OceanBase 团队最近开源了 seekdb。
简单来说,它是一个 AI 原生的混合搜索数据库。核心价值在于,它让你可以在一个数据库里同时处理关系型存储(与 MySQL 100% 兼容)、向量检索(内置 HNSW 索引)、全文搜索以及 JSON 半结构化数据。
这意味着,开发者不再需要写大量胶水代码去拼接不同的技术栈。只需一条 SQL 语句,你就能完成“向量搜索 + 全文匹配 + 结构化过滤”的联合查询,从而高效驱动 RAG(检索增强生成)流程,极大地简化了 AI 应用的开发。
SeekDB 与主流向量数据库对比
为了更直观地了解 seekdb 的定位,我们可以将其与 Chroma、Milvus 等主流方案进行对比:
| 功能 |
seekdb |
Chroma |
Milvus |
PostgreSQL |
| 嵌入式数据库 |
✅ |
✅ |
✅ |
❌ |
| MySQL 兼容 |
✅ |
❌ |
❌ |
❌ |
| 向量搜索 |
✅ |
✅ |
✅ |
插件 |
| 全文搜索 |
✅ |
❌ |
部分支持 |
插件 |
| 混合搜索 |
✅ |
❌ |
✅ |
部分支持 |
| OLTP |
✅ |
❌ |
❌ |
✅ |
| OLAP |
✅ |
❌ |
❌ |
✅ |
| 开源协议 |
Apache 2.0 |
Apache 2.0 |
Apache 2.0 |
PostgreSQL License |
综合来看,seekdb 的几个突出优势可以总结如下:
| 特性 |
说明 |
| MySQL 兼容 |
零学习成本,现有 MySQL 客户端、驱动和工具链可以直接连接使用。 |
| 轻量部署 |
单节点轻量,一个 Docker 命令就能跑起来,非常适合原型验证和中小规模应用。 |
| 混合搜索 |
向量相似度、全文关键词、结构化条件过滤,三者可以融合在一条 SQL 语句中完成。 |
| 支持嵌入应用 |
可作为轻量级库直接嵌入到你的 Spring Boot 应用中,不依赖独立服务。 |
一行命令快速启动
部署 seekdb 简单到令人意外,使用 Docker 只需一行命令:

docker run -d --name seekdb -p 2881:2881 oceanbase/seekdb:latest
执行完毕后,你的 seekdb 实例就在本地的 2881 端口运行起来了。接下来,用任何你熟悉的 MySQL 客户端(如命令行工具、Navicat 等)连接 localhost:2881 即可。
对于 Python 开发者,如果希望以嵌入式方式在应用内使用,安装同样简单:
pip install pyseekdb
实战:Spring Boot 3 与 JdbcClient 集成
理论说完,我们进入实战环节。下面我将演示如何在一个 Spring Boot 3.5 应用中使用 JdbcClient 来对接 seekdb,涵盖建表、插入向量数据和执行混合搜索三个核心场景。
1. 添加项目依赖
首先,在 pom.xml 中添加必要的依赖:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<!-- seekdb 兼容 MySQL 协议 -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>
<!-- LangChain4j 用于生成 Embedding -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>1.0.0-beta3</version>
</dependency>
</dependencies>
2. 配置数据库连接
在 application.yml 中配置数据源。由于 seekdb 完全兼容 MySQL 协议,因此配置与连接普通 MySQL 数据库无异:
spring:
datasource:
url: jdbc:mysql://localhost:2881/test?useSSL=false
username: root@test
password:
driver-class-name: com.mysql.cj.jdbc.Driver
3. 创建支持向量搜索的表
接下来,我们执行建表 SQL。注意 VECTOR(1536) 是 seekdb 定义的向量字段类型,维度 1536 对应 OpenAI 的 text-embedding-ada-002 模型。
-- 创建文档表,包含向量字段
CREATE TABLE documents (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(512) NOT NULL,
content TEXT,
vector VECTOR(1536), -- 1536维向量
metadata JSON,
created_at DATETIME DEFAULT CURRENT_TIMESTAMP
);
-- 在向量字段上创建 HNSW 索引,使用余弦距离度量
CREATE VECTOR INDEX vec_idx ON documents(vector)
WITH (DISTANCE=COSINE, TYPE=HNSW);
CREATE VECTOR INDEX 语法非常直观,DISTANCE=COSINE 指定使用余弦相似度,TYPE=HNSW 指定索引算法。
4. 向表中插入向量数据
我们创建一个 Service,利用 JdbcClient 和 Embedding 模型插入数据。
@Service
@RequiredArgsConstructor
public class DocumentService {
private final JdbcClient jdbcClient;
private final EmbeddingModel embeddingModel;
public Long insertDocument(String title, String content, String metadata) {
// 1. 使用 LangChain4j 生成文本的 Embedding 向量
float[] vector = embeddingModel.embed(title + " " + content)
.content().vector();
// 2. 将 float 数组转换为 JSON 数组字符串,seekdb 要求此格式
String vectorJson = toJsonArray(vector);
// 3. 执行插入,vector 字段直接传入 JSON 字符串
return jdbcClient.sql("""
INSERT INTO documents (title, content, vector, metadata)
VALUES (?, ?, ?, ?)
""")
.params(title, content, vectorJson, metadata)
.update();
}
private String toJsonArray(float[] vector) {
return "[" + Arrays.stream(vector)
.mapToObj(String::valueOf)
.collect(Collectors.joining(",")) + "]";
}
}
向量数据需要以 JSON 数组的格式(如 [0.1, -0.2, 0.3,...])传入,seekdb 会自动解析并存储。
5. 执行向量语义搜索
基于向量进行语义相似度搜索是核心能力。
public List<SearchResult> semanticSearch(String query, int topK) {
float[] queryVector = embeddingModel.embed(query).content().vector();
String vectorJson = toJsonArray(queryVector);
// 关键:使用 Cosine_distance 函数,并添加 APPROXIMATE 以利用 HNSW 索引加速
return jdbcClient.sql("""
SELECT id, title, content,
Cosine_distance(vector, ?) AS distance
FROM documents
ORDER BY Cosine_distance(vector, ?) APPROXIMATE
LIMIT ?
""")
.params(vectorJson, vectorJson, topK)
.query(SearchResult.class)
.list();
}
Cosine_distance() 函数计算两个向量间的余弦距离,值越小表示越相似。APPROXIMATE 关键字告诉数据库走 HNSW 索引进行近似最近邻搜索,速度极快;若去掉该关键字,则会进行精确但缓慢的全表扫描。
6. 执行杀手锏:混合搜索
单一的向量搜索有时会“误伤”或“遗漏”,结合关键词匹配能显著提升召回质量。这就是 seekdb 的混合搜索能力。
public List<HybridSearchResult> hybridSearch(
String query, int topK,
double keywordWeight, // 关键词权重,建议 0.3
double semanticWeight) { // 语义权重,建议 0.7
float[] queryVector = embeddingModel.embed(query).content().vector();
String vectorJson = toJsonArray(queryVector);
String likePattern = "%" + query + "%";
return jdbcClient.sql("""
SELECT id, title, content,
-- 关键词命中得 1 分
CASE WHEN title LIKE ? OR content LIKE ?
THEN 1.0 ELSE 0.0 END AS keyword_score,
-- 语义相似度(将距离转换为相似度:1-距离)
(1 - Cosine_distance(vector, ?)) AS semantic_score,
-- 加权综合得分
(CASE WHEN title LIKE ? OR content LIKE ?
THEN 1.0 ELSE 0.0 END) * ? +
(1 - Cosine_distance(vector, ?)) * ? AS final_score
FROM documents
ORDER BY final_score DESC
LIMIT ?
""")
.params(likePattern, likePattern, vectorJson,
likePattern, likePattern, keywordWeight,
vectorJson, semanticWeight, topK)
.query(HybridSearchResult.class)
.list();
}
这条 SQL 在一个查询中同时计算了关键词匹配分数和向量语义相似度分数,并按照你设定的权重进行加权融合,最后按综合得分排序。这种方法在构建 RAG 系统时,能有效平衡语义相关性和字面匹配,提供更精准的检索结果。

进阶:与 Spring AI Alibaba 快速集成
如果你希望进一步简化开发,可以使用 Spring AI Alibaba 提供的 VectorStore 抽象。它能帮你自动处理 Embedding 生成和向量存储。
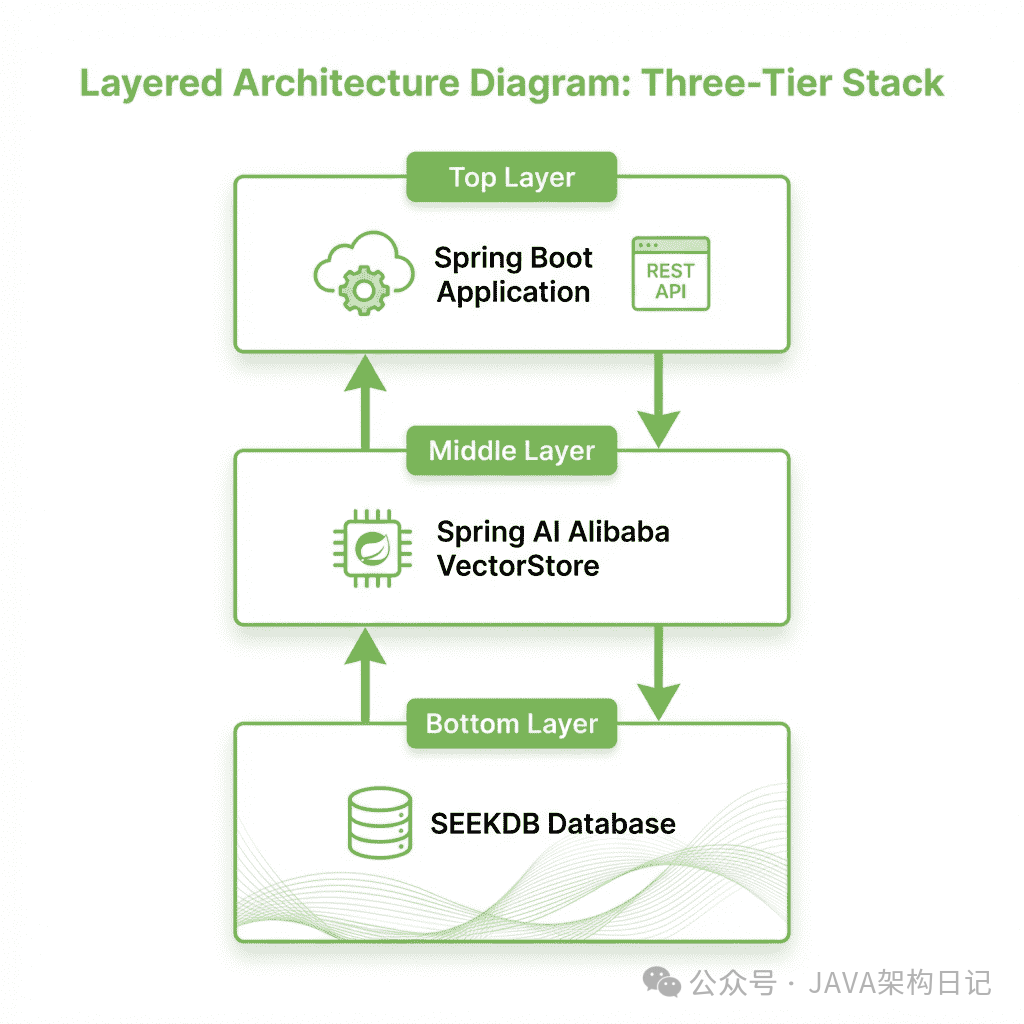
Spring AI 与 SeekDB 集成架构示意图
请注意:当前 Spring AI Alibaba 的 OceanBase VectorStore 实现主要支持向量相似度搜索,尚未直接封装上文演示的“向量+关键词”混合搜索能力。如需混合搜索,仍需编写自定义 SQL。
1. 添加依赖
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-store-oceanbase</artifactId>
<version>1.0.0.2</version>
</dependency>
2. 配置
spring:
ai:
dashscope:
api-key: ${DASHSCOPE_API_KEY}
vectorstore:
oceanbase:
enabled: true
url: jdbc:oceanbase://localhost:2881/test
username:
password:
tableName: ai_documents
defaultTopK: 5
defaultSimilarityThreshold: 0.7
3. 使用 VectorStore
@RestController
@RequiredArgsConstructor
public class RagController {
private final OceanBaseVectorStore vectorStore;
@PostMapping("/documents")
public String addDocuments() {
List<Document> docs = List.of(
new Document("Spring Boot 3.5 发布了", Map.of("type", "news")),
new Document("seekdb 支持混合搜索", Map.of("type", "tech"))
);
vectorStore.add(docs);
return "OK";
}
@GetMapping("/search")
public List<Document> search(@RequestParam String query) {
return vectorStore.similaritySearch(
SearchRequest.builder().query(query).topK(5).build()
);
}
}
Spring AI 的抽象层接管了从文本到向量存储再到检索的完整流程,让代码变得非常简洁。
总结与展望
AI 应用开发正从“拼凑式架构”向“一体化架构”演进。像 seekdb 这样的 AI 原生数据库,其核心思路正是将向量计算、混合检索等能力下沉到数据库层,而非在应用层进行复杂的集成。
这对于广大的 Java 开发者而言尤其友好。MySQL 协议的完全兼容意味着近乎为零的学习成本,你熟悉的 JdbcTemplate、JdbcClient、MyBatis 等工具都可以无缝使用。再结合 Spring AI 的 VectorStore 抽象,开发 RAG 应用数据层的体验得到了质的提升。
如果你正在着手开发 AI 应用或尝试构建 RAG 系统,不妨试试 seekdb,它可能会让你的技术栈变得更加简洁和高效。也欢迎到 云栈社区 交流你的使用心得。

 发表于 2026-1-27 04:27:02
|
查看: 184|
回复: 0
发表于 2026-1-27 04:27:02
|
查看: 184|
回复: 0
