许多团队一谈到“部署AI智能体”,第一反应往往是:做个接口,接上大模型就万事大吉。然而真正落地后才会发现,智能体的“部署形态”才是决定系统成败的关键——它直接决定了应用能跑多快、运营成本有多高、出了问题如何排查,以及最终用户感觉到的究竟是“流畅好用”还是“响应卡顿”。
更重要的是,并不存在一套适用于所有场景的“唯一正确”架构。你需要面对的是不同的数据形态(一次性批量数据、持续流动的数据流、请求驱动的交互、端侧产生的数据)、差异化的体验预期(要求秒级回复、可以接受延迟、必须支持离线可用)以及复杂的成本约束(算力峰值、网络带宽、存储开销、运维人力)。下面我们将深入剖析四种核心的AI智能体部署模式,并为每种模式提供一个可以直接参考的具体案例,帮助你根据自身业务快速对号入座。
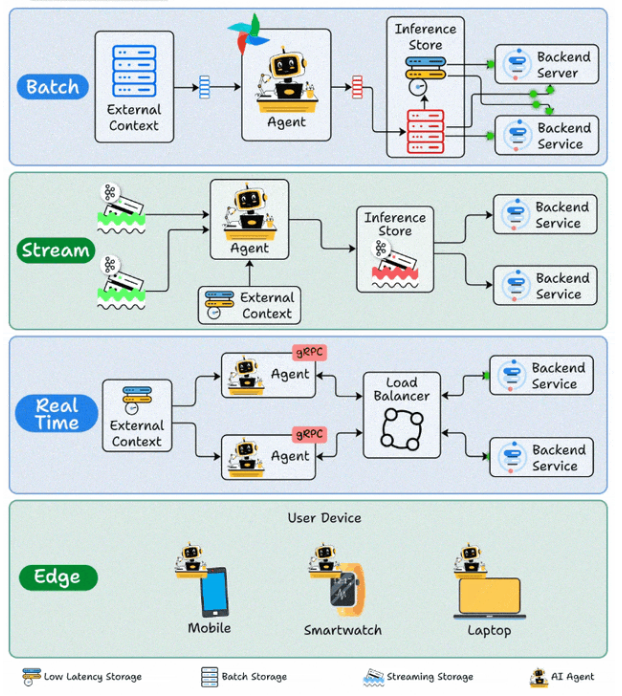
一、批量部署:将智能体视为“定时运行的自动化任务”
如果你能将智能体理解为“每天或每小时自动执行一次的脚本”,那么你就已经抓住了批量部署的精髓。
在这种模式下,智能体无需保持随时待命的状态,而是按照预设的计划周期性运行:从数据源(数据库、文件、API)拉取数据,调用工具或模型进行处理,最后将结果写回存储系统或数据仓库。它更关注的是吞吐量和成本效益:一次性能处理多少数据、单位成本能压到多低,而不是“单个请求能否在200毫秒内返回”。
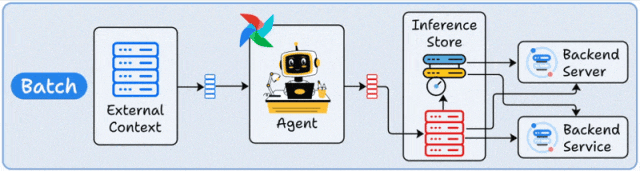
其适用场景非常明确:任务不要求即时响应,但数据量巨大、处理步骤繁多,并且需要稳定、可靠地输出结果。
案例:电商平台“评论质检与标签归类”夜间批处理
- 业务背景:电商平台每天新增数十万条用户评论。运营团队希望自动化完成以下工作:识别差评原因、检测是否包含敏感词、判断是否需要人工客服介入,同时为商品自动打上“做工好”、“物流慢”、“尺码偏小”等属性标签,以便次日清晨就能直接查看分析报表。
- 部署方式:在每天凌晨2点触发一个批量处理任务。智能体从数据仓库中拉取前一天产生的所有评论数据;首先使用规则引擎或轻量模型进行初筛(识别语言、过滤重复内容、标记疑似刷评),然后调用大模型API总结差评核心原因、抽取商品特征标签;最终将处理结果写回“评论标签表”和“风险待办工单表”。
- 为什么选择批量模式:用户评论并不需要实时处理,重点是实现“全量覆盖、成本可控、结果稳定”。选择在夜间运行,还能巧妙地避开日间的算力使用高峰,进一步降低成本。
你会发现,很多看似需要“炫酷AI”才能完成的工作,实际上最适合的反而是这种朴素、高效的定时任务形态。
二、流式部署:让智能体成为数据管道中的一环,持续在线处理
流式部署的关键词是“持续”和“实时数据流”。数据并非以批次的形式到达,而是如同水流般持续不断地产生:服务器日志、物联网传感器数据、金融交易事件、用户行为埋点……智能体化身为一个长期运行的处理节点,持续消费来自消息队列或流式存储中的事件。在处理过程中,它可能会实时访问后端服务以补充上下文信息,然后将处理结果输出,供下游的多个应用系统复用。
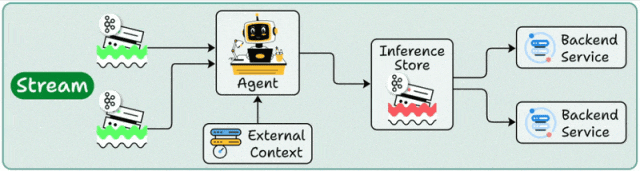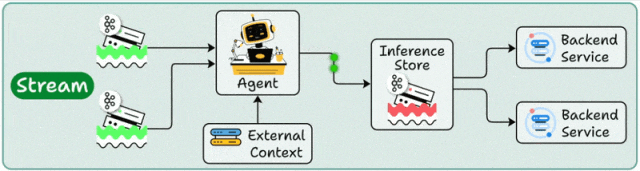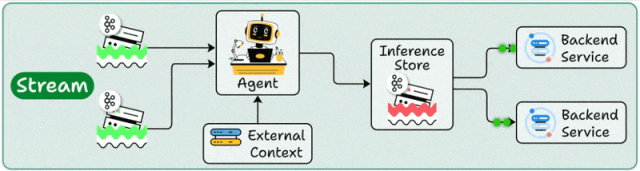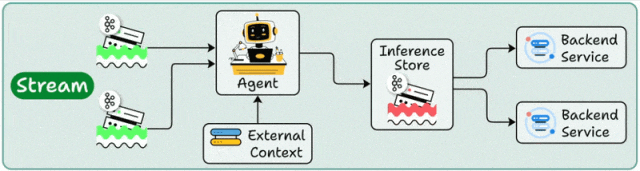
这种模式的优势在于:数据随到随处理,延迟稳定可预测;并且同一份处理结果可以被监控、告警、推荐、风控、BI等多个系统同时使用,避免重复计算。
案例:互联网平台“异常舆情与故障信号”流式监控
- 业务背景:一家互联网公司拥有APP、官网、客服工单系统和社交媒体等多个用户反馈渠道。任何一个渠道在短时间内出现大量关于“支付失败”、“应用闪退”、“无法登录”的集中抱怨,都可能是线上故障的早期信号,需要被立即发现。
- 部署方式:将所有渠道的用户反馈文本、客服工单摘要、社交媒体关键词抓取结果、应用日志中的关键错误事件,统一写入一个高吞吐的消息队列。智能体作为一个常驻服务,持续消费队列中的事件,进行实时聚合、去重和按主题归类。当识别出某个特定问题在短时间内的出现频率显著上升时,立即向告警系统输出一个结构化的“异常事件”,并附带由大模型生成的“可能原因分析、预估影响范围、建议排查路径”。
- 为什么选择流式模式:这不再是“每天看一次报表”的需求,而是“力争在十分钟内发现故障苗头”。只有让智能体一直处于运行状态,持续处理流动的数据,才能将故障发现时间从小时级压缩到分钟级。
流式部署就像将智能体嵌入公司数据系统的“血管”中,它不是在被动地“回答问题”,而是在主动地、持续地将原始信号转化为可供行动决策的线索。
三、实时部署:将智能体作为后端服务,请求到达即刻推理响应
实时部署最贴近大众对“智能体”的直观想象:它像一个可以对话、可以被随时调用的服务。这种模式通常通过RESTful API或gRPC接口对外暴露服务,收到请求后立即拉取相关上下文(用户画像、知识库、实时订单数据、工具调用结果等),然后驱动大模型进行推理,并尽快将结果返回给调用方。为了支撑高并发访问,需要引入负载均衡、弹性扩缩容、缓存与限流等机制。
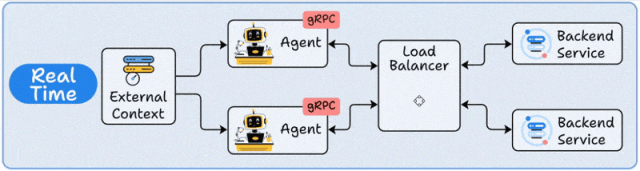
这个模式的核心考量是用户体验:用户正在另一端等待回复。响应延迟本身就是产品体验的一部分。
案例:银行App“智能客服+业务办理助手”
- 业务背景:用户进入银行App,可能会询问“我这笔转账为什么失败了?”、“如何解绑这张银行卡?”、“信用卡临时额度可以提现吗?”。用户不仅希望得到准确的文字解答,还期望能直接被引导至办理页面,而不是在复杂的菜单中自行寻找。
- 部署方式:智能体以API服务的形式部署在云端。每次请求到来,先进行用户身份鉴权和会话状态识别;随后从后端系统实时读取用户账户状态、近期交易记录摘要、产品规则知识库等信息;必要时调用内部工具查询订单详情、发起客服工单、生成业务办理步骤指引;最终目标是在2秒内给出一个“可理解、可执行”的答案,并将关键操作指令转换为结构化数据,交由下游业务系统执行。
- 为什么选择实时模式:用户在对话窗口里等待回复,超过几秒体验就会急剧下降。同时,系统必须保证在业务高峰期(如发薪日、节假日)也能稳定承载海量并发请求。
实时部署的挑战往往不在于“模型能不能给出答案”,而在于工程侧的实现:如何做好鉴权与安全、设计服务熔断与降级策略、处理工具调用失败的回退、实现全链路日志追踪与成本监控。这些工程能力才决定了智能体服务能否长期稳定地上线运行。
四、边缘部署:让智能体在用户设备端运行,优先保障隐私与离线能力
边缘部署的思路非常直接:既然数据敏感、网络环境不稳定、或者业务要求数据不能离开本地,那么就把推理逻辑尽可能地部署到终端设备上——例如手机、智能手表、个人电脑、车载系统、工业控制终端等。这样可以实现“数据不出设备”,极大保护隐私,并且在网络不佳甚至完全离线的状态下,核心功能依然可用。
这种模式通常意味着:使用的模型更加轻量、功能更加聚焦,但换来了更强的数据隐私保护能力和环境可用性。
案例:医疗场景下的“本地病历摘要与随访提醒”
- 业务背景:医生在门诊间隙需要快速回顾患者的历史病历要点、用药变化史、过敏史等信息,并且希望在查房时即使没有网络也能使用。同时,患者病历属于高度敏感数据,医院有严格规定,不允许上传至任何云端。
- 部署方式:在医院配发的专用平板电脑或笔记本电脑上部署端侧智能体应用。患者的病历文件仅在本地设备上进行加密存储。智能体在设备端完成对病历的自动摘要、关键信息结构化抽取(如诊断结论、异常检验指标、用药清单、注意事项),并生成随访提醒模板。当需要更新医学知识库时,只同步“规则与模型参数”的差分更新包,全程不上传任何患者原始数据。
- 为什么选择边缘模式:隐私合规是最高优先级的要求;医院内部网络环境可能复杂且不稳定;“数据不离开设备”本身也是该解决方案的核心价值与卖点。
边缘部署并不意味着“端侧万能”,它更像是一种架构策略:把最关键、最敏感、最需要离线可用的那部分能力放在终端设备上,其余更复杂或需要全局协调的能力,再通过按需调用云端服务来协同完成。
五、如何选择:四种模式的核心差异,一句话总结
- 批量部署:追求最大吞吐量与最低单位成本,允许任务延迟,适合大规模离线数据处理与分析场景。
- 流式部署:对持续流动的数据进行实时处理,适合实时监控、事件驱动与实时风控等场景。
- 实时部署:要求即时交互与低延迟响应,适合智能对话、在线业务办理与实时推荐等场景。
- 边缘部署:优先保障数据隐私与离线工作能力,适合终端敏感数据处理、弱网或离线环境。
六、总结
一个真正高质量、健壮的智能体系统,往往不是“四选一”的单选题,而是多种模式组合的“组合拳”。例如:在端侧(边缘)进行隐私数据脱敏和轻量级用户意图识别,将复杂推理交给云端实时服务;或者由实时服务处理在线请求,同时将关键交互数据沉淀下来,在夜间通过批量任务进行复盘与策略优化;再配合一条流式管道,实时监控所有环节的异常波动。
部署模式的选择远不是项目开发的最后一步,它实际上是产品体验和长期成本结构的起点。选对了架构模式,你会惊讶地发现,许多看似棘手的“模型效果问题”或“性能瓶颈”,会在系统架构层面找到更优雅的解决方案。对于更多AI与系统架构的深度讨论,欢迎在云栈社区与我们交流。
 发表于 2026-1-29 19:43:16
|
查看: 175|
回复: 0
发表于 2026-1-29 19:43:16
|
查看: 175|
回复: 0
