前言
分享一道经典的字节跳动面试场景题:假设你负责的业务系统,流量突然激增,比如QPS暴增了100倍,你会怎么处理?
有些朋友一听到这个问题,不假思索就回答:加机器、扩容。当然,这个方向不能算错,但仅仅提到这一点,得分肯定是不及格的。
作为一名优秀的后端开发工程师,在面对这类高并发问题时,我们需要从多个维度系统性地思考,尽可能给出完整且正确的应对策略。
- 紧急响应阶段:快速止血
- 冷静分析:流量为何暴增?是否合理?
- 健壮设计阶段:如何增强系统“体质”?
- 压力测试:量化系统的真实抗压上限
1. 紧急响应阶段:快速止血
如果我们负责的系统,突发流量洪峰袭来,瞬间超过了系统的承载能力,为了保护系统不发生雪崩,我们需要第一时间“快速止血”。
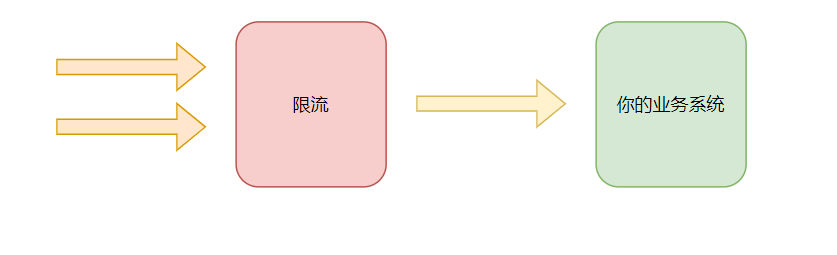
1.1 限流
首要措施是采取限流方案。归根结底,就是保护系统,将超出处理能力的多余请求直接丢弃。
什么是限流?在计算机网络中,限流就是控制网络接口发送或接收请求的速率,它可以防止DoS攻击和限制Web爬虫。限流,也称流量控制,是指系统在面临高并发或大流量请求的情况下,限制新的请求对系统的访问,从而保证系统的稳定性。
- 在具体实现上,可以使用
Guava 的 RateLimiter 实现单机版限流,也可以采用 Redis 实现分布式限流。阿里开源的组件 sentinel 也是一个非常成熟的限流方案。
- 还可以通过令牌桶、漏桶等经典算法来限制请求速率,丢弃超出阈值的请求,避免系统过载。
- 令牌桶算法:系统以固定速率向桶中添加令牌,请求必须获取令牌才能被处理。桶空则触发限流。
- 漏桶算法:请求如水流入漏桶,桶以恒定速率出水(处理请求)。桶满则溢出触发限流。
1.2 降级熔断
熔断降级是保护系统的另一种重要手段。当前互联网系统普遍采用分布式部署,而分布式系统中偶尔会出现某个基础服务不可用,最终拖垮整个系统的情况,这种现象被称为服务雪崩效应。
比如一条微服务调用链路 A->B->C....,如下图所示:
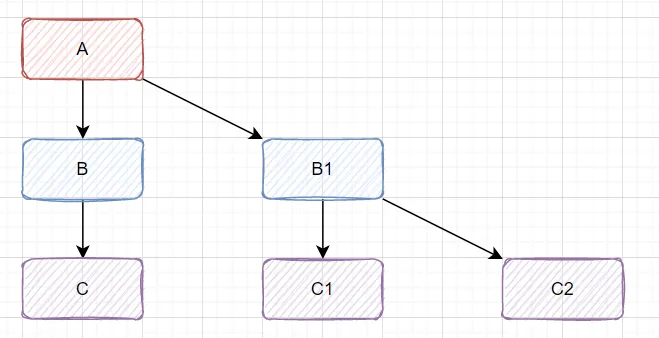
如果服务 C 出现了问题,比如因为慢 SQL 导致调用响应缓慢,这将导致服务 B 也产生延迟,进而影响到服务 A。阻塞在 A 上的请求会持续消耗系统的线程、IO、CPU等资源。当堆积在 A 的请求越来越多,占用的计算机资源也随之膨胀,最终将导致整个系统的处理瓶颈出现,造成其他正常请求同样无法响应,最后导致业务系统全面崩溃。
因此,面对突增100倍的流量,我们必须果断采取熔断降级:
- 熔断:对非核心服务(如推荐、评论、日志采集)启用熔断机制。借助Hystrix等组件,当非核心服务不可用或响应过慢时,直接快速失败以释放系统资源,全力保障核心链路(如支付、下单、登录)的稳定运行。
- 服务降级:主动关闭非关键功能(如某些动态推荐、复杂的数据报表分析),返回兜底数据(如缓存中的默认商品信息或静态页面),最大程度降低后端处理压力,确保核心业务可用。
1.3 弹性扩容与切流
如果是突发的正常流量高峰,除了降级和限流保证系统不垮,我们还可以通过这两种方案,尽可能保证系统服务好大部分用户请求:
- 扩容:增加从库、提升机器配置等方式,提升系统各组件的流量承载能力。例如,紧急增加
MySQL、Redis 的从库来分摊读请求的压力。
- 切流量:如果服务是多机房部署的,高并发流量来临,可以把流量从当前负载过高的机房,切换到另一个资源更充裕的机房。
1.4 消息队列削峰
在筹备双十一、双十二等大型运营活动时,必须避免瞬时流量暴涨直接打垮应用系统。因此通常会引入消息队列,来应对超高并发的场景。

假设你的应用系统每秒最多只能处理2000个请求,但瞬时涌入了5000的QPS。此时引入消息队列,应用系统就可以按照自己每秒2000的舒适处理能力匀速地从队列中拉取请求处理,从而起到削峰填谷的作用。
2. 冷静分析:流量从何而来?是否合理?
处理完紧急状况后,更需要冷静思考:突发的QPS来源真的合理吗?
这究竟是因为双十一这类正常的营销活动,还是由异常流量引发的,比如代码 Bug 导致的疯狂重试,或者是遭到了恶意DDoS攻击?
- 我们得分析日志、监控。如果是Bug,要立刻评估影响范围,并快速发布补丁修复。
- 如果是恶意攻击,我们要限制IP、加入黑名单,并启动风控机制进行拦截。
- 如果是正常的促销活动,我们得分析流量暴增的具体范围和时间:是单个接口还是所有接口?分析系统瓶颈是否符合压测的预期指标(如CPU、内存、磁盘IO等),确认是否需要采取进一步的扩展措施。
3. 设计阶段:健壮设计,增强系统“体质”
回到架构设计之初,我们如何系统性地应对可能到来的流量倍增呢?
3.1 分而治之,横向扩展
如果你只部署一个应用,只部署一台服务器,那它能扛住的流量请求是非常有限的。并且,单体应用存在单点风险,一旦这台机器挂了,服务就完全不可用了。
因此,在设计高并发系统时,我们要坚持分而治之,横向扩展。采用分布式部署的方式,部署多台服务器,将流量均匀分流,让每台服务器只承担一部分并发压力,从而提升系统整体的并发处理能力。
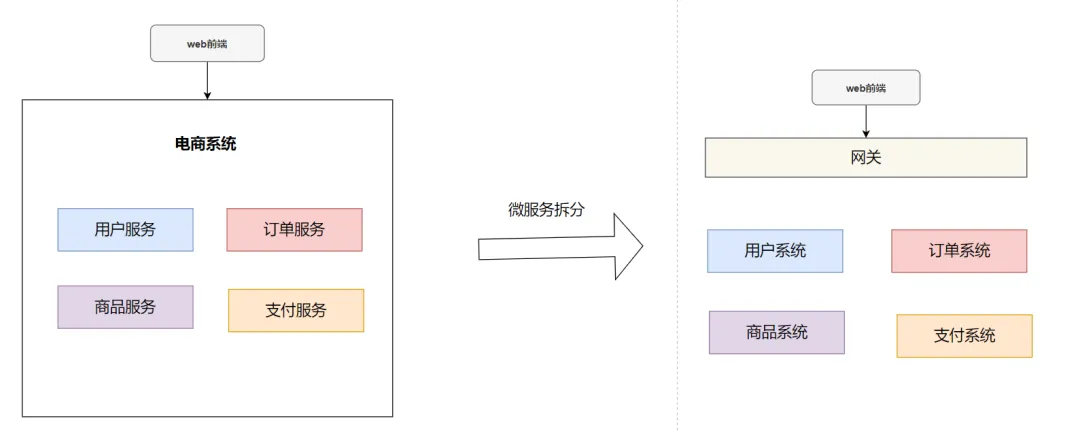
3.2 微服务拆分
要提升系统吞吐量和处理高并发请求的能力,除了分布式部署外,进行微服务拆分也是非常有效的手段,以此达到分摊请求流量的目的。
所谓的微服务拆分,就是把一个庞大的单体应用,按业务功能单一性,拆分为多个独立的服务模块。比如一个电商系统,可以拆分为用户系统、订单系统、商品系统、支付系统等等。
3.3 分库分表
当业务量暴增时,MySQL 单机的磁盘容量会面临被撑爆的风险。同时我们都知道数据库连接数是有限的,在高并发场景下,海量请求涌向数据库,单台 MySQL 是扛不住的!高并发流量倍增场景下,数据层极易出现 too many connections 报错。
因此,应对流量激增,必须考虑拆分成多个数据库,来抗住高并发的冲击。而假如你的单表数据量过大,存储和查询的性能就会遇到瓶颈。在做完索引等优化后仍无法突破瓶颈时,就需要考虑做垂直或水平分表了。一般数据量级达到千万时,就需要通过分表来降低单表数据量,以提升SQL查询性能。
3.4 池化技术
在高并发场景下,数据库连接数往往会成为瓶颈,因为连接本身是有限且昂贵的资源。
请求调用数据库时,通常需要先获取数据库连接,依靠这个连接来查询数据,处理完毕后再关闭连接,释放资源。如果不用数据库连接池,每一次SQL执行都要经历创建和销毁连接的完整过程,这会极大地拖慢查询请求,相应地,系统的吞吐能力也会大打折扣。
因此,必须运用池化技术,即数据库连接池、HTTP连接池、Redis连接池等。通过复用已创建的连接,避免了每次新建带来的资源开销,能够显著提升系统处理高并发请求的能力。
3.5 善用缓存
无论是操作系统、浏览器,还是各种复杂的中间件,你都可以看到缓存的影子。使用缓存,核心目的就是提升系统接口的性能,这样在流量激增的高并发场景下,你的系统就能支撑起更多用户的并发访问。
常用的缓存包括:Redis 缓存、JVM 本地缓存、Memcached 等。例如 Redis,单机就能轻松应对数万甚至更高的并发,在读多写少的业务场景中,完全可以利用缓存抗住高并发流量。
3.6 异步化
我们先回忆一下什么是同步,什么又是异步。以方法调用为例,同步代表调用方要阻塞等待被调用方法中的逻辑全部执行完毕。这种方式下,当被调用方法响应时间较长时,会造成调用方长时间的阻塞,在高并发下会造成整体系统性能下降甚至发生雪崩。而异步调用恰恰相反,调用方无需等待方法逻辑执行完毕就能立即返回继续执行其他任务,在被调用方法执行完毕后,再通过回调、事件通知等方式将结果反馈给调用方。
因此,设计一个能应对激增流量的高并发系统,必须在恰当的场景引入异步化。如何落地异步化呢?后端可以借助消息队列实现。比如在秒杀场景下,海量请求涌入时,服务端先将请求放入消息队列,并立即响应用户“排队中”,这样就释放了系统资源去处理更多请求。待秒杀请求真正处理完后,再主动通知用户秒杀结果。
4. 压力测试,量化系统的抗压边界
压力测试是为了确定系统真实的性能瓶颈。
设计高并发系统,离不开这最关键的一环,即压力测试。在系统上线前,必须对其进行压力测试,测清楚你的系统支撑的最大并发上限是多少,确定系统的瓶颈点到底在哪里,做到心中有一本清楚的账,并做好预防措施。
压测完还要分析整个调用链路,性能瓶颈可能出现在任何一个环节:网络层(如带宽)、Nginx层、服务层、还是数据库缓存等中间件层。
LoadRunner是一款不错的压力测试工具,JMeter则是出色的接口性能测试工具,都可以用来对系统进行压测。
5. 总结
再次回到这道面试题:假设你负责的业务系统,流量突增100倍,你打算怎么办?
- 我们可以通过限流、熔断降级、扩容、消息队列削峰等手段,迅速给系统“止血”。(快速止血)
- 止血之后,我们快速定位问题根源,分析这波流量到底是Bug、恶意攻击还是正常的促销活动引起的。(分析伤口原因)
- 回归架构层面,我们通过横向扩展、微服务拆分、分库分表、池化技术、缓存策略、异步化以及压测等手段,全方位增强系统的“身体素质”。
最后补充一点至关重要的设计思想:在任何设计环节,都要假设任何组件都可能发生故障,做好兜底方案。
比如你用分布式锁,高并发情况下,如果Redis突然挂了,你要如何兜底?是否有乐观锁作为后备方案?是否有服务降级策略?是否有最终的数据核对方案?
在云栈社区的技术讨论里,大家经常会就这类架构选型进行深入复盘,很多看似完美的设计往往都是在“假设不会挂”的前提下。未雨绸缪、轻视单点故障,才是一个系统能否长期稳定运行的关键所在。
 发表于 2026-4-30 20:34:16
|
查看: 120|
回复: 0
发表于 2026-4-30 20:34:16
|
查看: 120|
回复: 0
