前言
互联网连接时常有波动,速度也不总是理想。在客户端下载大文件时,由于网络问题导致传输中断的概率不容忽视。一旦中断,如果只能从头再来,不仅浪费时间,也消耗带宽资源。
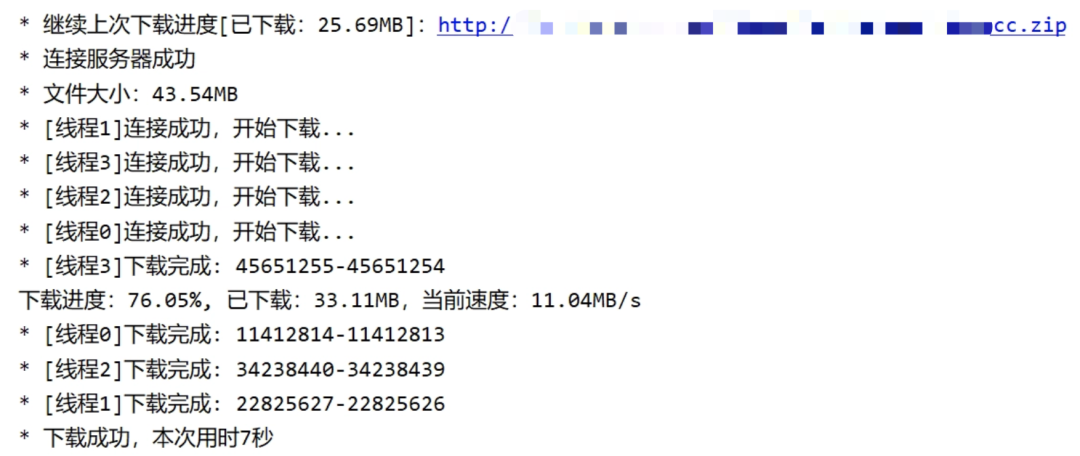
文件断点续传应运而生。其核心思路很简单:客户端记录已下载的部分,下次请求时告诉服务端“从上次中断的位置继续”。下面这张截图展示了一个典型的断点下载过程,可以直观看到多个线程协同工作、进度稳步逼近 100% 的场景。
那么,从技术层面如何实现这一需求?客户端发送 GET 请求时,可以通过设置 Range 头部来告知服务端需要从哪个字节位置开始输出数据。
判断服务端是否支持断点下载,可以依据 HTTP 规范 (参见 14.35.1 Byte Ranges)。一个直接的办法是检查响应头中是否包含 Accept-Ranges: bytes。
// 直接判断是否有 Accept-Ranges = bytes
boolean support = urlConnection.getHeaderField("Accept-Ranges").equals("bytes");
System.out.println("Partial content retrieval support = " + (support ? "Yes" : "No));
例如,我们用 curl 模拟一个范围请求,服务端的响应如下:
donald@donald-pro:~$ curl -i --range 0-9 http://localhost:8080/file/chunk/download
HTTP/1.1 206
Accept-Ranges: bytes
Content-Disposition: inline;filename=pom.xml
Content-Range: bytes 0-9/13485
Content-Length: 10
Date: Mon, 01 Nov 2021 09:53:25 GMT
当然,除了直接看 Accept-Ranges,还有一种更为精准的判断方式,就是发送 HEAD 请求来获取资源的元信息。
HeadObject 接口用于获取某个文件(Object)的元信息。使用此接口不会返回文件内容。
HEAD /ObjectName HTTP/1.1
Host: BucketName.oss-cn-hangzhou.aliyuncs.com
Date: GMT Date
Authorization: SignatureValue
在这个过程中,需要关注几个关键的 HTTP 状态码:
206 Partial Content:HTTP Range 请求成功。416 Requested Range Not Satisfiable status:HTTP Range 请求超出文件范围。200 OK:服务器不支持范围请求。
小结一下,实现断点下载需要把握以下几点:
HTTP 范围请求需要 HTTP/1.1 及以上版本支持,如果客户端或服务端任一端低于此版本,通常认为不支持。- 通过响应头中的
Accept-Ranges 字段来确定服务端是否支持范围请求。
- 客户端在请求头中添加
Range 字段,来指定请求的内容字节范围。
- 服务端在响应头中,通过
Content-Range 来标识实际返回的内容范围,并用 Content-Length 标识此次返回内容的长度。
- 在请求过程中,可以通过
If-Range 来校验资源是否发生了变更,值可以来自 ETag 或者 Last-Modified。如果资源有变动,则会重新走完整下载流程。
生产实战
开发必须依循标准和规范。我们来看看阿里云 OSS 文档中对 Range 的定义:
Range: bytes=0-499:表示第0~499字节范围的内容。Range: bytes=500-999:表示第500~999字节范围的内容。Range: bytes=-500:表示最后500字节的内容。Range: bytes=500-:表示从第500字节开始到文件末尾的内容。Range: bytes=0-:表示完整的文件内容。
如果客户端发来的 HTTP Range 请求是合法的,服务端响应 206 并在响应头中包含 Content-Range;反之,如果 HTTP Range 请求不合法,或者指定范围不在有效区间,Range 就会失效,服务端会响应 200 并返回完整的 Object 内容。
假设 Object 资源大小为 1000 字节,有效区间为 0~999。以下为不合法请求示例:
Range: byte=0-499:格式错误,byte 应为 bytes。Range: bytes=0-1000:末字节 1000 超出有效区间。Range: bytes=1000-2000:整个指定范围都超出有效区间。Range: bytes=1000-:首字节超出有效区间。Range: bytes=-2000:指定范围超出有效区间。
这里再举一个正常范围下载的例子,可以看到服务端返回了 206 状态码及详细的 Content-Range 信息。
# 正常范围下载
donald@donald-pro:~$ curl -i --range 0-9 http://localhost:8080/file/chunk/download
HTTP/1.1 206
Accept-Ranges: bytes
Content-Disposition: inline;filename=Screen_Recording_20211101-162729_Settings.mp4
Content-Range: bytes 0-9
Content-Type: application/force-download;charset=UTF-8
Content-Length: 16241985
Date: Wed, 03 Nov 2021 09:50:50 GMT
服务端 - 业务开发
理论知识已备齐,接下来以 Spring Boot 为例,演示如何在后端业务中实现支持 range 的下载功能。底层存储使用 ceph。
- 对外暴露支持
range 下载的接口。
- 底层对接
ceph 存储。
Controller 层核心代码:
@Slf4j
@RestController
public class Controller {
@Autowired
private FileService fileService;
/**
* 下载文件
*
* 对外提供
*
* @param fileId 文件Id
* @param token token
* @param accountId 帐号Id
* @param response 响应
*/
@GetMapping("/oceanfile/download")
public void downloadOceanfile(@RequestParam String fileId,
@RequestHeader(value = "Range") String range,
HttpServletResponse response) {
this.fileService.downloadFile(fileId, response, range);
}
}
Service 层的实现逻辑,关键在于 executeRangeInfo 方法对 Range 头部字符串的解析与校验。这正是 后端与架构 设计中需要细致处理的细节。
@Slf4j
@Service
public class FileService {
@Autowired
private CephUtils cephUtils;
/**
* 直接下载文件
*
* Tips: 支持断点下载
* @param fileId 文件Id
* @param response 返回
* @param range 范围
*/
public void downloadFile(String fileId, HttpServletResponse response, String range) {
// 根据 fileId 获取文件信息
FileInfo fileInfo = getFileInfo(fileId);
String bucketName = fileInfo.getBucketName();
String relativePath = fileInfo.getRelativePath();
// 处理 range,范围信息
RangeDTO rangeInfo = executeRangeInfo(range, fileInfo.getFileSize());
// rangeInfo = null,直接下载整个文件
if (Objects.isNull(rangeInfo)) {
cephUtils.downloadFile(response, bucketName, relativePath);
return;
}
// 下载部分文件
cephUtils.downloadFileWithRange(response, bucketName, relativePath, rangeInfo);
}
private RangeDTO executeRangeInfo(String range, Long fileSize) {
if (StringUtils.isEmpty(range) || !range.contains("bytes=") || !range.contains("-")) {
return null;
}
long startByte = 0;
long endByte = fileSize - 1;
range = range.substring(range.lastIndexOf("=") + 1).trim();
String[] ranges = range.split("-");
if (ranges.length <= 0 || ranges.length > 2) {
return null;
}
try {
if (ranges.length == 1) {
if (range.startsWith("-")) {
//1. 如:bytes=-1024 从开始字节到第1024个字节的数据
endByte = Long.parseLong(ranges[0]);
} else if (range.endsWith("-")) {
//2. 如:bytes=1024- 第1024个字节到最后字节的数据
startByte = Long.parseLong(ranges[0]);
}
} else {
//3. 如:bytes=1024-2048 第1024个字节到2048个字节的数据
startByte = Long.parseLong(ranges[0]);
endByte = Long.parseLong(ranges[1]);
}
} catch (NumberFormatException e) {
startByte = 0;
endByte = fileSize - 1;
}
if (startByte >= fileSize) {
log.error("range error, startByte >= fileSize. " +
"startByte: {}, fileSize: {}", startByte, fileSize);
return null;
}
return new RangeDTO(startByte, endByte);
}
}
以上便是 Java 文件断点下载从理论到生产的完整实战过程。这套方案已在云栈社区多位开发者的生产环境中稳定运行,如果你之后遇到类似的大文件传输需求,相信可以直接拿来即用,高效搞定!
 发表于 2026-4-30 20:40:31
|
查看: 71|
回复: 0
发表于 2026-4-30 20:40:31
|
查看: 71|
回复: 0
