关键词:MoE 训练、四维并行、DualPipeV、FP8 量化、Python 原生训练栈
大模型训练系统往往像一座封闭工厂:流水线、通信拓扑、专家路由、显存复用、混合精度与检查点恢复都在高速运转,但开发者很难看清齿轮如何咬合。
生产框架性能强,却常被十万行以上的 C++/CUDA 与复杂运行时包裹;轻量代码容易读懂,却难以承载真实 MoE 训练的吞吐压力。
- Efficient, Python-native, end-to-end MoE training in ~10K lines of code.
- Pith-Train 由 CMU 的贡献者开发,基于 DeepSeek 的 DualPipe 构建,DualPipe 提供了原生流水线并行调度方案与示例。我们感谢 CMU 基金会及语言模型(FLAME)中心为 PithTrain 的开发提供算力资源,同时也感谢英伟达 DGX B200 提供的支持。
- 开源代码:https://github.com/mlc-ai/Pith-Train
- 6000 字,阅读 35 分钟,播客 31 分钟
PithTrain 试图打破这个二选一:它用约一万行 Python,把 Pipeline、Expert、FSDP、Context 四维并行,DualPipeV 前后向重叠调度,DeepGEMM FP8 训练,以及 Triton 融合算子组织成一个可以从头读到尾的训练系统。
它的意义不只是“又一个训练框架”,而是展示了高性能训练工程如何在 AI 代码助手时代被重新设计。
本文目录
- 一、快速上手:从安装到跑通一次 MoE 预训练
- 二、项目定位:不是玩具框架,而是“可读的生产训练栈”
- 2.1 PithTrain 要解决的根本矛盾
- 2.2 关键目录的职责
- 三、训练主链路:从 torchrun 到一次参数更新
- 3.1 启动脚本:自动适配单机与 SLURM
- 3.2 launch 函数:三层上下文包住训练生命周期
- 3.3 一次 train_step 里发生了什么
- 四、四维并行:PP、DP、CP、EP 如何被统一成 DeviceMesh
- 4.1 四种并行各司其职
- 4.2 FSDP 与 MoE 参数分片
- 五、DualPipeV:PithTrain 吞吐优化的“交通调度中心”
- 5.1 V 型双向流水线
- 5.2 step 函数中的八步调度
- 5.3 FSDP hook 的手动接管
- 六、五阶段重叠:把一层 Transformer 拆成可调度的流水零件
- 6.1 模型协议先行
- 6.2 五阶段的真实含义
- 6.3 为什么拆成五段
- 七、FP8 训练:DeepGEMM 与 Triton 融合量化
- 7.1 FP8Linear 如何工作
- 7.2 架构感知的量化核
- 八、专家并行 dispatch:用 Triton 把二十多个小操作融合成三枚核
- 8.1 MoE 通信为什么难
- 8.2 O(n) counting sort 替代 O(n log n) argsort
- 九、数据与 checkpoint:训练系统的“地基工程”
- 9.1 mmap 数据读取与上下文并行切片
- 9.2 数据构建:可恢复的多进程分词
- 9.3 checkpoint 的 canonical 格式
- 十、PithTrain 的技术意义与边界
- 10.1 最大价值:把高性能训练系统变成可学习对象
- 10.2 与传统训练栈的差异
- 10.3 当前边界
- 十一、一张文字流程图:PithTrain 如何完成一次训练
- 结语:PithTrain 给训练系统设计带来的启发
一、快速上手:从安装到跑通一次 MoE 预训练
PithTrain 的 README 把环境要求说得很直接:需要 NVIDIA Hopper(SM90)或 Blackwell(SM100)GPU,CUDA 13.0,Python >= 3.12,并使用 uv 管理依赖。最小安装路径如下。
git clone https://github.com/mlc-ai/Pith-Train.git && cd Pith-Train
uv venv
uv pip install .
# 如果是开发者,需要安装开发依赖与源码环境:
uv sync
一次典型的 Qwen3-30B-A3B 从零预训练分为三步。
- 第一步:首先下载并分词 DCLM 预训练语料:
bash examples/build_tokenized_corpus/launch.sh dclm-qwen3。
- 第二步:编辑训练脚本,调整并行规模、batch size、学习率等参数,配置文件位于:
examples/pretrain_language_model/qwen3-30b-a3b/script.py。
- 第三步:启动训练:
bash examples/pretrain_language_model/launch.sh qwen3-30b-a3b。
训练脚本会自动探测 GPU 数量,并兼容单机与 SLURM 多机环境。模型检查点默认写入 workspace 目录,且支持从最新 checkpoint 自动恢复。训练完成后,可以把 PyTorch Distributed Checkpoint 格式导出为 Hugging Face 格式:
bash examples/convert_checkpoint/launch.sh qwen3-30b-a3b
更多模型与转换操作可参考 examples/build_tokenized_corpus/README.md、 examples/pretrain_language_model/ 以及 examples/convert_checkpoint/README.md。
二、项目定位:不是玩具框架,而是“可读的生产训练栈”
2.1 PithTrain 要解决的根本矛盾
PithTrain 在 README 中给自己的定位非常尖锐:Efficient, Python-native MoE training in ~10K lines of code. 它瞄准的不是“如何写一个简化版 Transformer 训练 demo”,而是 MoE 大模型训练中最难同时满足的三个目标:
- 性能接近生产系统:支持 4D 并行、计算通信重叠、FP8 训练、DeepGEMM、FlashAttention、Triton/TileLang 算子。
- 实现足够透明:主体是 Python,仓库规模约一万行,开发者与 AI agent 可以端到端读懂。
- 工程闭环完整:包含数据构建、训练循环、分布式拓扑、模型实现、检查点转换、日志、测试与 benchmark。
换句话说,PithTrain 不是把复杂性藏起来,而是把复杂性整理成可阅读的层次。
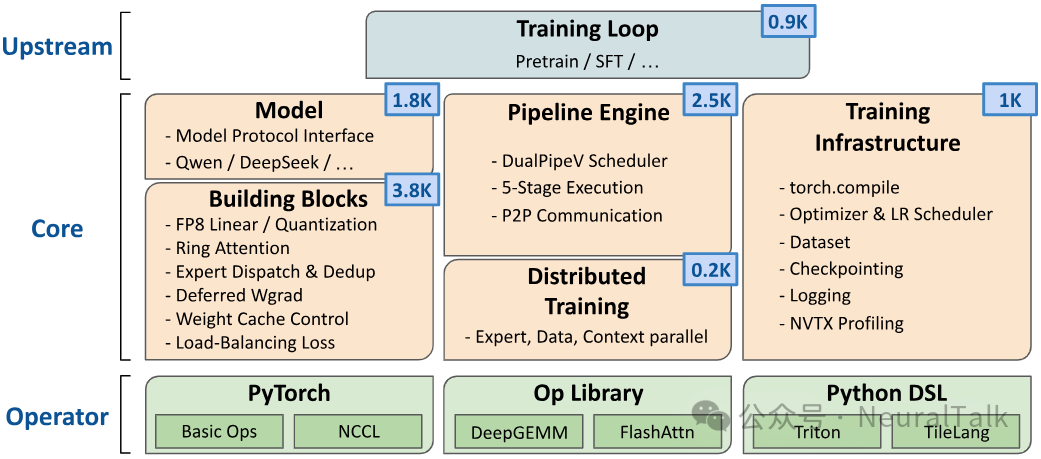
README 中的架构说明把系统分为三层:
- Upstream:面向预训练、SFT 等任务的训练循环。
- Core:模型、构建模块、DualPipeV 流水线、分布式训练、训练基础设施。
- Operators:PyTorch/NCCL、DeepGEMM、FlashAttention,以及 Triton、TileLang 等 Python DSL 算子。
2.2 关键目录的职责
从仓库结构看,PithTrain 的核心代码集中在 pithtrain/ 下:
pithtrain/tasks/pretrain_language_model.py:语言模型预训练入口,组织上下文、加载 checkpoint、执行训练循环。pithtrain/modules/training.py:训练配置、数据集、模型、FSDP、优化器、scheduler 初始化。pithtrain/modules/distributed.py:构建 PP/DP/CP/EP 四维 DeviceMesh。pithtrain/modules/dataset.py:基于 mmap 的打包 token 数据读取与全局 shuffle。pithtrain/dualpipe/dualpipev.py:DualPipeV 流水线调度器,是系统吞吐优化的中枢。pithtrain/dualpipe/overlap.py:把 Transformer 层拆成五阶段,执行前后向细粒度重叠。pithtrain/models/qwen3_30b_a3b.py、 deepseek_v2_lite.py、 gpt_oss.py:具体模型结构。pithtrain/models/interface.py:DualPipeV 要求模型层实现的协议。pithtrain/layers/deepgemm_fp8_linear.py:基于 DeepGEMM 的 FP8 Linear 与 MoE GroupLinear。pithtrain/operators/ep_dispatch.py:专家并行 dispatch 的 Triton 融合实现。pithtrain/operators/deepgemm_fp8_quantize.py:FP8 量化 Triton 核。pithtrain/modules/checkpoint.py:PP 无关的 canonical checkpoint 转换。examples/:数据准备、预训练、checkpoint 转换的可运行脚本。
这套组织方式很有意思:任务层并不直接写复杂算子,算子层也不感知训练循环。复杂训练系统被切成可替换模块,每个模块都有清晰边界。
三、训练主链路:从 torchrun 到一次参数更新
3.1 启动脚本:自动适配单机与 SLURM
预训练入口首先来自 shell 脚本。它根据 SLURM 环境或本机 GPU 自动构造 torchrun 参数。
# 来源:examples/pretrain_language_model/launch.sh
SLURM_NNODES=${SLURM_NNODES:-1}
SLURM_NODEID=${SLURM_NODEID:-0}
SLURM_STEP_GPUS=${SLURM_STEP_GPUS:-${CUDA_VISIBLE_DEVICES:-$(nvidia-smi --query-gpu=index --format=csv,noheader | paste -sd,)}}
LAUNCH_ARGS+=(--nnodes=$SLURM_NNODES --node-rank=$SLURM_NODEID)
LAUNCH_ARGS+=(--nproc-per-node=$(echo "$SLURM_STEP_GPUS" | tr ',' '\n' | wc -l))
LAUNCH_ARGS+=(--rdzv-backend=c10d)
SCRIPT=examples/pretrain_language_model/$1/script.py
torchrun ${LAUNCH_ARGS[@]} $SCRIPT
这段脚本看似普通,实则很关键:PithTrain 把“多机启动复杂性”留在外层 shell 中,而 Python 内部只假设自己运行在标准 torchrun 环境下。
3.2 launch 函数:三层上下文包住训练生命周期
真正的 Python 训练入口在 pithtrain/tasks/pretrain_language_model.py。它通过 ExitStack 依次建立日志、分布式、训练上下文,然后恢复 checkpoint 并进入训练循环。
# 来源:pithtrain/tasks/pretrain_language_model.py
@shutdown.record
def launch(cfg: PretrainLanguageModelCfg) -> None:
"""Launch the pretraining of a language model."""
with ExitStack() as stack:
ctx = PretrainLanguageModelCtx()
stack.enter_context(logging_context(cfg, ctx))
stack.enter_context(distributed_context(cfg, ctx))
stack.enter_context(training_context(cfg, ctx))
logger = ctx.logging.stdout
logger.info("launch(cfg=%s)" % cfg)
load_checkpoint(cfg, ctx)
raise_if_dataset_insufficient(cfg, ctx)
while ctx.training.step < cfg.training.max_steps:
train_step(cfg, ctx)
这是一种非常“Pythonic”的系统设计:
日志、分布式初始化、模型构建、数据集构建、优化器构建都被包进上下文管理器中。好处是生命周期清晰,异常路径也更容易统一处理。
3.3 一次 train_step 里发生了什么
train_step 是系统行为的缩影:取 batch、跑 DualPipeV、缩放梯度、裁剪梯度、optimizer step、scheduler step、记录日志、保存 checkpoint。
# 来源:pithtrain/tasks/pretrain_language_model.py
def train_step(cfg: PretrainLanguageModelCfg, ctx: PretrainLanguageModelCtx) -> None:
model = ctx.training.model
optimizer = ctx.training.optimizer
scheduler = ctx.training.scheduler
model.train()
accumulate_steps = global_batch_size // (micro_batch_size * dp_size * ep_size)
global_tokens, global_labels = get_global_batch(cfg, ctx, device)
loss, _ = model.step(
global_tokens,
num_chunks=accumulate_steps,
criterion=criterion,
labels=(global_labels,),
return_outputs=False,
)
if accumulate_steps > 1:
scale = 1.0 / accumulate_steps
for p in model.parameters():
if p.grad is not None:
p.grad.mul_(scale)
gradient_norm = clip_grad_norm_(model, max_norm=1.0, norm_type=2)
optimizer.step()
scheduler.step()
optimizer.zero_grad(set_to_none=True)
注意这里的 model 不是普通 Transformer,而是 DualPipeV 包装后的流水线模型。也就是说,训练循环不再直接调用 model(input),而是 把 batch 切成多个 micro-batch chunk,交给调度器安排前向、反向、通信、权重梯度计算的交错执行。
四、四维并行:PP、DP、CP、EP 如何被统一成 DeviceMesh
4.1 四种并行各司其职
PithTrain 支持的并行维度包括:
- PP,Pipeline Parallelism:把层切到不同 GPU 阶段。
- DP,Data Parallelism:复制模型或分片模型处理不同样本。
- CP,Context Parallelism:沿序列长度切分,用 ring attention 交换 KV。
- EP,Expert Parallelism:把 MoE 专家分布到不同 GPU。
这些并行不是临时拼接,而是通过 PyTorch DeviceMesh 统一表达。
# 来源:pithtrain/modules/distributed.py
def setup_device_mesh(cfg: DistributedCfg, ctx: DistributedCtx) -> None:
ctx.ep_size = cfg.expert_parallel_size
ctx.pp_size = cfg.pipeline_parallel_size
ctx.cp_size = cfg.context_parallel_size
ctx.dp_size = ctx.world_size // (ctx.ep_size * ctx.pp_size * ctx.cp_size)
kwargs = dict()
kwargs["device_type"] = "cuda"
kwargs["mesh_shape"] = (ctx.pp_size, ctx.dp_size, ctx.cp_size, ctx.ep_size)
kwargs["mesh_dim_names"] = ("pp", "dp", "cp", "ep")
ctx.device_mesh = torch.distributed.init_device_mesh(**kwargs)
ctx.dp_rank = ctx.device_mesh.get_local_rank("dp")
ctx.pp_rank = ctx.device_mesh.get_local_rank("pp")
ctx.cp_rank = ctx.device_mesh.get_local_rank("cp")
ctx.ep_rank = ctx.device_mesh.get_local_rank("ep")
这里有一个工程细节很重要:mesh 形状是 (PP, DP, CP, EP), 注释中说明 EP 和 CP 被放在内层,是为了让频繁通信尽量落在 NVLink 域内。 也就是说,拓扑布局不是抽象数学,而是直接服务通信性能。
4.2 FSDP 与 MoE 参数分片
在 training.py 中,PithTrain 对 MoE 专家参数和普通参数采用不同 FSDP mesh:
# 来源:pithtrain/modules/training.py
def apply_fsdp(model, mesh: torch.distributed.DeviceMesh):
moe_fsdp_mesh = mesh["dp", "cp"]._flatten()
other_fsdp_mesh = mesh["dp", "cp", "ep"]._flatten()
for i in range(2):
for layer in model[i].layers.values():
if hasattr(layer.mlp, "experts"):
fully_shard(
layer.mlp.experts,
mesh=moe_fsdp_mesh,
reshard_after_forward=False,
mp_policy=mp,
)
fully_shard(layer, mesh=other_fsdp_mesh, reshard_after_forward=False, mp_policy=mp)
这段逻辑揭示了 PithTrain 对 MoE 的理解:专家参数已经按 EP 分布,因此专家本体再按 DP/CP 切分;而非专家参数则可以跨 DP/CP/EP 一起分片。这样避免重复切同一个维度,也让专家并行和 FSDP 的职责不冲突。
五、DualPipeV:PithTrain 吞吐优化的“交通调度中心”
5.1 V 型双向流水线
pithtrain/dualpipe/dualpipev.py 明确说明它基于 DeepSeek DualPipe 思想,并扩展了五阶段重叠、FSDP2 集成、FP8 权重缓存和预分配中间张量。
DualPipeV 的核心价值可以用一个比喻解释:
- 传统流水线像单向车道,前向车辆先全部开过去,反向车辆再开回来,中间会产生大量空泡;
- DualPipeV 则像双向高架,把前向、反向、通信、权重梯度计算插入到不同时间槽里,尽量让 GPU 不空等。
5.2 step 函数中的八步调度
DualPipeV.step() 是调度器的核心。它要求 num_chunks >= pp_size * 2,然后执行八段调度:预热前向、双阶段前向、B/W/F 交错、主循环、收尾反向、zero-bubble 权重梯度等。
# 来源:pithtrain/dualpipe/dualpipev.py
def step(
self,
*inputs: Optional[torch.Tensor],
num_chunks: int = 0,
criterion: Optional[Callable] = None,
labels: List[Optional[torch.Tensor]] = [],
return_outputs: bool = False,
):
assert num_chunks > 0 and num_chunks >= pp_size * 2
self._reset_states()
if FP8WeightCacheControl.enabled:
FP8WeightCacheControl.step()
self._ensure_intermediate_tensors_allocated(num_chunks)
if self.is_first_pp_rank:
self.input_chunks = (scatter(inputs, num_chunks, self.batch_dim), [])
self.labels = scatter(labels, num_chunks, self.batch_dim)
self.criterion = criterion
# Step 1: nF0
# Step 2: nF0F1
# Step 3: nB1W1F1
# Step 4: nF0B1F1B0
# Step 5: nB1F1B0
# Step 6: nB1B0
# Step 7: nWB0
# Step 8: nW
在完整源码中,这些注释对应大量 _forward_chunk、 _backward_chunk、 _forward_backward_chunk 与 _weight_chunk 调用。真正的突破点不在“写了循环”,而在于它把每个 micro-batch 的不同阶段排成一张时间表,最大化重叠。
5.3 FSDP hook 的手动接管
DualPipeV 还处理了一个很底层的工程问题:流水线中反复调用自定义 backward,如果让 FSDP 默认 hook 每次都触发,会产生额外 CPU 开销。因此代码先抑制 FSDP root post-backward callback,循环结束后再手动调用。
# 来源:pithtrain/dualpipe/dualpipev.py
for module in self.module:
if isinstance(module, FSDPModule):
module.set_is_last_backward(False)
module.set_reshard_after_backward(False)
module.set_requires_gradient_sync(False)
if not self.forward_only:
fully_shard.state(module)._state_ctx.post_backward_final_callback_queued = True
这类代码体现了 PithTrain 不是“只会调用 PyTorch API”的上层框架,而是深入理解了 FSDP 执行时机、梯度同步与流水线调度之间的冲突。
6.1 模型协议先行
为了让不同模型都能进入 DualPipeV,PithTrain 定义了协议接口。每个 decoder layer 需要提供三个关键方法: forward_attn、 forward_mlp、 forward_aggregate。
# 来源:pithtrain/models/interface.py
class DecoderLayerProtocol(Protocol):
def forward_attn(self, hidden_states: torch.Tensor) -> ForwardAttnOutput:
"""LN + Attn + LN + Expert selection."""
def forward_mlp(
self,
gathered_tokens: torch.Tensor,
expert_idxs: Optional[torch.Tensor] = None,
expand_idx: Optional[torch.Tensor] = None,
) -> torch.Tensor:
"""MLP forward."""
def forward_aggregate(
self,
moe_outs: torch.Tensor,
moe_local_idxs: Optional[torch.Tensor],
topk_weight: Optional[torch.Tensor],
residual: torch.Tensor,
) -> torch.Tensor:
"""Weighted expert output + residual connection."""
这使得 Qwen、DeepSeek、GPT-OSS 等模型虽然结构不同,但只要满足协议,就能复用同一个流水线调度器。
6.2 五阶段的真实含义
dualpipev.py 开头直接列出了五阶段映射:
- Attention:LN + Attention + LN + Expert selection
- Dispatch:专家并行 all-to-all dispatch
- MLP:专家或普通 MLP 计算
- Combine:专家并行 all-to-all combine
- Aggregate:加权专家输出与残差连接
overlap.py 则负责把前向模块 0 和反向模块 1 交织起来。
# 来源:pithtrain/dualpipe/overlap.py
def overlapped_forward_backward(
module0: ModelProtocol,
inputs0: List[torch.Tensor],
criterion0: Optional[Callable],
labels0: Optional[List[torch.Tensor]],
intermediate_tensors0: IntermediateTensors,
module1: ModelProtocol,
loss1: Optional[torch.Tensor],
outputs1: Optional[List[torch.Tensor]],
output_grads1: Optional[List[torch.Tensor]],
intermediate_tensors1: IntermediateTensors,
comm_stream: Optional[torch.cuda.Stream],
ep_group: Optional[torch.distributed.ProcessGroup] = None,
):
# Interleaves forward stage1/2/3/4/5 with backward stage5/4/3/2/1
在主循环里,代码会交错执行 stage5_b、 stage4_b、 stage1_f、 stage2_f、 stage3_b、 stage3_w、 stage3_f 等函数。可以把它理解为:
- 当一批 token 正在等专家通信时,另一批 token 的 attention 或 backward 可以先跑;
- 当某个阶段需要通信流等待时,计算流继续推进别的阶段。
6.3 为什么拆成五段
MoE 层的瓶颈往往不只在 GEMM,而在“路由后的数据搬运”。如果把一层 Transformer 当成一个不可分割的大黑盒,那么通信只能卡在前后向之间; 拆成五段后,dispatch/combine 通信就能与 attention、MLP、backward 部分重叠。PithTrain 的设计重点正是把“通信等待”变成“可被其他计算覆盖的间隙”。
七、FP8 训练:DeepGEMM 与 Triton 融合量化
7.1 FP8Linear 如何工作
pithtrain/layers/deepgemm_fp8_linear.py 实现了可替换 nn.Linear 的 FP8 版本。权重仍以 BF16 保存,每次前向动态量化为 FP8;开启缓存后,同一个 pipeline step 内多个 micro-batch 可以复用量化权重。
# 来源:pithtrain/layers/deepgemm_fp8_linear.py
class FP8Linear(nn.Linear):
"""
Drop-in replacement for ``nn.Linear`` using FP8 GEMM via DeepGEMM.
"""
def _get_quantized_weight(self):
ver = FP8WeightCacheControl._version
if FP8WeightCacheControl.enabled and self._wq_version == ver:
return self._wq_cache
result = fused_blockwise_transpose_cast_to_fp8(self.weight)
if FP8WeightCacheControl.enabled:
self._wq_cache = result
self._wq_version = ver
return result
def forward(self, input: torch.Tensor) -> torch.Tensor:
quantized_weight = self._get_quantized_weight()
weight_fp8, scale_weight, weight_t_fp8, scale_weight_t = quantized_weight
input_2d = input.flatten(0, -2)
output_2d, _, _ = _fp8_linear_fwd(
input_2d, self.weight, weight_fp8, scale_weight, weight_t_fp8, scale_weight_t
)
return output_2d.view(*input.shape[:-1], self.weight.shape[0])
这里的设计兼顾了数值与性能:参数主副本保持 BF16,GEMM 输入以 FP8 执行,scale 按块记录,反向中也使用 FP8 GEMM 计算 dgrad 与 wgrad。
7.2 架构感知的量化核
deepgemm_fp8_quantize.py 展示了 PithTrain 对硬件差异的处理:Blackwell 使用 E8M0 power-of-2 scale,Hopper 使用 FP32 scale。量化核把 pad、abs、amax、scale、cast 融合成单个 Triton kernel,减少中间读写。
# 来源:pithtrain/operators/deepgemm_fp8_quantize.py
@triton.jit
def _compute_fp8_scale(amax, SCALING_MODE: tl.constexpr):
FP8_MAX_RCP: tl.constexpr = 1.0 / 448.0
amax_clamped = tl.maximum(amax.to(tl.float32), 1e-4)
scale_input = amax_clamped * FP8_MAX_RCP
if SCALING_MODE == "e8m0":
scale_e8m0_biased = tl.inline_asm_elementwise(
asm="cvt.rp.satfinite.ue8m0x2.f32 $0, 0.0, $1;",
constraints="=h,r",
args=[scale_input],
dtype=tl.uint16,
is_pure=True,
pack=1,
).to(tl.uint8)
scale_fp = (scale_e8m0_biased.to(tl.int32) << 23).to(tl.float32, bitcast=True)
else:
bits = scale_input.to(tl.int32, bitcast=True)
mantissa = bits & 0x007FFFFF
scale_fp = ((bits & 0x7F800000) + tl.where(mantissa != 0, 0x00800000, 0)).to(
tl.float32, bitcast=True
)
这段代码的核心不是“用了 FP8”,而是把 scale 选择做成架构感知路径,并尽可能使用精确的 2 次幂缩放,使量化/反量化乘法更稳定、更便于硬件执行。
八、专家并行 dispatch:用 Triton 把二十多个小操作融合成三枚核
8.1 MoE 通信为什么难
MoE 路由后,每个 token 可能被送到多个专家,而专家分布在不同 GPU 上。朴素实现需要 scatter、argsort、nonzero、searchsorted、repeat_interleave 等一串 PyTorch 操作。 这些操作单个看不重,但在小 batch、高频训练中会带来大量 kernel launch 和同步开销。
PithTrain 的 ep_dispatch.py 直接在文件注释中说明: 它用三个 Triton kernel 替代约 22 个小 PyTorch kernel。
# 来源:pithtrain/operators/ep_dispatch.py
"""
Fused Triton kernels for expert-parallel dispatch with token deduplication.
Replaces ~22 small PyTorch kernel launches ... with three Triton kernels:
Kernel 1: Atomic-free parallel bincount
Kernel 2: reduce + prefix sum + metadata construction
Kernel 3: dedup scatter + counting sort + expand_idx
"""
8.2 O(n) counting sort 替代 O(n log n) argsort
核心入口是 fused_dedup_prepare_dispatch。它先统计每个专家、每个 EP rank 的 token 数量,再构造 prefix sum 和 send metadata,最后完成去重 scatter 与 counting sort。
# 来源:pithtrain/operators/ep_dispatch.py
def fused_dedup_prepare_dispatch(
topk_ids: torch.Tensor,
num_experts: int,
ep_size: int,
experts_per_rank: int,
):
m, k = topk_ids.shape
# Kernel 1: atomic-free bincount with per-CTA private histograms
_dedup_bincount_kernel[(num_ctas,)](...)
# Kernel 2: reduce histograms, prefix sums, send_meta
_reduce_and_prefix_sum_kernel[(1,)](...)
# Kernel 3: dedup scatter + counting sort + expand_idx
_dedup_scatter_expand_kernel[grid](...)
这里的算法改进很明确:
- 用 counting sort 替代 argsort,复杂度从
O(n log n) 变成 O(n)。
- 用查表替代 searchsorted。
- 用预分配输出替代动态 nonzero。
- 用
tl.histogram 避免全局 atomic bincount 冲突。
- 把 dedup count 塞进 metadata all-to-all,减少通信轮次。
这体现了 PithTrain 的底层优化风格:不是盲目写 CUDA,而是在 Python 生态的 Triton 中把已知瓶颈压成更少、更大的融合核。对于想深入 开源实战 的开发者来说,这类算子融合思路非常值得参考。
九、数据与 checkpoint:训练系统的“地基工程”
9.1 mmap 数据读取与上下文并行切片
pithtrain/modules/dataset.py 使用 NumPy mmap 读取打包 token。每个样本的 tokens 和 labels 只相差一个位置,这符合自回归语言模型训练。
# 来源:pithtrain/modules/dataset.py
class MemmapDataset:
def __getitem__(self, idx: int):
start = idx * self.sequence_length
end = start + self.sequence_length
tokens = torch.tensor(self.tokens[start:end])
labels = torch.tensor(self.tokens[start + 1 : end + 1])
return tokens, labels
def get_chunk(self, idx: int, seq_offset: int, seq_length: int):
start = idx * self.sequence_length + seq_offset
tokens = torch.tensor(self.tokens[start : start + seq_length])
labels = torch.tensor(self.tokens[start + 1 : start + seq_length + 1])
return tokens, labels
get_chunk 尤其重要:当 CP 大于 1 时,每个 rank 只读取自己负责的序列片段,避免先读完整 sequence 再切片造成不必要的 CPU 内存与 PCIe 传输。
9.2 数据构建:可恢复的多进程分词
数据准备入口在 build_tokenized_corpus.py。它支持 JSONL 和 zstd 压缩 JSONL,按文件分配任务,多进程 tokenize,并把 token IDs 写成连续 NumPy 数组。
# 来源:pithtrain/tasks/build_tokenized_corpus.py
class Writer:
def append(self, tokens: np.ndarray) -> None:
self.tokens.append(tokens)
self.offset += tokens.shape[0]
self.splits.append(self.offset)
def flush(self) -> None:
tokens = np.concatenate(self.tokens, axis=0)
splits = np.array(self.splits, dtype=np.uint64)
with open(self.path, "wb") as f:
np.save(f, tokens)
np.save(f, splits)
.lock 哨兵文件让任务可恢复:如果 .bin 存在且没有残留 lock,就跳过;如果上次中断留下 lock,则重建该文件。这是训练系统中容易被忽视但非常实用的工程细节。
9.3 checkpoint 的 canonical 格式
PithTrain 保存 checkpoint 时,会把模型与优化器状态转换成 PP 无关的 canonical 格式。这样不同 pipeline 切分方式之间可以 reshard 恢复。
# 来源:pithtrain/tasks/pretrain_language_model.py
def save_checkpoint(cfg: PretrainLanguageModelCfg, ctx: PretrainLanguageModelCtx) -> None:
save_location = Path(cfg.training.save_location, "torch-dcp", "step-%08d" % ctx.training.step)
model_state, optim_state = get_state_dict(model, optimizer, options=options)
state_dict = dict()
state_dict["app"] = dict()
state_dict["app"]["model"] = to_canonical_model(model_state, model)
state_dict["app"]["optimizer"] = to_canonical_optim(optim_state, model)
state_dict["app"]["scheduler"] = scheduler.state_dict()
dcp.save(state_dict, checkpoint_id=save_location)
这解决的是大规模训练中非常现实的问题:训练中途换机器、换并行策略、导入导出 Hugging Face 格式,如果 checkpoint 强绑定当前 rank 布局,会极大限制可运维性。对此感兴趣的同学可以在 技术文档 中查阅更多避坑指南。
十、PithTrain 的技术意义与边界
10.1 最大价值:把高性能训练系统变成可学习对象
PithTrain 的最大价值不只是性能,而是 可读性与完整性的同时成立。它把以下复杂技术放在同一套 Python 代码中:
- PP/DP/CP/EP 四维并行。
- DualPipeV 双向流水线调度。
- MoE 专家 dispatch 与 combine。
- FSDP2 参数分片与手动 post-backward 协调。
- FP8 Linear 与 FP8 GroupLinear。
- Triton 融合量化、dispatch、scatter 等算子。
- mmap 数据集、checkpoint reshard、WandB 日志、Nsight 与显存 profile 入口。
这对研究者、系统工程师和 AI agent 都有价值。
- 对于人,它是可学习的训练系统蓝图;
- 对于 AI agent,它的代码规模足以放进上下文窗口,便于自动修改和验证。
10.2 与传统训练栈的差异
与 Megatron-LM、DeepSpeed 等传统生产框架相比,PithTrain 显然更小、更 Python 原生,也更容易端到端阅读。但它并不是替代所有生产平台的“万能框架”。 它更像一个高性能训练系统的“压缩参考实现”: 保留关键机制,减少历史包袱,让读者能看清每个组件为什么存在。
与普通 PyTorch 训练脚本相比,PithTrain 的复杂性明显更高,但这些复杂性对应真实 MoE 训练瓶颈:专家通信、pipeline bubble、FSDP hook、FP8 量化、checkpoint 重分片。它不是为了教学而简化问题,而是把真实问题用更紧凑的方式表达出来。
10.3 当前边界
基于当前仓库公开代码,PithTrain 主要面向 NVIDIA Hopper/Blackwell 与 CUDA 13.0 环境,依赖 torch>=2.10.0、 flash-attn-4[cu13]、 deep-gemm、 tilelang 等较新的组件。也就是说,它不是一套“随便一张消费级 GPU 即可体验”的框架,而是 面向先进 GPU 集群上的 MoE 训练实验与工程验证。
模型支持方面,代码中已经包含 Qwen3-30B-A3B、DeepSeek-V2-Lite、GPT-OSS 相关实现与配置路径,但扩展新模型需要遵守 ModelProtocol 和 DecoderLayerProtocol,把层拆成 attention、dispatch、MLP、combine、aggregate 可调度阶段。
十一、一张文字流程图:PithTrain 如何完成一次训练
11.1 端到端执行链路
可以把 PithTrain 的一次预训练运行概括为下面这条链路:
用户执行launch.sh
-> torchrun启动多进程
-> script.py构造PretrainLanguageModelCfg
-> launch(cfg)
-> logging_context初始化日志
-> distributed_context初始化NCCL与DeviceMesh(PP,DP,CP,EP)
-> training_context
-> setup_dataset:扫描.bin并构建mmap ConcatDataset
-> setup_model:AutoConfig选择模型类,构建双模块V形pipeline
-> apply_fsdp:按MoE/非MoE参数应用不同mesh分片
-> setup_optimizer:Adam
-> setup_scheduler:Linear warmup + Cosine/Constant
-> load_checkpoint:从最新DCP checkpoint恢复
-> while step < max_steps:
-> get_global_batch:按DP/EP/CP rank读取局部token片段
-> DualPipeV.step:
-> scatter成micro-batches
-> 8步V形pipeline调度
-> overlapped_forward_backward五阶段重叠
-> EP all-to-all dispatch/combine
-> FP8 GEMM与Triton融合核
-> 手动FSDP post_backward
-> CP loss all-reduce
-> 梯度累积缩放
-> 全局grad norm裁剪
-> optimizer.step
-> scheduler.step
-> 记录loss、吞吐、显存、学习率
-> 定期save_checkpoint
这条链路说明 PithTrain 的本质不是某个单点技巧,而是 一套围绕 MoE 训练吞吐构建的系统工程: 数据少搬一次,通信多重叠一点,权重量化少重复一次,hook 少触发一次,最终都汇成训练速度和可维护性的改善。
结语:PithTrain 给训练系统设计带来的启发
PithTrain 最值得学习的地方,是它重新定义了“高性能训练框架”的表达方式。过去,高性能常常意味着不可读:复杂 C++运行时、手写 CUDA、庞大的配置系统与层层抽象。 PithTrain 则展示了另一条路径:把不可避免的复杂性保留在代码里,但通过清晰协议、模块边界、Python DSL 算子和显式调度,把它变成可解释、可修改、可验证的工程。
它对 AI 时代尤其有启发。未来的软件不只是给人读,也会被 AI agent 阅读、检索、修改和重构。 一个约一万行、Python 原生、结构清晰、又包含真实生产级训练机制的项目,天然更适合这种协作模式。 PithTrain 不是把 MoE 训练变简单,而是把 MoE 训练的复杂性摆上台面,并以足够紧凑的方式组织起来。
如果说传统训练框架像一座巨型工厂,PithTrain 更像一张拆解到零件级别的工程图:你能看到数据如何进入,token 如何被路由,专家如何通信,前后向如何交错,FP8 权重如何缓存,checkpoint 如何摆脱 pipeline 切分绑定。对于想理解大模型训练系统底层逻辑的人,它提供的不是一个黑盒按钮,而是一条可以真正走通的路径。在 云栈社区 ,我们持续关注这类兼具深度与可读性的开源项目,期待更多开发者从中汲取灵感。

 发表于 2026-5-2 22:38:56
|
查看: 153|
回复: 0
发表于 2026-5-2 22:38:56
|
查看: 153|
回复: 0
