缓存,与消息队列、分库分表并称为高并发解决方案的“三剑客”。
它之所以能让系统“更快”,核心在于做到了以下两点:
- 减小 CPU 消耗:将需要实时计算的结果提前算好,或对公用数据进行复用,从而减少CPU消耗,提升响应速度。
- 减小 I/O 消耗:将对网络、磁盘等慢速介质的访问,转变为对内存等快速介质的访问,直接提升响应性能。
在应用系统设计中,缓存通常被划分为两大类:本地缓存和分布式缓存。
- 本地缓存:缓存组件与应用程序在同一进程内,读写速度极快,几乎没有网络开销。缺点是每个应用或集群节点都需维护自己独立的缓存,无法共享。
- 分布式缓存:缓存作为独立于应用的服务或组件部署,多个应用可以共享同一份缓存数据。
本文将深入探讨这两类缓存,结合具体的技术栈与实战案例,希望能帮助你在不同的业务场景下,做出更合理的缓存技术选型。
1 本地缓存的起点:JDK Map
在Java中,使用JDK自带的Map是实现缓存最直接的方式。
- HashMap:基于哈希表,提供了快速的插入、查找和删除操作。可以将键值对作为缓存项存储。
- ConcurrentHashMap:线程安全的
HashMap,能在多线程环境下保证高效的并发读写,是构建本地缓存的基础数据结构之一。
- LinkedHashMap:有序的
HashMap,可以按插入顺序或访问顺序遍历,可用于实现简单的LRU(最近最少使用)缓存。
- TreeMap:基于红黑树的有序Map,可按键的顺序遍历。
我曾负责过一个红包系统,其中的红包活动信息就是使用 ConcurrentHashMap 来缓存的,并通过定时任务刷新。
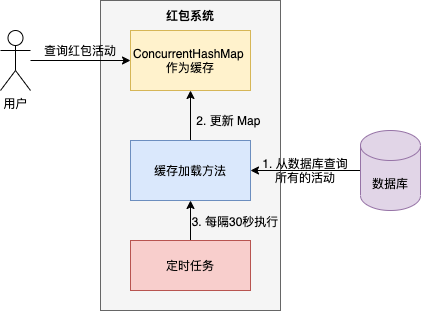
核心流程非常简单:
- 系统启动时,初始化一个
ConcurrentHashMap作为活动缓存。
- 从数据库查询所有红包活动,存入Map。
- 启动定时任务,每隔30秒执行缓存加载方法,刷新Map中的数据。
为什么选择这个方案?
- 红包系统属于高并发应用,从内存直接响应请求能极大提升用户体验。
- 红包活动总数有限,全部放入内存也不会导致溢出。
- 定时刷新缓存对业务逻辑无侵入性,实现简单。
许多单体应用都采用过类似的方案,其最大优点就是简洁、易用、实现成本低。
2 功能进阶:专业的本地缓存框架
尽管JDK Map能快速搭建缓存,但其功能较为单一。在实际开发中,我们往往需要缓存具备统计信息、过期失效、多样的淘汰策略(如LRU、LFU)等高级功能。
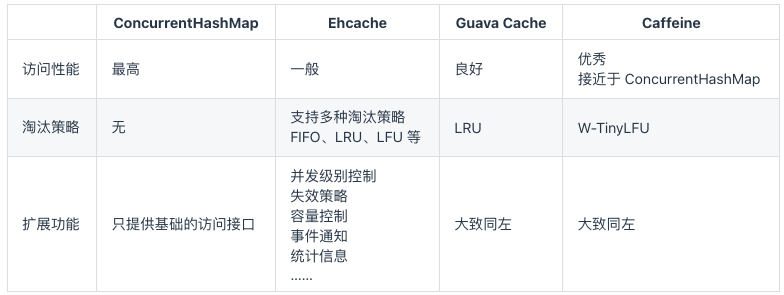
于是,专业的本地缓存框架应运而生。在Java生态中,Ehcache、Google Guava Cache和Caffeine是其中最流行的几个选择。
下面是一个使用Caffeine创建缓存的简单示例:
public class CacheDemo {
public static void main(String[] args) {
//创建一个缓存,最大容量为1000,过期时间为5分钟
Cache<String, Object> cache = Caffeine.newBuilder()
.maximumSize(1000)
.expireAfterWrite(5, TimeUnit.MINUTES)
.build();
// 向缓存中添加数据
cache.put("key1", "value1");
cache.put("key2", "value2");
cache.put("key3", "value3");
// 从缓存中获取数据
String value1 = (String) cache.getIfPresent("key1");
String value2 = (String) cache.getIfPresent("key2");
// 删除缓存中的数据
cache.invalidate("key3");
// 获取缓存统计信息
CacheStats stats = cache.stats();
System.out.println("缓存命中次数:" + stats.hitCount());
System.out.println("缓存未命中次数:" + stats.missCount());
System.out.println("缓存命中率:" + stats.hitRate());
System.out.println("缓存未命中率:" + stats.missRate());
}
}
尽管本地缓存框架功能强大,但其固有的缺陷依然存在:
- 缓存冷启动问题:在高并发场景下,应用重启后本地缓存失效,所有请求直接压向后端数据库或服务,可能导致系统负载激增,恢复缓慢。
- 数据一致性问题:在集群部署时,每个节点维护自己的缓存副本,数据同步会变得非常棘手。
3 应对共享与扩展:分布式缓存
分布式缓存将缓存数据分布到多台机器上,形成一个集群,以此提供更大的容量和更强的并发读写能力。如今,Redis几乎是分布式缓存的首选,其高性能和丰富的数据结构深受开发者喜爱。
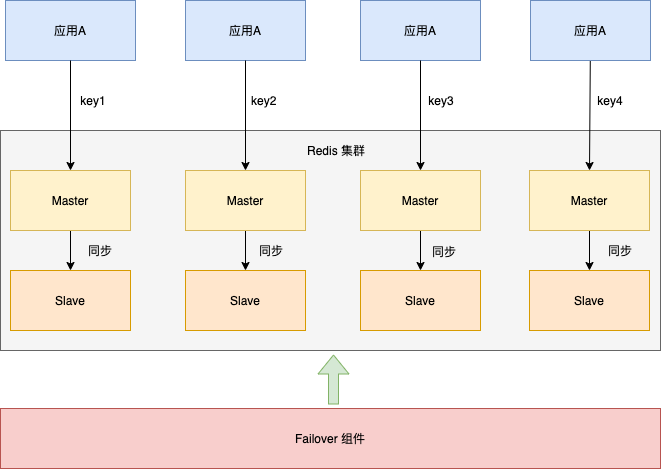
下图展示了一个经典的Redis高可用集群架构(参考自某专车订单系统)。将Redis集群分为多个分片,每个分片采用一主一从模式,主从可切换,并通过Failover组件保障高可用。应用根据不同的Key访问对应的分片。
与本地缓存相比,分布式缓存的优势很明显:
- 容量与性能可扩展:通过增加集群节点,可以水平扩展缓存容量和处理能力,并且数据对所有应用节点共享。
- 高可用性:数据分布在多台机器上,单点故障不会导致整个缓存服务不可用。
当然,它的缺点也同样突出:
- 网络延迟:每次读写都需要网络通信,相较于本地缓存,响应时间更长,受网络波动影响。
- 系统复杂性:引入了序列化/反序列化、数据分片、集群管理、运维监控等一系列新的复杂度。
这里分享一个让我对分布式缓存理解加深的真实案例。
2014年,一个同事开发的比分直播系统,所有数据都从Memcached(分布式缓存)读取后直接返回。平时很快,但在线用户一多,系统就变得异常卡顿。
使用jstat排查后发现GC频率极高,新生代很快被填满,CPU大量消耗在GC线程上。初步判断是缓存对象过大。果然,单个缓存值竟有300k到500k之大。
优化过程分了两步:
- 调整JVM参数并精简数据:将新生代内存从2G扩大到4G,同时将缓存数据大小从平均300k压缩到80k左右。
- 拆分缓存策略:将数据拆分为“全量数据”和“增量数据”。页面首次加载拉取全量数据,后续比分变化通过WebSocket推送微小的增量数据。
这次经历让我深刻认识到:缓存虽快,但在高并发下,缓存对象的大小和读取策略至关重要,处理不当极易引发性能事故,需要精细地控制以减少GC压力。
4 融合之道:多级缓存
开源中国早期全站使用Ehcache作为本地缓存。但随着流量增长,一个严重问题暴露出来:“每次发布重启Java应用,Ehcache缓存清空,大量请求瞬间打向数据库,极易导致数据库崩溃。”
为此,他们开发了多级缓存框架 J2Cache,采用 Ehcache (L1) + Redis (L2) 的架构。
多级缓存的核心优势在于:
- 就近访问:数据离用户越近,速度越快。
- 减少消耗:降低对分布式缓存的查询频率,减少了序列化/反序列化的CPU消耗和网络IO开销。
其标准工作流程如下:先查询一级(本地)缓存,命中则直接返回;未命中则查询二级(分布式)缓存,命中后回填到一级缓存再返回;若二级缓存也未命中,则查询数据源,并将结果回填至一、二级缓存。
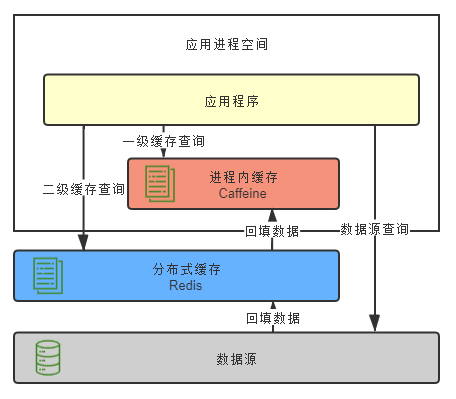
2018年,我曾为一家电商公司优化App首页接口,也采用了类似的两级缓存模式,并利用Guava Cache的惰性加载机制。架构如下图所示:
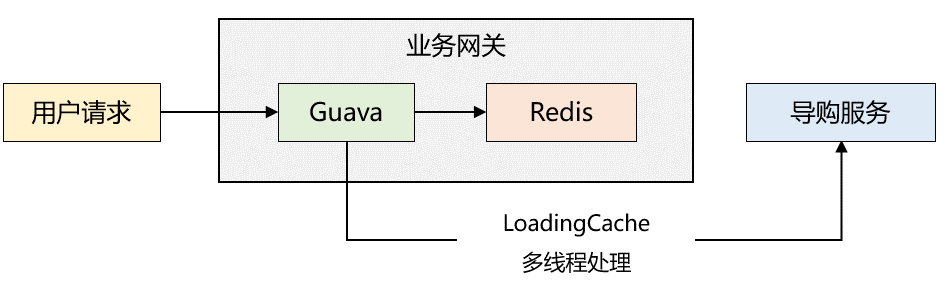
缓存读取流程:
- 网关启动/预热:本地缓存为空,查询Redis。若Redis也为空,则RPC调用导购服务获取数据,并写入本地缓存和Redis。
- 正常请求:直接读取已预热的本地缓存,快速返回。
- 定时刷新:Guava Cache配置了refresh策略,定期(如后台线程池)调用导购服务同步数据,更新本地缓存和Redis。
优化后接口平均耗时约5ms,效果显著。但后来我们发现了一个问题:App首页数据会偶尔出现不一致。
这说明了两点:
- 各服务器节点的Guava Cache惰性刷新并不同步,仍会导致数据不一致。
- 配置的
LoadingCache线程池参数不合理,可能引起了线程堆积。
最终解决方案是:
- 惰性加载结合消息通知:当导购服务数据变更时,主动通知业务网关,触发缓存更新,而非仅依赖定时拉取。
- 线程池调优与监控:调整并监控
LoadingCache的线程池参数,设置告警,实现动态调整。
5 总结与思考
软件工程界有一篇经典论文——《没有银弹》。它强调,没有任何一种技术或方法能解决所有问题。
缓存同样是一把双刃剑。一方面,它显著提升了系统性能;另一方面,它也引入了缓存失效、更新、一致性等复杂性问题。
因此,在面对缓存技术选型时,绝不能盲目追求单一方案的“强大”。你需要综合考虑业务场景(数据量、一致性要求、访问模式)、研发运维成本、团队技术储备等多种因素。无论是简单的ConcurrentHashMap、功能丰富的Caffeine,还是强大的Redis集群,或是灵活的多级缓存,都是工具箱中的选项,关键在于是否“适合”。
在云栈社区中,你可以找到更多关于系统架构和具体技术栈的深度讨论与实战分享,帮助你在实际项目中做出更明智的决策。
 发表于 2026-3-18 08:01:15
|
查看: 108|
回复: 0
发表于 2026-3-18 08:01:15
|
查看: 108|
回复: 0
