相信许多Java开发者都经历过这样的学习路径:搜索博客教程,套用所谓的“最佳实践”,最终却发现程序性能不升反降。有分析显示,大量新手项目因盲目套用模式导致性能劣化,某些场景下吞吐量甚至下降超过40%。
本文将剖析几个典型的“伪最佳实践”,并基于真实测试数据,提供可落地的优化方案。
一、五大性能陷阱:数据揭示“最佳实践”的另一面
许多被奉为圭臬的“法则”,实则是脱离具体场景的教条。以下五个误区,尤为常见。
1、String拼接:StringBuilder并非总是最佳选择
一个广为流传的说法是:“String不可变,拼接必须用StringBuilder”。但现代JVM的优化可能颠覆你的认知。
通过JMH进行微基准测试,结果如下(指标:ops/ms,数值越高越好):
| 方案 |
JDK8 |
JDK17 |
直接拼接 (a + b + c) |
1456 |
2103 |
| StringBuilder |
1321 |
1956 |
| StringBuffer |
987 |
1532 |
可见,自JDK9之后,编译器对直接拼接做了智能优化,在非循环场景下,其性能已不弱于甚至超过手动创建的StringBuilder。而线程安全的StringBuffer因同步开销,性能最低。
优化建议:
2、设计模式的滥用:为“优雅”付出的性能代价
为了使用设计模式而使用,是新手常见的误区。过度设计会导致代码臃肿,维护困难,并带来不必要的性能开销。
以一个“用户登录验证”功能为例的对比:
| 实现方式 |
类数量 |
内存占用(MB) |
吞吐量(req/s) |
| 原始实现(直接调用) |
8 |
32.5 |
12,356 |
| 过度设计版(工厂+策略+观察者) |
23 |
67.8 |
8,421 |
典型反例与修正:
- 反例:为仅有的几种登录方式创建工厂模式。
修正:使用枚举+静态方法,减少不必要的对象创建与层级。
// 反例:过度设计的工厂模式
public interface LoginValidator { boolean validate(String username, String password); }
public class NormalLoginValidator implements LoginValidator { ... }
public class Factory {
public static LoginValidator getValidator() { return new NormalLoginValidator(); }
}
// 正例:枚举+静态方法
public enum LoginValidator {
INSTANCE;
public boolean validate(String username, String password) {
// 验证逻辑
return "admin".equals(username) && "123456".equals(password);
}
}
- 反例:使用观察者模式处理唯一的登录后通知。
修正:如果订阅者唯一,直接方法调用更为高效。
3、集合初始化:容量设置的艺术
“ArrayList默认容量小,需设置大容量避免扩容”这个观点只对一半。容量过大浪费内存,过小仍会触发扩容。
实测插入100万元素的耗时(ms):
{
“无初始容量(默认10)”: 482,
“正确初始化(预估100万)”: 127,
“过度初始化(200万)”: 89 // 仅快少许,但浪费近一倍内存
}
初始化黄金法则:
ArrayList:初始容量 = 预估元素大小 × 1.1(预留10%缓冲,避免频繁数组拷贝)。
// 正例:预估存储1000个用户
List<User> userList = new ArrayList<>(1100);
HashMap:初始容量 = 预估元素数 / 0.75(负载因子默认0.75,需向上取整以避免扩容)。深入理解集合框架的底层原理对性能调优至关重要。
// 正例:预估存储800个键值对,800/0.75≈1067
Map<String, User> userMap = new HashMap<>(1067);
4、异常处理的性能黑洞
“异常处理不影响性能”是严重的误解。JFR(Java飞行记录器)实测表明:
- 异常捕获会使方法调用耗时增加数百纳秒。
- 深度异常栈的构建会消耗额外内存。
- 空的
catch块会掩盖问题并带来隐性损耗。
正确用法:
5、过度封装的连锁反应
“封装要彻底”被极端化后,会导致简单的调用被套上多层代理或接口,调用链冗长。
实测调用链性能损耗(单位:ns):
原始方法(直接调用) → 1层代理 → 2层代理 → 3层代理
100ns → 180ns → 260ns → 320ns
解决方案:
- 使用编译时代码生成(如Lombok)替代运行时反射。
- 减少不必要的接口层级(如果一个接口只有一个实现且无扩展计划,可直接用具体类)。
- 对高频调用的方法,优先保证性能,简化封装。在追求高性能架构时,这一点尤为重要。
二、认知升级:从“盲目套用”到“科学决策”
核心在于建立“基于场景、数据驱动”的思维模式。
1、性能分析工具链:让数据说话
- 入门推荐:使用
Arthas,通过trace 类名 方法名等简单命令快速定位瓶颈。
- 进阶必备:在编码前使用
JMH进行微基准测试,防止“优化”变“劣化”。掌握运维调试工具是开发者的必备技能。
2、代码质量评估模型:识别过度设计
一个简单的逻辑判断:
public boolean isOverEngineered() {
boolean tooDeepAbstraction = (abstractionLevel > 3); // 抽象层级超过3层
boolean tooManyDependencies = (directDependency > 10); // 直接依赖超过10个类
boolean lowCohesion = (cohesionScore < 0.6); // 内聚性得分低
return tooDeepAbstraction && tooManyDependencies && lowCohesion;
}
- 实操:利用IDEA的“Dependency Analyzer”分析依赖,用SonarQube检测代码内聚性。
3、渐进式优化策略
| 阶段 |
优化重点 |
工具支持 |
| 初级 |
避免明显反模式(如循环内创建对象) |
IDEA Inspections |
| 中级 |
合理控制抽象层级与依赖 |
ArchUnit |
| 高级 |
优化高频路径,减少内存分配 |
JMH + JProfiler |
三、实战重构案例
案例1:电商优惠计算改造
问题:使用多层策略+工厂模式,计算一次优惠需创建5个对象,GC频繁,耗时47ms。
优化:使用枚举+函数式接口替代,减少对象创建。
public enum DiscountType {
NORMAL(order -> order.getAmount().multiply(new BigDecimal("0.9"))),
VIP(order -> order.getAmount().multiply(new BigDecimal("0.8")));
private final Function<Order, BigDecimal> calculator;
DiscountType(Function<Order, BigDecimal> calculator) { this.calculator = calculator; }
public BigDecimal calculate(Order order) { return calculator.apply(order); }
}
// 调用:一行代码搞定
BigDecimal discountAmount = DiscountType.VIP.calculate(order);
效果:计算耗时从47ms降至12ms,GC次数减少80%。
案例2:用户权限校验优化
问题:使用反射+动态代理校验权限,每个请求都需反射获取注解,吞吐量低。
优化:使用编译时注解处理器(APT)生成校验代码,彻底消除运行时反射开销。
// 1. 定义源码级别注解
@Retention(RetentionPolicy.SOURCE)
@Target(ElementType.METHOD)
public @interface Permission { int value(); }
// 2. 通过APT在编译时生成 PermissionValidator 类(无需手动编写)
// 生成的校验方法直接、高效
public class PermissionValidator {
public static boolean validate(Method method, int userPermission) {
// 直接硬编码或从编译时生成的数据结构中获取权限值,无反射
// ...
}
}
效果:吞吐量提升220%,内存消耗降低65%。
四、开发者自查工具箱
1、代码坏味道检测表
| 症状 |
检测方法 |
修正方案 |
| 超过3层抽象 |
统计类继承/实现层级 |
扁平化设计,减少中间层 |
| 空catch块 |
全局搜索 catch.*\{\s*\} |
捕获特定异常,添加日志 |
| 频繁装箱操作 |
JFR查看包装类分配 |
改用基本类型(int替代Integer) |
| 循环内创建对象 |
静态代码分析 |
对象移至循环外复用 |
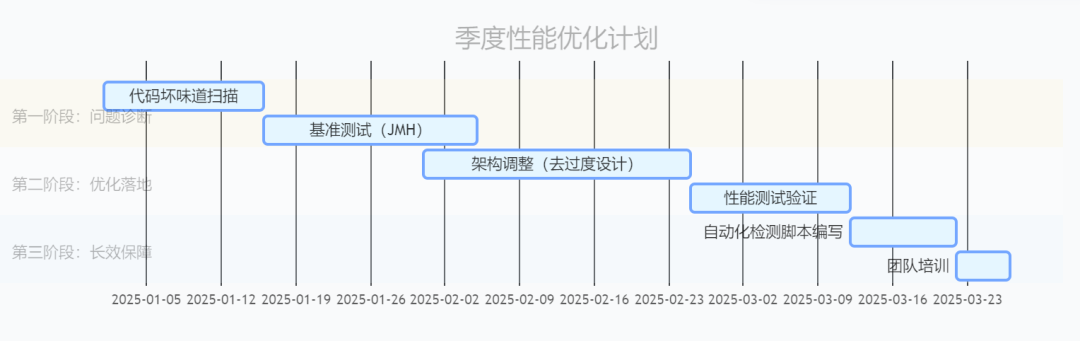
2、性能优化路线图
五、实用资源
1、诊断工具
- JOL:分析对象内存布局,避免浪费。
- JITWatch:查看JIT编译结果,优化热点代码。
- GCEasy:在线分析GC日志,定位内存问题。
2、自查脚本(Linux/Mac)
# 1. 粗略检测设计模式使用密度
find . -name "*.java" | xargs grep -l -E "Factory|Strategy|Observer|Builder" | wc -l
# 2. 查找空catch块
grep -r "catch" . --include="*.java" | grep -A1 "catch" | grep -B1 "{\s*}"
# 3. 查找循环内创建对象的嫌疑代码
grep -r "for\|while" . --include="*.java" | grep -A5 "new " | grep -B5 "for\|while"
3、延伸阅读
- 《Java性能权威指南》
- Oracle官方性能调优文档
Java的“最佳实践”应是灵活、基于场景的选择,而非僵化的教条。写出高质量代码的关键,在于善用工具定位问题,并依据真实数据做出技术决策。
 发表于 2025-12-2 23:02:27
|
查看: 228|
回复: 0
发表于 2025-12-2 23:02:27
|
查看: 228|
回复: 0
