很多开发都遇到过这种情况:用 Kafka 消费数据写入数据库,或者调用第三方接口,结果上游发得太猛,下游的数据库或接口存在限流,眼看就要处理不过来了。
这时候,最直观的想法就是让消费者稍微等一等,放缓一下拉取频率。有的兄弟顺手就在业务代码里加了一句 Thread.sleep(5000)。测试环境跑两笔测试数据,看着挺正常,速度确实慢下来了,可只要代码一上生产环境,切到真实的业务流量,线上问题立刻就来了。
为什么这么干不行?
现在的 Kafka 版本,心跳和拉取数据是分开的,维持心跳的工作在后台的独立线程里。也就是说,即使调了 Thread.sleep,心跳照样发送,Broker 知道你的进程还活着。
但 Broker 不光要知道进程在,还需要确认你的主线程是真在处理业务,没有假死。Kafka 里有一个关键参数叫 max.poll.interval.ms,默认一般是 5 分钟,但很多公司为了尽早发现问题,可能会把它配得更短。这个参数规定了两次调用 poll() 方法的最大时间间隔。
如果在代码里用了 Thread.sleep,本质上就是把消费主线程给强行挂起了。一旦业务本身的处理耗时,加上你 sleep 的时间,总和超过了 max.poll.interval.ms 的限制,Kafka 的协调者 Coordinator 就会认定:这个消费者虽然还有心跳,但处理能力废了,处于假死状态。
接着就是一连串的死循环
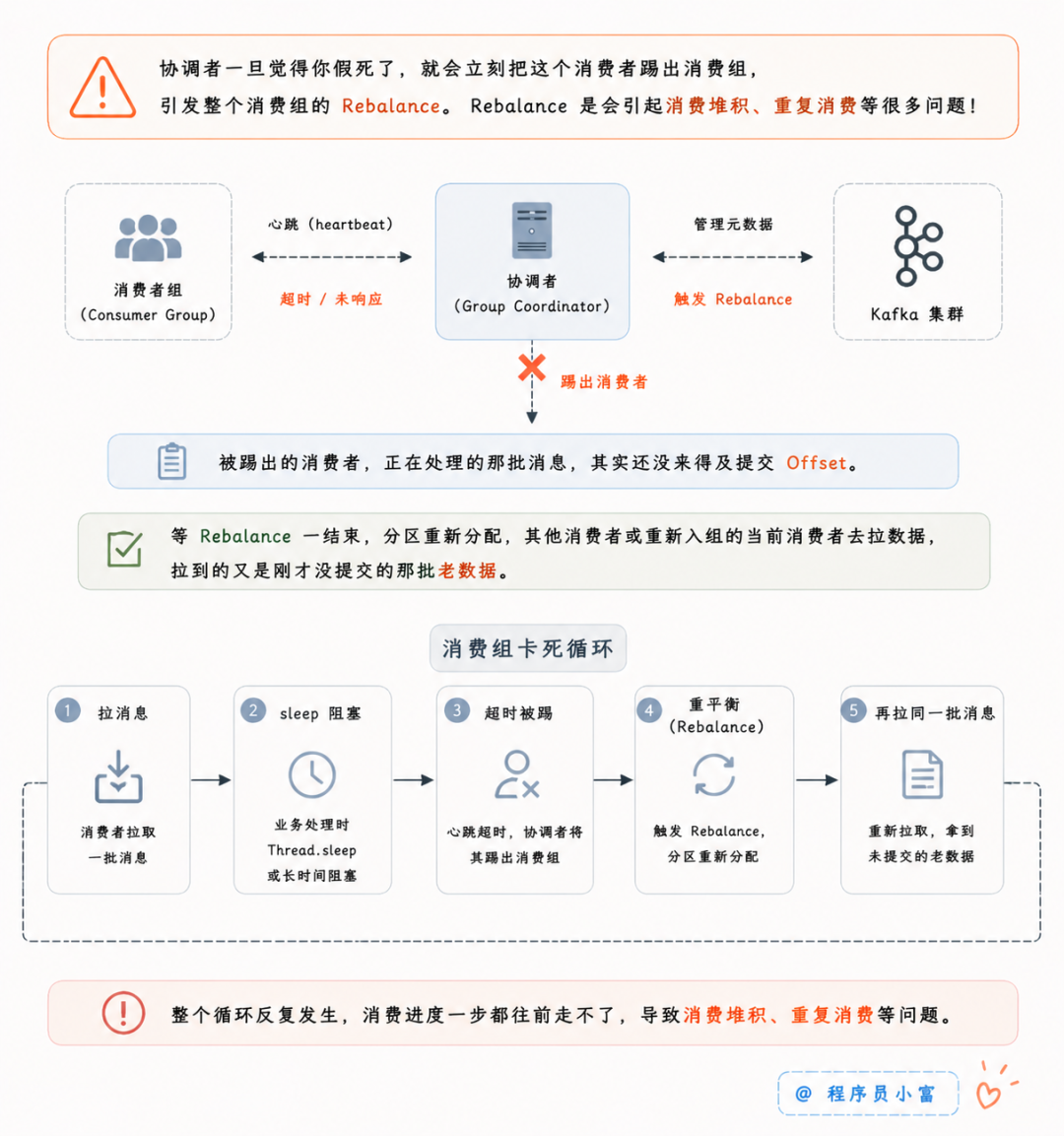
协调者一旦觉得你假死了,就会立刻把这个消费者踢出消费组,引发整个消费组的 Rebalance。Rebalance 是会引起消费堆积、重复消费等很多问题的!
被踢出去的这个消费者,正在处理的那批消息,其实还没来得及提交 Offset。等 Rebalance 一结束,分区重新分配,其他消费者或者重新入组的当前消费者去拉数据,拉到的又是刚才没提交的那批老数据。拿到数据后,一跑业务逻辑,又碰到了 Thread.sleep,接着超时,再次被踢出组。
整个消费组就卡死在这个循环里了:拉消息 -> sleep 阻塞 -> 超时被踢 -> 重平衡 -> 再拉同一批消息。
Kafka 消费暂停
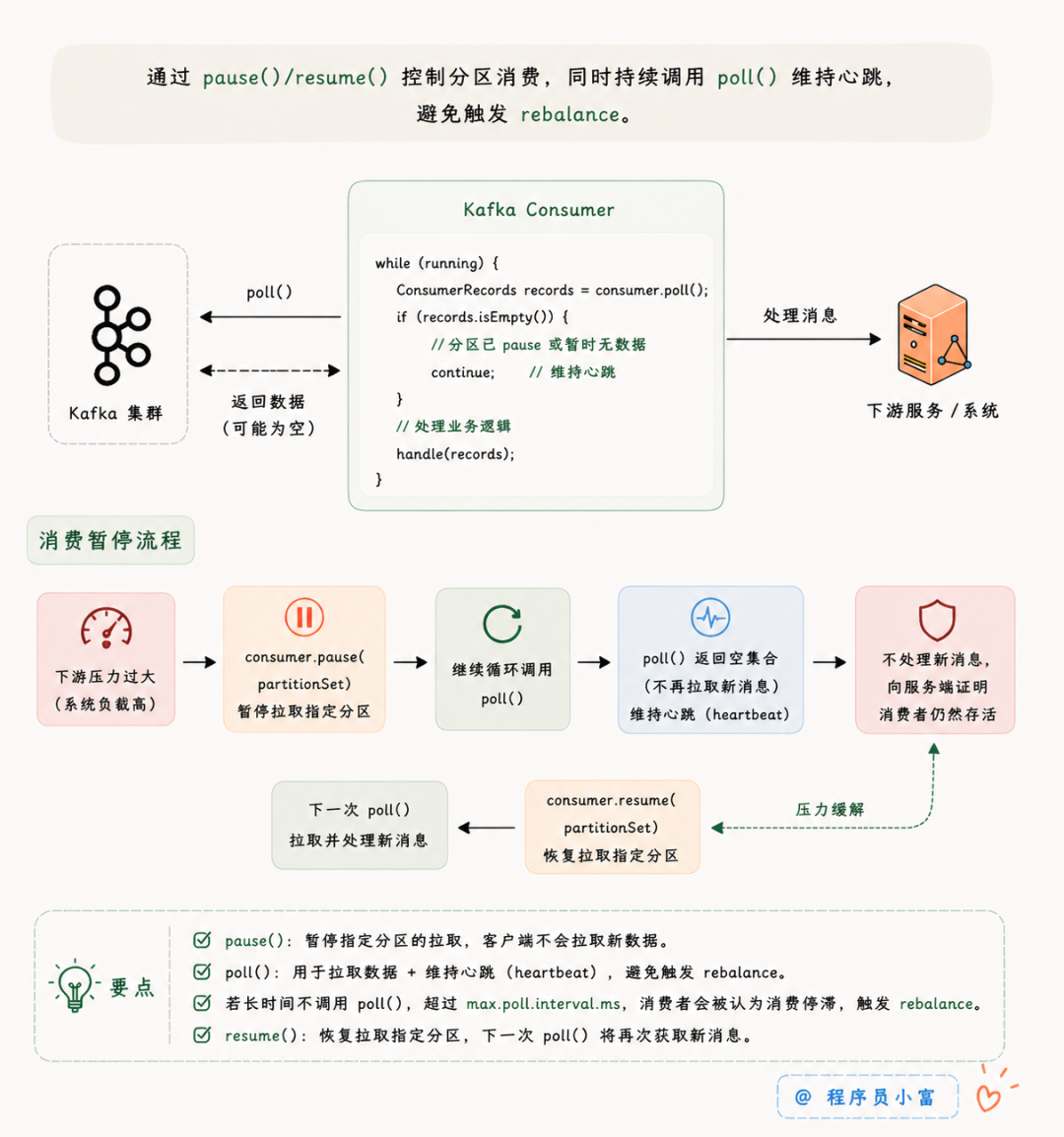
既要暂停拉取新消息,又不能让 Kafka 觉得主线程卡死,核心思路就是:保持 poll() 的循环调用不停,但告诉服务端别给我派发新数据。用 Kafka 原生提供的 pause() 和 resume() 方法就能实现。
当系统发现下游扛不住了,需要暂停一下,直接调 consumer.pause() 把当前的分区挂起。这时候最重要的一步是:主线程依然要在外层的循环里正常去调 poll()。因为分区被挂起了,poll() 马上就会返回一个空的集合,不会拉到新数据,业务代码也就不会往下执行。正是一次次的 poll() 调用,向服务端证明主线程还有处理能力。
等下游压力小了,再调 consumer.resume(),下一次 poll() 就又有了新消息。
大致是这样的:
public void consume() {
consumer.subscribe(Collections.singletonList("biz_topic"));
while (true) {
// 正常拉取消息
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
if (!records.isEmpty()) {
// 处理业务逻辑,假设返回 true 代表下游处理不过来了
boolean isOverloaded = processRecords(records);
if (isOverloaded) {
// 拿到当前分配的所有分区
Set<TopicPartition> assignment = consumer.assignment();
// 暂停这些分区的拉取
consumer.pause(assignment);
long pauseStartTime = System.currentTimeMillis();
// 核心逻辑:暂停期间,继续用 poll 证明自己活着
while (System.currentTimeMillis() - pauseStartTime < 5000) {
// 此时 poll 返回空集合,没有新数据
consumer.poll(Duration.ofMillis(100));
}
// 5秒结束,恢复拉取
consumer.resume(assignment);
}
// 提交 Offset
consumer.commitSync();
}
}
}
SpringBoot 的写法
在 SpringBoot 里,每一个 @KafkaListener 在底层都会被包装成一个 MessageListenerContainer 消息监听容器。这个容器会在后台默默地跑那个死循环去 poll 消息。
我们要做的事情很简单:给监听器弄个 ID,针对监听器调用暂停方法。 Spring 框架在收到暂停指令后,会自动在底层调用原生消费者的 pause() 方法,由框架的后台线程去调用 poll() 维持活跃度,避免 max.poll.interval.ms 超时的问题。
监听器弄个 ID
平时大家写 @KafkaListener 可能不写 id 属性,这里必须得加上,否则后面去容器注册表里捞不到它。
@Component
public class OrderConsumer {
// 核心点:必须指定 id,它是这个消费者的唯一标识
@KafkaListener(id = "biz-order-listener", topics = "biz_topic")
public void onMessage(ConsumerRecord<String, String> record) {
// 正常的业务逻辑处理
System.out.println("收到消息:" + record.value());
// 假设这里调用下游接口发现限流了,或者快被打挂了
// 注意:不要在这里直接写 Thread.sleep!
// 具体的暂停动作我们交由专门的控制逻辑来做
}
}
利用注册表实现暂停和恢复
我们需要把 KafkaListenerEndpointRegistry 注入进来。为了演示清晰,这里写一个专门的控制类。
@Service
public class KafkaFlowControlService {
@Autowired
private KafkaListenerEndpointRegistry registry;
// 消费者 ID,跟上面的注解保持一致
private static final String LISTENER_ID = "biz-order-listener";
/**
* 暂停消费
*/
public void pauseConsumption() {
// 从管家手里拿到具体的监听容器
MessageListenerContainer container = registry.getListenerContainer(LISTENER_ID);
if (container != null && !container.isContainerPaused()) {
container.pause();
System.out.println("下游压力过大,已暂停 Kafka 消费拉取...");
}
}
/**
* 恢复消费
*/
public void resumeConsumption() {
MessageListenerContainer container = registry.getListenerContainer(LISTENER_ID);
if (container != null && container.isContainerPaused()) {
container.resume();
System.out.println("下游压力缓解,恢复 Kafka 消费拉取...");
}
}
}
业务流里串起来
到这里机制已经打通了,但线上的坑往往出在流程流转上。一旦你调用了 pause(),这个消费者就不会再拉新消息了。所以必须得有个外部的力量来把它叫醒。
比较稳妥的做法是:业务触发暂停,定时任务负责恢复。
举个例子:在 @KafkaListener 里面发现下游接口连续报了 3 次 HTTP 429,这时候你立刻调用 KafkaFlowControlService.pauseConsumption() 把当前消费停掉。然后写一个定时任务,比如每隔一分钟去试探一下下游接口:
@Component
public class ResumeTask {
@Autowired
private KafkaFlowControlService flowControlService;
// 每隔 1 分钟执行一次
@Scheduled(fixedDelay = 60000)
public void checkAndResume() {
// 检查一下容器是不是在暂停状态
// 去 ping 一下下游系统的探针接口,或者看一眼 Redis 里的限流标识
boolean isDownstreamOk = checkDownstreamHealth();
if (isDownstreamOk) {
// 下游恢复了,把消费端重新拉起来
flowControlService.resumeConsumption();
}
}
}
这个问题是我刚入行时面试被问到的一个题,当时我就是回答的 sleep,还觉得说得挺好,结果却被挂了,哈哈~
(本文由云栈社区整理发布,分享实用技术经验。)
 发表于 2026-4-30 20:38:01
|
查看: 85|
回复: 0
发表于 2026-4-30 20:38:01
|
查看: 85|
回复: 0
