性能优化本质上是时间与空间资源的艺术性置换与取舍,最终目标是在业务遇到瓶颈前,利用成熟的技术手段将系统效能提升至预期水平。
本系列将分为两个维度进行探讨。上篇聚焦于六种普适性的“时空”互换策略,下篇则深入四种与提升并行能力紧密相关的进阶方案。每种技术都辅以一张《火影忍者》的趣味配图,希望能让硬核知识更易理解。
上篇:六种普适性优化策略
索引术:以空间换时间

索引的核心原理是牺牲额外的存储空间来换取查询速度。它增加了数据写入时的开销,却能将数据读取的时间复杂度从 O(n) 显著降低到 O(log n) 甚至 O(1)。这就像从一本没有目录的乱序字典中查字与通过拼音目录直接定位页数的区别。
软件世界中,索引的数据结构丰富多样,各擅胜场:
- 哈希表 (Hash Table): 原理类似银行取号,通过哈希函数直接定位,效率可达 O(1)。常见的 K-V 存储及编程语言中的 Map/Dict 多基于此。
- 二叉搜索树 (Binary Search Tree): 如 Java 中的 TreeMap、Linux CPU 调度所用的红黑树,属于有序存储结构。
- 平衡多路搜索树 (B-Tree): 为解决二叉树深度过深的问题而生的多叉树,MongoDB 的索引即采用此结构。
- 叶节点相连的平衡多路搜索树 (B+ Tree): B-Tree 的变体,仅叶子节点存数据,且叶子间相连。这是 MySQL 索引的基石,也被一些 Linux 文件系统用于索引 inode。
- 日志结构合并树 (LSM Tree): 为优化写性能而设计,像日志一样顺序写入,再分层合并。在大数据存储和一些 NoSQL 数据库中应用广泛。
- 字典树 (Trie Tree): 又称前缀树,从根到叶的路径即为数据本身,非常适合前缀匹配和词频统计,常用于自动补全、URL路由。其变体基数树在 Nginx、Redis 中均有应用。
- 跳表 (Skip List): 一种多层有序链表,通过概率“晋升”形成索引,适合高并发写场景。Redis ZSet 的底层即由哈希和跳表组成。
- 倒排索引 (Inverted index): 可称为“关键词索引”,标识每个关键词出现在哪些位置。ElasticSearch 的核心机制和 Prometheus 的按标签查询都依赖于此。
在数据库中使用索引时,需注意以下几点:
- 定义并使用好主键,它通常是效率最高的聚簇索引。
- 在 WHERE、GROUP BY、ORDER BY、JOIN ON 中频繁出现的字段应考虑建立索引或联合索引。
- 重复度过高(如枚举值)或更新过于频繁的列不适合建索引。
- 联合索引可以避免回表,但需注意最左前缀匹配原则。
- 根据数据库特性选择特殊索引,如 MongoDB 的 TTL 索引、Geo 索引等。
这种“空间换时间”的思维同样适用于代码层面,对于大量数据的查找,使用 Set、Map、Tree 等数据结构,本质上就是在利用哈希或树状索引,其性能远高于遍历列表。
缓存术:无处不在的加速

缓存的原理与索引一致,都是用额外的存储空间换取更快的访问速度。设想在浏览器中打开本文,缓存几乎无处不在:DNS 缓存、服务端 KV 缓存、数据库缓冲池、操作系统 Page Cache、磁盘自身缓存、浏览器静态资源缓存、CPU 多级高速缓存…… 从廉价磁盘到昂贵 CPU 缓存,目标都是为了节省宝贵时间。
然而,缓存并非银弹。计算机科学中有句名言:“计算机科学中只有两件困难的事情:缓存失效和命名规范。” 使用缓存会引入额外的复杂度,尤其是缓存失效问题,它可能引发缓存穿透、击穿、雪崩等现象,需要通过空值缓存、布隆过滤器、互斥锁、随机 TTL 等策略来应对。多级缓存之间的数据一致性维护也是挑战。
此外,对象重用的池化技术(如数据库连接池、线程池、Golang 的 sync.Pool)也可视为缓存的变体,通过复用资源来提升性能。
压缩术:以时间换空间
压缩是通过消耗计算时间,换取更紧凑的数据编码方式。为何要以宝贵的时间换取空间?考虑视频网站的例子:若不压缩,巨大的数据量导致的网络传输耗时将远超过编码压缩的时间。更小的空间会在传输维度上带来更大的时间收益,本质上是“网络/内核处理负担”与“CPU/GPU 压缩负担”的权衡。
常见的无损压缩应用场景包括:
- HTTP 协议中的 Gzip 压缩(针对文本资源)。
- HTTP/2 的头部 HPACK 压缩。
- JS/CSS 文件的混淆和压缩(Uglify/Minify)。
- RPC 或消息队列中消息的二进制编码与压缩(如 Snappy, LZ4)。
- JVM 的对象指针压缩(-XX:+UseCompressedOops)。
- MongoDB 的 BSON 编码相比 JSON 也是一种更紧凑的格式。
信息论指出,无损压缩的极限是信息熵。
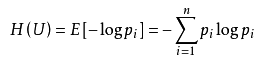
要进一步减小体积,就需要接受信息损失,即有损压缩,例如图片降清晰度、音频 MP3 编码。散列化(如 SHA-256)也可视为一种极端压缩,将不定长数据变成固定长度摘要。
更极端的空间优化是直接减少或删除数据:
- 减少:JS Tree Shaking、使用 HTTP/2、减少 Cookie 和请求头、采用增量更新(PATCH)、使用位图(如 Redis 位图记录用户登录状态)。
- 删除:删除无用数据、索引、日志;减少不必要的网络请求;甚至,终极方案是砍掉整个非核心功能。正如 Kelsey Hightower 所言:“不写代码,是编写安全可靠应用程序的最佳方式。”
预取术:用事先的耗时换首次的极速

预取通常与缓存结合,其原理是在“空间换时间”基础上,再加一次“时间换时间”,即用预先加载的耗时,换取用户第一次访问时的等待时间。就像自助餐厅提前备好菜品,顾客无需等待现做。
典型应用场景:
- 流媒体:播放前缓冲,甚至预测用户下一步行为预加载。
- HTTP/2 Server Push:请求一个主资源时,服务器主动推送相关 CSS、JS 等资源。
- 客户端/服务端预热:常驻进程预加载数据;服务启动时将热点数据载入内存,触发 JIT 编译等。
预取的副作用是可能导致启动变慢、占用闲时资源,以及可能预取了并不需要的数据。
削峰填谷术:错峰的艺术

削峰填谷同样是“时间换时间”,用非高峰期的处理能力来消化高峰期的请求洪峰,就像三峡大坝蓄洪调峰。软件世界中,这通常通过消息队列和异步化实现。
常见场景与解法:
- 前端优化:资源懒加载、分批加载。
- 背压控制(限流):网关层限流、前端按钮防抖、TCP SYN Cookie 防御洪水攻击。
- 业务洪峰缓冲:请求先入消息队列(如 Kafka, RocketMQ),高峰期后再异步消费。
- 捋平内部毛刺:错峰执行定时任务,避免与业务高峰重合。
- 避免错误风暴:实现带指数退避的重试机制,设置合理的超时与降级策略,防止网络抖动恢复后的次生洪峰冲垮系统。
批量处理术:压缩执行流程
批量处理可视作对执行流程的压缩,以减少重复操作。它以单次批处理更长的耗时为代价,换取整体吞吐量的大幅提升。
应用广泛:
- 前端:JS/CSS 打包合并、雪碧图、
requestAnimationFrame 批量更新 UI。
- 前后端交互:队列暂存数据后批量处理;GraphQL 单接口查询多种数据。
- 系统间通信:批量读写缓存(Redis MGET/MSET)、批量数据库插入、消息批量发布。
- 数据持久化:操作系统写文件缓冲、数据库 WAL 日志、NoSQL 的 LSM Tree 合并。
- 资源回收:JVM Survivor 区交换、Redis 过期键清除策略。
关键问题:批量大小如何设定?
这并无定论,需结合实际场景基准测试。例如:前端资源不宜全打包为一个文件,需按需分块;Redis MGET 每批 50-100 个 Key 可能是甜点;MySQL 批量插入每批 5000-10000 条可能效率最佳;消息队列单批长度通常需控制在 1MB 以内。批量处理的副作用在于增加了逻辑复杂性,并需要额外的内存作为缓冲区。
中篇:时空消耗的本质
在探讨进阶优化前,我们需明确:程序运行的时间和空间,究竟消耗在哪里?
时间都去哪儿了?
现代 CPU 频率已达 GHz 级别,每核每秒可执行数十亿条指令。但程序运行不仅依赖 CPU,还涉及内存、存储和网络。不同硬件之间的速度差异是数量级的。
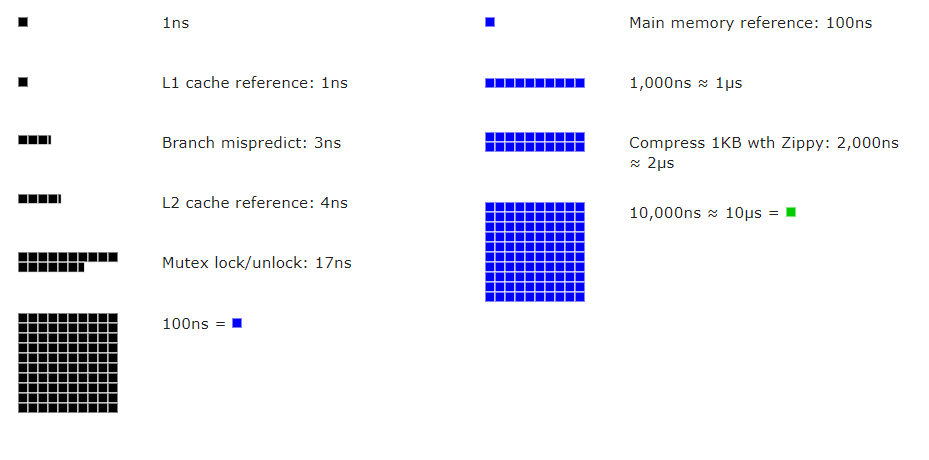

几个关键数据:
- CPU 缓存访问:1-10 纳秒级别。
- 主存(RAM)访问:~100 纳秒。
- SSD 随机读写:10 微秒 - 1 毫秒。
- 局域网往返:~0.5 毫秒。
一次网络传输的时间可能是主存访问的 5000倍。这直观解释了为何在循环中发起 HTTP 请求是极低效的行为。
空间都去哪儿了?
如今,持久化存储空间已不那么稀缺,但内存(RAM)仍是宝贵资源。以 JVM 为例,一个对象的空间开销包括:对象头(Header)、成员变量、对齐填充等。例如,一个含 8 个 int 成员的对象约占 48 字节,10 万个这样的对象就占约 4.58MB。实际应用中,大量内存常消耗在 char[]、集合等数据结构上。
堆外,空间“浪费”无处不在。 即使代码只返回“OK”两个字节,经过 TCP/IP 协议栈各层的封装(IP头至少20字节,以太网帧头至少18字节),最终传输的字节数远大于2。若数据超 MTU 还需分片,空间利用率进一步降低。高层抽象(如虚拟机、动态语言)在带来灵活性的同时,往往以空间利用率为代价。
小结:安迪-比尔定律
理解了时空消耗,还需明白为何软件总能吃光硬件资源。这源于 安迪-比尔定律:“安迪(Intel)给的,比尔(盖茨)全拿走。” 意指软件发展速度总能消化掉硬件进步带来的红利。应用日益复杂,抽象层越来越高,底层基础设施的优化和上层代码的效率愈发重要。
下篇:进阶并行化策略
八门遁甲 —— 榨干单机计算资源

目标:让硬件资源全力处理有效计算,而非空转或无关任务。这涉及从高层代码到底层特性的全方位优化。
-
聚焦:减少系统调用与上下文切换。
- 利用 I/O 多路复用(如 epoll)进行事件驱动,分离 I/O 与计算。
- 使用零拷贝技术减少 CPU 负担。
- 设置 CPU 亲和性,减少缓存失效。
-
蜕变:使用更高效的算法、数据结构和组件。从 Map 替代 List 遍历的微优化,到引入更优算法带来的数量级提升。
-
适应:针对运行时环境优化。
- 浏览器:减少 HTTP 请求、利用 WebSocket、优化 DOM 操作(虚拟 DOM)、避免
eval 等动态特性。
- JVM:编写利于 JIT 编译的代码(如多用静态类型、减少反射)。
- 系统级:调整 JVM/数据库内存参数、优化 Linux 内核参数。
-
运筹:系统性分析与资源调配。
- 最简单直接:选择匹配瓶颈的硬件。CPU 密集型选高频实例,I/O 密集型选高带宽或高 IOPS 实例。考虑 ARM、AMD 等性价比方案。
- 高阶手段:使用更底层特性(FFI、WebAssembly)、利用专用硬件指令(AES-NI)、定制 Runtime、乃至 FPGA 硬件加速。
影分身术 —— 水平扩容

当单机性能达到极限,便需借助“众人拾柴火焰高”的水平扩容。其理论基础是逐渐显效的阿姆达尔定律(Amdahl‘s Law)。前提是应用无状态。通过负载均衡将流量分发到多个副本,并结合监控指标实现自动扩缩容。
奥义 —— 分片术

水平扩容针对无状态服务,分片则用于有状态的数据服务,将数据集拆分到不同节点,进一步提升并行处理能力。这带来了如何选择分片键、处理热点数据、数据再平衡等复杂挑战。从 Java 7 ConcurrentHashMap 的分段锁到分布式数据库的分库分表,都是分片思想的体现。
秘术 —— 无锁术
锁是制约并行度的关键因素。无锁编程旨在避免或减少竞争,最大化并发。
- 减少锁粒度/范围:如秒杀场景将库存预加载到本地内存再细粒度扣减。
- 乐观锁/无锁算法:使用 CAS 操作,如 Java 8+
ConcurrentHashMap。
- Pipeline 技术:让连续操作流水线化,避免相互等待,见于 CPU 流水线、Redis Pipeline。
- 避免全局串行点:如用 QUIC 协议解决 TCP 队头阻塞。
总结
性能优化是一门权衡的艺术。初期就设计出完美的高性能系统几乎不可能。正确的做法是:随着系统演进,借助压测、性能剖析工具(Profiling)和监控,持续定位瓶颈,然后因地制宜地选择 ROI(投入产出比)最高的优化手段。
切记 Linux 性能大师 Brendan Gregg 的告诫:切忌过早优化和过度优化。首先学会规则,然后才能知道何时打破规则。保持观测,做那 80% 高效投入的优化。
本文技术讨论可前往 云栈社区 与更多开发者交流。
 发表于 2026-3-18 08:12:14
|
查看: 102|
回复: 0
发表于 2026-3-18 08:12:14
|
查看: 102|
回复: 0
