项目卡片
- 项目:PostHog
- 状态:v1.43.0 / 33.1k Stars / 持续活跃
- 一句话判断:如果你不想在产品分析上拼七八个 SaaS,PostHog 是目前最完整的开源替代方案
你大概遇到过这种场景:产品需要埋点分析,接 Mixpanel;出了线上 bug 要看用户操作回放,又得接 FullStory;想跑 A/B 实验再加一个 LaunchDarkly;做用户调研还要嵌一个 Typeform。最后 dashboard 上贴满不同平台的链接,数据口径对不上,月账单加起来超过一个小团队的人员工资。
PostHog 的做法是:把所有能力塞进一个开源仓库。
它到底装了多少东西
打开 PostHog 的 products/ 目录,里面躺着 62 个子产品。第一次看到这个数字时我也有点怀疑——会不会拆得太细了。但实际翻完代码结构后,这个粒度其实很合理,按功能域大致可以分成五大类:
分析与洞察:product_analytics、web_analytics、replay(会话录制)、dashboards、notebooks、funnels、retention、paths
增长实验:feature_flags、experiments、surveys、product_tours、early_access_features
数据工程:data_warehouse、batch_exports、cdp(数据管道)、data_modeling
可观测性:error_tracking、logs、tracing、alerts
AI 应用:llm_analytics、posthog_ai、mcp_analytics、mcp_store、session_summaries

PostHog 的产品按五大功能域组织,每个域内部再细分具体产品模块。
每个产品都是完整的前后端垂直切片——有自己的 Django app、API 层、React 前端和测试套件。不是 SDK 胶水,而是正经的模块化单体。
架构怎么扛住这么多功能
62 个产品塞在一个仓库里,最怕互相耦合,牵一发而动全身。PostHog 的解法是三层隔离:
产品级隔离。每个产品目录下是完整的 backend/ + frontend/,后端通过 facade 层暴露接口,不允许其他产品直接 import 内部模块。项目用 tach 工具在 CI 中强制检查导入边界,违规直接报错。
数据层分离。PostgreSQL 存业务数据(用户、团队、配置),ClickHouse 存分析数据(事件、录制、指标)。两者通过 Kafka 解耦——事件先写入 Kafka,再由 worker 消费写入 ClickHouse。日常查询走 ClickHouse 的列式引擎,分析性能和写入吞吐可以独立扩展。
服务拆分。核心之外,独立的服务有 llm-gateway(AI 调用代理)、mcp(MCP 工具服务)、oauth-proxy(OAuth 中转)等,按需独立部署。
这套架构让 PostHog 能做到一件事:在单仓库里保持 62 个产品的迭代节奏互不干扰,同时共享基础设施(认证、权限、数据库连接池)。
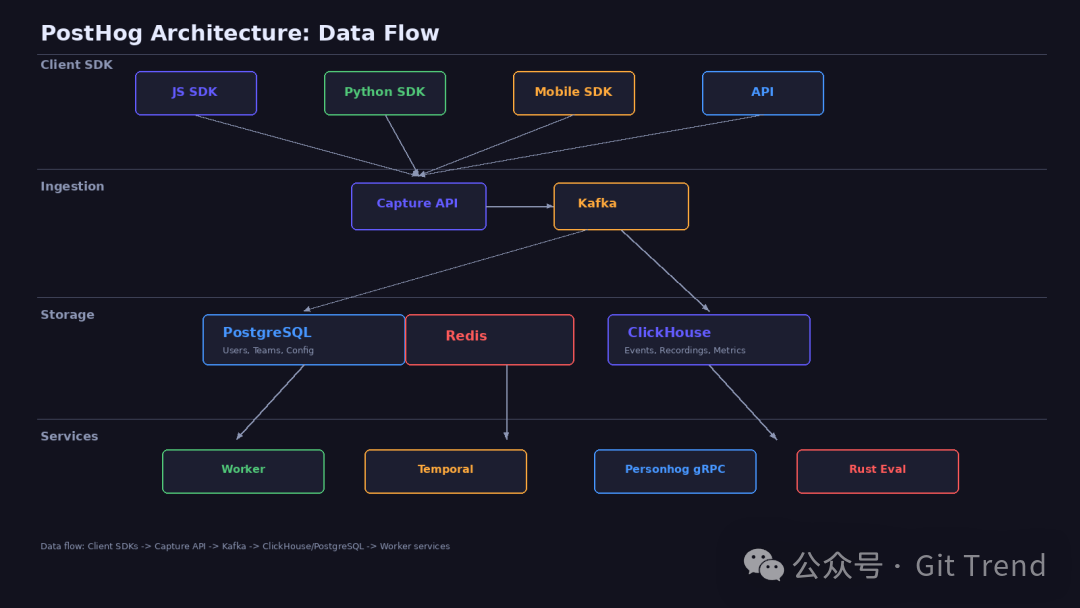
核心数据链路:客户端 SDK 发出事件,经 Capture API 进入 Kafka,由 Worker 分别写入 PostgreSQL(业务数据)和 ClickHouse(分析数据)。
自托管体验:一行命令的事
PostHog 的自托管门槛不算高。官方提供了一行脚本部署:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/posthog/posthog/HEAD/bin/deploy-hobby)"
脚本遵循自动化部署的典型惯例:set -e 保证出错即停,自动生成随机密钥和加密盐,支持 TLS 证书配置。底层跑的是 Docker Compose,拉起 PostgreSQL、Redis、ClickHouse、Kafka、Zookeeper 和 worker 六个服务。
推荐配置是 8GB 内存。官方说法是开源部署能扛住约 10 万事件/月,再往上建议上 Cloud 版。
但需要认清一个现实:自托管用的是 MIT 核心版,不含 ee/ 目录下的企业功能。LLM 分析、高级权限、SSO 等功能在生产环境使用需要企业订阅。开源版更适合做开发测试或小团队内部工具。
几个值得关注的工程细节
事件采集的分流设计。posthog/api/capture.py 是入口,会话录制事件($snapshot、$performance_event)走专门的 Kafka topic,常规分析事件走标准通道。这种分流避免了录制数据洪峰拖垮分析查询。
功能标志用 Rust 写了评估引擎。这点让我比较意外——一个 Python 为主的项目,核心路径上用了 Rust。原因也说得通:标志评估对延迟极度敏感,每个页面加载可能触发多次检查。搭配 Hypercache 缓存层,P99 延迟能压到毫秒级。
Temporal 编排长任务。批量导出、数据仓库同步、AI 对话处理这类可能跑几分钟甚至几小时的任务,全部交给 Temporal 工作流引擎。Temporal 提供自动重试、超时控制和持久化状态,worker 挂了可以无缝恢复。AGENTS.md 里特别强调了一条经验教训:Temporal payload 有 ~2 MiB 硬限制,大数据必须写外部存储后只传引用,这是在生产中踩过的坑。
Person 数据全部走 gRPC。用户相关的表(posthog_person、posthog_persondistinctid 等)不再允许直接查 Django ORM,必须经过 personhog_client 的 gRPC 接口。这是为了把用户数据服务拆成独立微服务,支持独立扩缩容。
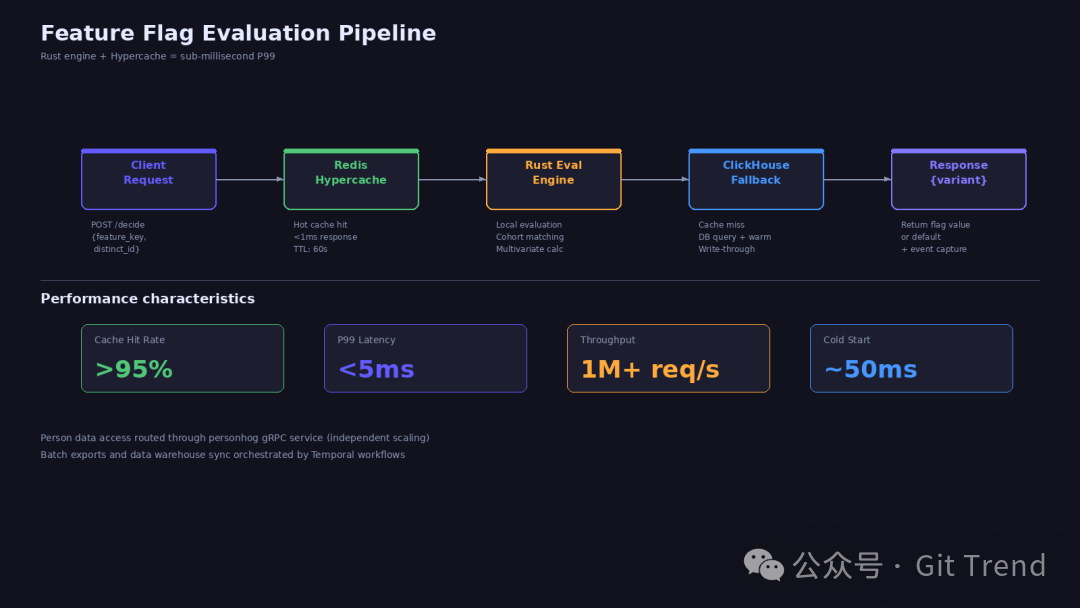
功能标志的评估链路:先查 Redis 热缓存,命中则直接返回;未命中则走 Rust 引擎本地计算,同时写回缓存。极端情况下才回源 ClickHouse。
LLM 分析:AI 时代的差异化赌注
products/llm_analytics/ 是 PostHog 最近投入最重的方向。它做的事情是:如果你在产品里集成了 LLM(比如 AI 客服、代码助手),PostHog 能帮你追踪每一次 LLM 调用的输入输出、延迟、token 成本、错误率。
独立的服务 services/llm-gateway/ 作为 AI 调用代理,接入了 OpenAI、Anthropic、Mistral 等多家 LLM 提供商。上层提供自动聚类(发现用户最常问的问题)、评估模板(批量测试 prompt 效果)、沙盒环境(在线调试 prompt)。
这跟传统的 LangSmith 或 Helicone 有交叉,但 PostHog 的优势在于数据不孤岛——LLM 调用数据可以和用户行为、转化漏斗、会话录制放在一起分析。你可以直接回答“用了新 prompt 之后,用户完成目标的转化率有没有变化”。
选型建议
62 个产品的代价也很直观:仓库体积巨大,shallow clone 都有近 2 万个文件。我 clone 的时候等了一段时间,本地开发环境搭建也不轻松——依赖 Django、ClickHouse、Kafka、Redis,不是装个 pip 就能跑的。
如果你符合以下条件,我认为它值得认真评估:
- 不想管理七八个分析 SaaS 的团队,尤其是月账单已经开始刺痛的时候
- 对数据归属有合规要求,需要自托管或私有云部署
- 产品里集成了 LLM,需要观测 AI 使用情况
- 愿意接受“80% 功能免费 + 企业功能付费”的模式
技术栈偏好上,Django + ClickHouse + Kafka + Temporal 的组合偏重,运维成本比纯 SaaS 高。但换来的是数据完全可控、功能不锁在别人的平台里。
免费层每月 100 万事件、5000 次录制、100 万次标志请求,对中小项目基本够用。超过这个量再按用量付费,或者考虑自托管绕开账单。
 发表于 2026-4-29 06:02:36
|
查看: 157|
回复: 0
发表于 2026-4-29 06:02:36
|
查看: 157|
回复: 0
