这篇文章,我们聊聊 Mybatis 动态 SQL,以及围绕它展开的几点编程思维思考。从一次线上事故的复盘出发,探讨如何更安全、更优雅地使用这项技术,希望能给你带来一些启发。
1. 什么是 Mybatis 动态SQL
如果你曾直接使用过 JDBC 或其他类似框架来拼接 SQL,一定体会过其中的痛苦:要小心翼翼地处理空格,还得时刻注意去掉列表末尾多余的逗号。
MyBatis 借助强大的 OGNL 表达式,能够根据传入的参数条件,动态地生成最终要执行的 SQL 语句。它最常见的应用场景,就是根据条件动态构建 WHERE 子句。
例如下面这段映射语句:
<select id="findActiveBlogWithTitleLike" resultType="Blog">
SELECT * FROM BLOG
WHERE state = 'ACTIVE'
<if test="title != null">
AND title LIKE #{title}
</if>
</select>
这条语句提供了一个可选的查询功能。如果不传入 title 参数,那么所有状态为 “ACTIVE” 的博客都会被返回。如果传入了 title 参数,则会在标题列上进行模糊匹配,返回相应的结果。
如果我们希望同时支持通过 title 和 author 两个参数进行搜索,只需再增加一个条件判断即可:
<select id="findActiveBlogLike" resultType="Blog">
SELECT * FROM BLOG
WHERE state = 'ACTIVE'
<if test="title != null">
AND title LIKE #{title}
</if>
<if test="author != null and author.name != null">
AND author_name LIKE #{author.name}
</if>
</select>
为了让动态条件拼接更优雅,我们还可以使用 <where> 标签。它只会在其内部包含的子元素返回内容时,才插入 WHERE 关键字。更棒的是,如果子元素返回的 SQL 片段以 AND 或 OR 开头,<where> 标签会自动将它们去除,避免语法错误。
<select id="findActiveBlogLike" resultType="Blog">
SELECT * FROM BLOG
<where>
<if test="state != null">
state = #{state}
</if>
<if test="title != null">
AND title LIKE #{title}
</if>
<if test="author != null and author.name != null">
AND author_name LIKE #{author.name}
</if>
</where>
</select>
当然,MyBatis 还支持 choose (when, otherwise)、trim (where, set)、foreach 等其他动态 SQL 标签,这里就不一一展开详述了。
2. 人生第一次线上 OOM 事故
我曾负责维护一家电商公司的用户中心模块,主要提供用户注册、查询、修改等基础功能。
那个年代,像 Dubbo 这样的 RPC 框架还未普及,服务间多以 HTTP 接口形式交互,数据格式则是 XML。为了提升开发效率,我设计了一个“通用”查询接口 getUserByConditions,它支持通过用户名、昵称、手机号、用户编号等多个条件来查询用户信息,目的是为了实现接口的“复用”。
当时使用的是 iBATIS(MyBatis 的前身),对应的 SQL 映射配置如下:
<select id="selectLotteryUser" parameterType="map" resultType="LotteryUser">
SELECT * FROM t_lottery_user t WHERE 1 = 1
<isNotEmpty prepend="AND" property="userName">user_name = #{userName}</isNotEmpty>
<isNotEmpty prepend="AND" property="id">id = #{id}</isNotEmpty>
<isNotEmpty prepend="AND" property="nickName">nick_name = #{nickName}</isNotEmpty>
<isNotEmpty prepend="AND" property="mobile">mobile = #{mobile}</isNotEmpty>
</select>
这种以 WHERE 1 = 1 开头的写法很常见,目的就是为了方便后续使用 AND 无条件地拼接其他查询条件。
然而,就是这个“便捷”的接口,上线后每隔几小时就会引发一次内存溢出(OOM)告警。通过与 DBA 沟通分析日志,我们发现服务高频次地执行了用户表的全表扫描,生成的 SQL 变成了这样:
SELECT * FROM lottery_users WHERE 1 = 1
继续追查发现,问题根源在于前端传参时出现了空字符串,而我的后端代码中竟然没有对参数进行任何校验。结果就是,当所有条件参数都为空时,动态 SQL 中所有 <isNotEmpty> 判断都不成立,最终执行的 SQL 只剩 WHERE 1 = 1,直接导致了千万级数据表的全表查询。几个这样的请求下来,服务内存很快就被撑爆了。
最终的解决方案其实很简单:在服务端接收参数时,加上必要的校验逻辑。
事故虽然迅速解决了,但它带给我的震撼和教训却持续至今。我依然记得当时站在运维同事身边,看着他不断调整 JVM 参数、反复重启服务的场景,内心满是羞愧。我暗自发誓,绝不能再让类似的事情发生。
这次事故也促使我对动态 SQL 的使用进行了更深入的思考,我的编程思维大致经历了以下三个阶段的演变:
- 前后端参数校验必须到位
- 在代码复用和接口专用性之间寻求平衡
- 建立主动的防御性编程意识
3. 前后端参数校验
在现代前后端分离的开发模式下,我们人为地将系统拆分,交由不同的团队负责。这虽然提升了开发效率,但也常常导致出现问题时,前后端开发者互相“甩锅”。
要让系统真正健壮,前后端必须同时、且独立地进行接口参数校验。特别强调一点:后端校验是必须的,是底线。当团队上下都遵循这条铁律时,系统出问题的风险将大大降低。
1. 前端校验
前端校验的核心价值在于提升用户体验。例如,用户输入一个邮箱地址,我们可以立即在前端用 JavaScript 验证其格式是否合法,无需等待网络请求往返。这种即时反馈能有效避免用户提交明显错误的数据。
但必须清醒地认识到,前端校验无法替代后端校验。在 B/S 架构中,用户可以轻易地绕过浏览器界面,直接向接口地址发送请求并传递任意非法参数。因此,前端校验是“锦上添花”,后端校验才是“雪中送炭”。
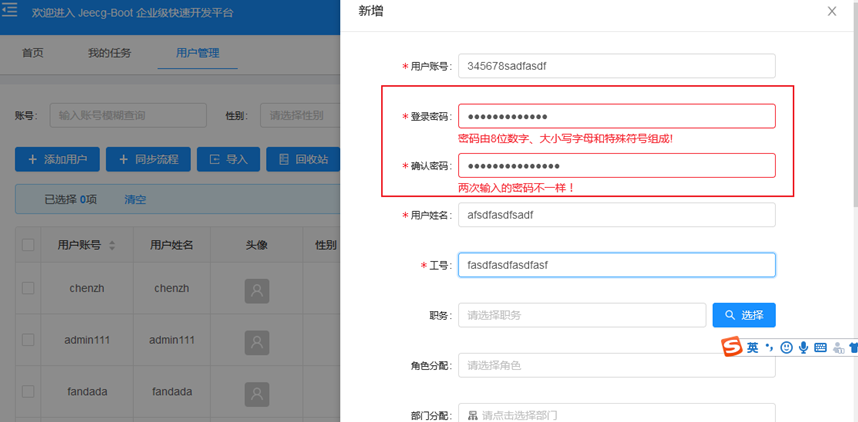
2. 后端校验
后端必须做参数校验。 这句话值得重复三遍,因为它至关重要。
数据在网络传输过程中存在被篡改的风险,也可能本身就因业务逻辑不满足要求。如果不做后端校验,轻则导致系统异常,重则可能引发严重的业务事故。
在 Spring Boot 项目中,我们可以方便地使用 Hibernate Validator 进行声明式参数校验。对于使用 @RequestBody 接收参数的 POST、PUT 请求,我们通常会定义一个 DTO(数据传输对象)来封装参数。只要在 DTO 类的字段上声明约束注解,并在控制器方法参数上添加 @Validated 或 @Valid 注解,就能实现自动校验。
例如,假设有一个保存用户的接口,要求 userName 长度在 2-10 之间,account 和 password 长度在 6-20 之间。我们可以这样定义 DTO:
@Data
public class UserDTO {
private Long userId;
@NotNull
@Length(min = 2, max = 10)
private String userName;
@NotNull
@Length(min = 6, max = 20)
private String account;
//每个注解对应不同的校验规则,并可制定校验失败后的信息:
@NotNull(message = "用户密码不能为空")
@Length(min = 6, max = 20)
private String password;
}
然后在控制器方法中启用校验:
@PostMapping("/save")
public Result saveUser(@RequestBody @Validated UserDTO userDTO) {
// 校验通过,才会执行业务逻辑处理
return Result.ok();
}
通过接口层面的参数校验,我们能有效保证传入动态 SQL 的参数是符合预期的。但这里还有一个潜在的陷阱:如果我们仅仅是在复用某个已经写好的 SQL 映射方法(Dao 方法),而调用方传递了错误的参数,依然可能导致非预期的查询结果(比如 WHERE 1=1 全表查询)。
当然,我们可以考虑更底层的解决方案,例如使用 MyBatis 拦截器 来统一处理,但这无疑会增加系统的复杂度。因此,我转向了另一个角度的思考:如何在复用和专用之间取得平衡?
4. 复用和专用要做平衡
回顾我之前设计的 getUserByConditions 接口,它为了追求“通用”和“复用”,同时支持四种不同条件的查询。初衷是为了“省时间,快点出活”。
但随着工作经验积累,我的编程习惯逐渐改变。对于业务场景明确、查询条件固定的需求,我现在更倾向于将“通用接口”拆分成多个“专用接口”。
例如,getUserByConditions 完全可以拆分成下面四个独立的接口:
getUserById:按照用户 ID 查询getUserByNickName:按照用户昵称查询getUserByMobile:按照手机号查询getUserByUserName:按照用户名查询
以按用户 ID 查询为例,其 SQL 映射就可以简化得非常清晰:
<select id="selectLotteryUserById" parameterType="java.lang.Long" resultType="LotteryUser">
SELECT * FROM t_lottery_user t where t.id = #{id}
</select>
通过这样的拆分,接口设计变得更加细粒度和专注,代码的可读性和可维护性都得到了提升。更重要的是,它从根本上规避了 WHERE 1 = 1 这种写法带来的不确定性风险(即便做了参数校验,复杂的条件组合仍可能产生意料之外的 SQL)。
可能有人会问:拆得这么细,岂不是大大增加了编写接口和 SQL 映射文件的工作量?
我的思路是:将重复劳动交给工具。完全可以定制或使用现有的代码生成器,根据数据库表结构,自动生成粒度更细、更贴合具体业务场景的 Mapper 接口和 SQL 映射文件,从而在保持开发效率的同时,获得更高质量的代码。
5. 防御性编程意识
刚入行时,我常常只是机械地完成功能需求,很少深入思考一段代码背后会占用多少系统资源,是否可能埋下隐患。
随着接触和参与维护的系统越来越多,并深入研究了许多优秀的开源项目,我慢慢养成了一种习惯:在写代码时,会下意识地问自己两个问题:
- 这段代码执行时会占用多少 CPU、内存、I/O 或数据库连接等资源?
- 可能存在哪些潜在风险?我该如何提前规避,做好预防?
这其实和玩一些竞技类游戏时的“意识”很像。
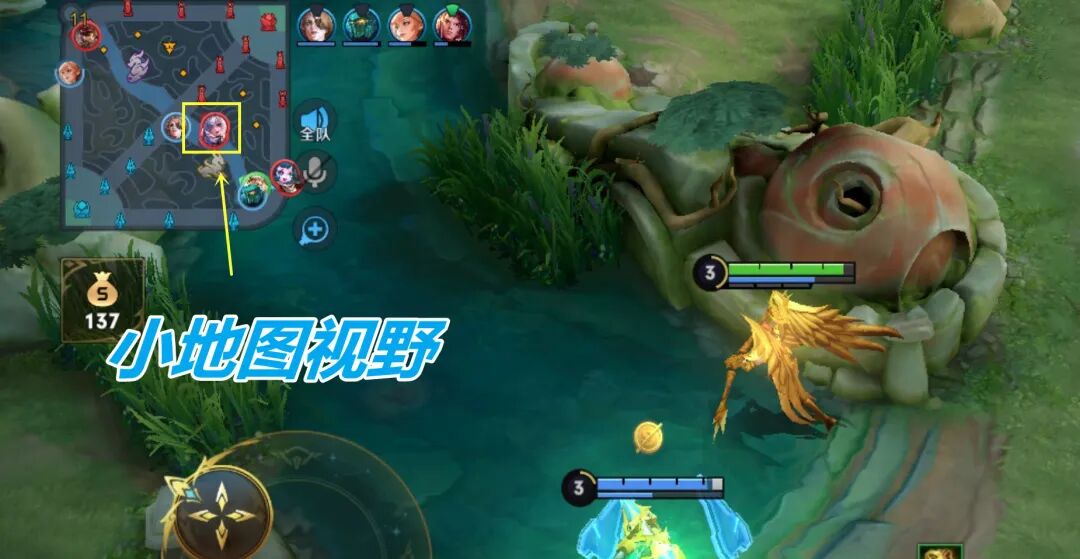
上图是一种常见的游戏情境。我方射手正在和辅助压制对方下路,此时从小地图观察到,敌方中野正朝下路赶来。这个信息告诉我们,对方要么是来“抓人”,要么是来协防。
面对这种情况,如果我方其他队友无法及时支援,最明智的选择就是“避战”,强行接团很可能导致损失。这种通过小地图信息进行分析、预判并做出正确决策的能力,就被称为“意识”。
编程亦是如此。在动手编码之前或之中,主动去思考代码可能引发的资源消耗和潜在风险,并预先采取防范措施,这就是我们应当培养的 “编程意识” 。对于动态 SQL 来说,这种意识就体现在:是否预见到了空参数导致全表扫描的风险?是否为查询添加了必要的索引?是否考虑了大结果集分页?
6. 写到最后
我职业生涯中第一次线上 OOM 事故,直接原因就是在使用 MyBatis 动态 SQL 时,忽略了后端参数校验。这件事给我带来了深刻的教训,也产生了长远的影响。
在之后的开发工作中,为了避免类似的生产环境事故,我一直在有意识地打磨自己的编程思维:
- 坚守后端校验的底线,绝不心存侥幸。
- 在“复用”与“专用”间寻找最佳平衡点,优先保证代码的清晰和健壮。
- 培养主动的防御性编程意识,像下棋一样,多看几步,提前预判风险。
絮絮叨叨说了这么多,或许有人会觉得我小题大做。但现实是,类似的事故至今仍在不断上演,我上周还目睹了一起。
有时会觉得,技术框架越来越强大、越来越丰富,但想要写出真正健壮、可靠的代码,似乎依然不是一件容易的事。这或许值得我们每一位开发者持续思考和精进。如果你对这类技术实践和思维讨论感兴趣,欢迎在 云栈社区 与其他开发者交流碰撞。
参考链接:
 发表于 2026-3-18 08:06:19
|
查看: 146|
回复: 0
发表于 2026-3-18 08:06:19
|
查看: 146|
回复: 0
