在大规模分布式系统中,Kafka 常常扮演着核心数据管道的角色。其百万级TPS(每秒事务处理量)的高吞吐能力是支撑大型架构的关键。这背后究竟有哪些核心技术作支撑?本文将图文结合,深度解析实现这一高性能目标的几个核心机制。
顺序写入:化随机为顺序的磁盘魔法
Kafka 性能卓越的首要秘诀在于其写入模式。它摒弃了传统的随机写入,采用了顺序追加写入(append-only log)的方式来存储消息。这种方式最大限度地利用了磁盘顺序写入远超随机写入的高效性,从而显著降低了I/O开销。
具体来说,Kafka 将消息按照分区(Partition)组织成一个个日志文件。所有的写入操作都只在文件尾部进行追加,消费者则根据偏移量(offset)顺序读取。这种设计完全避免了耗时的磁盘随机寻址操作。
那么,为什么顺序写入如此之快?关键在于机械硬盘的物理特性。随机读写需要磁头频繁移动寻道,这是主要的性能瓶颈。而顺序追加是机械硬盘的最优工作模式,其吞吐量可以达到数百MB/s。此外,Kafka的分区模型天然支持并行处理,多个分区可以分布在不同的Broker和磁盘上,实现并发读写。当分区数量足够多时,这种并行能力可以在集群层面轻松支撑百万级并发。
分区化与并行处理:水平扩展的基石
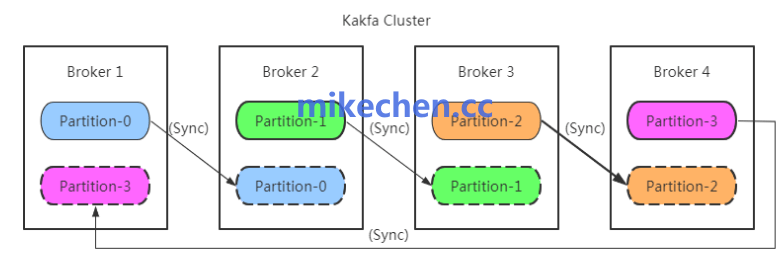
Kafka 的另一个核心设计是分区化。一个主题(Topic)可以被划分为多个分区,每个分区都是一个有序的、不可变的消息序列,并由一个领导者副本(Leader)负责读写操作。
通过增加分区数量和副本数量,Kafka 可以将负载水平分散到整个集群中,从而线性提升系统的整体并发处理能力和吞吐量。同时,分区的独立性使得一个消费者组(Consumer Group)内的多个消费者能够并行消费不同的分区,消费能力也因此得以线性扩展。这是实现高并发消费的关键。
批量传输与压缩:减少开销,提升效率
在高吞吐场景下,逐条处理消息会带来巨大的网络和磁盘I/O开销。Kafka 通过批量处理机制巧妙地解决了这个问题。
生产者(Producer)会将消息在内存中攒批,通过 linger.ms(等待时间)和 batch.size(批次大小)参数来控制。同样,Broker 端批量落盘,消费者端也批量拉取消息。此外,Kafka 还支持在传输过程中对消息批次进行压缩(如 Snappy、LZ4)。
批量与压缩带来的性能提升是显而易见的:
- 摊薄开销:将成百上千条消息合并为一个网络请求或一次磁盘写操作,大幅降低了每条消息的平均开销。
- 节省带宽:压缩可以有效减少网络传输的数据量,提升带宽利用率。
- 异步高效:生产者的异步批量发送模式,减少了对Broker的连接压力和请求次数。
在实际应用中,通常使用默认配置(如每批32KB,等待5ms)就能将单机TPS从万级别提升至百万级别。消费者端通过调大 fetch.max.bytes 参数拉取更大批次的消息,并配合多线程并行消费不同分区,可以进一步压榨系统的并发潜力。
页缓存与零拷贝:极致的内存利用
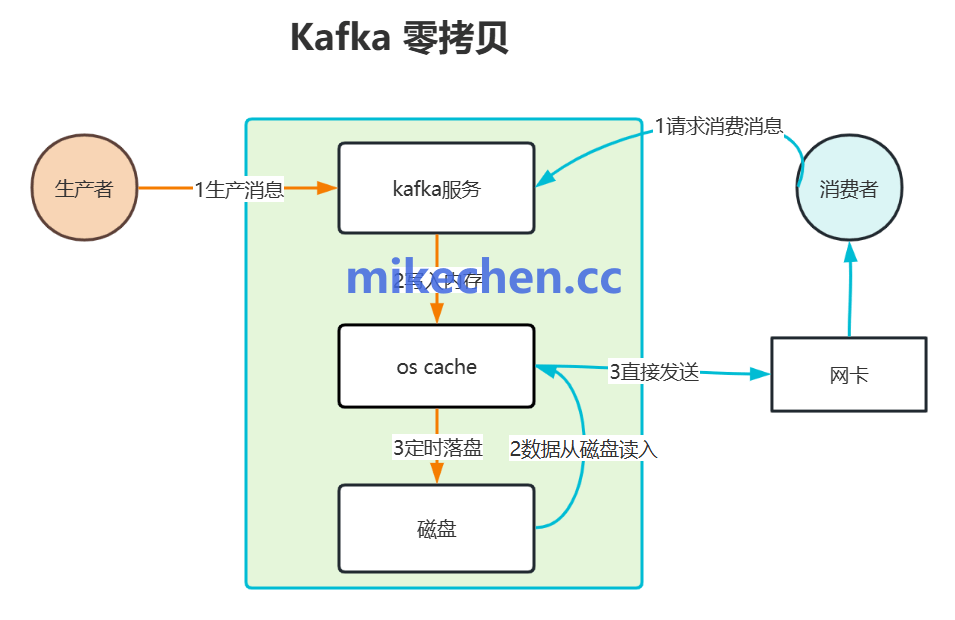
Kafka 并未在应用层(JVM堆内)自行维护复杂的缓存机制,而是选择充分信赖并利用操作系统的页缓存(PageCache)。这是其设计哲学中非常高明的一点。
其工作原理是:Kafka 通过内存映射文件(MMap)将日志文件映射到进程的虚拟地址空间。当写入数据时,实际上是先写入操作系统内核空间的页面缓存中,由操作系统在后台异步地将脏页刷写到磁盘。
这种架构带来了两大核心优势:
- 规避JVM GC开销:大量消息数据驻留在内核态的内存中,不会进入JVM堆,因此完全避免了Java垃圾回收(GC)可能带来的停顿和性能波动,保证了服务的长期稳定性和可预测性。
- “零拷贝”快速消费:当生产者写入的消息还停留在页缓存未落盘时,如果消费者来读取,数据可以直接从页缓存通过DMA(直接内存访问)方式发送到网卡。这个过程跳过了从内核缓存拷贝到用户态应用缓冲区,再从应用缓冲区拷贝到内核Socket缓冲区的步骤,实现了所谓的“零拷贝”(Zero-Copy),使得消费热数据的延迟极低、速度极快。
总结
综上所述,Kafka 的百万级TPS能力并非由单一“黑科技”实现,而是一系列精妙设计协同作用的结果。从顺序写入挖掘磁盘极限,到分区并行实现水平扩展,再到批量压缩优化传输效率,最后依托页缓存与零拷贝实现内存级速度,每一步都直指高性能系统的核心痛点。
理解这些底层原理,不仅能帮助我们在使用Kafka时做出更优的配置和架构决策,也对设计其他高并发、低延迟的数据系统具有重要的借鉴意义。更多的系统架构设计与实践经验,欢迎在云栈社区与广大开发者一同交流探讨。 |  发表于 2026-1-31 10:48:57
|
查看: 173|
回复: 0
发表于 2026-1-31 10:48:57
|
查看: 173|
回复: 0
