1 背景
在一次日常沟通中,客服技术部的同事反馈了一个服务治理中的棘手问题:一个平均执行耗时仅1.5ms的核心接口,在调用方设置了100ms超时的情况下,成功率却无法达到五个九(99.999%)的公司标准。
该接口的主要逻辑是先查询缓存,若未命中则查询数据库并回写缓存。从业务逻辑上看简洁高效,平均耗时也很低,但监控数据显示每天仍有数百次超时发生。这显然不符合常理,平均耗时与超时配置之间存在巨大的数量级差异,问题究竟出在哪里?这促使我们开始了一次深入的排查之旅。
2 验证与分析
2.1 准备工作
在开始验证前,有必要先了解转转内部RPC框架SCF(假定命名)的基本调用流程。一次完整的RPC调用通常包含以下几个步骤:
- 序列化:调用方SCF对请求进行负载均衡、序列化等处理。
- 发送:将序列化后的二进制数据流通过网络发送至服务方节点。
- 反序列化:服务方节点接收数据,由SCF进行反序列化、请求排队等操作。
- 执行:SCF将请求交由服务方的业务方法具体处理。
- 序列化:SCF将业务方法的处理结果序列化为二进制数据流。
- 发回:将结果数据流发送回调用方。
- 反序列化:调用方SCF收到数据后,反序列化为对象,交还给调用方业务代码。
整个过程对业务方透明,使其感觉如同在进行本地方法调用。我们可以将链路大致划分为“框架耗时”(步骤1、2、3、5、6、7,涉及网络与框架本身)和“业务耗时”(步骤4,纯业务逻辑执行)。
2.2 验证数据
首先,我们查看了服务方的监控数据,确认该接口的平均执行耗时确实稳定在1.5ms左右,这与反馈信息一致。
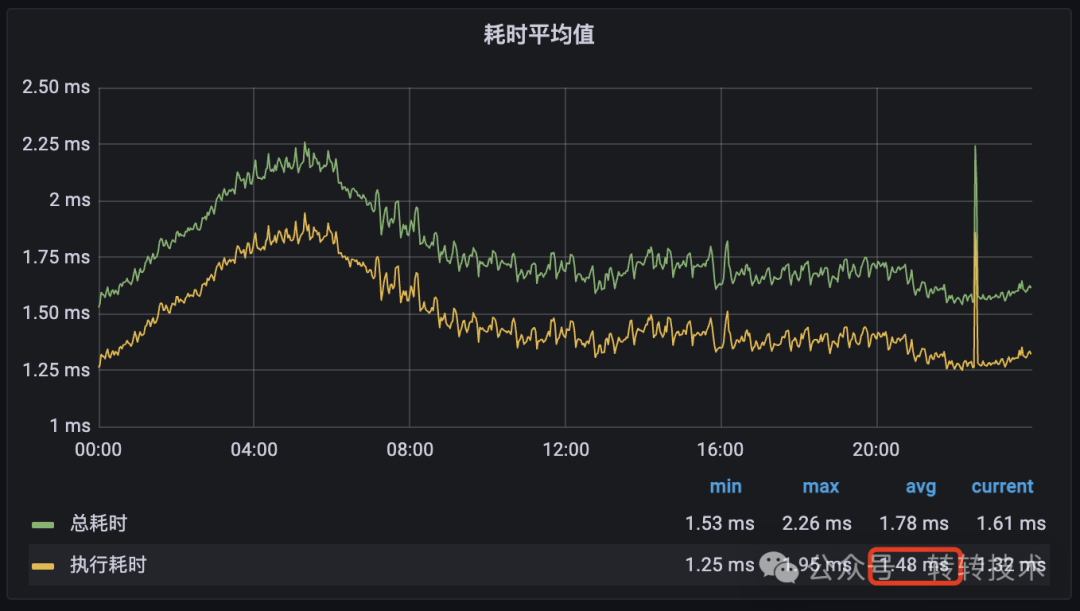
然而,调用方的监控大盘却揭示了另一番景象:在超时时间设置为100ms的前提下,该接口每天确实会产生500多次超时,成功率无法达到99.999%。
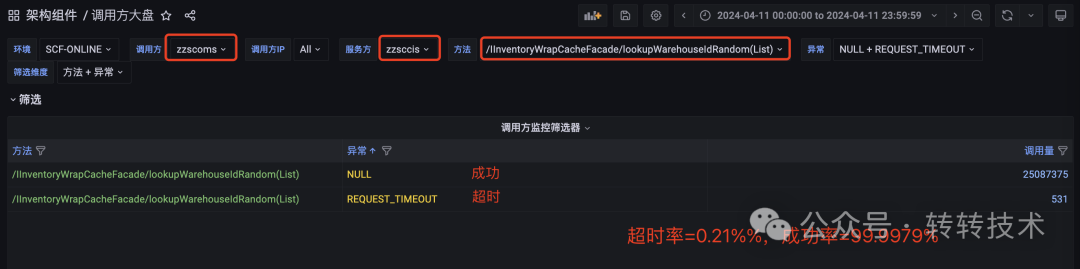
平均耗时与超时配置之间超过60倍的差距,与实际出现的超时情况形成了强烈矛盾。
2.3 问题分析
根据RPC调用链路,超时可能发生在框架或业务的任何一个环节。为了定位问题,我们查看了服务方接口的耗时分布监控。这个视图能告诉我们所有请求的耗时分布在各个区间的情况,而非只看平均值。
监控结果令人意外:尽管绝大多数请求在5ms内完成,但竟然有314个请求的执行耗时直接超过了100ms!
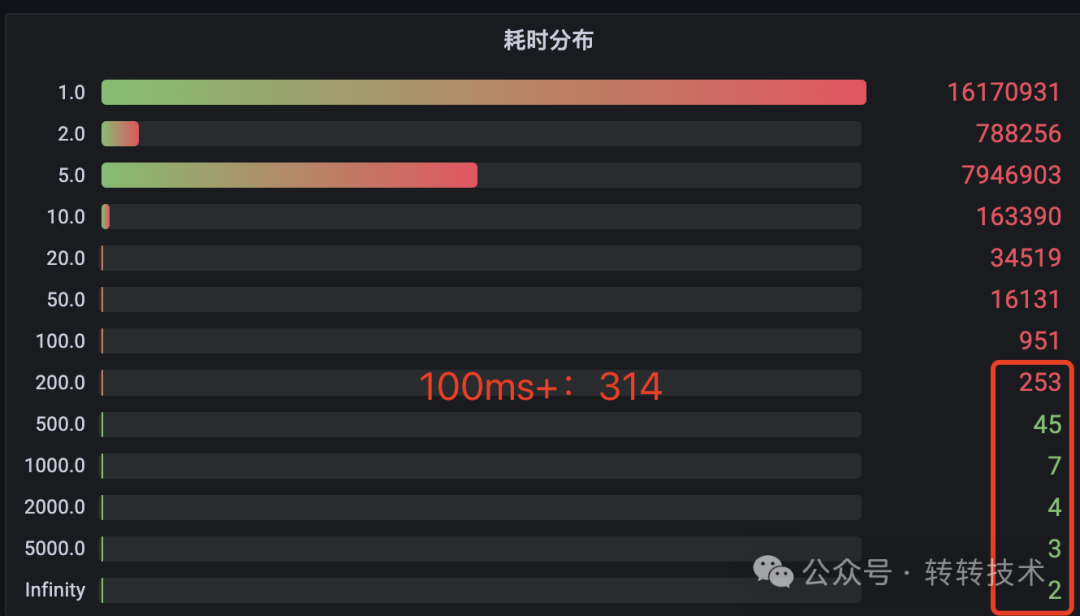
这个发现是关键:我们被1.5ms的平均值“欺骗”了。业务逻辑本身存在长尾请求,其耗时足以触发调用方的超时。 那么,这些长尾请求的时间到底消耗在哪里?
2.4 深入排查
为了进一步定位耗时点,我们将该接口的内部逻辑拆解成几个核心阶段,并为每个阶段添加了细粒度的耗时监控:
- 访问缓存(I/O)
- 计算需查询DB的ID列表(CPU)
- 从数据库查询数据(I/O)
- 数据格式映射(CPU)
- 回写缓存(I/O)
- 组织返回结果(CPU)

各阶段的监控结果如下:
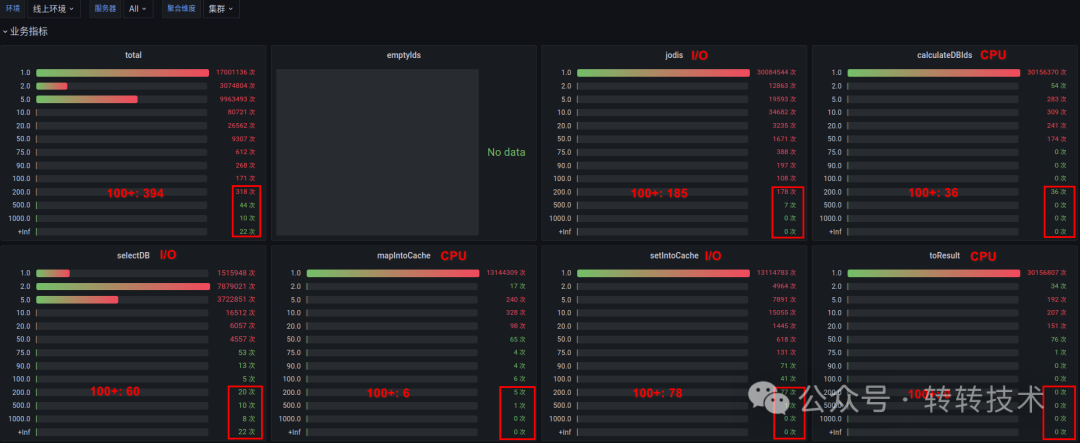
从数据中可以观察到两个现象:
- I/O操作(访问缓存、DB、回写缓存)更容易出现抖动,有不少超过100ms的极端情况。
- 纯CPU操作(计算、映射)也并非始终平稳,出现了从1ms到20ms的跳跃式增长,而非渐进式变慢。
2.5 根因推测
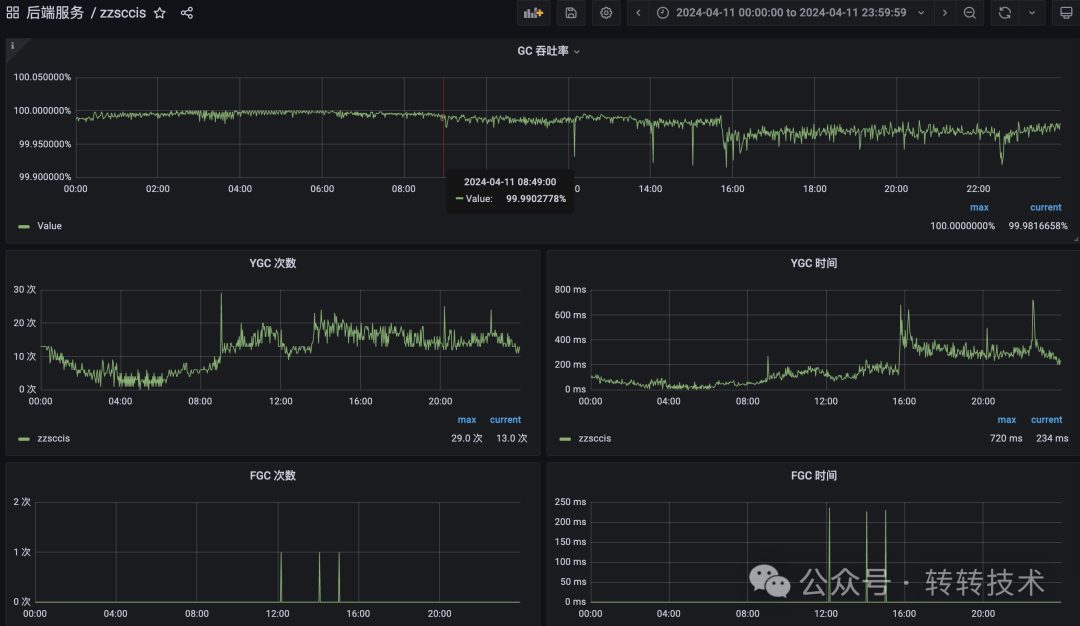
至此,问题清晰了:长尾效应是导致低平均耗时下仍出现超时的根本原因。是哪些因素会导致这种偶发性的长耗时呢?在 Java 服务中,垃圾回收(GC)是首要怀疑对象。一次Full GC或耗时的Young GC暂停,会“冻结”所有线程,导致正在处理的请求耗时飙升。
我们调取了服务实例的GC监控,发现其在某些时段确实发生了GC耗时尖峰。
此外,CPU时间片竞争、网络瞬时抖动、操作系统调度等都可能是诱因。为了验证这是否是个普遍现象,我们查看了另一个业务(商品服务)的类似接口,其耗时分布也表现出相同的长尾特征。
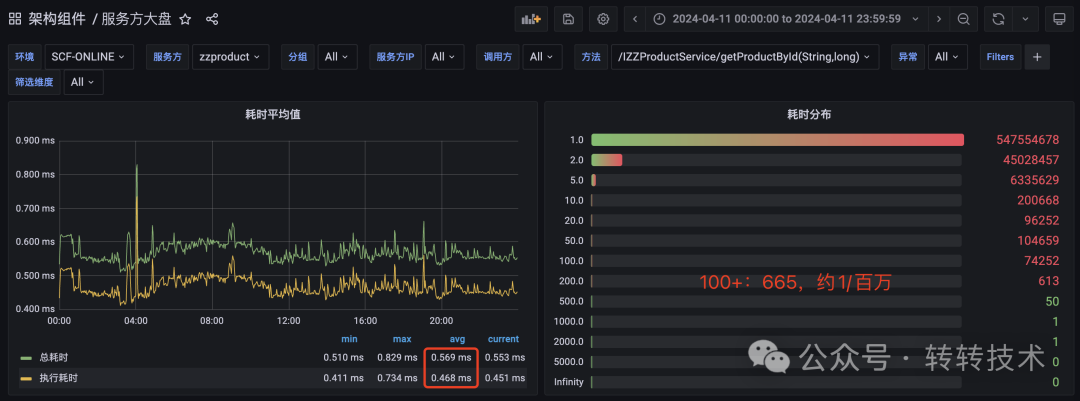
这说明,在复杂的生产环境(尤其是 JVM 上),即使是简单的操作,由于底层资源调度的不确定性,也存在出现偶发性耗时的可能。
3 解决方案
问题根源在于长尾效应。那么,要满足五个九的SLA要求,有什么办法呢?
最直接的思路是调整超时时间。我们可以参考调用方监控中的高百分位(例如TP9999或TP99999)耗时来设置。如下图所示,该接口的TP99999(保证99.999%请求快于该值)约为123ms,而当前超时配置为100ms,这必然会导致那0.001%的请求超时。
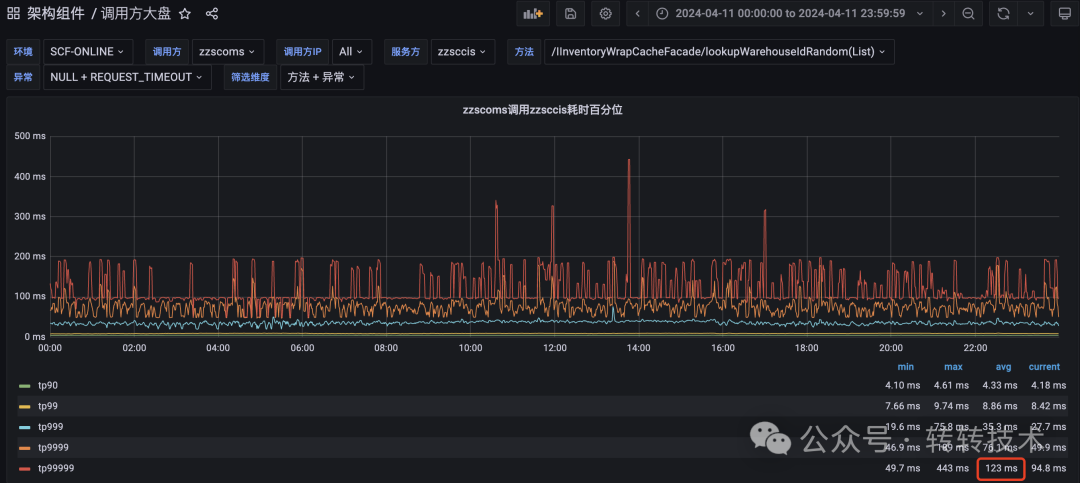
因此,将超时时间调整为大于TP99999的值(如130ms),即可从配置上解决此问题。其他方法还包括深度优化JVM参数以减少GC停顿,或优化业务逻辑进一步压平长尾,但这些通常成本较高。
3.1 框架优化:弹性超时
除了调整静态超时,我们是否可以在 RPC 框架层面做一些智能化的改进?基于本次分析,我们设计并实现了弹性超时方案。
核心思想:在保持原有超时配置(如100ms)不变的前提下,允许在可控范围内(时间窗口、请求次数)对少量偶发超时请求进行“宽恕”,给予一个更长的弹性超时时间(如1300ms)。这样既能兜底解决因偶发因素(如GC、瞬时抖动)导致的超时,提升成功率,又避免因全局放宽超时而影响用户体验或掩盖真实故障。
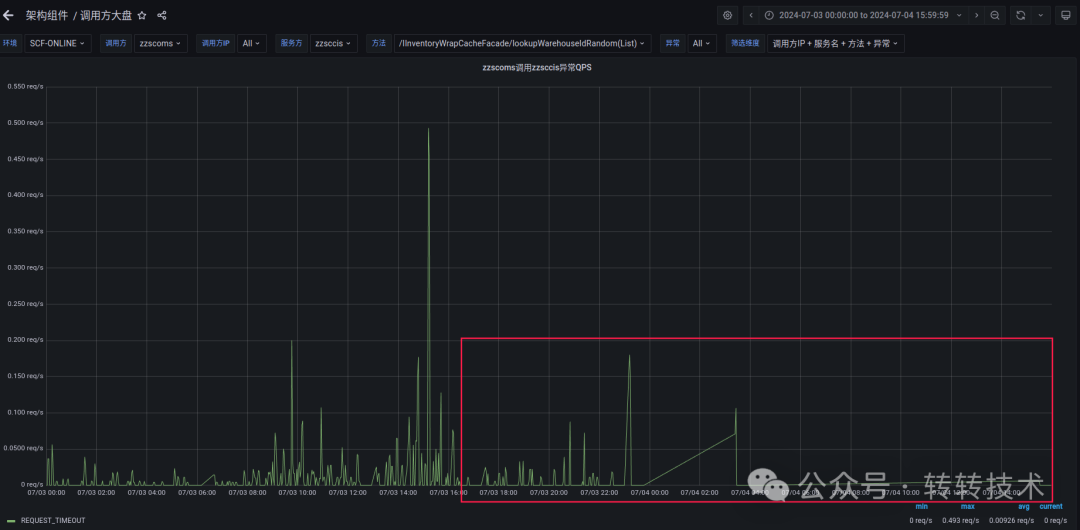
3.1.1 效果展示
我们在服务治理平台上为该接口配置了弹性超时:每40秒内,允许最多15个请求使用1300ms的弹性超时时间。
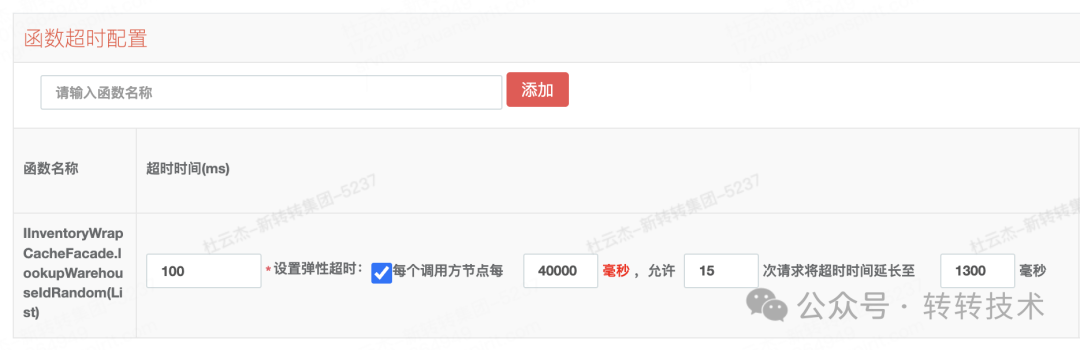
配置生效后,监控显示原有的偶发性超时错误基本被消除,接口成功率显著提升。
3.1.2 适用场景
弹性超时是一剂“特效药”,但并非万能。它主要适用于偶发性、非持续性的超时场景,例如:
- 短暂的GC停顿
- 网络瞬时抖动
- CPU时间片竞争
- 服务冷启动等
如果出现大面积的、持续的超时,则表明系统存在根本性瓶颈或故障,此时应优先进行系统诊断和治理,而不是依赖弹性超时来掩盖问题。
4 总结
本次排查经历刷新了我们的一个常见认知:一个平均耗时极低的接口,由于GC、系统调度等底层因素,依然可能产生足以触发超时的长尾请求。单纯依赖平均耗时进行性能评估和超时设置是危险的,必须结合耗时分布、高百分位等指标。
解决方案可以从业务方和框架方双向入手:业务方可根据TP9999等指标合理设置超时,或进行JVM/代码深度优化;框架方则可提供如“弹性超时”的智能治理手段,在保障SLA的同时提升系统韧性。
在云栈社区的日常交流中,我们常常发现,许多复杂的系统问题都源于对这些基础原理和监控指标的深入理解。希望这个案例能为你带来启发。
 发表于 2026-1-31 07:53:33
|
查看: 170|
回复: 0
发表于 2026-1-31 07:53:33
|
查看: 170|
回复: 0
