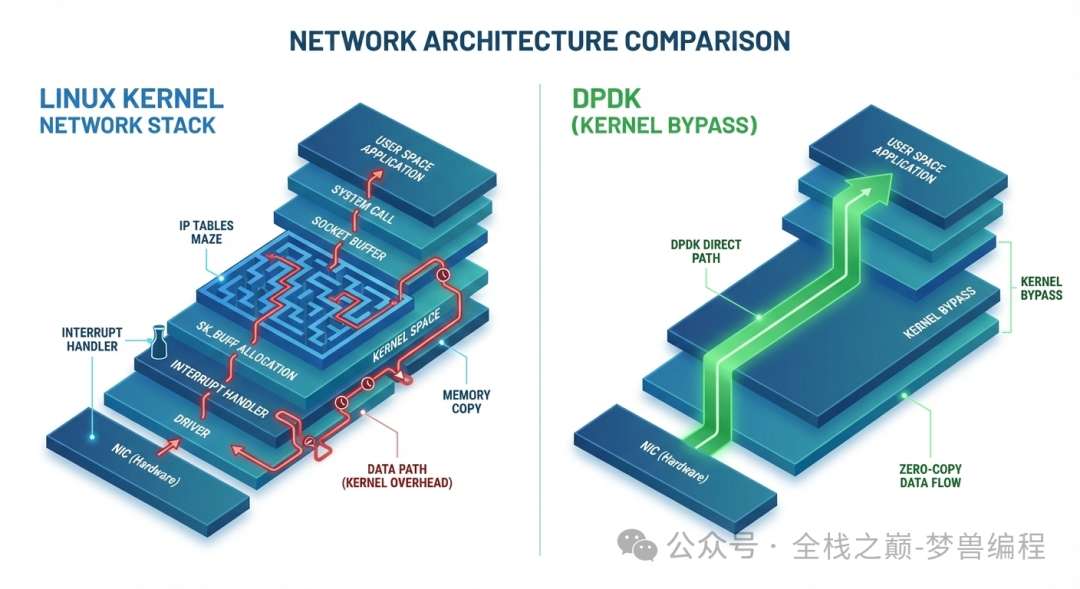
架构对比:左边是传统的多层Linux网络栈,右边是DPDK的零拷贝直接路径
这就像是让快递包裹直接送到你家门口,而不是先经过邮局分拣三次、盖章、登记。数据包一抵达就直接落入你指定的内存区域,你的代码可以直接读取。没有中间商赚差价。
DPDK不是一个简单的库,它更像是一份给操作系统的“逐客令”。它揭示了内核的网络协议栈从来都只是一个“可选项”。然而,代价也随之而来:你失去了所有的“护栏”。没有现成的TCP协议栈,没有socket() API,没有netstat,没有tcpdump,所有你熟悉的安全网和调试工具瞬间失效。网卡从操作系统的视角里“消失”了。
搭建DPDK环境不像是在写代码,更像是在黑屋子里拆炸弹。你必须在系统启动、内核染指之前,就预先划分好“大页内存”:
// 破釜沉舟 - 重启前内核别想拿回这块网卡
// 一次性核选项:./dpdk-devbind.py --bind=vfio-pci eth1
struct rte_eth_conf port_conf = {
.rxmode = {
.mq_mode = RTE_ETH_MQ_RX_RSS, // 要么RSS要么死:把负载分摊到各个核心上
},
};
// 这儿就是你从操作系统手里抢硬件的地方
rte_eth_dev_configure(port_id, nb_rx_queues, nb_tx_queues, &port_conf);
// 预先煮好一池子数据包缓冲区(以前内核还得帮你盯着这个)
struct rte_mempool *mbuf_pool = rte_pktmbuf_pool_create(
"MBUF_POOL",
8192, // 太少了负载一上来就得饿死
250, // 每核心缓存实现无锁性能
0, // 私有数据大小 - 通常就是零
RTE_MBUF_DEFAULT_BUF_SIZE, // 2KB一块
rte_socket_id() // 绑到本地NUMA或者准备好交延迟税
);
运行完这些,你的网卡就真的不见了。执行ip link show也看不到它。现在它完全归你的进程管理,内核只能一脸茫然地站在原地。
将操作系统“踢开”后,实际的数据处理循环简单得令人难以置信:
while (1) {
struct rte_mbuf *bufs[32]; // 批处理就是一切 - 缓存局部性
// 直接轮询硬件 - 不等待,不系统调用
uint16_t nb_rx = rte_eth_rx_burst(port_id, queue_id, bufs, 32);
// 这轮出现的任何东西现在都是你的了
for (int i = 0; i < nb_rx; i++) {
// 你的数据包逻辑 - 解析、路由、响应
// 全用户空间内存,从网卡零拷贝
process_packet(bufs[i]);
}
// 把缓冲区还回去,不然你就泄露了然后死掉
rte_pktmbuf_free_bulk(bufs, nb_rx);
}
结果有些讽刺:现在只需要8个核心,在40%的负载下“打着哈欠”,就能完成以前64个核心满载都干不完的活儿。相同的流量模式,相同的数据包数量。我一度怀疑是不是我们引入了什么Bug导致静默丢包。但事实证明,这只是效率终于回归了正常。
XDP:在“门口”进行精确拦截
如果说DPDK是“核选项”,那么XDP(eXpress Data Path)就是“精确打击”。你仍然身处内核的地盘,但你在“门廊”工作,在数据包“敲门”(进入完整网络栈)之前,通过“猫眼”快速检查其身份。
你的eBPF程序运行在网络驱动层,在数据包触及任何昂贵的网络栈处理之前就将其拦截。
// 运行在内核空间但在驱动层 - 在所有东西之前
SEC("xdp")
int xdp_drop_garbage(struct xdp_md *ctx) {
void *data = (void *)(long)ctx->data; // 数据包开始
void *data_end = (void *)(long)ctx->data_end; // 边界
struct ethhdr *eth = data;
// eBPF验证器很偏执 - 边界检查否则程序被拒绝
if ((void *)(eth + 1) > data_end)
return XDP_DROP; // 格式错了,在门口干掉
// 任何不是IPv4的东西都死在这儿,内核永远看不到
if (eth->h_proto != htons(ETH_P_IP))
return XDP_DROP;
return XDP_PASS; // 让正常流量通过到正常处理
}
我们现在就用这个做DDoS防护。上个月我们遭遇了一次攻击,峰值达到每秒500万个垃圾数据包。部署了XDP程序后,其中超过480万个包在“车道”里就被直接丢弃,它们连内核的“门”都没敲着。内核根本没感知到它们的存在,CPU使用率几乎没动。剩下的20万个正常数据包则像什么都没发生一样,得到了常规处理。
但XDP的“好日子”在你需要追踪连接状态时就到头了。eBPF验证器会变得异常“挑剔”:不允许无界循环,不允许不确定的指针访问。如果它认为你的代码有丝毫可能让内核崩溃,程序就会被拒绝。对于简单的包过滤,XDP是完美的。但对于有状态处理或复杂协议解析?抱歉,你可能还是得回到DPDK的怀抱。
高昂的“入场费”
选择内核旁路技术的代价,就是一笔高昂的“入场费”:你几乎撕毁了整个运维剧本。所有基于内核的传统监控?失效了。依赖内核插件的安全工具?没用了。你花了数年建立的调试肌肉记忆?完全用不上。
需要抓包分析?tcpdump什么都看不见,你必须从零开始编写自定义工具。想要连接统计?最好把这功能内建到你的应用里。防火墙规则?现在这完全是你的责任了——所有安全逻辑都在你的代码里,而当它出错时,你再也无法责怪内核。
调试过程变成了一场心理战。我们曾花三个星期追踪一个内存泄露。三个星期里,团队成员盯着十六进制内存转储,看到眼睛发酸。标准工具根本“看”不到DPDK管理的内存池。gdb可以附加进程,但显示的是乱码。valgrind完全“瞎了”。最后我们被迫在代码里加入自定义的统计信息转储,每10秒输出一次,然后手动将其与网卡硬件计数器关联起来,感觉就像回到了1985年用汇编语言调试程序。
部署也成了大问题。有一次生产环境发布失败,原因是一位同事(姑且称他为Dave吧,因为我现在还有点生气)在内核更新后,忘记将网卡重新绑定到vfio-pci驱动。Dave以为自动化脚本会处理这件事,但脚本没有。应用启动得很“顺利”,只是发现零个可用的DPDK网卡,于是它选择静默地待着。没有错误日志。进程运行中。健康检查通过。监控仪表板上的曲线平坦得像一条直线。我们没有“失败”,我们只是……“不存在”了。Dave花了45分钟查看应用日志,而那几块网卡就在角落里,被整个世界无视。
基准测试:当理论照进现实
我们将两台配置完全相同的服务器并排放置——都搭载了双路至强6138 CPU和Intel X710网卡——然后向它们抛洒相同的UDP洪流,看谁先崩溃。
我们为运行标准Linux内核的那台服务器用上了所有“最佳实践”:将IRQ中断绑定到特定核心、将环形缓冲区调到极大、像救命稻草一样配置RPS和RFS。结果呢?32个核心拼尽全力,也只能勉强维持每秒180万数据包的处理,并且丢包率高达18%。服务器的风扇听起来像停机坪上的喷气引擎,声音越响,我们丢的包越多。

性能测试结果:内核网络在180万PPS时已不堪重负,而DPDK轻松达到920万PPS
而运行DPDK的另一台服务器呢?同样的负载下,它能持续处理每秒920万数据包。仅用了12个核心,负载约60%。丢包率低于0.001%,并且那点丢包大多还是我们用户态逻辑里的Bug导致的,并非框架本身的问题。
内核网络在低速巡航时表现优异。但一旦你跨过每秒100万数据包的门槛,系统就开始“步履蹒跚”。到了200万PPS,车轮就彻底脱落了,你付给云服务商的钱,只是在看CPU如何在内核的上下文切换中把自己“累死”。
最后的警告:失效的“隔离”
你知道比内核网络在200万PPS时“窒息”更糟糕的是什么吗?是你的DPDK应用在1000万PPS时发生了缓冲区泄露。在这种速率下,你可以在三秒内耗尽网卡的所有缓冲区。我们曾因一个缓冲区回收的“差一错误”,在流量高峰期间导致服务完全崩溃。那个月的SLA图表上满是参差不齐的下降缺口,像被锯子锯过一样。恢复服务意味着完全重启,这会带来5秒钟的完全数据丢失,同时CFO在Slack私信里的用词也会越来越有“创意”。
此外,找到能真正维护这套系统的人才比登天还难。我曾问过一位分布式系统专家——他能聊几小时Paxos算法——如何处理无锁环形缓冲区造成的缓存缺失。他看着我的眼神,就像我在说火星语。他根本不知道什么是TLB缺失。我们面试过能背诵RFC的网络工程师,但他们离开图形化界面就不会调试内存泄露。这两类人才技能的交集微乎其微。
而且问题会不断叠加。每次内核升级都意味着要重新测试大页内存配置。每次网卡固件更新都是一颗潜在的地雷。我们甚至为此维护了一个独立的、专门用于包处理测试的预发布环境,因为它的故障模式太过诡异,常规的质量保证流程根本抓不住。
但说真的,如果你的生产环境真的需要处理每秒超过500万个数据包,你其实别无选择。Linux内核会成为瓶颈。这不是因为它设计得糟糕——事实上,它对99.9%的用例都极其出色——而是因为“CPU速度永远比网络快”这个底层假设已经死亡。这个假设大约在2015年前后就瓦解了,而我们都生活在其后果之中。
所以,不要因为它“很酷”就去尝试内核旁路技术。只有当你在处理高并发、海量数据包的场景下,并且已经尝试了所有其他优化手段却依然无果时,才应该考虑它。它确实管用,但它也足够“糟糕”,我因为它失眠的时间,比因为任何其他架构决策而失眠的时间总和还要多。
总结与建议
Linux内核网络就像一个过度热情的门房。在低速时,它的服务无微不至。但到了每秒百万级数据包的场景,它就只顾着反复“应门”,根本没时间处理真正的“邮件”。
给几条务实的建议:
- 每秒低于100万数据包? 别折腾,标准的Linux内核网络栈完全够用。
- 每秒100万到200万之间? 优先优化中断绑定、缓冲区大小、RSS(接收端缩放),内核方案还能再撑一撑。
- 每秒超过200万? 认真考虑DPDK或XDP,但要做好心理准备,你的整个运维和调试工具链需要推倒重来。
- 技术选型上:DPDK是“核选项”,XDP是“精确打击”,根据你的需求(完全控制 vs. 简单过滤)来选择。
- 最重要的一条: 维护这类系统极具挑战,找到合适的人才比解决技术问题本身可能更难。
无论你是尚未遇到性能瓶颈,正在百万级边缘挣扎,还是已经踩过DPDK/XDP的“坑”,这些经验都值得在云栈社区这样的技术平台上交流与沉淀。毕竟,在追求极致性能的路上,多数人遇到的问题都是相似的。如果大家对如何观测这些绕过了内核的高性能系统状态感兴趣,我们下次可以专门聊聊——毕竟,当传统的监控工具都“瞎了”之后,我们该如何看清系统的全貌呢?
 发表于 2026-1-26 10:26:33
|
查看: 231|
回复: 0
发表于 2026-1-26 10:26:33
|
查看: 231|
回复: 0
