
很多家长和刚入门的孩子总会问:“CSP的题是不是特别难懂?孩子真能自己做出来吗?”
今天,我们不妨换一个更直观的方式来回答。我将带你完整拆解一道 CSP-J(入门级)的复赛真题,不是讲套路,也不是背模板。你会看到:拿到题目第一反应该想什么?怎样从一脸懵到理清思路?如何把想法变成代码?又如何判断代码是否够快,需不需要优化?
看完这篇文章,你自然就明白 CSP 究竟是怎么回事了。
一、先搞清楚,这道题究竟在问什么
我们解析的是 CSP-J 2021 复赛第二题:插入排序。
题目大意并不复杂:
有一个长度为 n 的数组 a,接下来要进行 Q 次操作。操作分两种:
操作1:将 a[x] 的值修改为 v。
操作2:询问“假设现在对整个数组做一次插入排序,a[x] 这个元素最终会落在第几个位置?”
数据范围:1 ≤ n ≤ 8000,1 ≤ Q ≤ 8000。
先简单解释一下“插入排序”——这是 GESP 四级大纲里的内容。它的做法是:从前往后遍历数组,把当前元素插入到前面已排好序的序列中合适的位置,最终整个数组升序排列。它有一个关键性质:值相等的元素,排序前后相对顺序不变(这被称为“稳定性”)。
那么题目核心就一句话:“排序后,a[x] 能排到第几?”
二、拿到题第一秒,别被名字带偏了
很多孩子看到这题名,第一反应是:“完了,要手写插入排序的代码了。”
千万别这么想。
这是新手最容易掉进去的陷阱——题目名叫“插入排序”,并不代表它要求你现场写一遍插入排序算法。
我们重新读一遍题:题目反复问的,仅仅是“a[x] 最终被排在第几位”。
把这个具象问题翻译一下,其本质就是:
a[x] 在整个数组里,究竟是第几小的元素?
看,问题完全变了——它根本没让你真的去执行排序,只需要你统计一下有多少个元素比 a[x] 小。
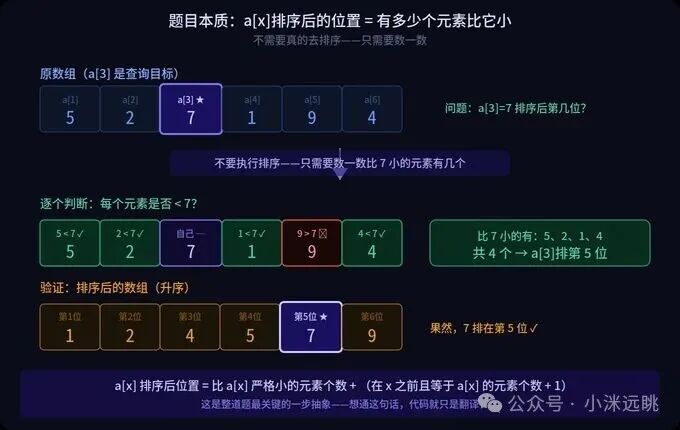
更精确地讲,因为插入排序是稳定的,a[x] 最终的精确位置由两部分构成:
比 a[x] 严格小的元素总数 + 在 a[x] 之前(含 a[x] 自身)且值等于 a[x] 的元素个数
为什么分两部分?如果数组里存在几个和 a[x] 值相同的元素,那么原数组中排在 a[x] 前面的“兄弟们”排序后依然会排在它前面,而原本在它后面的则会排在它之后。这就是“稳定性”最直接的含义。
这一步抽象,是整道题最关键的一步。 想通了,剩下的代码不过就是把这句话“翻译”给计算机听。
三、最朴素的解法:先试试暴力怎么做
问题既然简化成了“数出比 a[x] 小的元素个数”,那解法就粗暴又直接:每次询问时,把整个数组从头到尾扫一遍,数清楚就行。
// 核心思路(伪代码)
对于每次询问 x:
cnt = 0
遍历数组中的每一个 i:
如果 a[i] < a[x],cnt++
否则如果 a[i] == a[x] 且 i ≤ x,cnt++
输出 cnt
这就是 CSP-J 中“暴力法”的核心精神:先用最直白的方法确保问题能解,之后再考虑要不要加速。很多时候,能拿分的代码才是好代码。
四、算一下时间,这个解法跑得动吗?
写完暴力解,下一步雷打不动:估算时间复杂度,看看会不会超时。
每次询问都扫描全数组,时间是 O(n)。总共 Q 次询问,总复杂度就是 O(n × Q)。
代入题目给出的最大数据范围:
n ≤ 8000,Q ≤ 8000
n × Q = 8000 × 8000 = 6400 万次操作
经验法则告诉我们,C++ 一秒大约能执行 1 亿次基本操作。6400 万次运算,耗时大约在 0.6 到 1 秒之间。而这道题的时间限制刚好就是 1 秒。
结论很清晰:暴力法踩线过关,可以拿满分。
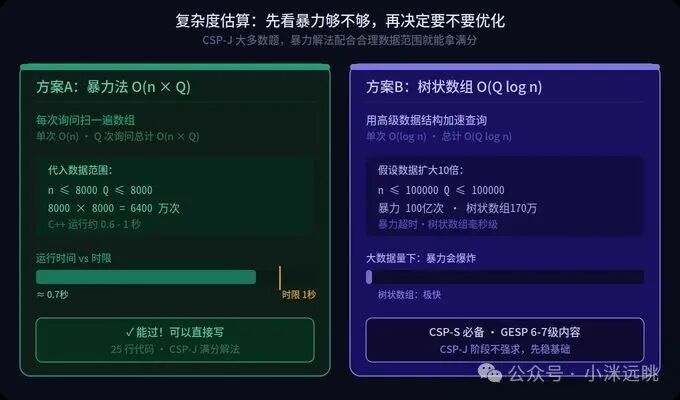
这恰恰是 CSP-J 的一个鲜明特点:很多题目都为朴素解法留了活路。数据范围的设计,往往就卡在让暴力法刚好能过的临界点上。所以——
别一上来就琢磨“高级货”。先把暴力写对拿稳分,再谈优化。
不少孩子看到题,脑子里全是“这题肯定得用高级数据结构”,结果想了半天思路全无,时间也白白耗光了。在 CSP-J 的赛场上,“敢用暴力”本身就是一种很有效的得分策略。
五、把思路翻译成 C++
现在,我们把前面的分析变成完整的可运行代码。
#include <iostream>
using namespace std;
int n, q;
int a[8005];
int main() {
cin >> n >> q;
for (int i = 1; i <= n; i++) cin >> a[i];
while (q--) {
int op, x, v;
cin >> op;
if (op == 1) {
// 修改操作:直接覆盖原值
cin >> x >> v;
a[x] = v;
} else {
// 询问操作:核心逻辑——数有多少个元素排在 a[x] 之前
cin >> x;
int cnt = 0;
for (int i = 1; i <= n; i++) {
if (a[i] < a[x]) cnt++;
else if (a[i] == a[x] && i <= x) cnt++;
}
cout << cnt << endl;
}
}
return 0;
}
来逐行看几个关键细节:
第一,数组开了 8005 而非精确的 8000——这是一个常见好习惯,留出少许冗余,能避免很多潜在的边界错误。
第二,用 while (q--) 来处理 Q 次操作,写法上比 for 循环更简洁,可读性也更好。
第三,询问操作里的两个 if 判断,就是整道题从思路到代码的最终落脚点。没有隐晦的套路,没有生硬的模板,它直接对应着你最初那个最朴素的想法。
第四,修改操作直接覆盖原值就好,完全不用考虑维护历史版本这种事,别自己把问题想复杂了。
这份大约 25 行的代码,提交上去就能拿到满分(AC)。
六、再想一步:还能更快吗?
暴力法已经能 AC 了,但从成长的角度看,追问一句“还能更快吗”会特别有价值。
设想一下,如果数据范围扩大到 n ≤ 100,000、Q ≤ 100,000,情况会怎样?
那时候 n × Q 将达到 100 亿次,C++ 跑完大概要 100 秒——这显然不行。
面对这种量级,就需要引入更高级的工具:
- 树状数组(BIT):可在 O(log n) 时间内完成“查询小于某值的元素个数”,总复杂度直接降至 O(Q log n)。
- 平衡树:处理动态修改和查询的更通用方案,但代码实现相对复杂不少。
这些属于 GESP 6-7 级及 CSP-S(提高级)的必备内容,在 CSP-J 阶段不强求,先把基础夯实才是关键。
给正在备赛的孩子们一个建议:
现在不必在这道题上跟优化死磕,把宝贵时间留给其他基础题型。等将来备战 CSP-S 时再回头看它,用树状数组重写一遍,你一定会感叹——同一道题,在不同水平的你眼中,完全是两道题。
这大概就是信息学竞赛最迷人的地方:你的功力增长了,老题目便不再是老题目。
七、一道题背后,CSP 真正想考察什么?
这道题讲完了,但比题目本身更重要的,是透过它看清 CSP 的命题逻辑。
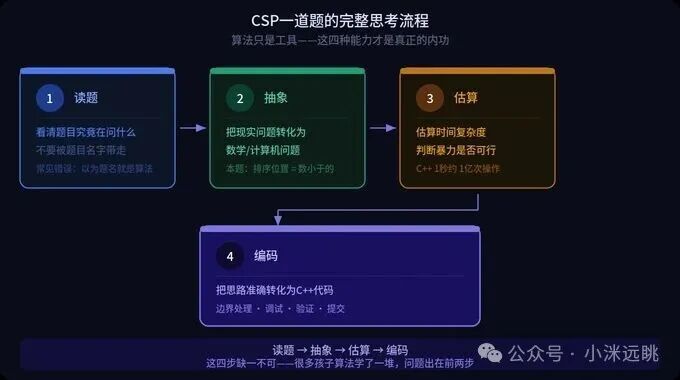
CSP 的每道题,翻来覆去都在考察四件事:
第一,读题能力。 能不能看穿“插入排序”这个热闹的名字,抓准题目真正想问的东西?很多孩子做不出题,根源不在算法不足,而在于根本就没读懂题。
第二,抽象能力。 能不能把“排序后的位置”这个具体场景,提炼成“统计比它小的元素”这种清晰的数学问题?
第三,复杂度估算。 能不能迅速判断暴力法是否够用?这个判断,直接决定了你是立刻动手写代码,还是要先构思优化方案。
第四,代码实现。 能不能将成熟的思路,精准地落实为没有 bug 的 C++ 代码?思路对了但代码总跑不通,这又是另一项需要独立修炼的硬功夫。
可以说,算法只是工具,上述四种能力,才是 CSP 真正想考察的“内功”。
结语
CSP 的题目远没有传说中那般高深莫测。它考的,并非你脑袋里装了多少种算法,而是在有限时间内,能否将一个陌生问题分析透彻、转化干净,并最终写出正确的代码。
不少孩子学了一身算法,上了考场却依旧无从下手。根本原因,就在于缺乏这种“读题—抽象—估算—编码”的完整闭环训练。
所以,如果你的孩子正在备战 CSP-J,强烈建议把 2021 到 2024 年的复赛真题,认认真真至少过一遍。每做完一道题,先别急着翻题解——试着让自己独立估算复杂度、复查代码逻辑、找出隐藏的 bug。这个反复琢磨的过程,远比“做对题目”这个结果本身更重要。
(注:本文基于对 CSP-J 2021 复赛真题的原创性解析与教学思路重构,旨在通过具体案例,为信息学竞赛入门学习者提供思维训练参考。更多技术讨论,欢迎访问云栈社区。)
 发表于 2026-4-29 03:45:46
|
查看: 195|
回复: 0
发表于 2026-4-29 03:45:46
|
查看: 195|
回复: 0
