2026年1月27日,DeepSeek发布了DeepSeek-OCR-2模型。本文将记录在本地环境中部署该模型的完整过程,并对其在不同场景下的OCR识别效果进行简单的测试与评估。
环境准备
1.1、基础配置信息
- 操作系统:Windows 11 专业版(WSL2)
- Python 版本:3.12.9
- GPU:RTX 4090
1.2、构建项目环境
(1)安装 torch 库
安装 torch2.6.0 的命令:
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu126
(2)安装相关库
在 torch 库安装成功后,依次安装下述版本的库。
transformers==4.46.3
tokenizers==0.20.3
einops
addict
easydict
(3)安装 flash-attn 库
flash-attn 库用于模型的加速推理。直接安装该库速度较慢,为了实现快速安装,可以首先下载 whl 文件到本地,下载地址为:Releases · Dao-AILab/flash-attention。
选取的文件为:flash_attn-2.8.3+cu12torch2.6cxx11abiFALSE-cp312-cp312-linux_x86_64.whl。
切换到下载的 whl 文件所在目录,执行下述命令进行安装:
pip install flash_attn-2.8.3+cu12torch2.6cxx11abiFALSE-cp312-cp312-linux_x86_64.whl
模型推理
下载模型文件到本地,地址为:deepseek-ai/DeepSeek-OCR-2 at main
使用 transformers 库推理代码为:
from transformers import AutoModel, AutoTokenizer
import torch
import os
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
model_name = 'model_file'
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name, _attn_implementation='flash_attention_2', use_safetensors=True, trust_remote_code=True)
model = model.eval().cuda().to(torch.bfloat16)
# prompt = "<image>\nFree OCR. "
prompt = "<image>\n<|grounding|>Convert the document to markdown. "
image_file = 'test_img/p1.jpg'
output_path = 'output2'
res = model.infer(tokenizer, prompt=prompt, image_file=image_file, output_path = output_path, base_size = 1024, image_size = 768, crop_mode=True, save_results = True)
简单测试
3.1、PDF 文件
下述是中国知网下载的论文文档,文档解析结果如图 1-5 所示。针对图 1 的文档,题目、摘要、引言、文章编号等部分都准确地识别了出来。但是页眉页脚区域的内容没有识别出来。

图 1:含有页眉页脚的文档识别结果图
针对图 2 带有简单表格的文档,表格标题、表格内容和分布识别非常准确。
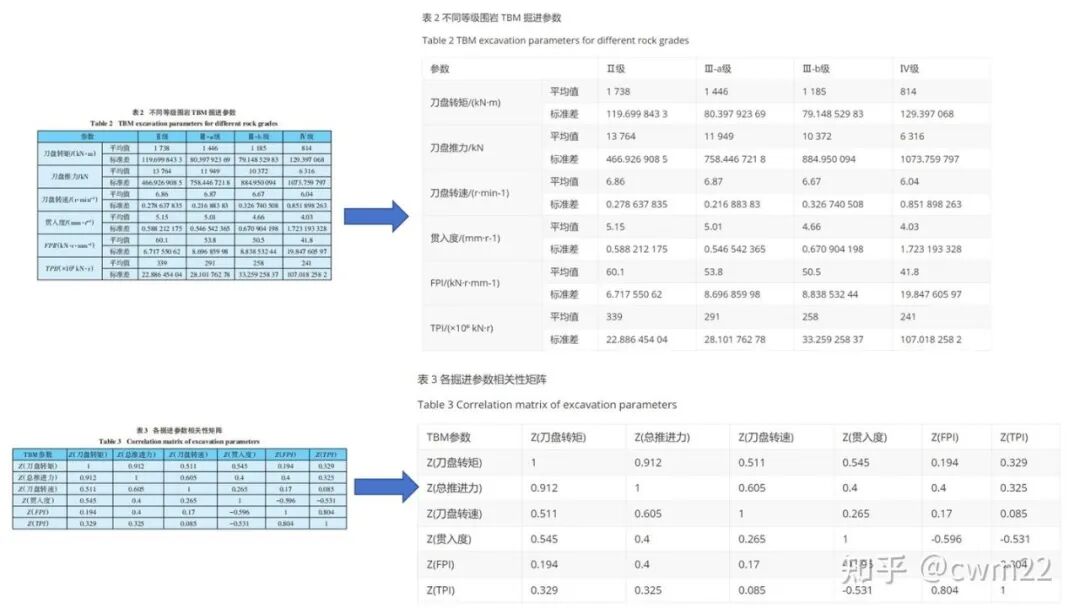
图 2:含有简单表格的文档识别结果图
针对图 3 带有复杂表格的文档,识别效果不佳,最后 1 列识别的内容发生了错乱。
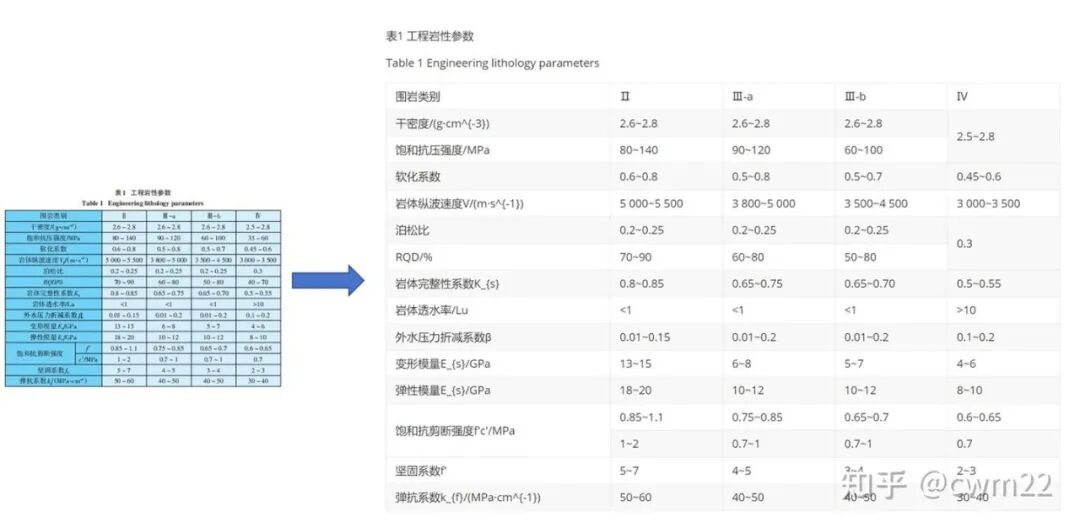
图 3:含有复杂表格的文档识别结果图
针对图 4 带有图片的文档,图片区域可以准确识别出来,效果很好。
图 4:含有图片的文档识别结果图
针对图 5 带有参考文献的文档,参考文献内容、编号识别效果良好。

图 5:参考文献文档识别结果图
3.2、发票
针对如图 6 所示的增值税发票,整体上识别结果良好,尤其是中间的表格布局部分,基本完美还原了发票表格内容。二维码、印章部分都作为图片完美地识别了出来。
存在的一些小问题:
- 主体表格旁纵向的文本内容没有识别出来;
- “密码区”识别为“密码”以及密码的一些字符识别有点问题。

图 6:增值税发票识别效果图
3.3、手写文本
针对图 7 所示的手写文本内容,识别效果非常差。“重要贡献”识别成“梦想是阳光”很离谱,测试了几个手写文本图片,全部正确的一个没有。
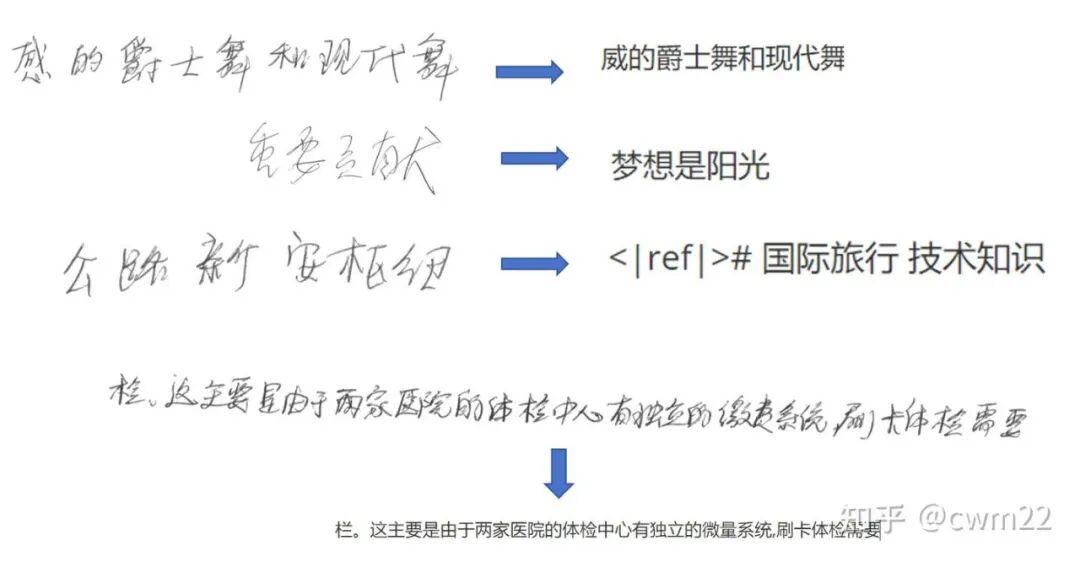
图 7:手写文本识别结果图
3.4、手写公式
针对如图 8 所示的手写公式,只有简单的公式(第 3 个和第 4 个)识别比较准确。
第 1 个公式,人工书写的已经非常规整了,识别的结果效果很差;第 2 个公式,阶乘符号(!)识别为了 1,后两个公式识别的也有问题。对于复杂的手写公式,整体上识别效果不佳。
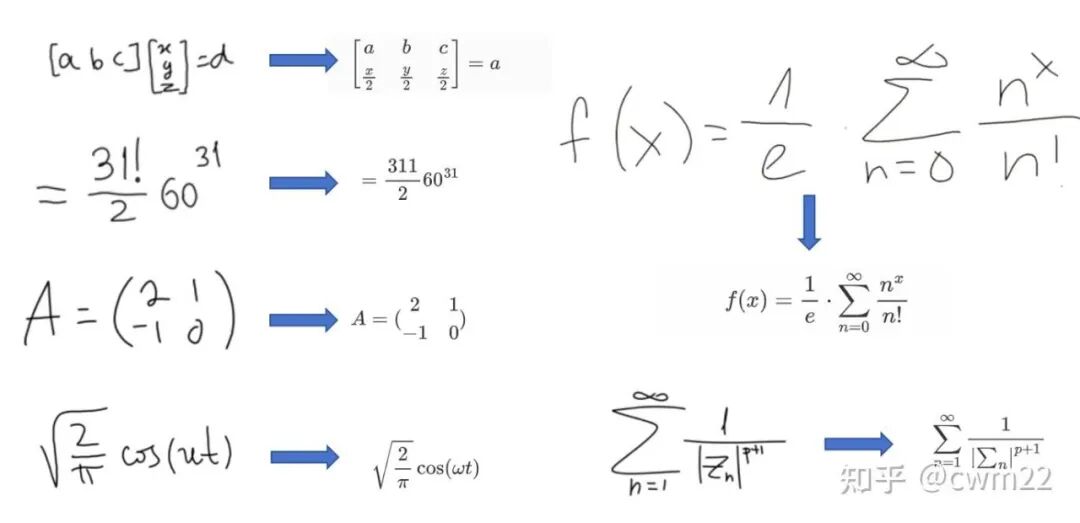
图 8:手写公式识别结果图
3.5、街景图片
针对图 9 所示的简单街景图片,非常清晰的识别没问题。对于有背景干扰的或者稍模糊的都不太行。“二十年老字号南昌小吃”识别为了“=千年老手手前的心”很离谱。

图 9:简单街景图片识别结果
总结
本次在 Windows WSL2 环境下成功部署并测试了 DeepSeek-OCR-2 模型。从实测结果来看,该模型在标准印刷体文档、简单表格、参考文献以及发票等结构化场景下表现出色,识别准确率很高。尤其是在文档转换为 Markdown 格式的任务上,展现了强大的文档理解与结构化能力。
然而,模型在面对复杂表格、手写文本、手写公式以及具有复杂背景的街景文字时,表现仍有较大提升空间。例如,手写体的识别几乎不可用,复杂公式的解析也容易出错。这提示我们在实际应用深度学习 OCR 模型时,需要充分考虑目标场景的适配性。
总体而言,DeepSeek-OCR-2 是一款在特定场景下(尤其是电子文档处理)非常强大的工具,其开源特性也为开发者提供了丰富的自定义和优化可能性。对于有相关需求的开发者,可以在云栈社区等平台交流更多的部署技巧和实战经验。
来源:https://zhuanlan.zhihu.com/p/1999539215457871071
 发表于 2026-1-31 06:58:31
|
查看: 180|
回复: 0
发表于 2026-1-31 06:58:31
|
查看: 180|
回复: 0
