最近OpenClaw的火爆催生了许多衍生项目,其中超轻量级的nanobot 尤为引人注目,项目地址是 https://github.com/HKUDS/nanobot。

nanobot是一个超轻量级的个人AI助手框架,它实现了LLM对话、工具调用、多渠道通信(Discord/飞书)、会话记忆、定时任务和后台子Agent等核心能力。
根据官方文档,其核心Agent代码仅有约3510行,功能上却与OpenClaw的430k+行代码相似,体积小了99%!对于希望理解OpenClaw这类人工智能 Agent设计原理,但又对海量代码望而却步的开发者来说,nanobot无疑是一个极佳的学习和研究样本。项目作者也将其“研究就绪”作为核心卖点之一:

这足以体现作者对代码质量的信心。本文旨在深入解析nanobot的源码,借此探究OpenClaw的设计精髓,并学习其精巧的工程实现。
项目骨架
整体架构
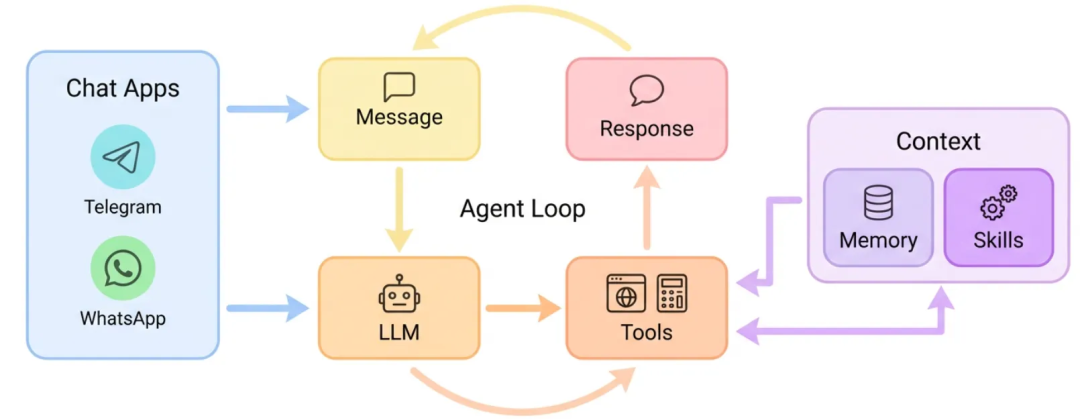
首先,我们通过官方架构图来建立整体认知:
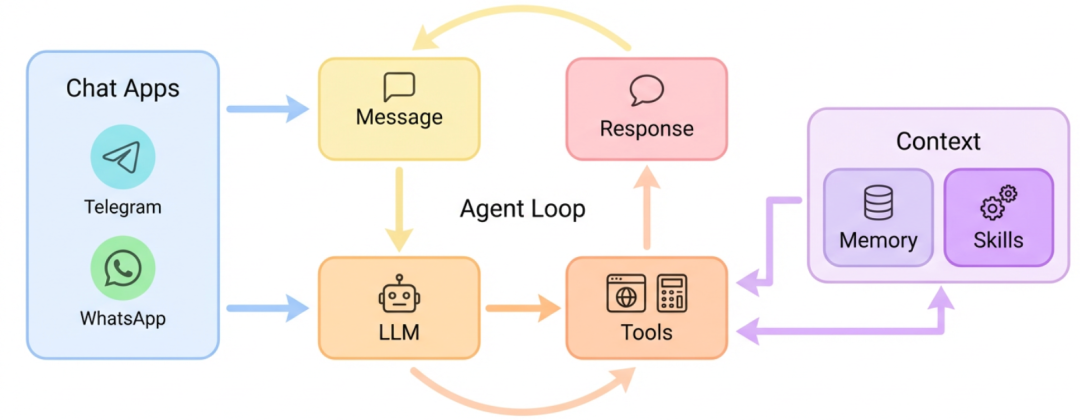
流程非常清晰:用户通过聊天软件发送消息,LLM接收消息后,为完成任务会调用各种工具(如联网搜索、文件操作)。工具执行结果会被拼接到AI的上下文中,LLM据此决定是回复用户还是继续调用工具。这个循环会持续直到问题解决或任务中断。Memory(记忆)和Skills(技能)作为Context(上下文)贯穿整个过程,为LLM提供状态和能力支持。
对应到项目代码的目录结构中,各个包的功能划分如下:

通过包名基本可以猜到其职责,后文会逐一详解。
核心配置文件
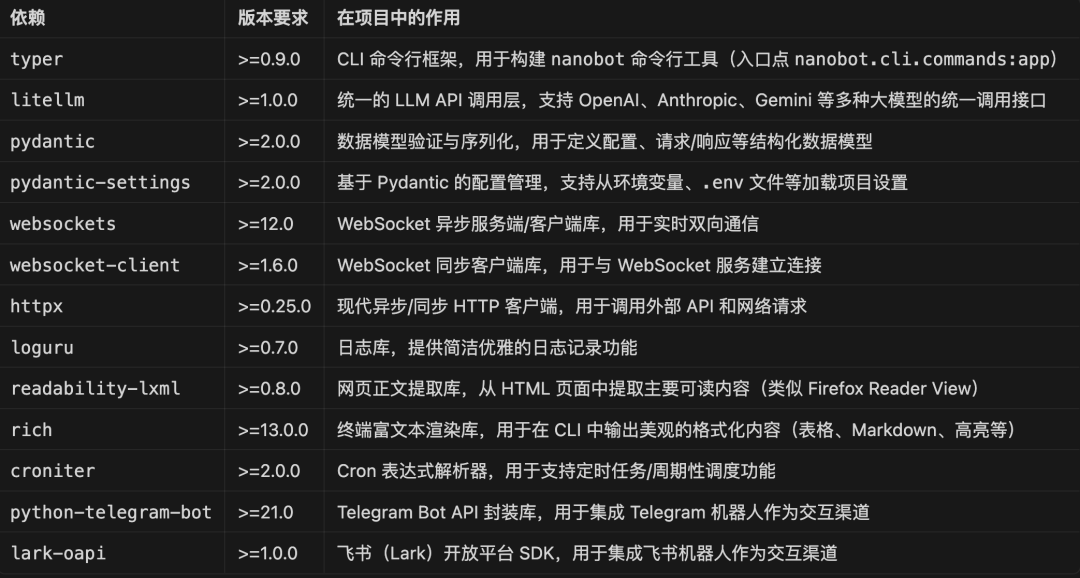
我们先看项目的核心配置文件 pyproject.toml。其依赖项非常精简,都是常用库,这大大降低了学习门槛。
此外,配置中有一行核心内容:
[project.scripts]
nanobot = "nanobot.cli.commands:app"
这表示通过pip或uv安装后,系统会生成一个名为 nanobot 的命令,其入口点位于 nanobot.cli.commands 包下的 app 对象。这个 app 就是整个项目的命令行入口,后文会详细分析。
基建服务
接下来分析项目的几个基础服务模块,主要是 bus(消息总线)和 providers.base,它们定义了消息格式、传输和LLM接口等核心概念。
bus 消息总线
bus/events.py 定义了两个核心消息类:用户发送的 InboundMessage 和AI回复的 OutboundMessage。
bus/queue.py 则定义了两个异步队列及对应的发布/消费方法,代码简洁明了:
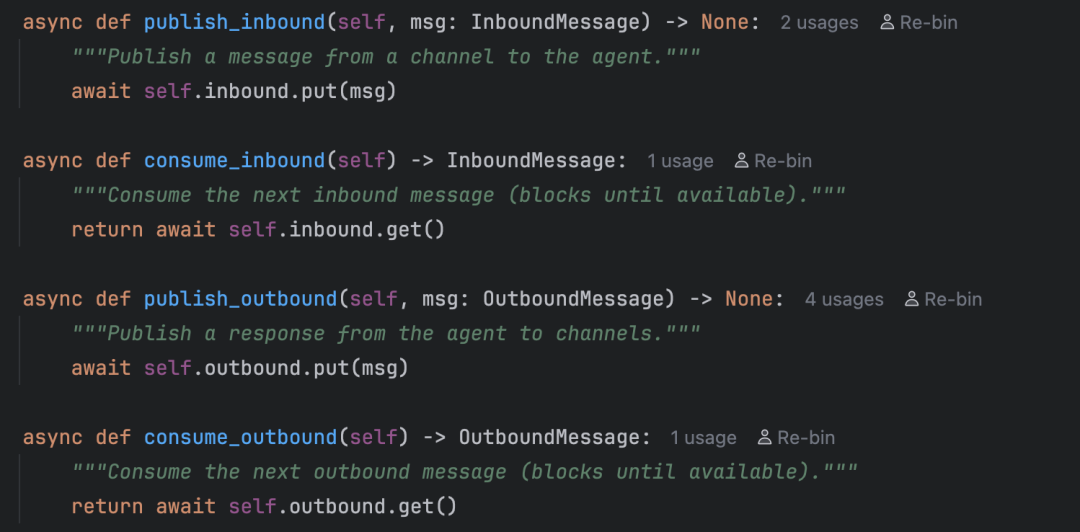
bus/ 消息总线
├── events.py 定义两种消息格式
│ ├── InboundMessage → 进来的消息(用户发的)
│ └── OutboundMessage → 出去的消息(回复给用户的)
└── queue.py MessageBus:两个异步队列 + 订阅分发机制
├── inbound 队列 → 渠道放消息,Agent 取消息
└── outbound 队列 → Agent 放回复,渠道取回复
这种设计的最大优势是实现了解耦。Agent和各聊天渠道不直接通信,所有消息都通过统一的总线。不同渠道(如QQ、飞书)的原始消息格式会被转换为统一的 InboundMessage,Agent无需关心来源。同样,Agent只负责生成 OutboundMessage 并放到总线,由各渠道自行处理发送细节,避免了核心逻辑与渠道API的耦合。
试想没有 OutboundMessage 的混乱场景:
# ❌ 没有 OutboundMessage 的情况
if msg.channel == "telegram":
html = markdown_to_html(final_content)
await telegram_bot.send_message(chat_id=int(msg.chat_id), text=html, parse_mode="HTML")
elif msg.channel == "discord":
await http.post(f"https://discord.com/api/channels/{msg.chat_id}/messages", ...)
elif msg.channel == "feishu":
receive_id_type = "chat_id" if msg.chat_id.startswith("oc_") else "open_id"
await feishu_client.send(...)
elif msg.channel == "whatsapp":
await ws.send(json.dumps({"type": "send", "to": msg.chat_id, ...}))
所有发送逻辑都耦合在Agent核心模块中,每增加一个新渠道就得修改核心代码。有了消息总线,这些问题迎刃而解。
providers.base.py
这个文件定义了 LLMProvider 抽象类,其核心方法是 chat,返回类型为 LLMResponse。这意味着所有要接入的大模型服务都需要继承 LLMProvider 并实现 chat 方法,且响应必须转换为 LLMResponse 类型。
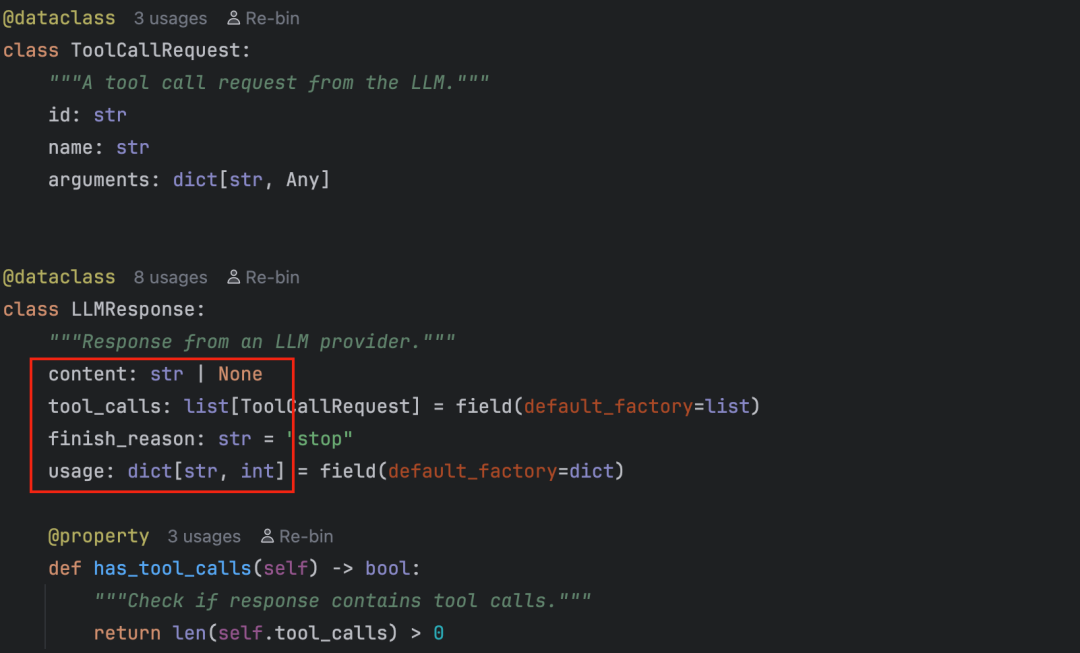
这种抽象设计的好处显而易见:无论接入多少种大模型,都只需要编写新的实现类,上层调用逻辑完全统一。
工具系统
工具是AI与外界交互的手脚。nanobot内置了10个工具,涵盖文件操作、Shell命令、网络搜索、主动发消息、后台子任务、定时任务等能力,全部位于 agent/tools/ 目录下:
agent/tools/
├── base.py # 工具抽象基类(所有工具的模板)
├── registry.py # 工具注册表(管理所有工具)
├── filesystem.py # 文件工具:读、写、编辑、列目录
├── shell.py # Shell 工具:执行命令
├── web.py # 网络工具:搜索、抓取网页
├── message.py # 消息工具:主动给用户发消息
├── spawn.py # 子任务工具:启动后台 Agent
└── cron.py # 定时工具:创建/管理定时任务
base.py 中定义了所有工具的抽象基类 Tool。任何工具都必须提供以下四个部分:
| 属性/方法 |
类型 |
作用 |
name |
属性 |
工具名称,如 "read_file"、"exec" |
description |
属性 |
工具描述,告诉LLM这个工具能做什么 |
parameters |
属性 |
参数定义,用JSON Schema描述,告诉LLM需要哪些参数 |
execute() |
方法 |
实际执行逻辑,接收参数,返回字符串结果 |
除了这些必需接口,Tool 基类还提供了两个通用方法:
to_schema(): 将工具信息转换为OpenAI function calling格式。这份“说明书”让LLM知道有哪些工具可用以及如何使用。validate_params(): 在执行前校验LLM传来的参数是否合法。
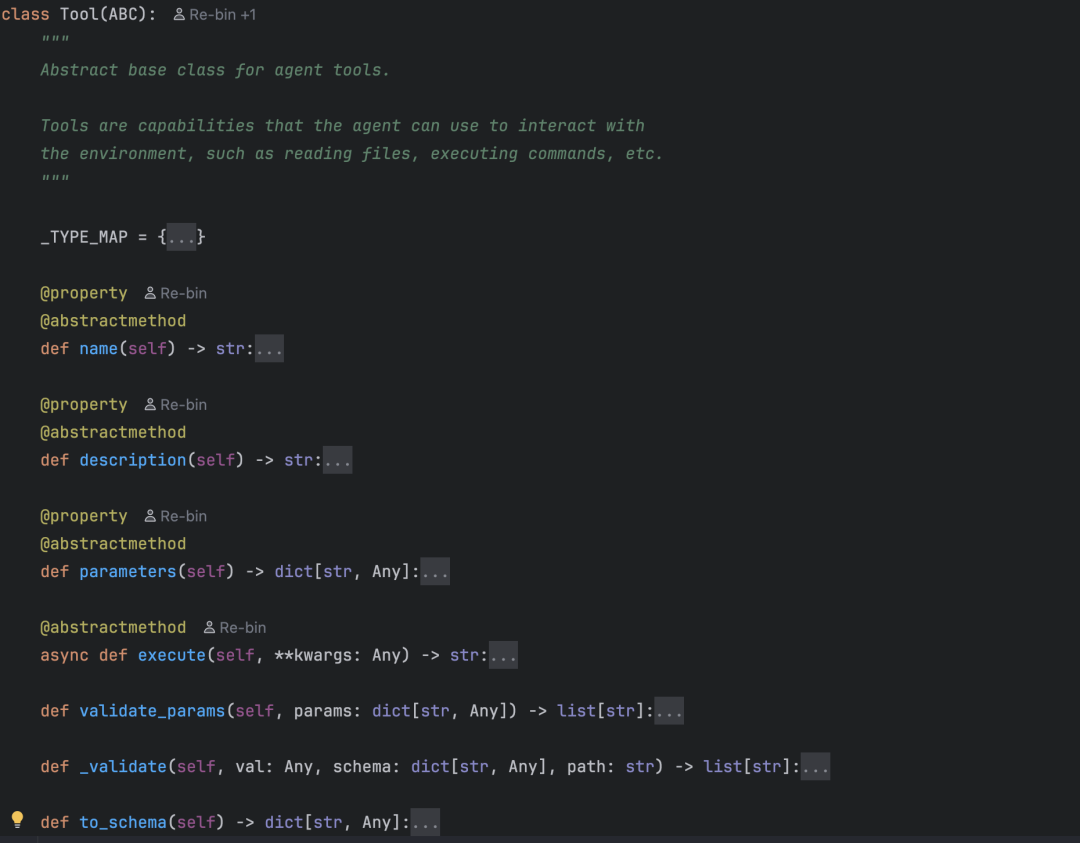
这里有一个关键设计:execute() 方法的返回值统一是字符串。无论工具功能是读文件、执行命令还是搜索网页,最终都返回 str。因为工具执行结果需要拼接回LLM的上下文,统一返回字符串最为简单直接。
有了工具模板,还需要一个中心化的管理器。registry.py 中的 ToolRegistry 就是为此而生,其内部维护了一个 dict[str, Tool] 字典,以工具名称为键。

它有三个核心方法:
register(tool): 注册一个工具到字典中。get_definitions(): 遍历所有工具,调用各自的 to_schema() 方法,生成供LLM使用的工具列表。execute(name, params): 根据工具名找到对应对象,先调用 validate_params() 校验参数,再执行 execute()。
execute() 方法的错误处理也很有借鉴意义:如果工具执行出错,它不会抛出异常,而是返回一个以 "Error:" 开头的字符串。这样LLM收到错误信息后可以自行决定下一步(如重试或告知用户),增强了Agent的鲁棒性。
那么,这些工具是在何时注册到 ToolRegistry 中的呢?答案在 agent/loop.py 的 _register_default_tools() 方法里:
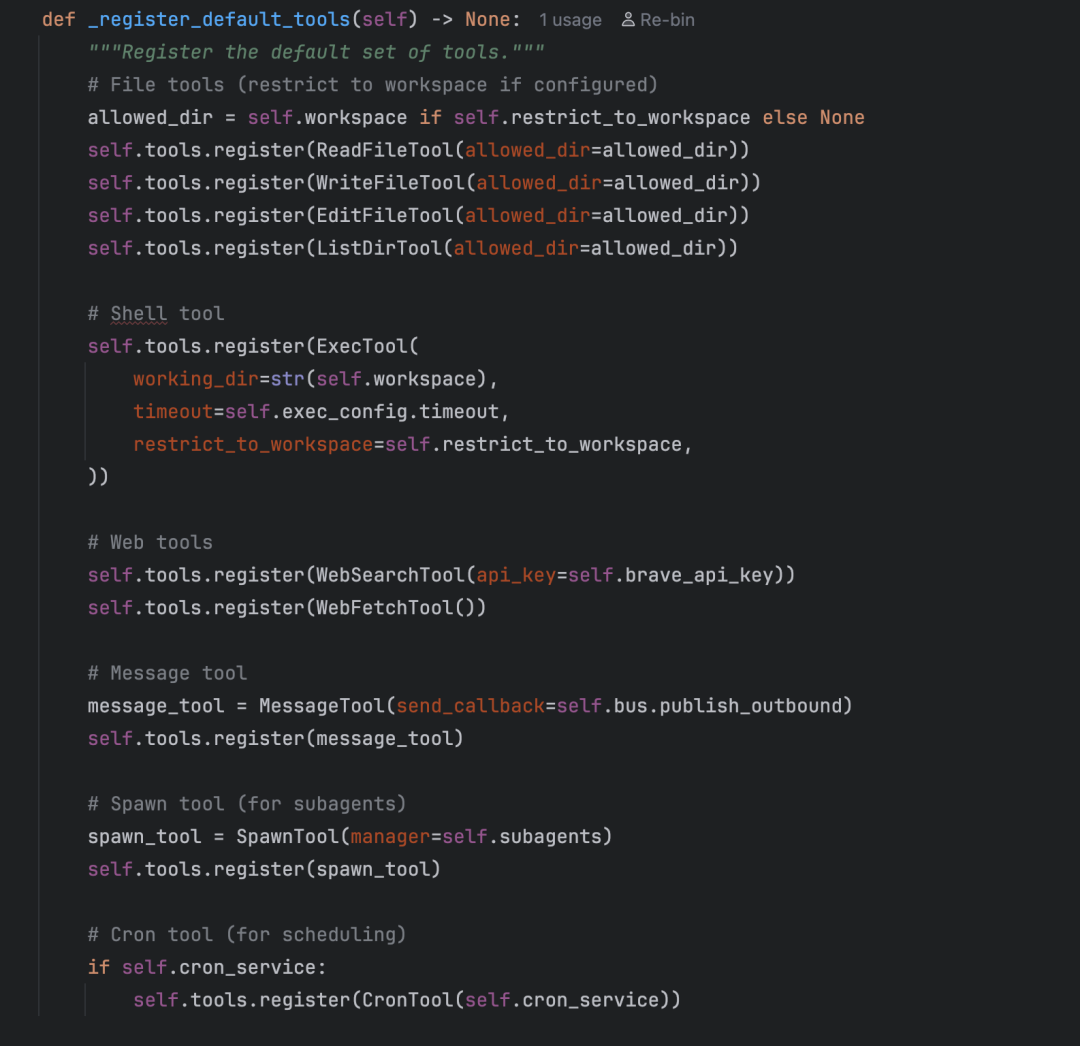
系统初始化时,10个内置工具会被全部注册。至此,工具系统的脉络已清晰:Tool 定义模板 → 具体工具类实现 → ToolRegistry 统一管理 → Agent启动时注册。
LLM Provider
如果说工具是AI的手脚,那么LLM就是AI的大脑。我们已经见过 LLMProvider 抽象类,其唯一实现是 LiteLLMProvider。
为什么只需要一个实现类?因为nanobot借助了 LiteLLM 这个开源库来统一不同大模型(OpenAI、Anthropic、Gemini、DeepSeek、智谱、通义千问等)的API调用。LiteLLMProvider 的核心 chat() 方法流程如下:
第一步:模型前缀处理
LiteLLM约定不同来源的模型需要不同前缀(如 openrouter/, dashscope/)。chat() 方法会根据配置的模型名自动补全前缀。
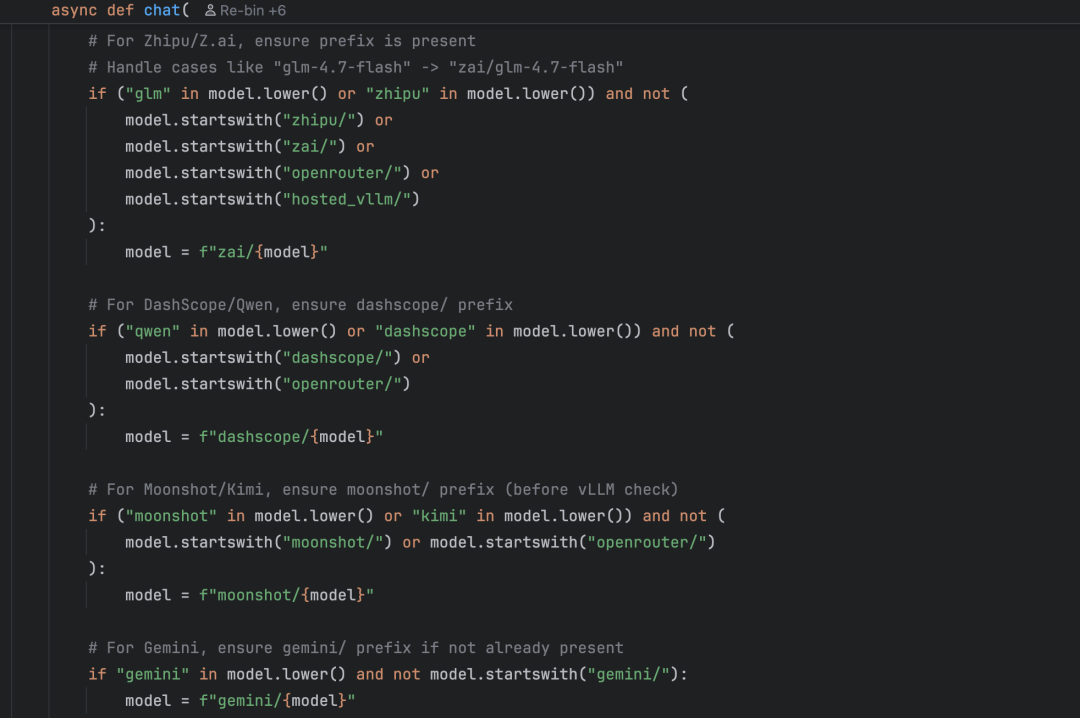
例如,用户在配置中写 "qwen-max",代码会自动转为 "dashscope/qwen-max"。
第二步:调用LiteLLM
前缀处理完后,构建参数并调用LiteLLM的 acompletion 异步接口。如果传入了 tools 参数,会设置 tool_choice = "auto",让LLM自行决定是否调用工具。
第三步:解析响应
_parse_response() 方法将LiteLLM返回的复杂响应格式,解析为统一的 LLMResponse 对象。
上下文构建
每次调用LLM,都需要为其组装完整的上下文,包括身份、记忆、技能和历史对话。这项工作由 ContextBuilder 完成,它依赖 MemoryStore 和 SkillsLoader 两个数据源。
agent/memory.py 中的 MemoryStore 管理Agent的记忆,采用朴素的Markdown文件存储:
- 长期记忆:
workspace/memory/MEMORY.md,记录跨越时间的重要信息。
- 每日笔记:
workspace/memory/YYYY-MM-DD.md,按天记录。
其核心方法 get_memory_context() 会将长期记忆和今日笔记拼接为文本,注入到system prompt中。
agent/skills.py 中的 SkillsLoader 负责加载Agent技能(也是Markdown文件)。技能有两个来源,优先级从高到低:
- workspace技能:用户放在
workspace/skills/ 下的自定义技能。
- 内置技能:项目自带的
nanobot/skills/ 目录下的技能。
加载策略采用了巧妙的渐进式加载以节省Token:
2. Available skills: 只注入摘要
skills_summary = self.skills.build_skills_summary()
`agent/context.py` 中的 `ContextBuilder` 负责最终组装。`build_system_prompt()` 方法按以下顺序构建系统提示词:
1. **核心身份** (`_get_identity()`): 如“你是nanobot”,当前时间、系统信息等。
2. **引导文件** (`_load_bootstrap_files()`): 加载 `AGENTS.md`(行为准则)、`SOUL.md`(人格)、`USER.md`(用户画像)等。
3. **记忆** (`memory.get_memory_context()`): 长期记忆 + 今日笔记。
4. **技能** (`skills`): always技能完整内容 + 其他技能摘要列表。
`build_messages()` 方法则在上述system prompt基础上,加入来自Session的历史对话和当前用户消息,构成最终发送给LLM的messages列表。
## 会话管理
`session/manager.py` 定义了 `Session` 和 `SessionManager`。
- `Session` 代表与某个用户的一次对话,核心是一个消息列表 `messages`。
- `SessionManager` 通过 `session_key`(格式为`渠道:聊天ID`,如`feishu:12345`)来区分和管理不同会话。
其核心逻辑包括内存缓存(避免频繁读盘)和磁盘持久化。每个会话存储为一个 `.jsonl` 文件,每行一条消息。`get_or_create(key)` 方法遵循:先查缓存 → 再查磁盘 → 都没有则新建。
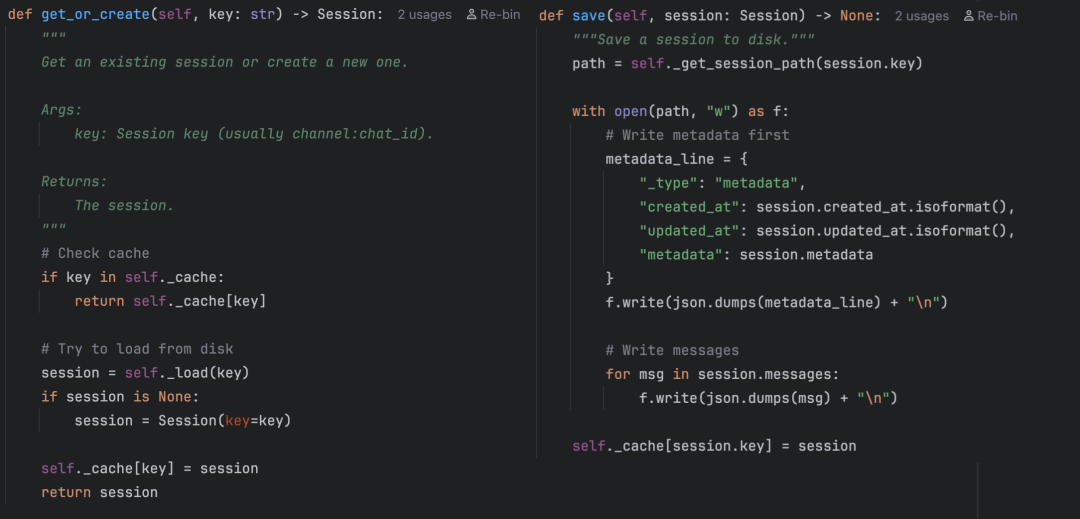
JSONL格式简单且易于追加,虽然当前 `save()` 实现是全量写入而非追加。
## Agent Loop(核心模块)
`agent/loop.py` 中的 `AgentLoop` 是整个项目的“大脑”,它将前述所有组件汇聚一堂。
### 组装零件
看其 `__init__` 方法接收的参数,就能对应到之前的各个模块:`bus`(消息总线)、`provider`(LLM服务)、`workspace`(工作空间)等。初始化过程中,它创建了三个核心成员:
```python
self.context = ContextBuilder(workspace) # 上下文组装
self.sessions = SessionManager(workspace) # 会话管理
self.tools = ToolRegistry() # 工具注册表
随后调用 _register_default_tools() 注册所有默认工具。
运行循环
run() 方法是Agent的主循环。它持续从消息总线的inbound队列中消费 InboundMessage,处理后再将结果作为 OutboundMessage 发布回总线。
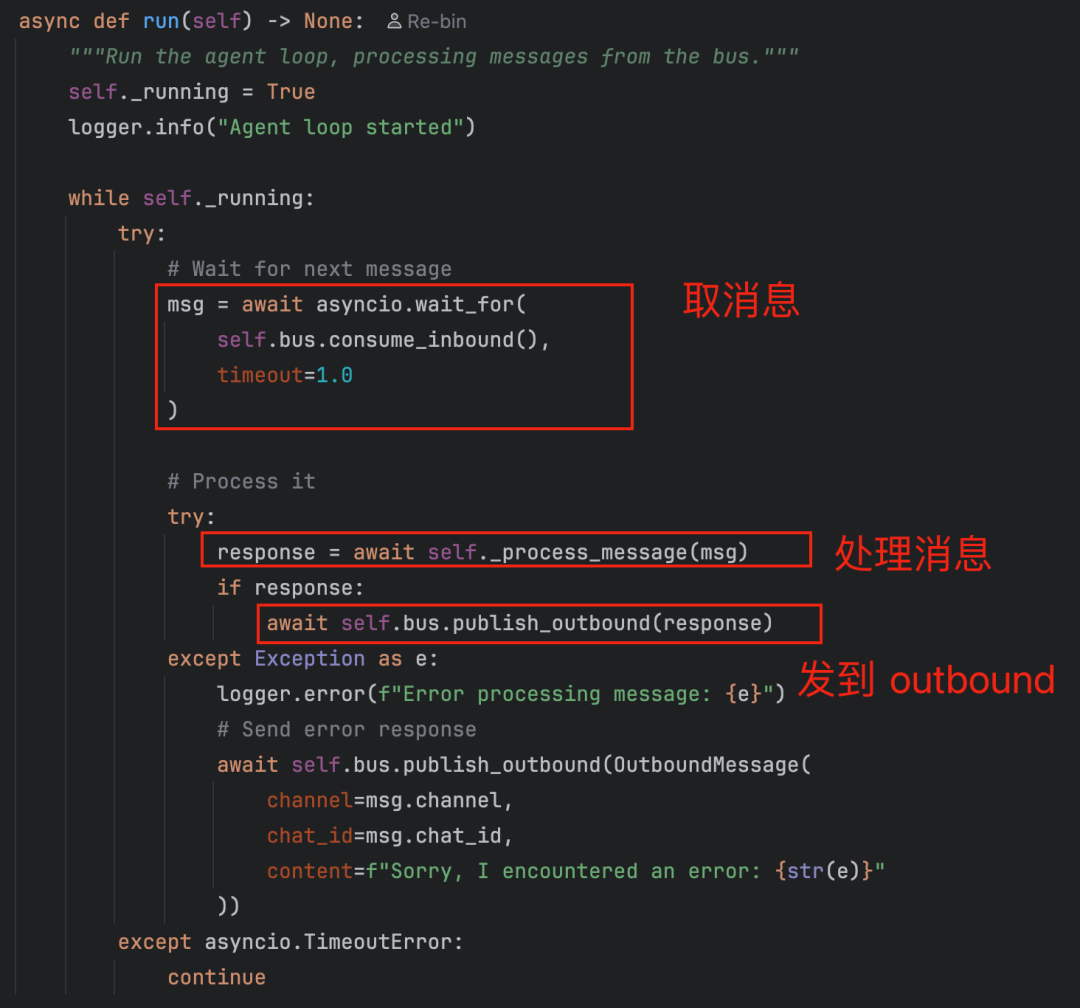
这里使用了 asyncio.wait_for 并设置1秒超时,以实现非阻塞轮询,使得 stop() 方法可以随时中断循环。
核心方法 _process_message()
这是最核心的方法,处理一条用户消息分为四个阶段:
1) 准备会话
session = self.sessions.get_or_create(msg.session_key) # 获取或创建会话
2) 组装上下文
messages = self.context.build_messages(
history=session.get_history(), # 历史对话
current_message=msg.content, # 当前用户消息
channel=msg.channel, # 渠道信息
chat_id=msg.chat_id, # 聊天 ID
)
3) LLM ↔ Tools 循环(ReAct模式)
while iteration < self.max_iterations:
iteration += 1
# 调 LLM
response = await self.provider.chat(
messages=messages,
tools=self.tools.get_definitions(),
)
# LLM 要调用工具?
if response.has_tool_calls:
# 把 LLM 的回复(包含工具调用)追加到 messages
messages = self.context.add_assistant_message(messages, response.content, tool_call_dicts)
# 执行工具,把结果追加到 messages
for tool_call in response.tool_calls:
result = await self.tools.execute(tool_call.name, tool_call.arguments)
messages = self.context.add_tool_result(messages, tool_call.id, tool_call.name, result)
else:
# LLM 不需要工具了,直接输出文本回复
final_content = response.content
break
这个 while 循环就是官方架构图中 Agent Loop 的具体实现。它完美体现了ReAct(Reasoning + Acting)模式:LLM推理决策 → 执行工具动作 → 根据结果再次推理,循环直到任务完成或达到最大迭代次数。
4) 收尾
session.add_message("user", msg.content)
session.add_message("assistant", final_content)
self.sessions.save(session) # 保存会话
return OutboundMessage(channel=msg.channel, chat_id=msg.chat_id, content=final_content)
CLI快捷入口
除了通过消息总线处理消息的 run() 方法,AgentLoop 还提供了 process_direct() 方法。它直接构造 InboundMessage 并调用 _process_message(),绕过了消息总线,主要用于命令行模式 nanobot agent -m "xxx"。
渠道系统
渠道系统负责连接外部聊天平台,处理消息的出入站。
渠道基类 BaseChannel
channels/base.py 定义的 BaseChannel 是所有渠道的抽象基类,要求子类实现 start()、send(msg)、stop() 三个方法。基类还提供了白名单检查 (is_allowed) 和统一的消息预处理方法 (_handle_message)。
渠道管理器 ChannelManager
channels/manager.py 中的 ChannelManager 负责管理所有渠道。它运行一个后台任务,持续从消息总线的outbound队列消费消息,并根据 msg.channel 字段路由到对应渠道的 send() 方法。
msg = await self.bus.consume_outbound() # 从总线取消息
channel = self.channels.get(msg.channel) # 找到对应渠道
await channel.send(msg) # 发送
至此,出站流程完全串联:AgentLoop → bus.publish_outbound() → ChannelManager._dispatch_outbound() → Channel.send() → 用户。
定时任务、心跳与子任务
除了主对话流程,nanobot还提供了一些重要的辅助能力。
定时任务 CronService
定义于 cron/ 目录下。其核心是一个定时器循环,计算并执行到期的 CronJob。巧妙之处在于,任务的执行是通过回调函数 on_job 交给Agent处理的(在 cli/commands.py 中设置),本质上是定时给Agent发送一条消息,完全复用现有的Agent Loop能力。
心跳服务 HeartbeatService
heartbeat/service.py 实现了一个简单实用的功能:每隔30分钟(默认)读取 workspace/HEARTBEAT.md 文件,如果有内容,则将其作为prompt发给Agent处理。这相当于给AI设置了一个定期检查待办事项的“闹钟”。
子任务 SubagentManager
agent/subagent.py 中的 SubagentManager 解决了耗时任务阻塞主对话的问题。用户可以通过 SpawnTool 触发一个独立的后台子Agent来执行长任务。子Agent完成后,通过消息总线通知主Agent,再由主Agent告知用户。
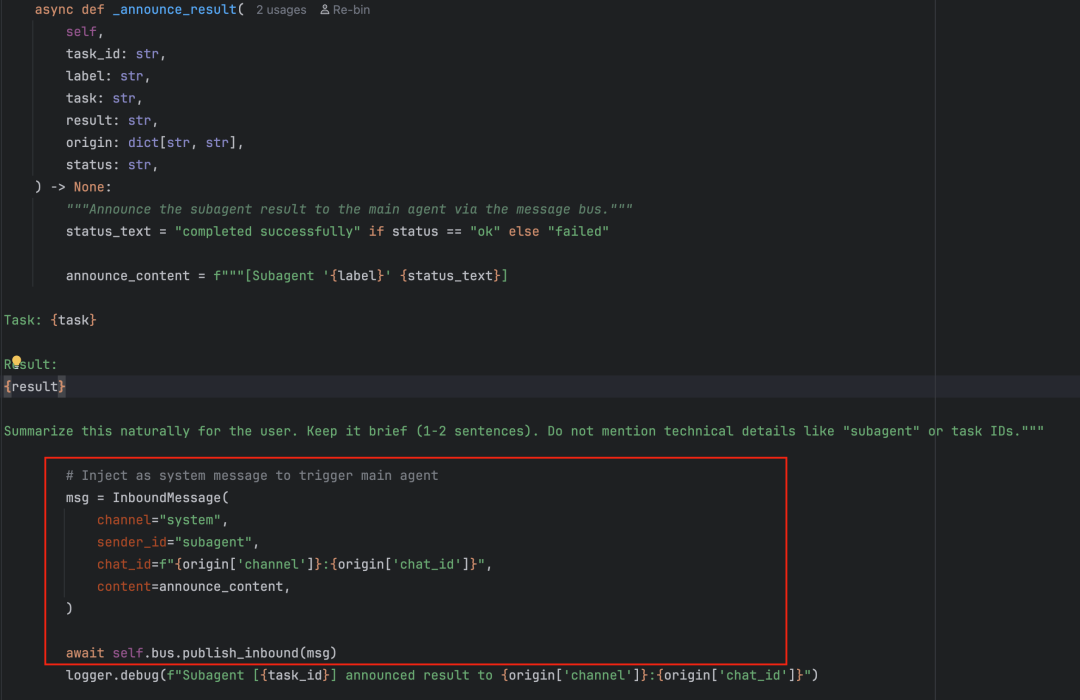
这一设计巧妙地复用了现有的消息总线机制,保持了架构的简洁。
CLI入口与整体组装
cli/commands.py 是项目的组装车间,使用Typer框架定义命令,将所有模块整合为可运行的程序。几个关键命令:
nanobot onboard: 初始化配置和工作空间。nanobot agent -m "xxx": 单次对话模式,展示了最核心的组装逻辑。nanobot gateway: 启动完整网关,这是最复杂的命令,它按顺序创建并启动了所有核心服务:
# 1. 基础组件
config = load_config() # 加载配置
bus = MessageBus() # 消息总线
provider = LiteLLMProvider(...) # LLM 提供商
# 2. 定时任务
cron = CronService(store_path) # 创建 Cron 服务
# 3. Agent Loop(核心)
agent = AgentLoop(bus, provider, workspace, ..., cron_service=cron)
# 4. 设置 Cron 回调(定时任务通过 agent.process_direct() 执行)
async def on_cron_job(job: CronJob) -> str | None:
response = await agent.process_direct(job.payload.message, ...)
return response
cron.on_job = on_cron_job
# 5. 心跳服务
async def on_heartbeat(prompt: str) -> str:
return await agent.process_direct(prompt, session_key="heartbeat")
heartbeat = HeartbeatService(workspace, on_heartbeat=on_heartbeat, ...)
# 6. 渠道管理
channels = ChannelManager(config, bus)
# 7. 全部启动
await cron.start()
await heartbeat.start()
await asyncio.gather(agent.run(), channels.start_all())
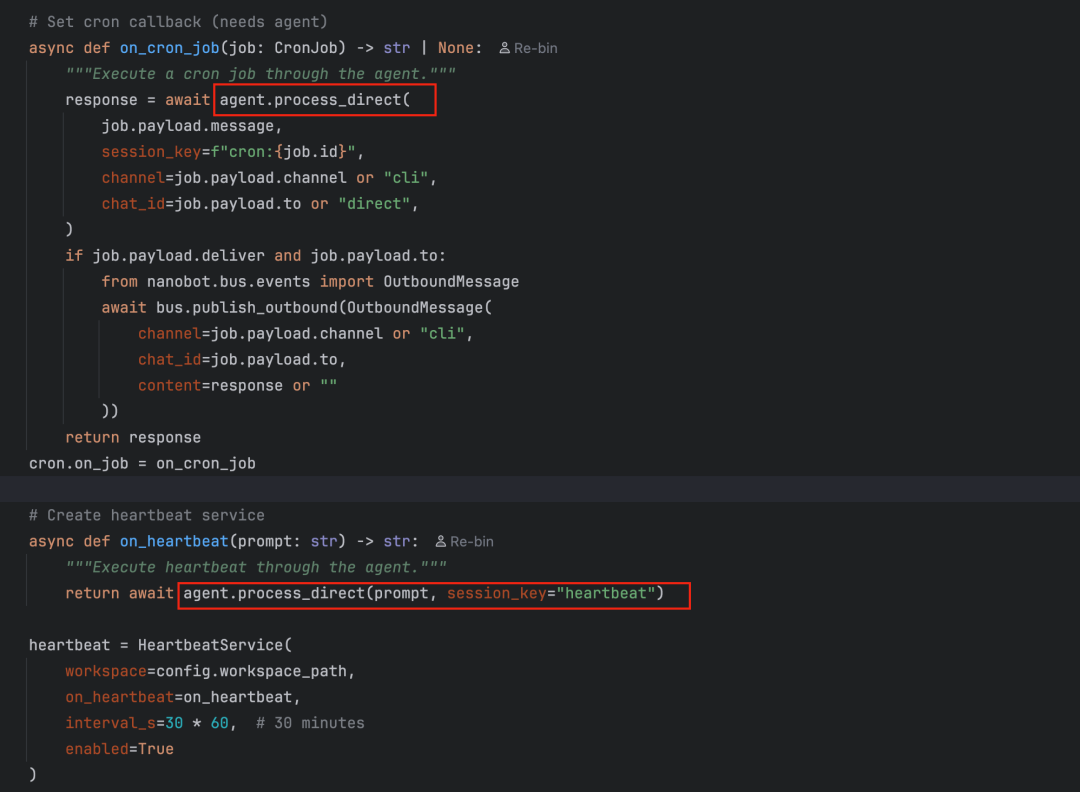
最后的 asyncio.gather() 并发启动了Agent主循环和所有渠道监听。注意,定时任务和心跳服务的回调最终都指向 agent.process_direct(),这再次体现了“一切皆消息”的设计哲学和惊人的代码复用。
全链路回顾
让我们以一个具体场景(用户在飞书上发送“帮我搜一下今天的新闻”)来串联整个流程:
用户在飞书发消息
│
▼
FeishuChannel._on_message() [channels/feishu.py]
│ 解析消息,构造 sender_id、chat_id
▼
BaseChannel._handle_message() [channels/base.py]
│ 权限检查 → 打包成 InboundMessage
▼
bus.publish_inbound(msg) [bus/queue.py]
│ 消息放入 inbound 队列
▼
AgentLoop.run() → bus.consume_inbound() [agent/loop.py]
│ 从队列取出消息
▼
AgentLoop._process_message(msg) [agent/loop.py]
│
├── sessions.get_or_create(msg.session_key) [session/manager.py]
│ 获取会话历史
│
├── context.build_messages(history, msg, ...)[agent/context.py]
│ 组装系统提示词(身份、记忆、技能)+ 历史 + 用户消息
│
├── while 循环开始 ─────────────────────────────
│ │
│ ├── provider.chat(messages, tools) [litellm_provider.py]
│ │ 调用 LLM,返回 LLMResponse
│ │
│ ├── response.has_tool_calls? → Yes
│ │ 执行 web_search 工具,将结果追加回messages
│ │
│ ├── provider.chat(messages, tools) ← 带上搜索结果再问一次
│ │
│ └── response.has_tool_calls? → No
│ final_content = response.content → "以下是今天的新闻..."
│
├── 保存 user 和 assistant 消息到 session
│
└── return OutboundMessage(channel="feishu", chat_id="12345", content=...)
│
▼
bus.publish_outbound(response) [bus/queue.py]
│ 消息放入 outbound 队列
▼
ChannelManager._dispatch_outbound() [channels/manager.py]
│ 根据 channel="feishu" 找到 FeishuChannel
▼
FeishuChannel.send(msg) [channels/feishu.py]
│
▼
用户在飞书收到回复 ✅
一条消息从用户发出,历经渠道层 → 消息总线 → Agent Loop(含LLM与工具循环)→ 消息总线 → 渠道层,最终回到用户。每个组件职责单一,通过消息总线松耦合连接。
结语
通过对 nanobot 这一开源实战项目的源码剖析,我们得以窥见一个现代AI Agent框架的核心设计。它用约3500行Python代码,清晰地实现了LLM调度、工具系统、多渠道通信、记忆、会话、定时任务等完整能力,堪称“麻雀虽小,五脏俱全”。其模块化设计、消息总线解耦、以及高度的代码复用思想,为理解和构建更复杂的Agent系统提供了宝贵的蓝本。希望这篇分析能帮助你更深入地理解AI Agent的工作原理与工程实现。
 发表于 2026-3-19 05:48:32
|
查看: 160|
回复: 0
发表于 2026-3-19 05:48:32
|
查看: 160|
回复: 0
