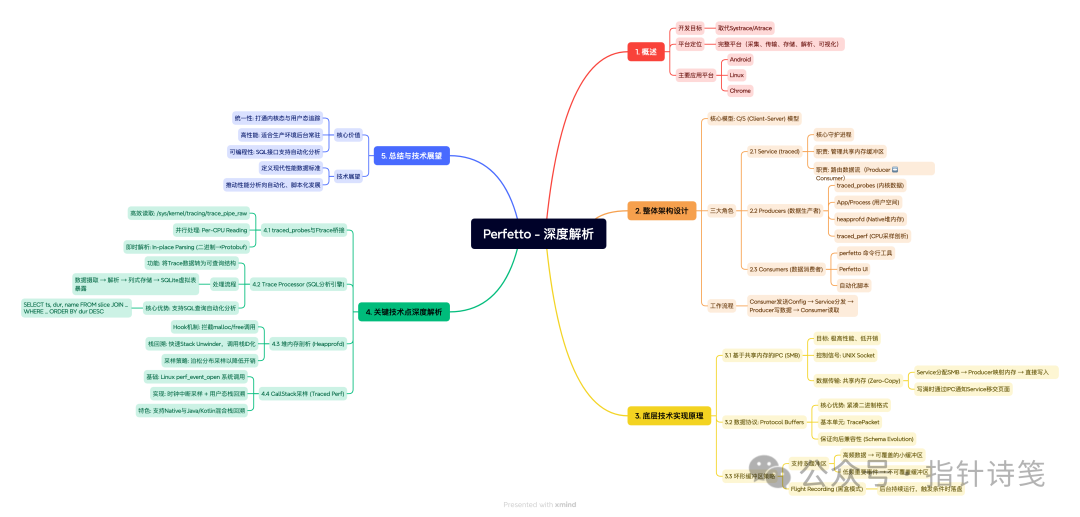
你是否好奇,那些动辄生成数百MB、包含数十亿事件的系统性能数据,是如何被高效采集、传输和分析的?Google推出的Perfetto给出了答案。它不仅旨在替代传统的Systrace和Atrace,更构建了一套涵盖数据采集、传输、存储、解析与可视化的完整平台,现已成为Android、Linux乃至Chrome平台性能剖析的基石。
1. 整体架构设计
Perfetto的架构遵循高度解耦与模块化原则,其核心采用经典的C/S (Client-Server) 模型,但为应对极致的性能与低开销要求,进行了深度定制。
整个系统围绕三个核心角色运作:
1. Service (traced)
- 这是整个系统的核心守护进程。
- 负责管理用于追踪的共享内存缓冲区。
- 作为仲裁者,协调数据生产者(Producer)与消费者(Consumer)之间的连接与状态。
- 关键职责:它不主动产生或解析数据,而是专注于高效地路由二进制数据流。
2. Producers (数据生产者)
- 连接到Service并写入追踪数据的客户端。
- 类型多样:
traced_probes: 一个特权守护进程,专门采集内核数据(如Ftrace, /proc信息)。- App/Process: 嵌入了Perfetto SDK的用户空间进程(如Chrome浏览器、Android系统服务)。
heapprofd: 专门用于Native堆内存剖析。traced_perf: 用于CPU采样剖析。
3. Consumers (数据消费者)
- 连接到Service并读取追踪数据的实体。例如命令行工具
perfetto、Web UI前端,或用于自动化测试的脚本。
- 工作流程通常为:Consumer发送配置(Config)给Service,Service分发给相应Producer,Producer开始写入数据,Consumer最终读取数据。
2. 底层技术实现原理
Perfetto区别于传统工具的核心,在于其对性能极致的追求,这主要体现在其IPC通信机制与数据格式上。
2.1 基于共享内存的IPC
为了在每秒数万次事件的高频场景下采集数据而不拖慢系统,Perfetto必须避免传统Socket通信带来的内核上下文切换与数据拷贝开销。
- SMB (共享内存缓冲区):
- Producer与Service之间通过UNIX Socket建立连接(仅用于控制信号,如握手、配置)。
- 所有数据传输完全通过共享内存进行,实现了Zero-Copy。
- 流程:Service分配共享内存区域并将其文件描述符传递给Producer;Producer将其映射到自身地址空间后直接写入数据;写满一页后通知Service,Service将其移交或流式传输给Consumer。
- 核心优势:数据从产生到进入缓冲区,完全无内核拷贝,仅涉及内存写入操作,这对系统监控和性能分析至关重要。
2.2 数据协议:Protocol Buffers
Perfetto全面采用Protocol Buffers (Protobuf) 作为其数据格式。
- 紧凑性:相比Systrace的文本格式,二进制Protobuf体积显著减小,大幅降低I/O压力。
- Schema Evolution:保证了良好的前后向兼容性。
- TracePacket:作为数据流的基本单元,所有事件(如
SchedSwitch、CpuFrequency)都被封装在一个TracePacket消息中。
2.3 环形缓冲区策略
在Service内部,数据被存储在环形缓冲区中。
- 多缓冲区支持:允许配置多个环形缓冲区。例如,可将高频的Ftrace数据放入一个小的、可覆盖的缓冲区,而将低频关键事件放入另一个受保护的缓冲区。
- Flight Recording (黑盒模式):设备可后台持续运行Perfetto并覆盖旧数据。当特定触发器(如应用崩溃)发生时,系统发送
STOP信号,Perfetto将当前环形缓冲区数据落盘。这对捕获“偶现Bug”至关重要。
3. 关键技术点深度解析
3.1 traced_probes 与 Ftrace 的桥接
Perfetto并不重新发明内核追踪,而是高效地利用Linux内核主要的追踪机制——Ftrace。
traced_probes进程通过/sys/kernel/tracing/trace_pipe_raw读取内核原始的二进制Trace数据。- Per-CPU Reading:为每个CPU核心启用独立线程并行读取,避免锁竞争。
- In-place Parsing:读取到的原始Ftrace二进制数据被立即原地解析并转换为Perfetto的Protobuf格式,然后写入SMB,整个过程高度优化,CPU占用极低。
3.2 Trace Processor:基于SQL的分析引擎
这是Perfetto相比传统工具最大的飞跃,它解决了“展示数据易,查询数据难”的问题。
- 工作流程:
- Ingestion: 读取Protobuf格式的Trace文件。
- Parsing: 根据Schema解析数据。
- Columnar Storage: 将数据加载到内存中的列式存储结构(针对查询优化)。
- SQLite Virtual Tables: 通过SQLite的虚拟表接口将这些数据暴露出来。
- 最终,用户可以使用标准SQL语句对海量Trace数据进行灵活查询。例如,查找主线程耗时最长的操作:
SELECT
ts,
dur,
name
FROM slice
JOIN thread_track ON slice.track_id = thread_track.id
JOIN thread ON thread_track.utid = thread.utid
WHERE thread.name = 'MainThread'
ORDER BY dur DESC
LIMIT 10;
3.3 堆内存剖析 (Heapprofd)
Perfetto实现了低开销的Native内存剖析。
- Hook机制:在Android上利用Bionic libc的
malloc_debug,或在Linux上通过LD_PRELOAD拦截malloc/free调用。
- 栈回溯(Unwinding):当内存分配发生时,通过高度优化的栈回溯器获取调用栈,并将调用栈ID化以减少数据量。
- 采样:支持基于泊松分布的采样,并非记录每次
malloc,而是统计学上每分配一定字节数记录一次,最终通过统计方法还原总量,以控制开销。
3.4 CallStack 采样 (Traced Perf)
利用Linux的perf_event_open系统调用进行基于时钟中断的CPU采样。
- 内核驱动:内核周期性中断CPU,记录当前指令指针与寄存器状态。
- 用户态解析:
traced_perf读取这些样本,并进行用户态或内核态的栈回溯。
- 混合栈回溯:支持Java/Kotlin (ART Runtime) 与 Native (C++) 的混合调用栈回溯,这是通过与ART虚拟机的协作实现的。
4. 总结与技术展望
Perfetto不仅仅是一个工具,它定义了一套现代化的性能数据采集-传输-分析标准。
- 统一性:打破了内核态与用户态、不同数据源之间的隔阂。
- 高性能:通过共享内存与Zero-Copy技术,使其能够应用于生产环境甚至后台常驻。
- 可编程性:Trace Processor与SQL接口使得性能分析可以自动化、脚本化,极大地提升了运维与研发效率。
随着5G、物联网和边缘计算的发展,对跨平台、低开销、深度可分析的系统追踪需求将愈发强烈。Perfetto凭借其优秀的设计,正在推动整个行业性能分析向标准化、数据驱动的方向发展。如果你想深入了解此类系统级工具或与其他开发者交流,可以前往云栈社区的运维/DevOps/SRE板块进行探讨。 |  发表于 2026-1-27 03:43:15
|
查看: 252|
回复: 0
发表于 2026-1-27 03:43:15
|
查看: 252|
回复: 0
