作为互联网从业者,高并发一直是绕不开的核心话题。掌握一套行之有效的技术方案,不仅能应对海量流量的挑战,更是进阶为系统架构师的关键路径。那么,构建一个高并发系统,通常有哪些主流的技术方案可供选择呢?
一、负载均衡
在当今的分布式时代,单纯依赖优化单台机器的 内存、CPU、磁盘、网络带宽 来应对高并发已经捉襟见肘。正所谓“双拳难敌四手”,我们需要的是通过增加机器数量来提升整体处理能力,即水平伸缩方案。
面对众多服务器实例,如何高效、公平地调度网络流量?第一道入口便是负载均衡。它的核心职责是将外部请求“均摊”到后端集群的不同机器上,从而避免部分服务器压力过大而另一些却处于空闲状态。通过负载均衡,每台服务器都能获得适合自身处理能力的负载,在为高负载节点分流的同时,也避免了资源浪费,一举两得。
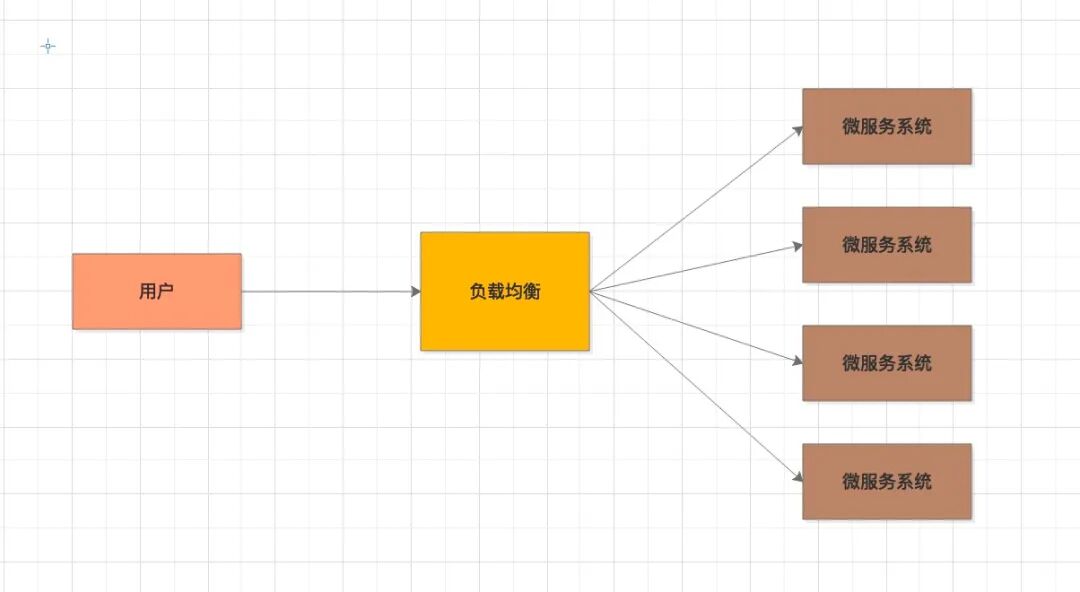
常见的负载均衡算法包括:
- 随机算法
- 轮询算法
- 轮询权重算法
- 一致性哈希算法
- 最小连接算法
- 自适应算法
常用的负载均衡工具有:
对于超大型系统,通常会采用 DNS 解析、四层负载(如 LVS)和七层负载(如 Nginx)相结合的多层次负载均衡架构,以实现更精细的流量管控和高可用性。
二、分布式微服务
以往单体大而全的系统,在面对复杂多变的业务规则时,往往显得臃肿且难以维护。借鉴“分而治之”的思想,通过 SOA 架构直至微服务架构,将一个庞大的系统拆分成若干个职责单一、粒度更小的服务。
每个微服务独立开发、部署和扩展,服务间通过轻量级的通信机制进行协作,例如标准的 HTTP RESTful API 或高效的私有 RPC 协议。
微服务架构的主要特点:
- 业务清晰:按业务域划分服务,单个服务代码量小、功能聚焦,易于理解和维护。
- 独立自治:每个微服务拥有自己独立的数据存储(如数据库)和基础组件。
- 通信解耦:服务间通过定义良好的接口通信,并具备熔断、降级等容错能力。
- 动态治理:有一套服务治理方案(如服务发现、配置管理),服务可动态注册与剔除。
- 弹性伸缩:每个服务可独立进行集群化部署,具备负载均衡能力。
- 安全与可观测性:拥有完整的安全认证、授权机制,以及链路追踪和实时日志系统。
市面上常用的微服务框架有:Spring Cloud、Dubbo、Kubernetes、gRPC、Thrift 等。
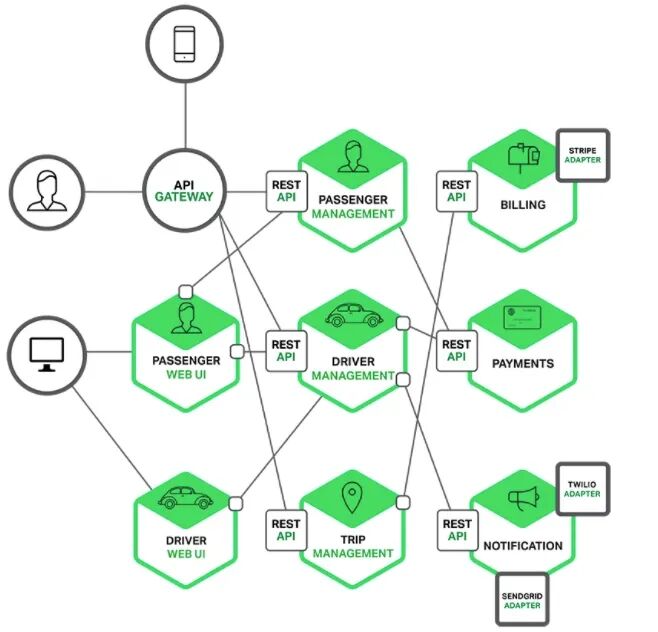
微服务数量众多,它们如何发现彼此?这就需要引入注册中心。服务启动时向注册中心注册自己的网络地址,消费方通过查询注册中心来获取可用的服务列表。
常用的注册中心包括:Zookeeper、etcd、Eureka、Nacos、Consul。
当然,微服务在带来灵活性的同时,也引入了新的复杂性,需要额外关注:
- 分布式事务
- 限流与降级机制
- 熔断机制
- API 网关
- 服务链路追踪
三、缓存机制
性能不够,缓存来凑。要想快速提升系统响应速度和吞吐量,引入缓存几乎是立竿见影的方案。
以 Memcached 为例,单服务器简单的 key-value 查询 TPS 可达 5 万以上;而 Redis 的性能更是可以达到 10W+ QPS。缓存为何如此之快?关键在于数据访问路径的巨大差异。
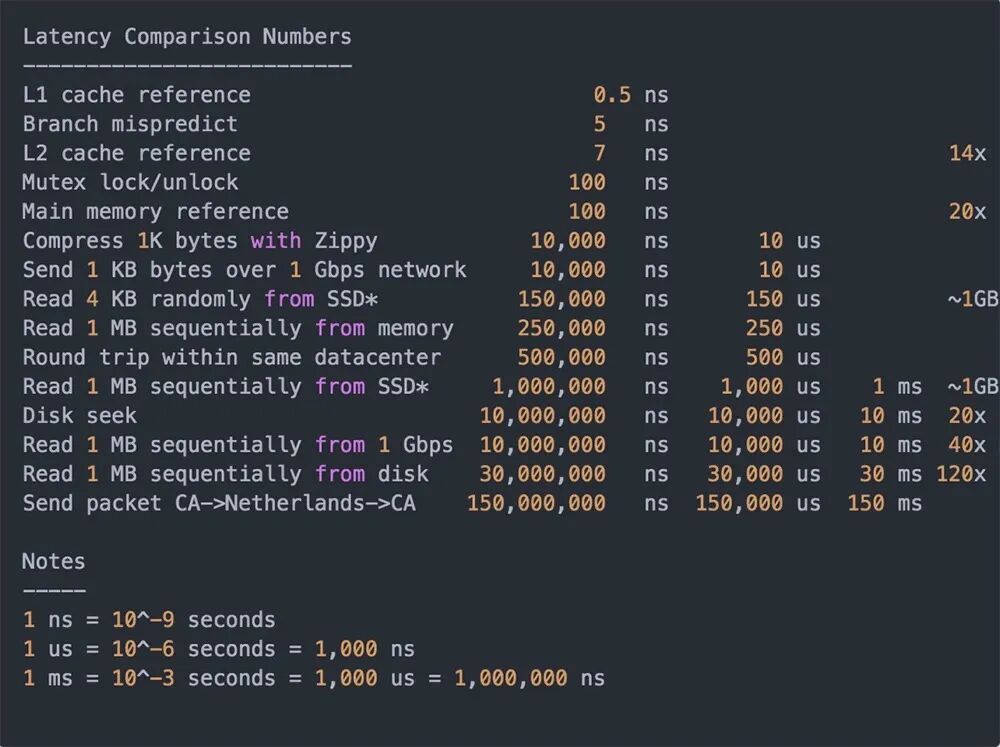
从上图延迟对比可以看出,同机房网络来回一次加上内存顺序读取1M数据,总计约 0.75ms。若从机械硬盘读取,仅一次磁盘寻址就需要10ms,再顺序读取1M数据需30ms。使用内存缓存将性能提升了数个数量级,自然也能支撑更高的并发量。
缓存主要分为本地缓存和分布式缓存,核心区别在于是否需要网络访问。
- 本地缓存:存储在应用进程内部(如 JVM 堆内),访问速度极快。但在多实例部署时,数据更新难以同步,通常通过设置较短的过期时间(秒/分钟级)来保证最终一致性,避免返回脏数据。
- 分布式缓存:采用独立集群部署,如 Redis Cluster。虽然存在网络开销(通常小于1ms),但它支持水平扩容、数据集中管理、一致性更好,是构建高并发系统的标配。
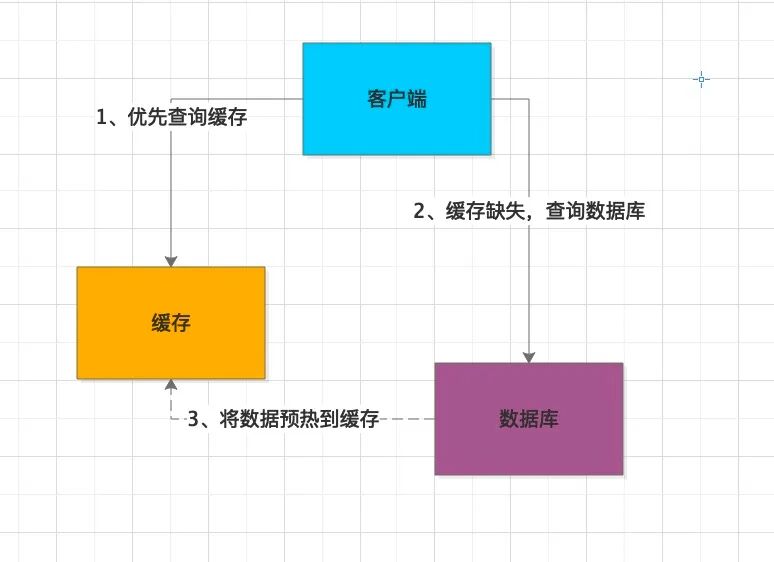
常用的缓存更新策略有哪些?
- Cache Aside(旁路缓存):最常用的策略。先更新数据库,再删除缓存。为兜底通常还会给缓存设置一个过期时间。
- Read/Write Through(穿透读写):应用只与缓存代理交互,由代理来维护缓存与数据库的一致性,对应用透明。
- Write Behind(异步回写):应用只更新缓存,缓存代理异步批量将数据写入数据库,极大提升写性能。操作系统 Page Cache 就是类似机制。
四、分布式关系型数据库
单机 MySQL 数据库即便有 B+ 树索引优化,考虑到 I/O 性能,其单表数据量通常也建议控制在千万级别以内。当数据量或并发量超越单机瓶颈时,分库分表就成为必然选择。
分表主要分为垂直分表和水平分表。
- 垂直分表:纵向切分,将一张宽表的列拆分到多个表中,遵循“冷热分离”、“大字段独立”、“高频字段分离”等原则,使表结构由“宽”变“窄”。
- 水平分表:横向切分,表结构不变,按照某种规则(如用户ID哈希)将数据行分布到多个结构相同的表中。拆分后所有子表的数据并集等于原始数据。
分库分表涉及的核心技术点:
- SQL 改写:根据分片键(如 user_id)计算目标物理表,并重组 SQL。
- 数据路由:如果是分库,还需根据分片结果路由到正确的数据库实例。
- 结果合并:对于未指定分片键的查询,可能需要查询所有分片并对结果进行合并、排序等操作。
业界实现方案主要有两种模式:
- Proxy 代理模式:所有 SQL 解析、路由、结果合并逻辑集中在一个独立的代理服务中(如 MyCat)。业务方像使用单一数据库一样连接代理。
- 优点:对业务代码零侵入,支持多语言,升级方便。
- 缺点:引入了新的中间件,可能成为性能瓶颈和单点,运维复杂度增加。
- Client 客户端模式:以 Jar 包形式集成到业务应用中(如 Sharding-JDBC),在应用层完成所有分片逻辑。
- 优点:轻量,无额外网络跳转,性能好,运维简单。
- 缺点:通常只支持特定语言(如 Java),升级需要客户端配合。
实施分库分表的关键思路:
- 选择分片键:要求数据分布均匀、避免跨分片查询、值不频繁更新。例如电商订单常用
user_id。
- 制定分片策略:常见有范围分片、哈希取模分片、一致性哈希分片及混合策略。
- 数据迁移方案:通常采用“全量+增量同步”、“双写”、“灰度切流”的组合方案,保证平滑迁移。
有一种经验之谈:数据量大,就分表;并发高,就分库。实际设计中需根据业务增长预测做好技术选型,并特别注意分片键选择不当可能导致的数据倾斜问题。
五、分布式消息队列
并非所有的调用都需要同步处理。对于那些实时性要求不高,或非核心链路的逻辑,采用异步处理能显著提升主流程的响应速度——这便是消息队列的用武之地。
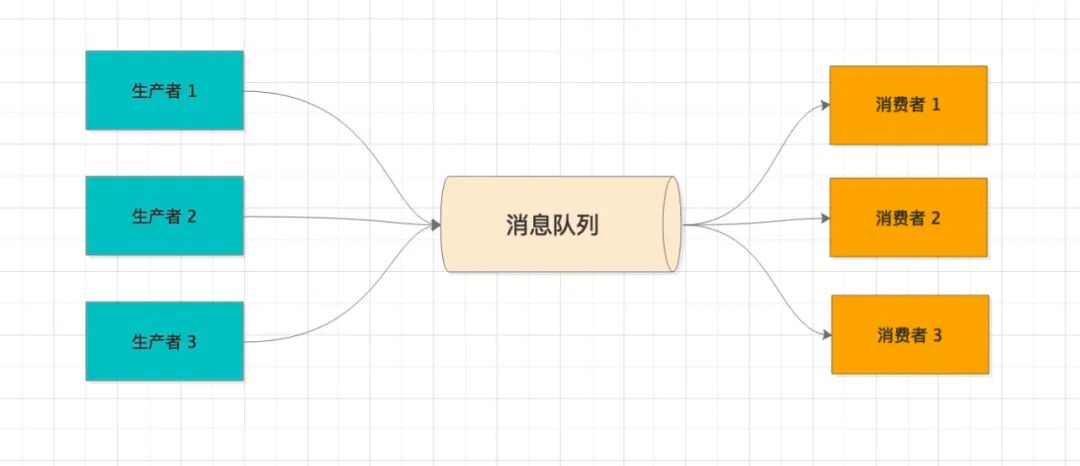
消息队列主要包含三种角色:生产者、消息队列(Broker)、消费者。生产者在完成核心逻辑后,将事件封装成消息发送至队列;下游关心该事件的系统,只需订阅对应的主题(Topic),即可消费消息进行后续处理。双方通过消息中间件彻底解耦,系统扩展性极强。
常用的消息中间件有哪些?
Kafka, RocketMQ, RabbitMQ, Pulsar, ActiveMQ 等。
消息队列的典型应用场景:
- 异步处理:将注册送积分、发送通知短信等非核心流程异步化,缩短主链路响应时间,提升吞吐量。
- 削峰填谷:应对秒杀等瞬时流量高峰,将请求缓冲在队列中,让下游系统按照自身处理能力平稳消费,避免被冲垮。
- 应用解耦:订单系统与库存系统通过消息队列通信,即使库存系统短暂宕机,订单消息也不会丢失,提升了系统整体可用性。
- 最终一致性:在分布式事务场景中,通过可靠消息传递实现数据的最终一致性。
六、CDN(内容分发网络)
CDN 全称 Content Delivery Network。其目标是在现有互联网基础上构建一层智能虚拟网络,将源站的静态内容(图片、CSS、JS、视频等)缓存到遍布全球的边缘节点。用户请求时,通过全局负载均衡调度,从距离最近、速度最快的节点获取内容,从而极大提升访问速度,减轻源站压力。
CDN 可以理解为 镜像(Mirror) + 缓存(Cache) + 全局负载均衡(GSLB) 的组合体。
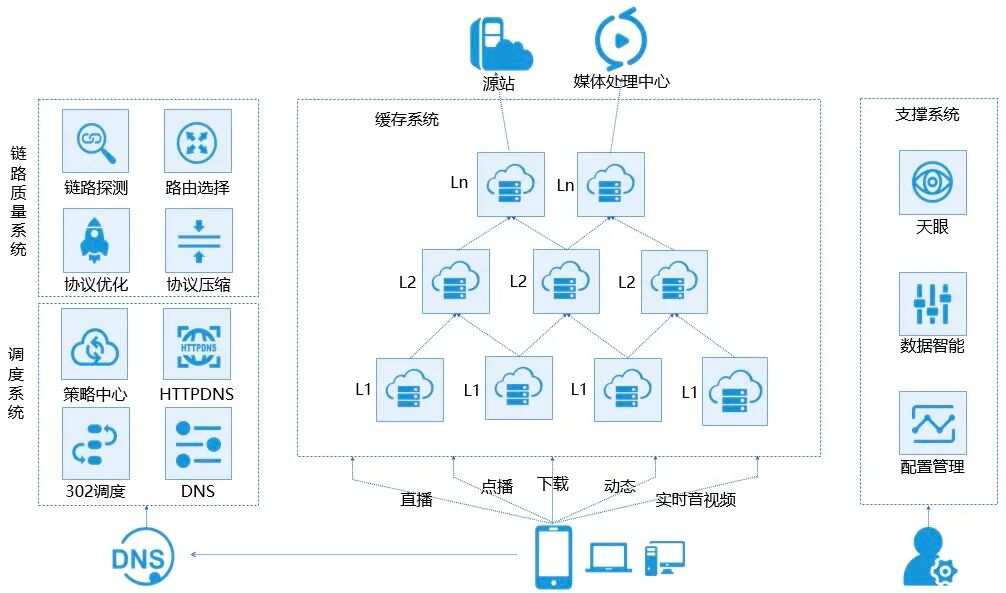
CDN 的主要特点:
- 本地 Cache 加速,降低访问延迟。
- 实现跨运营商、跨地域的远程加速。
- 通过边缘节点分摊流量,优化源站带宽成本。
- 利用分布式架构具备一定的集群抗攻击能力。
主要应用场景:
- 网站静态资源加速
- 音视频点播与大文件下载分发
- 视频直播流加速
- 移动应用静态内容加速
七、其他补充技术
除了上述核心方案,一个成熟的高并发系统生态往往还会涉及其他关键技术作为补充,例如:
- 分布式文件系统:用于海量非结构化数据(如图片、视频)的存储与访问。
- NoSQL 数据库:如 MongoDB(文档型)、Cassandra(列存储),应对特定场景下的高性能读写需求。
- NewSQL 数据库:如 TiDB,尝试兼具 NoSQL 的扩展性和传统 SQL 数据库的事务一致性。
- 大数据处理框架:用于离线或实时分析海量业务数据,驱动决策。
构建高并发系统是一个系统工程,需要根据具体的业务特征、流量规模、团队技术栈等因素,灵活组合运用这些技术方案。每个方案的选择与落地都充满了权衡与细节,这也正是架构设计的挑战与魅力所在。希望这篇梳理能为你提供一些清晰的思路。如果你对其中某个技术点有更深入的兴趣,欢迎在 云栈社区 与更多开发者一起交流探讨。
 发表于 2026-3-18 07:59:08
|
查看: 136|
回复: 0
发表于 2026-3-18 07:59:08
|
查看: 136|
回复: 0
