作为研发工程师,我们在实现业务需求之外,还肩负着一个至关重要的使命:保障系统性能。试想,一个上线后无法承载预期流量的系统,用户体验和客户满意度都将大打折扣。
谈及性能提升,我们通常会回顾几种经典策略:
- 架构解耦与微服务化:依据领域驱动设计思想,将庞杂的业务域拆分为独立的微服务,通过 RPC 进行调用。无状态的微服务理论上支持水平无限扩展。
- 异步化与响应时间优化:利用消息队列将非核心链路异步化,缩短请求的整体响应时间 (RT = work time + wait time),从而提升系统并发处理能力。
- 数据层拆分与优化:对数据库进行垂直拆分、读写分离乃至分库分表,从存储层面分担压力。
- 引入缓存:这正是我们今天要深入探讨的核心武器。
业内常有“性能不够,缓存来凑”的说法。对于典型的互联网应用而言,缓存往往是解决大多数性能瓶颈的“第一解药”。它见效快、周期短,是软件性能优化中性价比极高的手段。


计算机的核心在于计算与存储,但两者的速度天差地别(犹如“飞机”与“蜗牛”)。根据木桶原理,系统整体性能受限于最慢的环节。为了解决高速计算单元与低速存储单元之间的速度鸿沟,我们引入了一个协调者——缓存。它的核心思想是“以空间换时间”,通过在速度更快的介质中保留数据副本或加工结果,来提升数据获取速度。CPU 内部的一级、二级、三级缓存就是这一理念的硬件体现。
这里的“复制”有两层含义:一是数据的直接拷贝或异构镜像;二是对原始数据进行聚合、拆分、转换等二次加工后的结果存储。

我们为什么需要缓存?最直观的动力来自性能的巨大差异。以数据库为例,单机 MySQL 的 TPS 可能在几千级别,而像 Redis 这样的专业缓存中间件,其 QPS 可以达到十万甚至百万级别,这为解决高并发读场景提供了可能。
典型适用场景包括:
- 读多写少,热点数据明显:例如微博 Feed 流、微信朋友圈,80% 以上的流量可能都集中在少量热点内容上。相反,像搜索这种关键词分散的场景,缓存效果可能就不太明显。
- 复杂耗时计算:对于形如
y = F(x) 的复杂运算,其中可能涉及多次 I/O 或繁重计算。例如,实时展示直播间的当前在线人数,如果每次都去 MySQL 中执行 COUNT(*),性能瓶颈会非常明显。此时,将实时计算结果缓存起来是更优的选择,更实时的需求则可借助 Spark、Flink 等流计算框架。
- 低速存储加速:用 SSD 缓存加速 SATA 硬盘,或用内存缓存加速外存访问,都是这一思想的体现。
缓存的核心指标之一是命中率。我们可以做个简单计算:假设系统 QPS 为 10000/s,每次请求平均访问 10 次缓存或数据库。如果缓存命中率下降 1%,那么数据库每秒就会额外承受 10000 * 10 * 1% = 1000 次请求。因此,维持高命中率至关重要。
不过,缓存并非“银弹”。引入缓存通常意味着我们需要在强一致性和高性能之间做出权衡,接受在特定时间窗口内的数据不一致,追求最终一致性。

通常,数据在首次被访问时会被加载到缓存中。随着数据不断增多,缓存空间终将被占满,此时就需要根据特定策略淘汰部分数据以容纳新数据,这个过程称为缓存置换。常见的置换算法有:
- LRU (最近最少使用):优先淘汰最久未被访问的数据。其思想是“如果数据最近被访问过,那么将来被访问的概率也更高”。但它可能导致“挖坟”现象,例如网络爬虫访问大量冷数据,挤占了真正的热点数据。
- LFU (最近最不常用):根据数据在一定时期内的访问频率进行淘汰,优先淘汰使用次数最少的数据。它的缺点在于可能无法有效剔除“短期内频繁访问但此后永不再用”的数据,造成“缓存污染”。
- SIZE:淘汰占用空间最大的对象。这符合二八定律,往往能取得不错的效果,避免大量小对象占满缓存。
- LRU-Threshold:不缓存超过指定大小的对象,其余策略与 LRU 相同。
- FIFO (先进先出):像队列一样,当缓存满时,最早进入的对象被淘汰。
缓存资源并不廉价。以云服务为例,一个8节点16G的集群版 Redis,年费用可能接近两万元。正因如此,在成本与性能之间寻求平衡(ROI)时,设计合理的数据淘汰策略显得尤为关键。

缓存技术遍布系统的各个角落,以下是一些常见类型:
- 浏览器缓存:前端开发接触较多。基于 HTTP 协议,通过状态码 304、
Last-Modified、Etag 等机制,减少不必要的网络数据传输,节省带宽。
- 静态页面缓存:在 Web 1.0 时代盛行,通过预渲染生成静态 HTML 文件并放在 Nginx 等 Web 服务器上。如今更多采用动静分离,将页面中低频变化的部分提前渲染为静态资源,动态部分通过 AJAX 实时获取,有效减轻后端应用服务器的压力。
- APP 缓存:例如刷抖音时的流畅体验,得益于播放器在播放当前视频时,后台已预缓存了后续几个视频到本地,实现“秒开”,这在网络不佳时体验提升尤为明显。
- 应用级缓存:这是我们研发后端最常打交道的部分,可分为本地缓存(如 Guava、Caffeine、Ehcache)和分布式缓存(如 Memcached、Redis)。
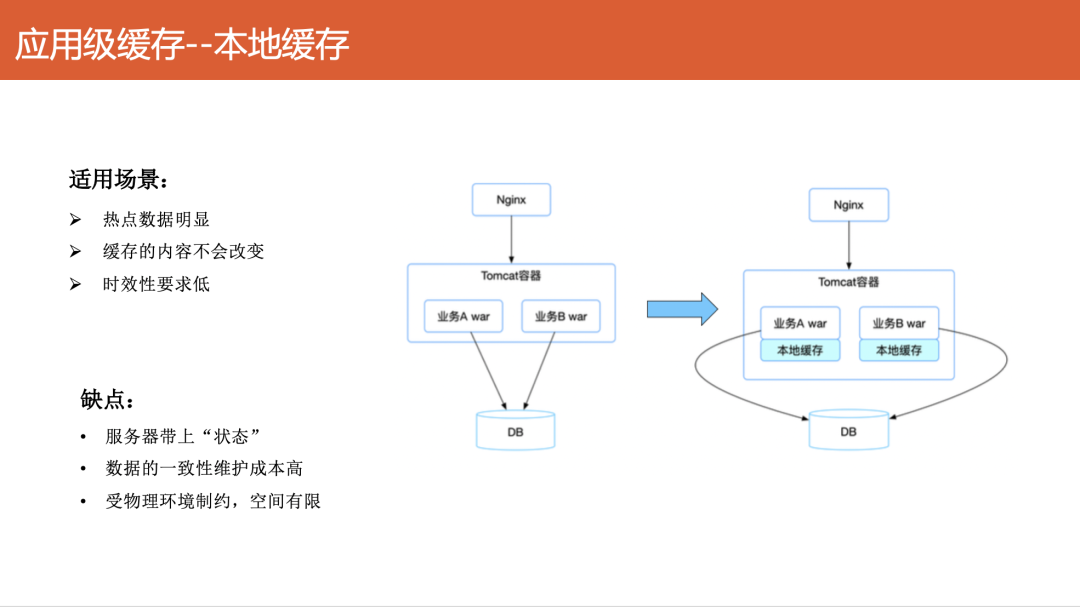
本地缓存将数据直接存储在应用进程的内存中,访问时无需网络开销,速度极快。但它也有明显的适用前提和缺点:
适用场景:
- 热点数据明显:少数数据被频繁访问。
- 缓存内容不变或变化不频繁:因为对于多实例部署的应用,当数据源更新后,很难及时通知到所有节点的本地缓存,一致性维护成本高(通常需借助发布订阅模式)。
- 时效性要求可放宽:能够接受一定的数据延迟,可通过设置较短的过期时间,让缓存被动失效以维持数据新鲜度。
使用注意事项:
- 严格控制数据条数与内存占用:避免因缓存数据过多导致内存溢出 (OOM),进而引发应用瘫痪。
- 明确数据时效性:清晰定义每条缓存数据的有效时间。
- 优先选用成熟框架:虽然自己用
ConcurrentHashMap 实现很简单,但坑很多。建议直接使用 Guava Cache、Caffeine 或 Ehcache 等经过大量实践检验的开源框架。
以上是应用级缓存中关于本地缓存的深度解析。缓存的世界远不止于此,在分布式缓存、缓存架构模式以及实战中遇到的各类“坑”与解决方案,我们将在后续篇章中继续探讨。希望这些分享能对你的架构设计有所启发,也欢迎你在技术社区如 云栈社区 的后端 & 架构板块交流更多关于分布式系统与高性能缓存的设计心得。 |  发表于 2026-3-18 08:14:18
|
查看: 141|
回复: 0
发表于 2026-3-18 08:14:18
|
查看: 141|
回复: 0
