云原生时代,微服务架构下的负载均衡至关重要。作为运维人员,想必你早已受够了传统负载均衡的静态配置——每次后端服务扩缩容,都需要手动修改配置并重启代理,效率低下且极易出错。
而 Traefik 这款云原生专属的动态应用代理,正是为了解决这些痛点而生。它支持动态服务发现、路由自动更新,并内置了多种负载均衡算法,极大简化了运维工作。本文将从核心概念到实战优化,为你深度解析 Traefik 的负载均衡能力,助你快速上手。

先搞懂:Traefik负载均衡到底是个啥?
简单来说,Traefik 的负载均衡是一个“智能流量分发器”。它能实时监控后端服务实例的状态,将用户请求合理地分配到不同的服务器上。这样做既能防止单台服务器过载,又能在某个实例故障时,自动将流量切换到健康的节点,实现高可用。
其最大优势在于完全自动化。无论是 Docker 容器还是 K8s Pod,当服务实例动态扩缩容时,Traefik 都能自动感知并更新路由,真正实现“无感运维”。
Traefik负载均衡核心架构:3层设计,简单清晰
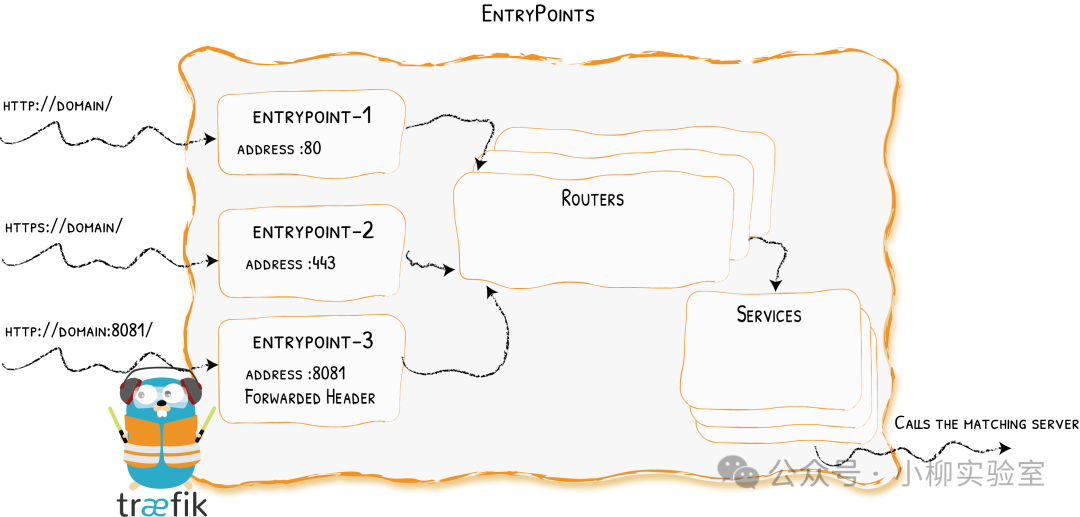
Traefik 的负载均衡逻辑清晰明了,依赖于 入口点(EntryPoints)→ 路由器(Routers)→ 服务(Services) 三层组件协同工作:
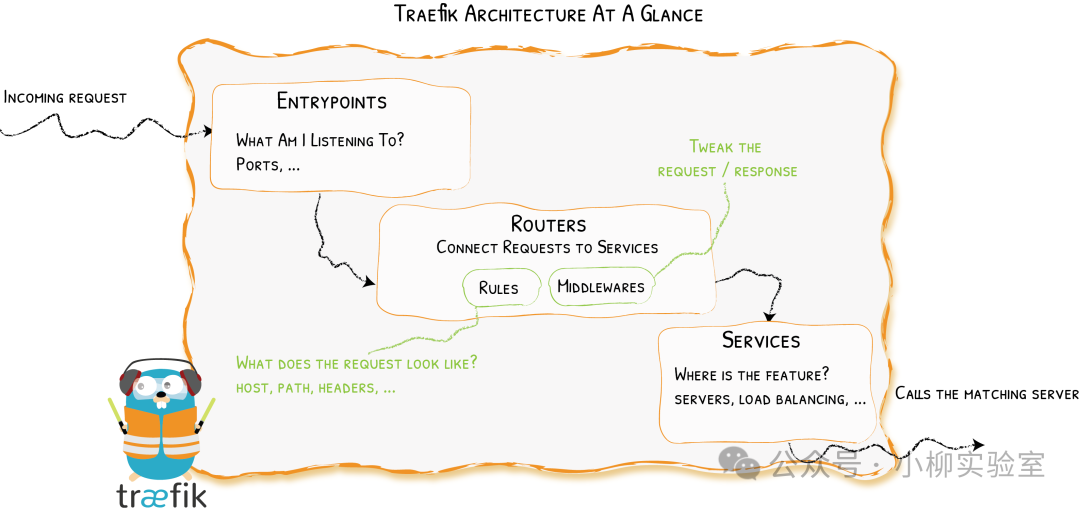
- EntryPoints(入口点):这是
Traefik 的“监听端口”,定义了外部流量进入的协议(HTTP/HTTPS/TCP)和端口。所有请求都必须先通过这里。
- Routers(路由器):相当于“交通规则制定者”。它根据你定义的规则(如域名、URL路径、请求头等)来判断一个请求应该被路由到哪个后端服务。
- Services(服务):这是执行负载均衡的“核心引擎”。它接收来自路由器的指令,并根据你选择的算法将请求分发到具体的后端实例。它还负责管理健康检查、连接池等事宜。
整个过程可以概括为:请求进入入口点 → 路由器匹配规则 → 服务执行负载均衡并调用后端,全程自动化。
重点来了!7种负载均衡算法,怎么选才对?
Traefik 内置了 7 种负载均衡算法,覆盖了绝大多数业务场景。选择不当会直接影响系统性能和稳定性。下面详细解析每种算法的原理与适用场景:
-
轮询算法(Round Robin)
- 原理:最基础的策略,按照后端实例列表的顺序依次分发请求。
- 适用场景:后端服务器配置、性能基本一致,且请求处理时间相近的场景(如静态资源服务)。
- 优点:实现简单,开销小,是无脑入门的选择。
-
加权轮询算法(Weighted Round Robin)
- 原理:在轮询基础上,为性能不同的服务器设置权重。权重越高,被分配到的请求比例越大(例如,权重 3:1 意味着前者接收约三倍于后者的流量)。
- 适用场景:后端实例性能不均(如新旧机器混用),希望高性能机器承担更多负载。
- 优点:能够更精细地控制流量分配,充分利用硬件资源。
-
最少连接算法(Least Connections)
- 原理:实时监控各后端实例的活跃连接数,将新请求优先分发给当前连接数最少的服务器。
- 适用场景:请求处理时间波动较大(例如有的请求是简单查询,有的涉及复杂计算或数据库操作),能有效避免慢请求堆积在某个实例上。
- 优点:动态均衡负载,防止单实例因慢请求而过载。
-
加权最少连接算法(Weighted Least Connections)
- 原理:结合服务器权重和当前活跃连接数进行决策,既考虑预设的静态性能差异,也关注实时负载情况。
- 适用场景:后端性能参差不齐,且请求处理耗时变化大的复杂业务场景(如核心业务微服务)。
- 优点:复杂场景下的较优解,能同时兼顾性能和实时负载的均衡性。
-
IP哈希算法(IP Hash)
- 原理:根据客户端 IP 地址计算一个哈希值,确保来自同一 IP 的请求始终被定向到同一台后端实例。
- 适用场景:需要会话保持(Session Stickiness)的业务,如用户登录状态、购物车等,避免会话数据因请求被分发到不同实例而丢失。
- 优点:无需部署外部会话共享组件(如Redis),配置简单,直接实现会话亲和性。
-
响应时间算法(Response Time)
- 原理:基于历史请求的响应时间,将新请求优先分发给历史响应最快的服务器。
- 适用场景:对延迟极其敏感的应用,如金融交易、实时数据查询等,追求极致用户体验。
- 优点:性能导向,可以有效降低整体请求延迟。
-
随机算法(Random)
- 原理:完全随机地从后端实例列表中选取一个来处理请求。
- 适用场景:后端实例数量庞大且本身负载已较为均衡,对分发规则无特殊要求的无状态服务。
- 优点:能够很好地分散流量,避免因固定模式分发而可能产生的“热点”问题。
实战优化!4个技巧,让Traefik性能起飞
选对算法只是基础,结合以下 4 个优化技巧,才能让你的 Traefik 负载均衡发挥最大效能。
1. 健康检查必须配,故障转移快人一步
健康检查是避免流量打入故障节点的生命线。合理配置是关键:
- 检查类型:HTTP 服务使用 HTTP 检查(检查返回状态码,如 2xx/3xx 视为健康);TCP 服务使用端口连通性检查。
- 频率与超时:适当缩短检查间隔(如 5 秒)并设置合理的超时时间(如 2 秒),以便快速发现异常实例。
- 被动健康检查:启用该功能后,当某个实例连续返回错误,Traefik 会将其暂时移出负载均衡池,待其恢复健康后再重新加入,实现更平滑的故障转移。
2. 连接池精细化管理,别浪费服务器资源
连接池配置不当会导致连接耗尽或资源闲置:
- 最大连接数:根据后端实例的处理能力设置合理的最大连接数上限,防止单个实例被压垮。
- 超时控制:配置连接超时、请求超时和空闲连接超时,及时释放无效或闲置连接,回收资源。
- 连接复用:为 HTTP/1.1 和 HTTPS 服务启用 Keep-Alive(长连接),减少频繁建立 TCP 连接带来的开销。
3. 开缓存!减轻后端压力,响应速度翻倍
利用 Traefik 的缓存中间件,将高频访问且不常变动的响应结果缓存起来,直接返回给用户。
- 静态资源:为图片、CSS、JavaScript 等设置较长的缓存时间。
- 高频接口:为某些查询接口设置短期缓存,并注意根据请求参数(如 query string)生成缓存键,确保数据准确性。
- 失效策略:规划好缓存失效机制,避免因缓存数据过期而影响业务。
4. 监控必须盯紧,问题早发现早解决
没有监控的优化就是盲人摸象。Traefik 提供了丰富的可观测性数据。
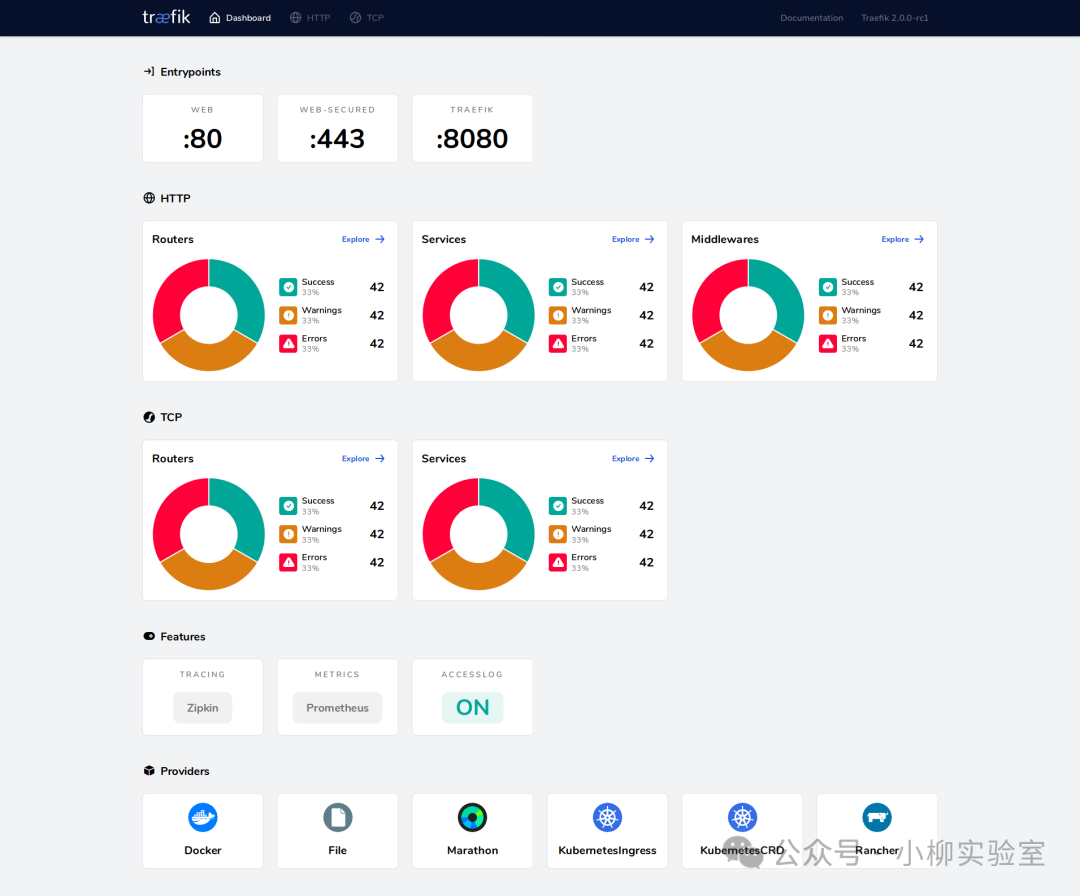
- 内置仪表盘:开启后可以直观查看入口点流量、路由匹配状态、后端服务健康度等。
- 集成监控栈:将 Traefik 的 Metrics 数据接入
Prometheus + Grafana,搭建可视化的监控面板,并设置告警规则。这通常是运维团队的标配。
- 核心指标:重点关注每个后端实例的请求分发量、平均响应延迟、错误率等。一旦发现指标异常,即可快速调整算法或进行扩容。
最后:Traefik负载均衡最佳实践,运维避坑指南
- 算法选型看场景:不要凭感觉选。会话保持用 IP 哈希,延迟敏感用响应时间,混合复杂场景用加权最少连接。
- 健康检查是底线:无论场景多简单,都必须配置基础的健康检查,这是高可用的基础保障。
- 监控是优化的眼睛:没有监控数据,所有性能调优都是猜测。建立完善的监控体系至关重要。
- 定期演练故障转移:主动模拟后端实例故障(如停止一个容器),验证流量是否能自动、平滑地切换到健康实例,确保灾难恢复预案真实有效。
总结
Traefik 作为云原生时代的动态负载均衡利器,其核心价值在于 自动化配置 与 灵活的算法策略。理解其三层架构,根据业务特征选择合适的负载均衡算法,并辅以健康检查、连接池管理、缓存和监控等优化手段,你就能轻松构建出高可用、高性能的微服务网关。
如果你在实践 Traefik 或其它云原生、运维技术时遇到问题,欢迎到 云栈社区 的 运维/DevOps/SRE 板块与其他开发者交流讨论,共同进步。 |  发表于 2026-1-31 08:19:20
|
查看: 187|
回复: 0
发表于 2026-1-31 08:19:20
|
查看: 187|
回复: 0
