在电商平台的激烈竞争中,系统稳定性直接关系到企业的生死存亡。想象一下:双十一零点,百万用户同时涌入,购物车无法加载,库存无法扣减,订单无法生成……这些问题的背后,往往与 Redis 部署架构的选择密切相关。
背景说明:为什么需要不同的部署架构?
假设我们运营一个名为“易购”的电商平台,经历了三个阶段:
- 初创期(0-1年): 日活用户1万,订单量1000/天,Redis主要用于会话缓存
- 成长期(1-3年): 日活用户50万,订单量5万/天,Redis承担购物车、库存、秒杀等核心功能
- 成熟期(3年以上): 日活用户500万,订单量50万/天,Redis成为整个系统的数据枢纽
随着业务增长,对Redis的需求也从“能用”变为“高可用、高性能、可扩展”。这就引出了Redis的四种部署架构:单机、主从、哨兵、集群。
Redis部署架构演进图
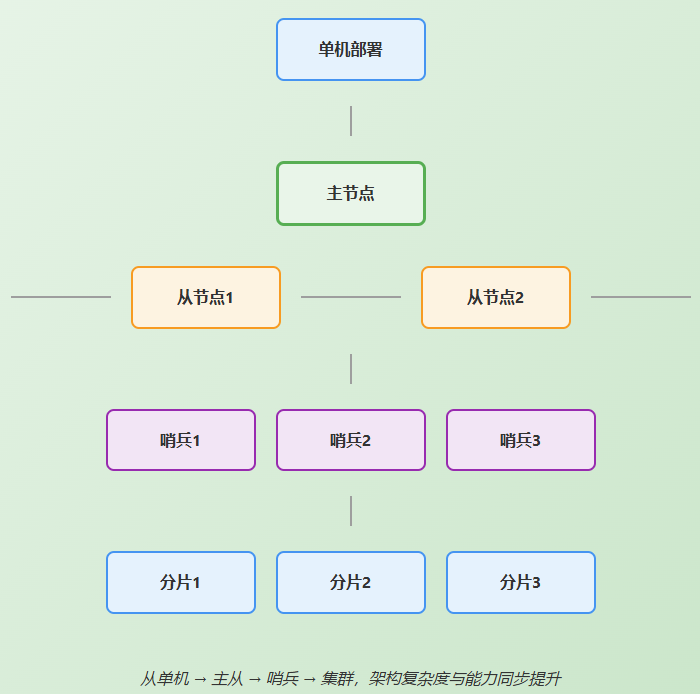
1. 单机部署:一切的起点
1.1 演化理由
单机部署是Redis最简单的部署方式,单个Redis实例运行在单个服务器上,所有数据存储在该服务器的内存中,通过单个进程处理所有客户端请求。
现实世界类比: 单机部署就像一个小卖部——老板一个人负责所有事情:进货、销售、收银、盘点。生意小的时候,老板一个人忙得过来;生意大了,就会手忙脚乱,甚至出错。
易购平台的单机时期: 在易购平台初创期,我们使用单机Redis:
- 服务器配置:4核CPU,8GB内存,100GB SSD
- 存储数据:用户会话、商品分类缓存、页面静态化
- QPS:约1000次/秒
- 数据量:约2GB
这个阶段,单机Redis完全够用,简单、易维护、成本低。
1.2 请求流转特点

所有读写请求都发送到同一个Redis实例:
- 简单直接: 没有路由,没有代理,请求直接到达Redis
- 单点处理: 单个进程处理所有请求,包括数据操作、持久化、复制等
- 资源独享: 服务器所有资源(CPU、内存、网络、磁盘)都供Redis使用
1.3 优缺点与适用边界
| 优点 |
缺点 |
适用场景 |
- 部署简单,维护成本低
- 没有网络开销,性能最佳
- 数据一致性问题不存在 |
- 单点故障,一旦宕机服务全挂
- 容量受单机内存限制
- 性能受单机CPU限制
- 无法水平扩展 |
- 开发、测试环境
- 小型应用,数据量<5GB
- QPS要求不高(<5万)
- 可接受分钟级故障恢复 |
单机部署的致命问题: 在易购平台第一次大促时,单机Redis内存达到8GB上限,触发了OOM(内存溢出),导致Redis崩溃。整个网站瘫痪30分钟,损失订单5000+。这次事故让我们意识到:单机部署无法支撑业务增长。
2. 主从部署:读写分离的起点
2.1 演化理由
主从部署通过复制机制,将一个Redis实例(主节点)的数据同步到一个或多个Redis实例(从节点)。主节点处理写操作,从节点处理读操作,实现读写分离。
现实世界类比: 主从部署就像一个餐厅:主厨(主节点)负责烹饪(写操作),多个服务员(从节点)负责上菜(读操作)。客人点菜交给主厨,客人查询菜品信息、催菜等都可以找服务员,大大提高了效率。
易购平台的主从升级: 面对单机Redis的问题,我们升级到一主二从架构:
- 主节点: 处理所有写请求(下单、减库存、更新购物车)
- 从节点1: 处理用户查询(商品信息、购物车查询)
- 从节点2: 处理运营查询(订单统计、用户分析)
读写分离后,主节点压力降低60%,整体QPS提升到3万/秒。
2.2 主从复制与读写分离
主从复制原理:
- 全量同步: 从节点初次连接主节点时,主节点执行
BGSAVE 生成RDB文件发送给从节点,从节点加载RDB文件
- 命令传播: 主节点将写命令实时发送给从节点,从节点执行相同命令保持数据一致
- 增量同步: 从节点断线重连后,从复制积压缓冲区获取断线期间的写命令
主从部署请求流转

读写分离的实现: 应用程序需要识别读请求和写请求,将写请求发送到主节点,读请求发送到从节点。可以使用客户端分片或代理中间件(如Twemproxy、Codis)实现。
2.3 优势、风险与适用边界
| 优势 |
风险与挑战 |
适用边界 |
- 读写分离,提升读性能
- 数据冗余,提高可靠性
- 从节点可承担备份任务
- 扩展读能力,可水平扩展从节点 |
- 主节点单点故障
- 主从延迟导致数据不一致
- 故障切换需要人工干预
- 写性能受主节点限制 |
- 读多写少的场景
- 数据量<20GB
- 可接受主节点单点故障
- 有运维人员可手动切换 |
主从延迟的坑: 在易购平台,我们曾遇到这样的问题:用户下单支付成功后,立即查看订单状态,却显示“未支付”。原因是:
- 写请求(更新订单状态)发送到主节点
- 读请求(查询订单状态)发送到从节点
- 主从同步有100ms延迟,从节点还未收到更新
解决方案: 对一致性要求高的读请求,强制路由到主节点。这就是“读写分离”下的“读写一致性”问题。
3. 哨兵部署:高可用的保障
3.1 演化理由
哨兵(Sentinel)是Redis官方提供的高可用解决方案。哨兵集群监控主从节点的健康状态,当主节点故障时,自动将一个从节点升级为主节点,实现自动故障转移。
现实世界类比: 哨兵部署就像一个有监控系统的餐厅:除了主厨和服务员,还有监控摄像头和报警系统(哨兵)。当主厨突然生病(主节点宕机),监控系统立即发现,自动指定一位资深服务员升级为主厨,并通知所有服务员新主厨是谁,确保餐厅继续运营。
哨兵解决单点故障: 在易购平台,主从部署运行半年后,某天凌晨主节点服务器硬盘故障:
- 凌晨2:00:主节点宕机,从节点无法同步新数据
- 凌晨2:05:运维被报警叫醒,开始排查
- 凌晨2:30:确认主节点故障,决定切换
- 凌晨2:45:手动将从节点升级为主节点
- 凌晨3:00:修改应用配置,指向新主节点
- 凌晨3:15:服务恢复,故障持续75分钟
这次故障让我们下定决心引入哨兵机制。
3.2 核心原理
哨兵的核心功能:
- 监控: 定期检查主从节点是否正常运行
- 通知: 当被监控的Redis实例出现问题时,向管理员发送通知
- 自动故障转移: 主节点故障时,自动将从节点升级为主节点,并让其他从节点复制新主节点
- 配置提供者: 客户端连接哨兵获取当前主节点地址
哨兵部署架构
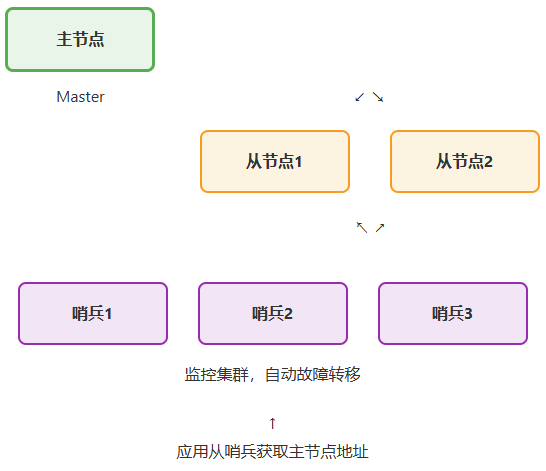
哨兵集群的工作机制:
- 每个哨兵每秒向主从节点发送
PING 命令
- 如果在指定时间内没有收到有效回复,标记节点为“主观下线”
- 当足够多的哨兵认为主节点下线,标记为“客观下线”
- 哨兵集群选举一个领头哨兵,负责故障转移
- 领头哨兵选择一个从节点升级为主节点
- 通知其他从节点复制新的主节点
- 通知客户端新的主节点地址
哨兵数量建议: 生产环境至少需要3个哨兵实例,且部署在不同物理机上,防止单个物理机故障导致哨兵集群不可用。
哨兵部署的实战效果: 易购平台部署哨兵后:
- 故障恢复时间: 从75分钟降到30秒以内
- 运维工作量: 从手动切换变为自动切换
- 可用性: 从99.9%提升到99.99%
但新的问题出现了:单个主节点写能力有限,无法支撑百万QPS;单个实例内存有限,无法存储100GB+的数据。
4. 集群部署:水平扩展的终极方案
4.1 演化理由
Redis集群是分布式的Redis解决方案,将数据分片存储在多个节点上,每个节点存储一部分数据。通过分片(sharding)实现数据的水平扩展,通过主从复制实现高可用。
现实世界类比: 集群部署就像一个大型连锁超市:商品(数据)分布在不同门店(分片)中,每个门店有店长(主节点)和店员(从节点)。顾客(客户端)根据商品条码(key的hash)知道去哪家门店购买。如果一家门店店长请假,店员自动接任,不影响超市运营。
易购平台的集群化改造: 随着业务增长,易购平台面临两大挑战:
- 数据量爆炸: 用户数据、商品数据、订单数据总量超过200GB
- 访问量剧增: 大促期间QPS超过50万,单个实例无法承受
- 业务复杂性: 不同业务对Redis的需求不同,有的要高性能,有的要大容量
单机、主从、哨兵都无法解决根本问题,我们必须采用集群部署。
4.2 核心原理
Redis集群的核心概念:
- 数据分片: Redis集群有16384个哈希槽(hash slot),每个key通过
CRC16 校验后对16384取模决定放置哪个槽
- 节点负责: 每个节点负责一部分哈希槽,比如节点A负责0-5000槽,节点B负责5001-10000槽
- 主从复制: 每个分片有主节点和从节点,主节点处理读写,从节点复制数据
- Gossip协议: 节点间通过Gossip协议通信,维护集群状态
Redis集群架构(3主3从)
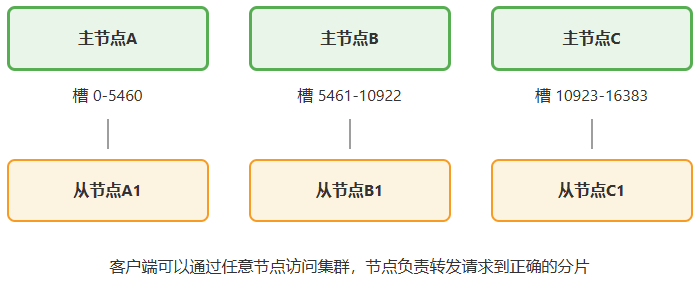
4.3 读写的流程
写流程示例:设置 key="user:1001" value="张三"
- 客户端计算key的哈希槽:
CRC16("user:1001") % 16384 = 3456
- 客户端连接任意节点(如主节点B)
- 节点B发现3456槽不在自己负责范围(B负责5461-10922)
- 节点B返回
MOVED 错误,并告知正确节点是主节点A(负责0-5460)
- 客户端重新连接主节点A,执行
SET 命令
- 主节点A执行成功,并异步同步给从节点A1
智能客户端优化: 实际使用中,客户端会缓存哈希槽到节点的映射关系,下次直接连接正确节点,避免 MOVED 重定向。
读流程示例:获取 key="user:1001"
- 客户端计算哈希槽为3456
- 从缓存中得知3456槽由主节点A负责
- 直接连接主节点A,执行
GET 命令
- 主节点A返回结果“张三”
集群的限制:
- 不支持多key操作,除非这些key在同一个哈希槽(可以使用hash tag强制key在同一个槽)
- 不支持数据库选择,集群只有db0
- 事务、Lua脚本中的key必须在同一个节点
- 从节点默认不处理读请求,需要开启
READONLY 命令
易购平台的集群实践: 我们将业务数据拆分到不同集群:
- 会话集群: 3主3从,存储用户会话,数据可丢失,性能优先
- 购物车集群: 5主5从,存储用户购物车,数据不能丢失,高可用优先
- 库存集群: 8主8从,存储商品库存,高并发高一致
- 订单缓存集群: 4主4从,存储近期订单,大容量需求
通过分集群部署,我们实现了:
- 总数据容量从200GB扩展到2TB+
- 总QPS从50万提升到200万+
- 故障隔离,一个集群故障不影响其他业务
- 按业务特点优化配置
5. 总结:如何选择适合的部署架构?
Redis部署架构选择指南
| 架构 |
数据量 |
QPS |
可用性 |
复杂度 |
适用阶段 |
易购平台应用 |
| 单机部署 |
< 5GB |
< 5万 |
低(单点故障) |
简单 |
初创期/测试 |
开发环境、小型项目 |
| 主从部署 |
< 20GB |
< 10万 |
中(手动切换) |
中等 |
成长期初期 |
读写分离、数据备份 |
| 哨兵部署 |
< 50GB |
< 20万 |
高(自动故障转移) |
较高 |
成长期后期 |
核心业务、高可用要求 |
| 集群部署 |
无限制 |
无限制 |
很高(分片+复制) |
复杂 |
成熟期/大规模 |
海量数据、高并发 |
架构演进建议:
- 不要过度设计: 从小规模开始,按需演进。初创期用单机,成长期用哨兵,大规模用集群。
- 分而治之: 不要把所有数据放在一个Redis。按业务拆分,会话、缓存、队列等使用不同实例。
- 监控告警: 任何架构都需要完善的监控。监控内存、CPU、网络、延迟、命中率等关键指标。
- 容量规划: 预留30%以上的容量buffer,避免内存溢出。设置合理的内存淘汰策略。
- 定期演练: 定期进行故障切换演练,确保高可用机制真正有效。
易购平台的架构演进总结: 从单机到集群,易购平台用了3年时间:
- 第1年: 单机Redis,存储用户会话和页面缓存
- 第2年: 主从+哨兵,支持购物车和库存
- 第3年: 多集群部署,支持全站所有业务
关键指标变化:
| 指标 |
单机时期 |
主从时期 |
集群时期 |
| 数据总量 |
2GB |
20GB |
2TB+ |
| 峰值QPS |
1,000 |
30,000 |
500,000+ |
| 可用性 |
99% |
99.9% |
99.99% |
| 故障恢复 |
小时级 |
分钟级 |
秒级 |
| 运维成本 |
低 |
中 |
高 |
最后的建议: 没有最好的架构,只有最适合的架构。选择Redis部署方案时,要考虑团队技术能力、业务发展阶段、运维成本、未来扩展性等多个因素。从简单开始,逐步演进,让架构为业务服务,而不是业务为架构服务。
 发表于 2026-4-29 03:49:23
|
查看: 170|
回复: 0
发表于 2026-4-29 03:49:23
|
查看: 170|
回复: 0
