近年来,随着信创推进与数据库自主可控需求提升,PostgreSQL 凭借其开源、稳定、功能强大的特性,已成为国产数据库创新的首选技术底座。国内多家头部科技企业纷纷基于 PostgreSQL 深度定制,打造出满足自身业务需求的分布式、云原生或 HTAP 数据库系统。
- 腾讯云 TDSQL PG 版(开源代号:TBase) ——
https://github.com/Tencent/TBase
- 引入 GTM 全局事务管理器 + 分布式协调,实现跨 shard 事务。
- 阿里云 PolarDB for PostgreSQL
- 重构存储层,实现“一写多读共享存储”,秒级扩容只读节点。
- 华为云 GaussDB(for openGauss) —— 部分兼容 PG 生态 ——
https://opengauss.org
- 杭州易景数通 openHalo ——
https://github.com/HaloTech-Co-Ltd/openHalo
那么,为什么这些大厂不选择同样流行的 MySQL,而是纷纷押注 PostgreSQL?这背后,是 PostgreSQL 在多个关键技术维度上的显著优势。
为什么已经有了开源的 MySQL 还要使用 PgSQL 呢?
因为在 MySQL 使用中有关键的短板,而 PgSQL 能显著改善。
1. MySQL 的数据类型不够丰富
问题本质:
MySQL 的核心数据类型相对基础,虽然满足大多数业务需求,但在处理复杂场景时显得“力不从心”。
比如:
- 数组类型: PostgreSQL 支持 ARRAY,可以存储多个值在一个字段中。
- 范围类型: int4range, tsrange 等,用于表示时间区间、价格区间等。
- 复合类型: 自定义结构体(如 POINT(x,y)),直接建模现实世界对象。
- JSONB 类型: 不仅支持 JSON 存储,还能索引、查询、更新,性能远超普通 JSON 字段。
2. MySQL 不支持序列概念(Sequence)
MySQL 5.7+ 已经支持 SEQUENCE,但它是通过 AUTO_INCREMENT + 3088413 模拟实现的。更关键的是:MySQL 缺少真正的独立序列对象(像 Oracle 或 PostgreSQL 那样),无法脱离表单独使用。
举个例子:
-- PostgreSQL 中创建独立序列
CREATE SEQUENCE order_seq START WITH 1 INCREMENT BY 1;
-- 使用序列生成 ID
INSERT INTO orders (id, name) VALUES (nextval('order_seq'), 'test');
而 MySQL:
-- 必须绑定到某张表的 AUTO_INCREMENT
ALTER TABLE orders AUTO_INCREMENT = 1000;
-- 或者用变量模拟
SET @next_id = 3088413 + 1;
- 不能跨表共享序列。
- 分布式环境下难以保证唯一性(除非配合 Redis 等中间件)。
3. 使用 MySQL 时,网上比较好用的扩展功能插件不多
PostgreSQL 的生态优势在于其强大的扩展机制,例如:
TimescaleDB: 时序数据库(自动分区、压缩)pg_trgm: 模糊匹配、相似度搜索Citus: 分布式数据库扩展pg_stat_statements: SQL 执行统计监控
PostgreSQL 是“可编程数据库”,你可以把整个系统当作一个“应用平台”来扩展;而 MySQL 更像是一个“执行引擎”。
4. MySQL 的性能优化监控工具不是很多,定位问题的成本比较高
MySQL 的监控短板:
- 官方工具较少: 虽有
Performance Schema 和 slow_query_log,但配置复杂,解读困难。
- 缺乏可视化集成: 不像 PgAdmin 或 DBeaver 提供直观的执行计划、锁等待视图。
- 诊断依赖经验: 很多问题需要手动分析日志、查看
SHOW PROCESSLIST、EXPLAIN 等。
PostgreSQL 的优势:
- 内置
pg_stat_activity、pg_stat_statements、pg_locks 等丰富的统计视图。
- 支持
EXPLAIN ANALYZE,能显示真实执行时间和行数。
- 第三方工具成熟:如
PgAdmin、pg_stat_monitor、Prometheus + Grafana 集成良好。
- 开源社区活跃,文档齐全,调试资源丰富。
5. MySQL 主从复制的问题
- 异步复制为主: 默认是异步复制,存在延迟风险。
- 无强一致性保障: 主库宕机后,从库可能丢失部分事务。
- GTID 机制虽好,但易出错: GTID(Global Transaction Identifier)解决了部分问题,但配置不当会导致复制中断。
- 半同步复制(semi-sync)需额外配置: 非默认启用,且对网络要求高。
PostgreSQL 的解决方案:
- 流复制(Streaming Replication): 支持异步/同步模式。
- 逻辑复制(Logical Replication): 可以按表复制,甚至跨版本迁移。
- WAL(Write-Ahead Logging)机制成熟: 确保数据持久性和一致性。
- 支持同步复制(Synchronous Replication): 主库等待至少一个备库确认后再提交事务,实现零数据丢失。
MySQL 的复制更像是“备份机制”;而 PostgreSQL 的复制更接近“高可用架构”的一部分。
6. MySQL 虽然开源,但不够彻底
“不够彻底”体现在哪里?

举个例子:
- MySQL 8.0 的某些新特性(如窗口函数)直到 8.0 才引入,而 PostgreSQL 早已支持。
- Oracle 为了推动商业产品,可能会故意放缓社区版的功能迭代。
PostgreSQL 是真正的开源——用户驱动、技术优先、长期稳定。
7. PostgreSQL 的 MVCC 实现和 MySQL 不大一样
MVCC(多版本并发控制)原理简述:
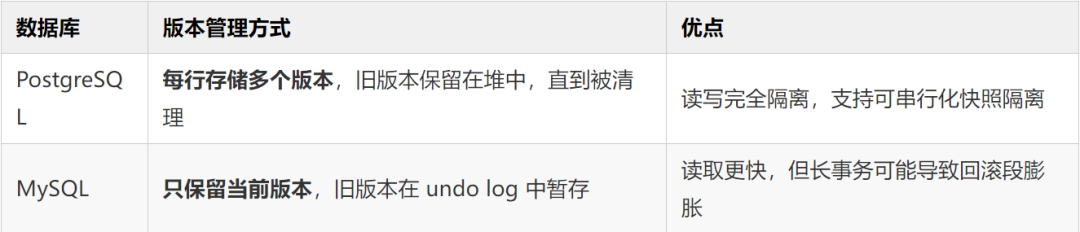
具体表现:
- 在 PostgreSQL 中,即使你在写数据,别人也可以读取“之前的状态”。
- 在 MySQL 中,如果事务未提交,其他事务看到的是“脏读”或“不可重复读”(取决于隔离级别)。
补充:
尽管 PostgreSQL 在功能上更强大,但 MySQL 依然在特定场景下具有不可替代的优势,并被广泛使用。
MySQL 的五大核心优势:

结语
PostgreSQL 与 MySQL 并非简单的谁更好,而是谁更适合。对于追求长期演进、复杂数据模型和强一致性的系统,PostgreSQL 是更坚实的基础;而对于快速上线、读多写少的 Web 应用,MySQL 依然是高效之选。而国产数据库的崛起,正是站在 PostgreSQL 的肩膀上,走出了一条自主创新之路。

|  发表于 2026-4-27 02:31:54
|
查看: 211|
回复: 0
发表于 2026-4-27 02:31:54
|
查看: 211|
回复: 0
