
CVPR的Rebuttal阶段即将截止,ECCV的投稿准备也该提上日程了。
想象这样一个场景:审稿人写道:“Your method lacks comparison with recent work XXX (2024).”
你打开ChatGPT,输入论文和审稿意见。它给你的回复是:“感谢审稿人的宝贵建议,我们将在修订版中补充相关比较。”
然后呢?剩下的工作一点没少。你还是得自己打开Google Scholar,找到那篇XXX论文,自己阅读、总结差异、组织语言。ChatGPT只是帮你写了一句话术。
那么,是否存在一个系统,能自动帮你完成文献查找、内容对比、甚至生成带有准确引用的反驳回复呢?
这正是上海交通大学AutoLab团队提出的 RebuttalAgent——一个将审稿回复视为“以证据为中心”的规划任务的多智能体协作框架。它不仅能优化措辞,更能主动检索文献、核实论据,最终生成有理有据、结构清晰的学术回复。

使用方法很简单:上传你的论文PDF和Markdown格式的审稿意见,RebuttalAgent便能像一位经验丰富的“学术军师”,为你提供一套完整的决策与证据组织方案:
- 全自动拆解:将长篇复杂的审稿意见拆解为原子级的独立问题。
- 证据溯源:自动从你的论文中回溯相关段落,并在需要时联网搜索arXiv等资源,寻找外部文献作为佐证。
- 行动清单:在撰写最终回复前,先生成一份清晰、可检查的“待办事项清单”(例如:需要补充哪些消融实验、计算哪些新指标)。
- 拒绝幻觉:它倾向于生成严谨、带有占位符的回复模板,等待你填入真实的实验结果或数据,而非信口开河。

方法:告别“张口就来”,三步构建严谨回复
与传统大模型“直出文本”的模式不同,RebuttalAgent将回复审稿意见定义为一个决策与证据组织问题。为此,它设计了一套 “先核验,后写作” 的透明化工作流:
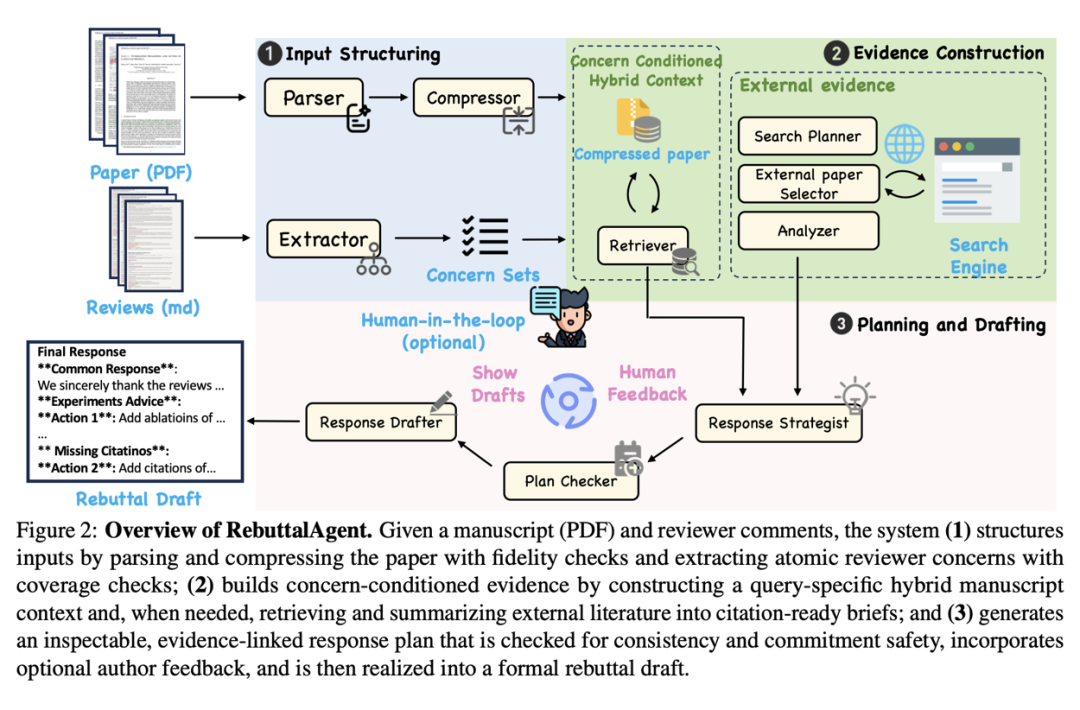
1. 结构化解析与关注点提取
系统首先通过“解析器”和“压缩器”智能体,将论文PDF转化为高保真度的压缩表示。同时,它将审稿人复杂的反馈意见拆解为一个个独立的“原子关注点”,确保每一个具体的质疑都不会被遗漏。
2. 混合证据构建
这是RebuttalAgent的核心。针对每一个具体的质疑点,它会执行双向检索:
- 对内检索:在论文全文中精准定位与问题最相关的论述、实验或数据段落。
- 对外检索:当遇到“相关工作对比缺失”或“基线方法不新”等问题时,系统会自动调用搜索工具,在arXiv等学术数据库上寻找相关的最新文献,并生成引用就绪的文献摘要。
3. 战略规划与人机回环
在正式起草回复信之前,系统会先生成一份回复策略计划。这份计划明确了对每个质疑点的反驳逻辑、拟采取的应对措施以及具体的行动项。
关键点:这一步引入了“人在回路”机制。作者可以审阅并修改这份计划(例如:“这个补充实验来不及做,我们改用理论分析来论证”)。在作者确认计划无误后,起草智能体才会根据计划生成最终的、正式的回复信草稿。

效果评测:不仅文笔好,更能理解你
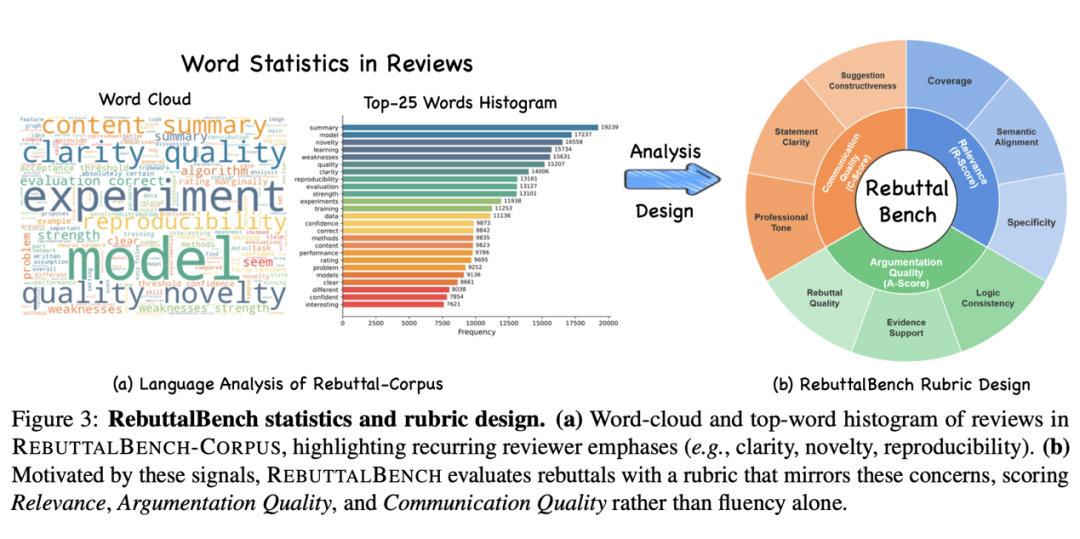
为了客观评估其性能,研究团队构建了 RebuttalBench——一个基于ICLR OpenReview真实数据的专业评测基准。实验结果表明,RebuttalAgent在多方面表现突出:
- 更全面:在覆盖审稿人提出的所有关键关注点上,RebuttalAgent显著优于ChatGPT、Gemini等通用大模型。
- 更可靠:在论证逻辑质量和证据支持度上取得了大幅提升,有效减少了模型“幻觉”(即编造不存在的实验或数据)的情况。
- 更透明:通过提供“行动清单”和“证据链”等中间产物,大大降低了作者梳理思路、组织回复的认知负担。
论文中提供了一个具体的案例研究,清晰地展示了RebuttalAgent的详细输出。可以看到,相比基线模型,RebuttalAgent生成的反驳策略更为详细,待办事项清单也极其具体和可操作。



总结:让AI成为你的“学术辩护助理”
RebuttalAgent的出现,标志着AI辅助科研写作从简单的“文本润色”迈向了深度的“逻辑推理与决策支持”。
它并非旨在取代作者做出最终决定,而是通过提供结构化的证据链和清晰的行动计划,帮助作者在紧张的Rebutta时期保持思路清晰,做出最有力、最有利的学术回应。
从此,面对审稿人的“灵魂拷问”,你将不再是孤军奋战。让RebuttalAgent帮你整理庞杂的文献、梳理回应逻辑,而你只需专注于提供关键的领域反馈,并从它给出的策略中选择最优路径。这是一个典型的开源实战项目如何解决具体科研痛点的优秀范例。
你对这类能提升研究效率的AI工具有什么看法?欢迎在云栈社区相关板块分享你的见解或使用体验。
 发表于 2026-1-29 19:59:16
|
查看: 243|
回复: 0
发表于 2026-1-29 19:59:16
|
查看: 243|
回复: 0
