概述
本次我们将探讨如何设计与实现一个简易的文章热榜功能。所谓热榜,就是平台将短期内最可能被大众阅读、讨论和转发的内容集中到一个榜单中展示,例如“今日热门”或“每周热榜”,让用户快速了解当下的焦点。
本文分为上下两篇,上篇主要聚焦于热榜分数的核心计算逻辑,涵盖用户关键行为的权重分配、基于牛顿冷却定律的时间衰减因子设计,以及最终将计算出的热度分、文章ID和标题回写到Redis中的完整过程。
热榜功能的实现思路
热榜分数的计算思路
实现文章热榜,首先要解决两个核心问题:一是如何计算出合理的分数,二是在用户交互数据不断变化的情况下,应该以怎样的时间间隔来重新计算这个榜单。
要将热门内容进行排序,首先需要采集用户的关键行为数据,例如阅读、点赞、评论、收藏、分享、停留时长等,并将这些行为量化为分数。通常,不同行为的权重不同,一个常见的权重关系是:收藏 > 点赞 > 阅读。假设我们已经通过其他方式采集到了这些行为数据(例如存储在数据库的 interactive 表中),那么初步的热榜分数公式可以表示为:
热榜分数 =(阅读数 × 阅读权重)+(点赞数 × 点赞权重)+(收藏数 × 收藏权重)
接着,将所有文章按此分数从高到低排序,就能得到一个基础的热门榜单。但这样做有一个明显的问题:发布很久但阅读量极高的“老文章”会一直占据榜单前列,导致新文章没有曝光机会。因此,我们必须引入“时间衰减”机制,让发布越久的文章其热度分数自然降低,从而实现榜单内容的新陈代谢。于是,公式演进为:
热榜分数 = [(阅读数 × 阅读权重)+(点赞数 × 点赞权重)+(收藏数 × 收藏权重)] × 时间衰减因子
不同平台的权重设定千差万别,且可能需要动态调整。为了简化演示,本文设定如下权重值:
时间衰减的规则,我们借鉴了牛顿冷却定律的思想。该定律描述了物体冷却速率与它和环境之间温差的关系:初期温差大,冷却快;后期温差小,冷却慢。这种“初期降得快,后期降得慢”的衰减规律,非常符合人们对“热度”逐渐消退的直觉认知。
公式表示为:T(t) = T_s + (T_0 - T_s) * e^(-k*t),其中 t 为时间,k 为衰减系数。
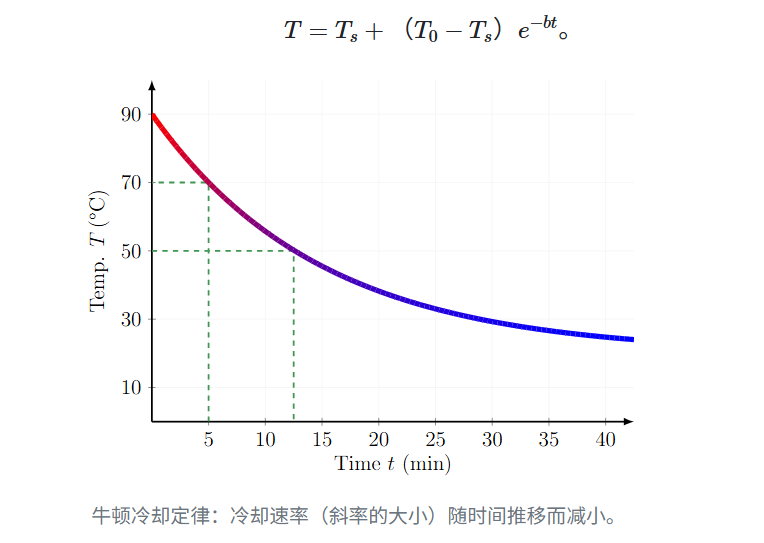
在热榜场景中,我们参考此定律,使用 decayFactor = e^(-k * t) 作为衰减因子。其中 k 是衰减系数,t 是文章发布后经过的时间(单位为小时)。调整 k 值可以灵活控制热度的衰减速度:k 值越大,热度衰减越快,榜单更新更频繁;k 值越小,衰减越慢,榜单更稳定。
不同平台、不同类型的榜单(如小时榜、日榜、周榜)对衰减系数的要求也不同。例如,新闻资讯类平台对时效性要求极高,k 值会设得很大;而对于书评、影评等内容质量重于时效性的平台,k 值则可以设得较小,甚至需要利用衰减机制来为“水文”降温。本文为演示方便,将衰减系数 k 设定为 0.1。
解决了分数计算问题,接下来是计算频率。我们不可能也无必要每秒重新计算全站文章的热度。合理的做法是定时计算,例如小时榜每小时计算一次,日榜每天计算一次。定时任务的实现可以借助 Go 的 robfig/cron 等库,这部分与Web前端的整合我们留到下篇讨论。下文我们将重点放在热榜分数的具体计算与存储实现上。
热榜的功能实现
最终的热榜接口需要返回文章ID、文章标题和实时热度分,因此这些信息都需要存入 Redis。我们分步实现:
1. 数据获取与分数计算
首先,我们需要从数据库获取文章的交互数据。由于还需要文章标题,这里涉及 interactive 表与 articles 表的联表查询。为了避免一次性查询数据量过大,我们采用分页查询,每次处理1000条。在实际生产环境中,可以增加查询门槛,例如只计算阅读量大于一定数值的文章。
定义领域模型和DAO层查询方法:
// domain
type ArticleWithInteractive struct {
ID string `json:"id" gorm:"primary_key;autoIncrement;"`
Title string `gorm:"column:title"`
ReadCount int `json:"readCount" gorm:"column:read_count"`
LikeCount int `json:"likeCount" gorm:"column:like_count"`
CollectCount int `json:"collectCount" gorm:"column:collect_count"`
CreatedAt string `json:"createdAt" gorm:"column:created_at"`
}
...
// dao层
func (i *GromTbTask) GetArticleIDs(pageIndex, pageSize int) (res []domain.ArticleWithInteractive, err error) {
if err = i.db.Model(&domain.Article{}).
Select("article.id,title,read_count,like_count,collect_count,created_at").
Joins("JOIN webook.interactive ON webook.article.id = webook.interactive.aid").
Limit(pageSize).Offset((pageIndex - 1) * pageSize).Find(&res).Error; err != nil {
return res, err
}
return res, nil
}
拿到数据后,便可计算热榜分数。计算分为两步:先根据权重算出基础分,再结合发布时间和衰减系数计算衰减因子,两者相乘得到最终热度分。
func CalcHotScore(article domain.ArticleWithInteractive) float64 {
// 基础分数
baseScore := float64(article.ReadCount)*ReadScore + float64(article.LikeCount)*LikeScore + float64(article.CollectCount)*CollectScore
layout := "2006-01-02 15:04:05"
t, err := time.ParseInLocation(layout, article.CreatedAt, time.Local)
if err != nil {
return 0
}
pubishedDuration := time.Since(t).Hours()
decayFactor := math.Exp(-HotDecayCoefficient * pubishedDuration)
return baseScore * decayFactor
}
2. 数据存储到Redis
计算出的热度分需要写入Redis。这里我们使用两种数据结构:
- ZSet (有序集合): 以文章ID为成员(member),热度分为分值(score)。ZSet天生支持按分值排序,非常适合于实现“榜单”。
- Hash (哈希表): 以文章ID为键,存储文章的标题等详细信息,方便根据ID快速获取。
在repository层,我们分批获取文章数据,计算分数后依次写入Redis:
func (t taskRepository) ReCalcHotList(ctx context.Context) (err error) {
/*
1. 分批查询. 每次1000篇,设置门槛:只查阅读量大于xx的,日榜只查今天的
*/
pageSize := 1000
index := 1
for {
alist, err := t.taskDAO.GetArticleIDs(index, pageSize)
if err != nil {
log.Println("err", err)
return err
}
if len(alist) == 0 {
break
}
// 每计算完1000篇就写入redis,清空缓存区,计算分数
for _, art := range alist {
artScore := events.CalcHotScore(art)
_, err := t.rdb.ZAdd(ctx, "hotlist/articles/score/", redis.Z{Score: artScore, Member: art.ID}).Result()
if err != nil {
log.Println("err", err)
return err
}
_, err = t.rdb.HSet(ctx, "hotlist/articles/"+art.ID, "title", art.Title, "score", 0.1).Result()
if err != nil {
log.Println("err", err)
return err
}
}
index++
}
return nil
}
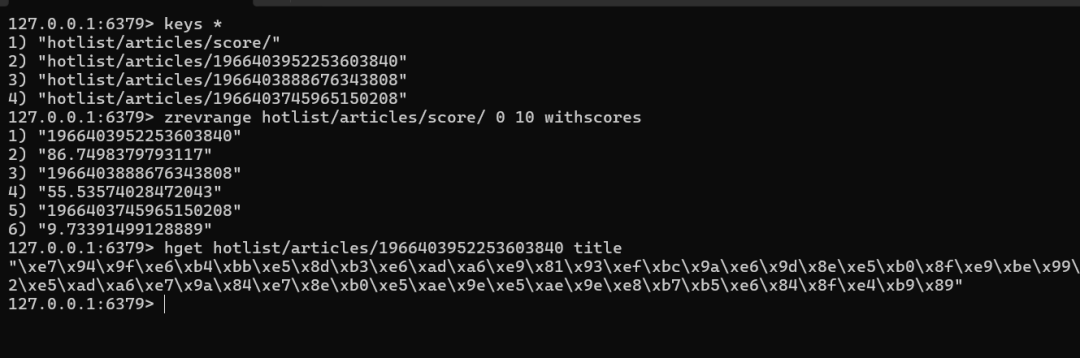
计算完成后,我们可以在Redis中查看写入的数据。使用 ZREVRANGE 命令可以按分数从高到低获取指定区间的成员及其分数。
3. 提供热榜查询接口
最后一步是实现热榜查询API,从Redis中读取数据并返回。为了提高效率,我们使用Pipeline进行批量操作,减少网络往返次数。
// dao 层
func (dao *GORMArticle) GetHosList(ctx context.Context, key string) (hostList []domain.ArticleWithScores, err error) {
pipe := dao.rdb.Pipeline()
zCmd := pipe.ZRevRangeWithScores(ctx, key, 0, 10)
_, _ = pipe.Exec(ctx)
zs, err := zCmd.Result()
if err != nil {
return nil, err
}
if len(zs) == 0 {
return nil, nil
}
pipe2 := dao.rdb.Pipeline()
titleCmds := make([]*redis.StringCmd, len(zs))
for i, z := range zs {
idStr := z.Member.(string)
titleCmds[i] = pipe2.HGet(ctx, "hotlist/articles/"+idStr, "title")
}
_, err = pipe2.Exec(ctx)
if err != nil && !errors.Is(err, redis.Nil) {
return nil, err
}
output := make([]domain.ArticleWithScores, 0, len(zs))
for i, z := range zs {
id, _ := strconv.ParseUint(z.Member.(string), 10, 64)
output = append(output, domain.ArticleWithScores{
ID: strconv.FormatUint(id, 10),
Title: titleCmds[i].Val(),
Score: z.Score,
})
}
hostList = output
return hostList, nil
}
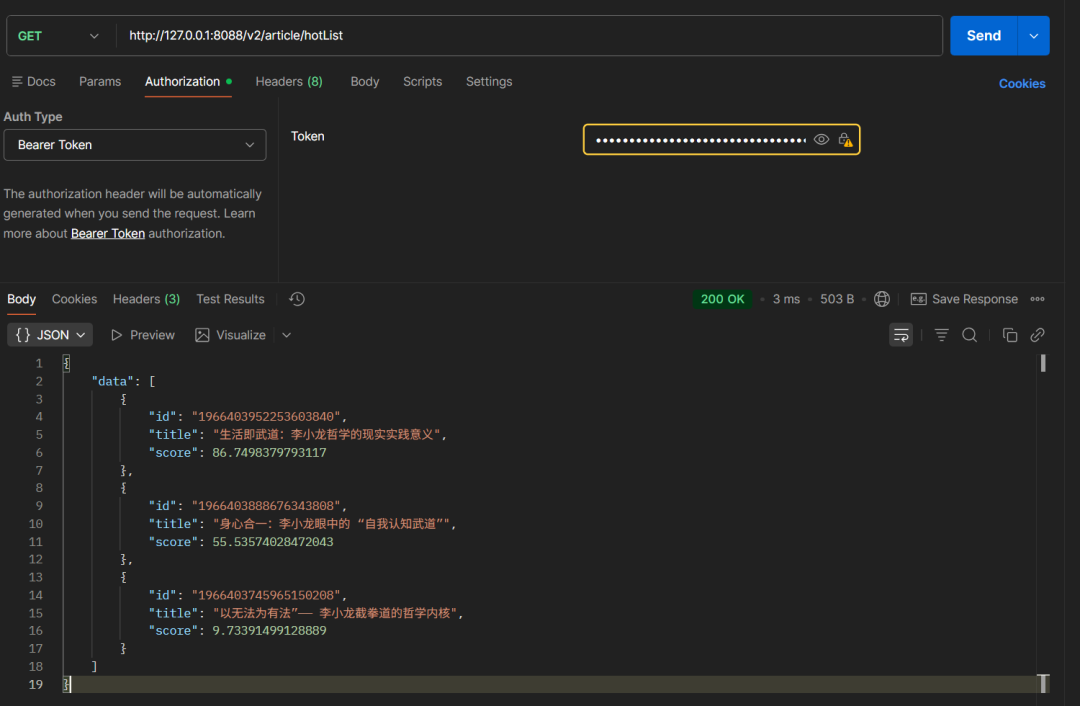
此时,访问热榜接口,便能获得按热度排序的文章列表。
总结
至此,我们完成了文章热榜功能核心计算与存储部分的设计与实现。我们定义了用户行为的权重,引入了基于牛顿冷却定律的时间衰减机制来保证榜单的时效性,并利用Redis的ZSet和Hash数据结构高效地存储和查询榜单数据。
在下篇中,我们将把热榜计算逻辑与Go的定时任务框架结合,实现可动态配置的日榜、周榜计算,并探讨如何与前端进行交互。希望本文的实现思路能对你有所启发。欢迎在云栈社区交流更多关于系统设计与Go开发的实践经验。
 发表于 2026-1-26 14:20:24
|
查看: 263|
回复: 0
发表于 2026-1-26 14:20:24
|
查看: 263|
回复: 0
