在高并发场景下,巧妙地利用缓存批量查询技巧能够显著提高系统性能。细粒度的缓存使用是每位开发者都应掌握的技能。本文将深入探讨 Redis 中几种不同的批量查询技巧,分析它们各自的适用场景与优劣,希望能为你的技术选型带来启发。
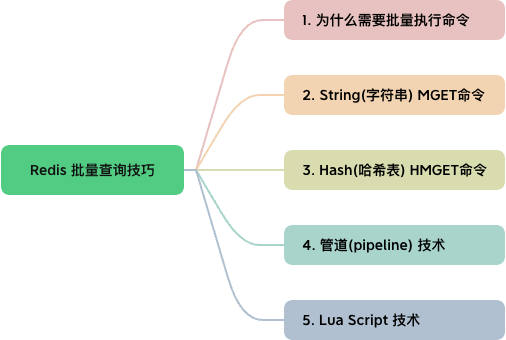
1. 为什么需要批量执行命令?
传统的 Redis 交互流程如下:客户端发送单个命令,服务端接收、执行后返回结果,如此循环往复。
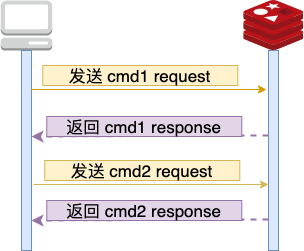
批量执行命令主要有以下三点优势:
- 提高命令执行效率:最直接的收益是减少了网络往返次数(RTT)。单个命令的往返包含网络传输、协议解析等开销,批量操作将多次开销合并为一次,显著提升了整体响应速度。
- 简化客户端逻辑:将多个离散的命令封装成一个操作,使得客户端代码逻辑更清晰、更易于维护,避免了在业务代码中处理多次异步回调或循环等待。
- 提升事务性能:对于需要保证一组命令原子执行的场景,批量操作能确保它们在服务端同一时间内被处理,这对于维护数据一致性尤为重要。
接下来,我们将详细讲解四种实现批量查询的方式:字符串 MGET 命令、哈希表 HMGET 命令、管道技术以及 Lua 脚本。
2. 字符串 MGET命令
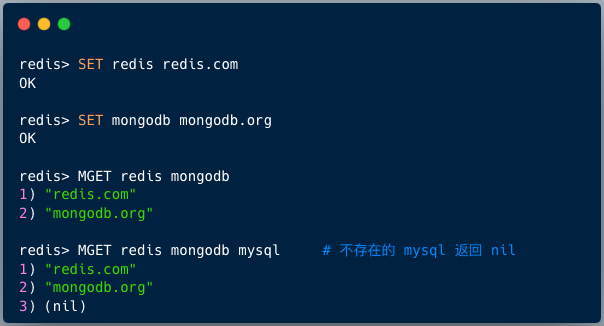
MGET 是 Redis 中用于批量获取多个字符串键的值的原子命令。它接受一个或多个键作为参数,并返回一个按顺序对应这些键的值的列表。如果某个键不存在,则其对应位置返回 nil。
命令基本语法如下:
MGET key1 [key2 ... keyN]
key1, key2, ..., keyN:需要获取值的键名列表。
通过一个命令获取多个值,可以有效减少多次单独查询的网络开销。
SpringBoot 项目示例
在实际的 Java 项目中,我们可以使用 Spring Data Redis 提供的 RedisTemplate 来方便地操作。
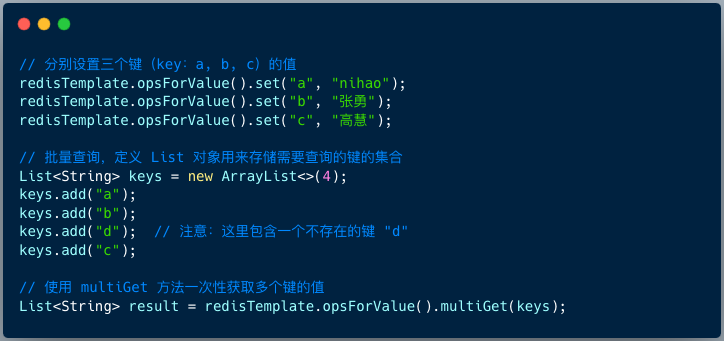
如上图代码所示,我们首先设置了三个键 a, b, c 的值,然后定义了一个包含四个键(其中 d 不存在)的 List 集合,最后使用 multiGet 方法一次性获取所有值。
执行后,结果会封装在一个 List 对象中。
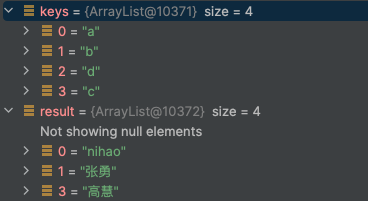
可以看到,返回的 List 大小为 4,顺序与查询的键列表一致。对于不存在的键 d,其对应的值显示为 null(对应 Redis 的 nil)。
3. 哈希表 HMGET命令
当数据存储在 Redis 的 Hash 结构中时,我们可以使用 HMGET 命令来批量获取同一个哈希键下的多个字段值。
命令基本语法如下:
HMGET key field1 [field2 ... fieldN]
key:哈希表的键名。field1, field2, ..., fieldN:需要获取值的字段名。
如果某个字段不存在或哈希表 key 本身不存在,对应的返回值将是 nil。

SpringBoot 项目示例
在 Spring Data Redis 中,可以通过 opsForHash() 来操作哈希结构。
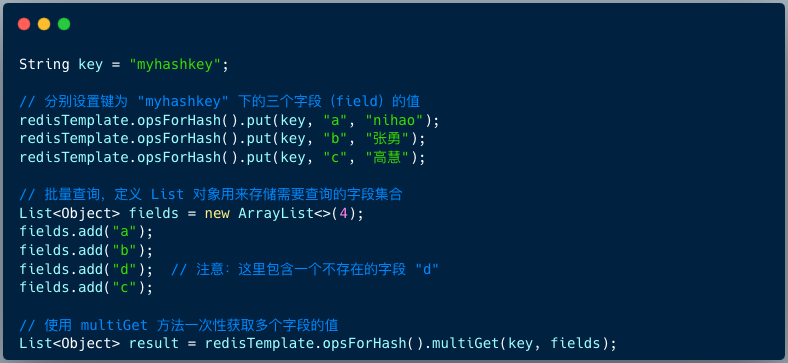
代码中,我们首先向名为 myhashkey 的哈希表中设置了三个字段 a, b, c 的值。然后,定义了一个包含四个字段(其中 d 不存在)的查询列表,调用 multiGet 方法进行批量查询。
查询结果同样以 List 对象的形式返回,其大小与查询的字段列表一致,不存在的字段 d 对应的值为 null。
4. 管道技术
MGET 和 HMGET 是针对特定数据结构的批量命令。而 Pipeline(管道) 是一种更通用的网络优化技术,它允许客户端将多个任意类型的 Redis 命令一次性发送给服务器,服务器依次执行后,再将所有结果打包一次性返回给客户端。
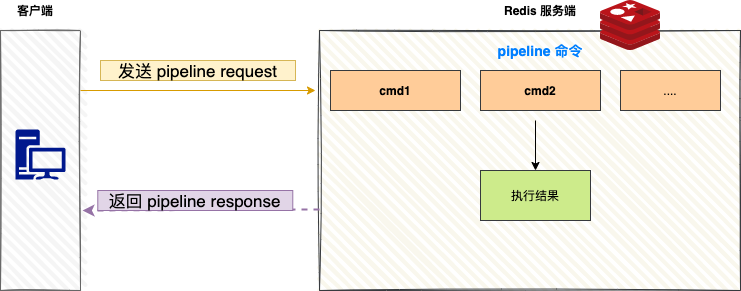
使用 Pipeline 的核心优势在于,它将多次网络往返时间(RTT)压缩为一次,公式可以简化为:
1 次 pipeline(n条命令) = 1 次网络时间 + 执行n 条命令时间
在高并发或对延迟敏感的场景下,性能提升效果非常显著。对于高并发系统设计来说,这是优化与Redis交互的常用手段。
SpringBoot 项目示例
下面的代码展示了如何使用 RedisTemplate 执行 Pipeline 操作,混合查询字符串和哈希数据。
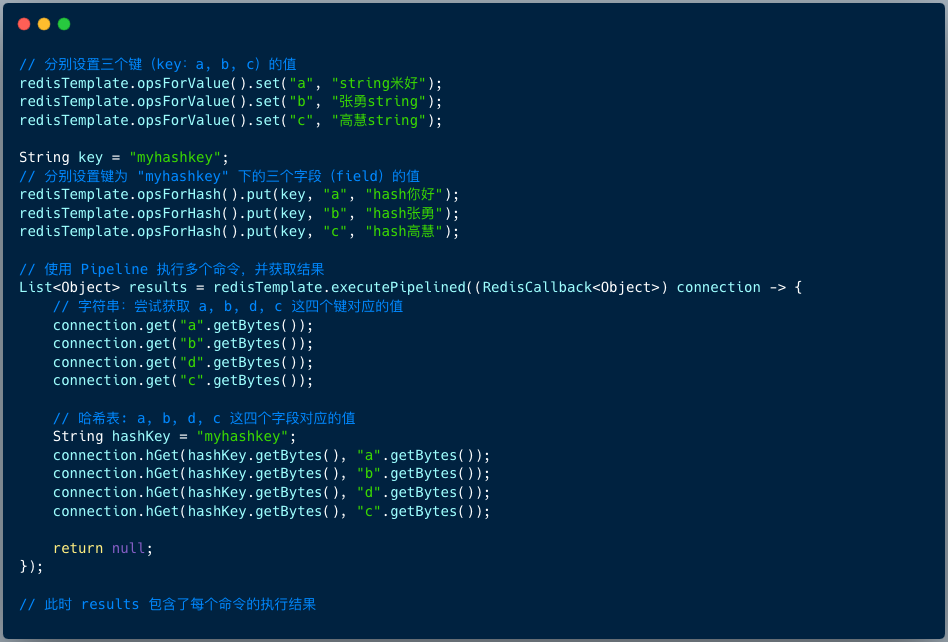
在这段代码中,我们通过 executePipelined 方法一次性提交了 8 条命令(4条GET,4条HGET)。所有命令会在服务端队列中依次执行。
执行完成后,结果会按照命令提交的顺序,封装在一个 List 对象中返回。

使用 Pipeline 的注意事项
- 原子性:在 Redis Cluster 集群模式下,Pipeline 无法保证原子性。因为不同的 key 可能分布在不同节点的哈希槽上,命令实际上是在不同节点上分别执行的。
- 命令依赖:Pipeline 中的命令虽然会按顺序发送和执行,但无法实现后一个命令依赖前一个命令执行结果的逻辑。所有命令在发送时就已经确定。
- 数量限制:虽然理论上可以打包大量命令,但实践中需考虑网络包大小和服务端缓冲区。建议单次 Pipeline 的命令数量不宜过多(例如不超过500条),需根据实际命令数据大小进行调整。
5. Lua 脚本
Redis 自 2.6 版本起支持 Lua 脚本。你可以在服务器端执行一段 Lua 代码,这段代码中可以包含多个 Redis 命令。Lua 脚本在 Redis 中是以原子性方式执行的,中途不会被其他命令插入,非常适合需要复杂原子操作的场景。
Redis 执行 Lua 脚本有两种方式:Eval 和 EvalSHA。
5.1 Eval
EVAL 命令是直接执行给定的 Lua 脚本字符串。
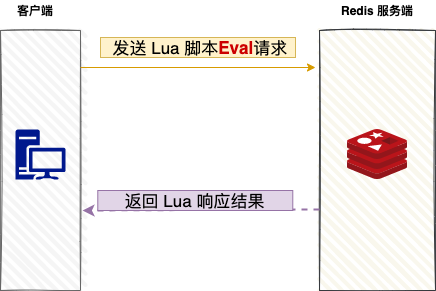
其命令格式为:
EVAL script numkeys key [key ...] arg [arg ...]
script:Lua 脚本字符串。numkeys:后续 key 参数的数量。key [key ...]:作为键名参数传入脚本,在脚本中可通过 KEYS[1]、KEYS[2] 访问。arg [arg ...]:作为附加参数传入脚本,在脚本中可通过 ARGV[1]、ARGV[2] 访问。
在 Lua 脚本中,通过 redis.call() 函数来调用 Redis 命令。
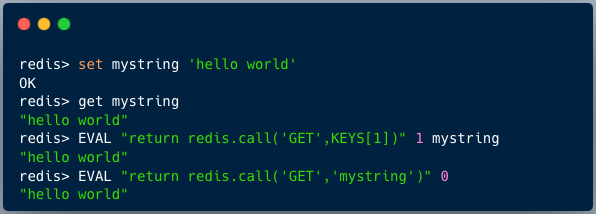
5.2 EvalSHA
EVALSHA 命令通过脚本的 SHA1 校验和来执行之前已经加载过的脚本,避免了每次传输冗长脚本内容带来的网络开销。
使用步骤分为两步:
1. 加载脚本并获取 SHA1:
SCRIPT LOAD "local key = KEYS[1] local value = ARGV[1] redis.call('SET', key, value)"
执行后会返回一个 SHA1 字符串,如 a1104f2250e5dd9fc10c3c681ddb389e7bd4a2cf。
2. 使用 SHA1 执行脚本:
EVALSHA a1104f2250e5dd9fc10c3c681ddb389e7bd4a2cf 1 mykey myvalue
5.3 SpringBoot 项目示例
以下示例演示了如何在 Java 中编写并执行一个复杂的 Lua 脚本,同时批量查询字符串和哈希数据。
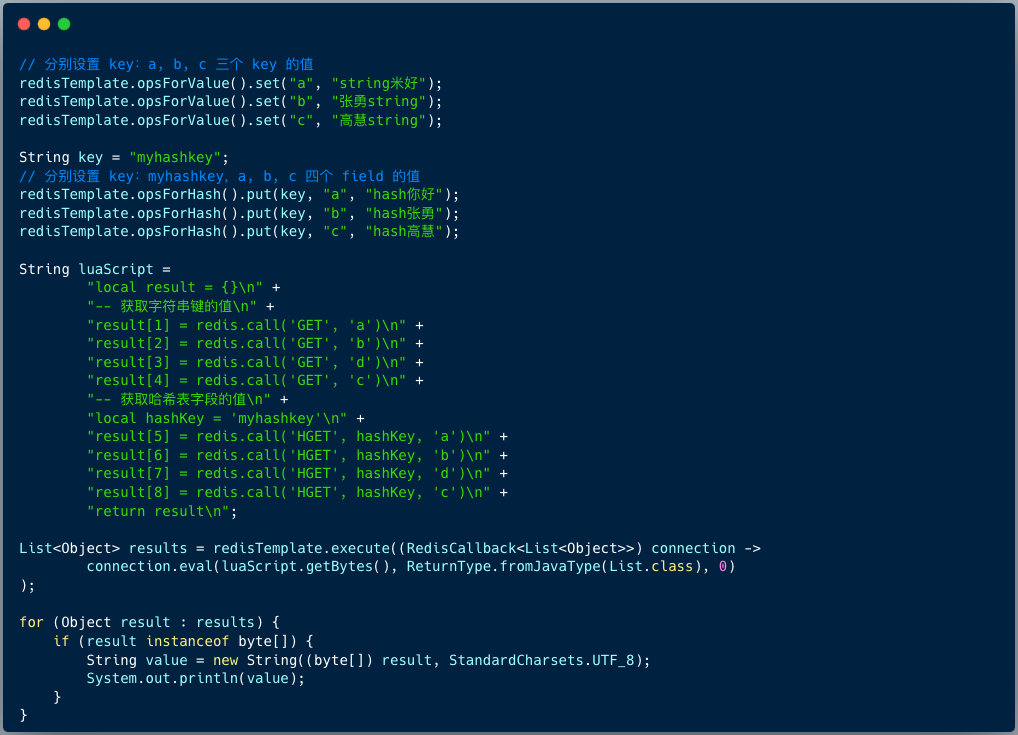
这段代码首先准备了一些测试数据,然后拼接了一个 Lua 脚本字符串。该脚本内部依次调用了 GET 和 HGET 命令,并将结果放入一个 Lua 表中返回。最后通过 redisTemplate.execute 方法执行该脚本,并处理返回的字节数组结果。
6. 总结与选择
本文探讨了 Redis 中四种主流的批量查询技术,它们各有特点和最佳适用场景:
- MGET:最简单直接,专用于批量获取字符串键的值。适用于键名已知且数据结构简单的场景。
- HMGET:专用于批量获取同一个哈希键下的多个字段值。是操作 Hash 结构时的首选批量方法。
- Pipeline:最通用的网络优化技术。可以批量执行任意类型、无相互依赖的命令,能最大限度减少网络 RTT,是提升整体吞吐量的利器。但需注意在集群环境下的限制。
- Lua脚本:功能最强大的原子操作工具。它不仅能批量执行,还能在脚本内实现复杂的逻辑判断和命令间依赖,保证原子性。代价是脚本的编写、调试和维护相对复杂,且需要注意脚本执行的性能。
在选择时,可以遵循这个简单的思路:如果只是简单的字符串或哈希批量获取,用 MGET/HMGET;如果需要批量执行多种命令且无需原子性,用 Pipeline;如果批量操作需要强原子性或复杂逻辑,则使用 Lua 脚本。
掌握这些技巧并合理运用,能帮助你在设计高并发系统时,更好地驾驭 Redis 这一强大的缓存与数据库中间件,构建出更高效、更稳健的应用。如果你想深入探讨更多系统设计与中间件话题,欢迎到 云栈社区 与更多开发者交流学习。
 发表于 2026-3-18 08:03:49
|
查看: 101|
回复: 0
发表于 2026-3-18 08:03:49
|
查看: 101|
回复: 0
